







常用SparkRDD容易混淆的算子区别
1.map与flatMap的区别
# 初始化数据
val rdd1 = sc.parallelize(Array("hello world","i love you"))- map
# map算子
rdd1.map(_.split(" ")).collect
# map算子结果输出
res0: Array[Array[String]] = Array(Array(hello, world), Array(i, love, you))- flatMap
# flatMap算子
rdd1.flatMap(_.split(" ")).collect
# flatMap算子结果输出
res1: Array[String] = Array(hello, world, i, love, you)flatMap是将数据先进行map转化,在通过flattern对map结果进行’压平’。也就是将map转化的2个Array压平处理。
flatMap的效率要优于map
2.map与mapPartitions的区别
map是对rdd中的每一个元素进行操作。
mapPartitions(foreachPartition)则是对rdd中的每个分区的迭代器进行操作。
如果在map过程中需要频繁创建额外的对象(例如将rdd中的数据通过jdbc写入数据库,map需要为每个元素创建一个链接而mapPartition为每个partition创建一个链接),则mapPartitions效率比map高的多。
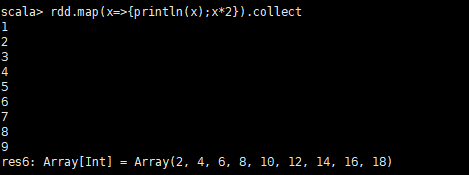
- map示例
# 初始化数据,设置3个分区
val rdd = sc.parallelize(Array(1,2,3,4,5,6,7,8,9),3)
rdd.map(x=>{println(x);x*2}).collect输出结果:
- mapPartitions示例
rdd.mapPartitions(x=>{println("-----------");for(i<-x)yield i*2}).collect输出结果:

通过对比,我们可以发现,mapPartitions在每个分区只会调用一次。而map每次都会被调用。所以在特定的场景mapPartitions效率比map高的多。
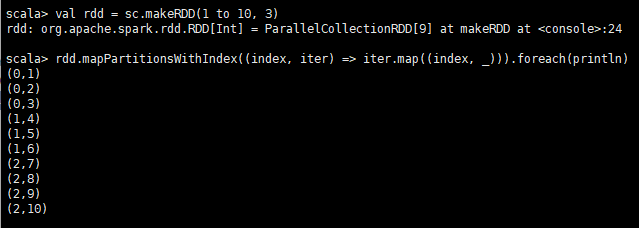
3.mapPartitionsWithIndex示例
- mapPartitionsWithIndex
类似于mapPartitions,但取两个参数。
第一个参数是分区的索引(index),第二个参数是通过这个分区中的所有项的迭代器(iterator)。
输出是一个迭代器,它包含在应用函数编码的任何转换之后的项目列表。
# 初始化数据
val rdd = sc.makeRDD(1 to 10, 3)
# mapPartitionsWithIndex方法是调用,传入一个函数,函数参数1为index,参数2为iterator
rdd.mapPartitionsWithIndex((index, iter) => iter.map((index, _))).foreach(println)输出结果:
4.mapValues与flatMapValues
- mapValues
# 初始化rdd
val rdd = sc.makeRDD(List("hello spark", "hello java", "hello python", "hello r","hello scala"), 2)
rdd.map(x => (x.length % 3, x)).mapValues(x => x.split(" ")).collect()输出结果:

- flatMapValues
# 初始化rdd
val rdd = sc.makeRDD(List("hello spark", "hello java", "hello python", "hello r","hello scala"), 2)
rdd.map(x => (x.length % 3, x)).flatMapValues(x => x.split(" ")).collect()输出结果:

flatMapValues是把map中的value进行过函数操作后,再将数据结构压平。
5.coalesce、repartition与partitionBy
- coalesece
该函数用于将RDD进行重分区,使用HashPartitioner进行分区。
接受2个参数,第一个参数为重分区的数目,第二个为是否进行shuffle,默认为false;
val rdd1 = sc.parallelize(1 to 12,3)
println(rdd1.partitions.length) //输出结果 3
val rdd2 = rdd1.coalesce(2)
println(rdd2.partitions.length) // 输出结果 2
//如果重分区的数目大于原来的分区数,那么必须指定shuffle参数为true,//否则,分区数不变
val rdd3 = rdd1.coalesce(4)
println(rdd3.partitions.length) // 输出结果 3
val rdd4 = rdd1.coalesce(4,true)
