







1. ArrayList 继承体系