println(rdd4.partitions.length) // 输出结果 4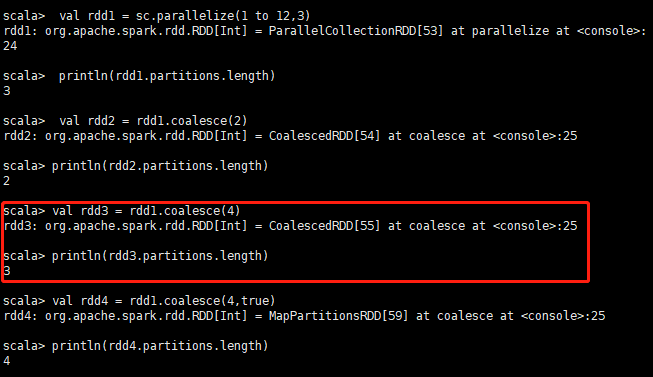
- repartition
该函数其实就是coalesce函数第二个参数为true的实现
def repartition(numPartitions: Int)(implicit ord: Ordering[T] = null): RDD[T] = withScope {
coalesce(numPartitions, shuffle = true)
}示例:
val rdd1 = sc.parallelize(1 to 12,3)
val rdd5 = rdd1.repartition(4)
println(rdd5.partitions.length) // 输出结果 4
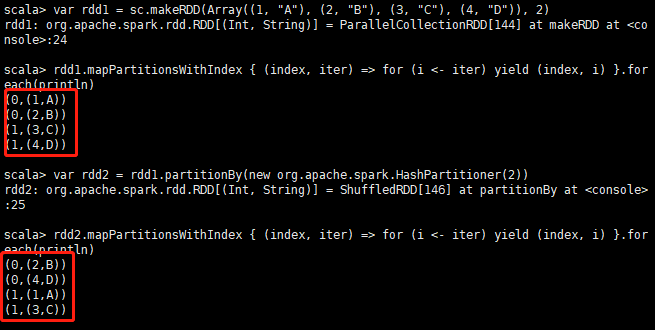
- partitionBy
partitionBy:表示重新分区,不是仅仅是设置分区数
var rdd1 = sc.makeRDD(Array((1, "A"), (2, "B"), (3, "C"), (4, "D")), 2)
rdd1.mapPartitionsWithIndex { (index, iter) => for (i <- iter) yield (index, i) }.foreach(println)
# 重新设置分区
var rdd2 = rdd1.partitionBy(new org.apache.spark.HashPartitioner(2))
rdd2.mapPartitionsWithIndex { (index, iter) => for (i <- iter) yield (index, i) }.foreach(println)结果如图:4.13图
6.union、distinct、intersection、subtract
- union
求并集
val rdd1 = sc.parallelize(List(5, 6, 4, 3))
val rdd2 = sc.parallelize(List(1, 2, 3, 4))
rdd1.union(rdd2).collect
# 输出结果,这个结果不会去重
res52: Array[Int] = Array(5, 6, 4, 3, 1, 2, 3, 4)- distinct
去重
val rdd1 = sc.parallelize(List(5, 6, 4, 3))
val rdd2 = sc.parallelize(List(1, 2, 3, 4))
val rdd3 = rdd1.union(rdd2)
rdd3.distinct.collect
# 输出结果,结果去重
res53: Array[Int] = Array(4, 6, 2, 1, 3, 5)- intersection
求交集
val rdd1 = sc.parallelize(List(5, 6, 4, 3))
val rdd2 = sc.parallelize(List(1, 2, 3, 4))
rdd1.intersection(rdd2).collect
# 输出结果:
res54: Array[Int] = Array(4, 3)- subtract
求差集
val rdd1 = sc.parallelize(List(5, 6, 4, 3))
val rdd2 = sc.parallelize(List(1, 2, 3, 4))
rdd1.subtract(rdd2).collect
# 输出结果
res55: Array[Int] = Array(5, 6)
rdd2.subtract(rdd1).collect
# 输出结果
res56: Array[Int] = Array(1, 2)- subtractByKey
subtractByKey和基本转换操作中的subtract类似,只不过这里是针对K的
val rdd1 = sc.makeRDD(Array(("A", "1"), ("B", "2"), ("B", "3"), ("C", "3")), 2)
val rdd2 = sc.makeRDD(Array(("A", "a"), ("C", "c"), ("D", "d")), 2)
rdd1.subtractByKey(rdd2).collect
# 输出结果:因为rdd2的key中有A,C,所以差集就是B
res57: Array[(String, String)] = Array((B,2), (B,3))
rdd2.subtractByKey(rdd1).collect
# 输出结果:
res58: Array[(String, String)] = Array((D,d))7.groupByKey、reduceByKey、foldByKey、aggregateByKey
- groupByKey
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2), ("shuke", 1)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 3), ("shuke", 2), ("kitty", 5)))
//求并集
val rdd3 = rdd1 union rdd2
rdd3.groupByKey().collect
# 输出结果:
res89: Array[(String, Iterable[Int])] = Array((tom,CompactBuffer(1, 3)), (jerry,CompactBuffer(3, 2)), (shuke,CompactBuffer(1, 2)), (kitty,CompactBuffer(2, 5)))
rdd3.groupByKey().map(t=>(t._1,t._2.sum)).collect
# 输出结果:
res90: Array[(String, Int)] = Array((tom,4), (jerry,5), (shuke,3), (kitty,7))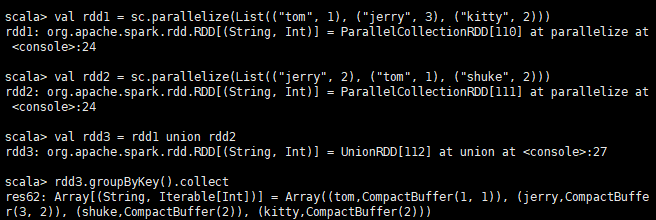
- reduceByKey
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2), ("shuke", 1)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 3), ("shuke", 2), ("kitty", 5)))
val rdd3 = rdd1.union(rdd2)
//按key进行聚合
rdd3.reduceByKey(_ + _).collect
# 输出结果:
res91: Array[(String, Int)] = Array((tom,4), (jerry,5), (shuke,3), (kitty,7))groupByKey和reduceByKey都可以通过key来进行聚合。不同的是2者,聚合的过程是不一样的。
reduceByKey现在map过程中先进行聚合,再到reduce端聚合,减少数据太大带来的压力,减小RPC过程中的传输压力。
groupByKey是直接在reduce端进行聚合的,所以效率比reduceByKey低。
推荐使用reduceByKey,因为效率比groupByKey高
关于groupByKey与reduceByKey的推荐文章:reduceByKey和groupByKey区别与用法
- foldByKey
该函数用于RDD[K,V]根据K将V做折叠、合并处理,其中的参数zeroValue表示先根据映射函数将zeroValue应用于V,进行初始化V,再将映射函数应用于初始化后的V.
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2), ("shuke", 1)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 3), ("shuke", 2), ("kitty", 5)))
val rdd3 = rdd1.union(rdd2)
rdd3.foldByKey(0)(_ + _).collect
# 输出结果:
res84: Array[(String, Int)] = Array((tom,4), (jerry,5), (shuke,3), (kitty,7))foldByKey和reduceByKey的功能是相似的,都是在map端先进行聚合,再到reduce聚合。不同的是flodByKey需要传入一个参数。该参数是计算的初始值。
- aggregateByKey
aggregateByKey函数对PairRDD中相同Key的值进行聚合操作,在聚合过程中同样使用了一个中立的初始值。
def aggregateByKey[U](zeroValue: U)(seqOp: (U, V) => U, combOp: (U, U) => U)(implicit arg0: ClassTag[U]): RDD[(K, U)]
def aggregateByKey[U](zeroValue: U, numPartitions: Int)(seqOp: (U, V) => U, combOp: (U, U) => U)(implicit arg0: ClassTag[U]): RDD[(K, U)]
def aggregateByKey[U](zeroValue: U, partitioner: Partitioner)(seqOp: (U, V) => U, combOp: (U, U) => U)(implicit arg0: ClassTag[U]): RDD[(K, U)]示例:
val rdd1 = sc.parallelize(List(("tom", 1), ("jerry", 3), ("kitty", 2), ("shuke", 1)))
val rdd2 = sc.parallelize(List(("jerry", 2), ("tom", 3), ("shuke", 2), ("kitty", 5)))
val rdd3 = rdd1.union(rdd2)
# aggregateByKey(0)(math.max(_,_),_+_)
# (0):0是传入的初始值
# math.max(_,_):是一个函数,表示传入的数据与初始值比较,取最小值
# _+_:和reduceByKey中一样,表示`(x,y)=>x+y`这样的函数
rdd3.aggregateByKey(0)(math.max(_,_),_+_).collect
# 输出结果:
res93: Array[(String, Int)] = Array((tom,4), (jerry,5), (shuke,3), (kitty,7))aggregateByKey会先在本节点内先聚合,然后再聚合所有节点的结果。
8.zip函数与zipPartitions函数
- zip函数
zip函数用于将两个RDD组合成Key/Value形式的RDD
var rdd1 = sc.makeRDD(1 to 5, 2)
var rdd2 = sc.makeRDD(Seq("A", "B", "C", "D", "E"), 2)
rdd1.zip(rdd2).foreach(println)
# 输出结果:
(1,A)
(2,B)
(3,C)
(4,D)
(5,E)
rdd2.zip(rdd1).foreach(println)
# 输出结果:
(A,1)
(B,2)
(C,3)
(D,4)
(E,5)这里需要注意的是:
1.如果两个RDD分区数不同,则抛出异常:Can’t zip RDDs with unequal numbers of partitions
2.如果两个RDD的元素个数不同,则抛出异常:Can only zip RDDs with same number of elements in each partition
- zipPartitions函数
zipPartitions函数将多个RDD按照partition组合成为新的RDD。
该函数需要组合的RDD具有相同的分区数,但对于每个分区内的元素数量没有要求。
2个RDD进行zipPartitions操作
var rdd1 = sc.makeRDD(1 to 5, 2)
var rdd2 = sc.makeRDD(Seq("A", "B", "C", "D", "E"), 2)
rdd1.zipPartitions(rdd2) {
(rdd1Iter, rdd2Iter) => {
var result = List[String]()
while (rdd1Iter.hasNext && rdd2Iter.hasNext) {
result ::= (rdd1Iter.next() + "_" + rdd2Iter.next())
}
result.iterator
}
}.foreach(println)
# 输出结果:
2_B
1_A
5_E
4_D
3_C
3个RDD进行zipPartitions操作
var rdd1 = sc.makeRDD(1 to 5, 2)
var rdd2 = sc.makeRDD(Seq("A", "B", "C", "D", "E"), 2)
var rdd3 = sc.makeRDD(Seq("a", "b", "c", "d", "e"), 2)
var rdd4 = rdd1.zipPartitions(rdd2, rdd3) {
(rdd1Iter, rdd2Iter, rdd3Iter) =>
{
var result = List[String]()
while (rdd1Iter.hasNext && rdd2Iter.hasNext && rdd3Iter.hasNext) {
result ::= (rdd1Iter.next() + "_" + rdd2Iter.next() + "_" + rdd3Iter.next())
}
result.iterator
}
}
rdd4.foreach(println)
# 输出结果:
2_B_b
1_A_a
5_E_e
4_D_d
3_C_c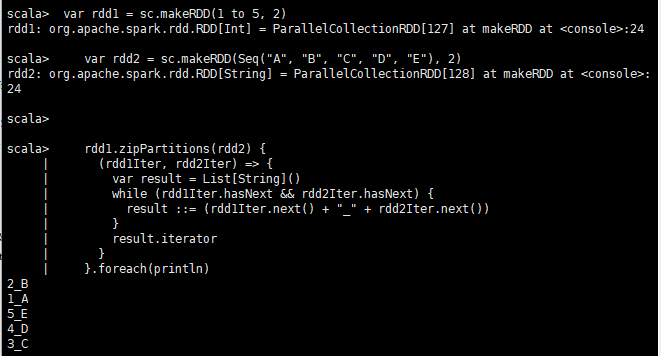
9.zipWithIndex函数与zipWithUniqueId函数
- zipWithIndex函数
该函数将RDD中的元素和这个元素在RDD中的ID(索引号)组合成键/值对。
va rdd2 = sc.makeRDD(Seq("A", "B", "R", "D", "F"), 2)
rdd2.zipWithIndex().foreach(println)
# 输出结果:
(A,0)
(B,1)
(R,2)
(D,3)
(F,4)- zipWithUniqueId函数
该函数将RDD中元素和一个唯一ID组合成键/值对,
该唯一ID生成算法如下:
每个分区中第一个元素的唯一ID值为:该分区索引号
每个分区中第N个元素的唯一ID值为:(前一个元素的唯一ID值) + (该RDD总的分区数)
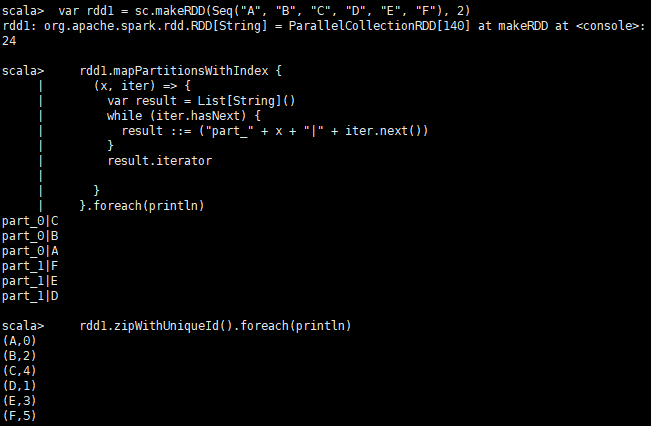
var rdd1 = sc.makeRDD(Seq("A", "B", "C", "D", "E", "F"), 2)
rdd1.mapPartitionsWithIndex {
(x, iter) => {
var result = List[String]()
while (iter.hasNext) {
result ::= ("part_" + x + "|" + iter.next())
}
result.iterator
}
}.foreach(println)
rdd1.zipWithUniqueId().foreach(println)结果如图:















 514
514

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









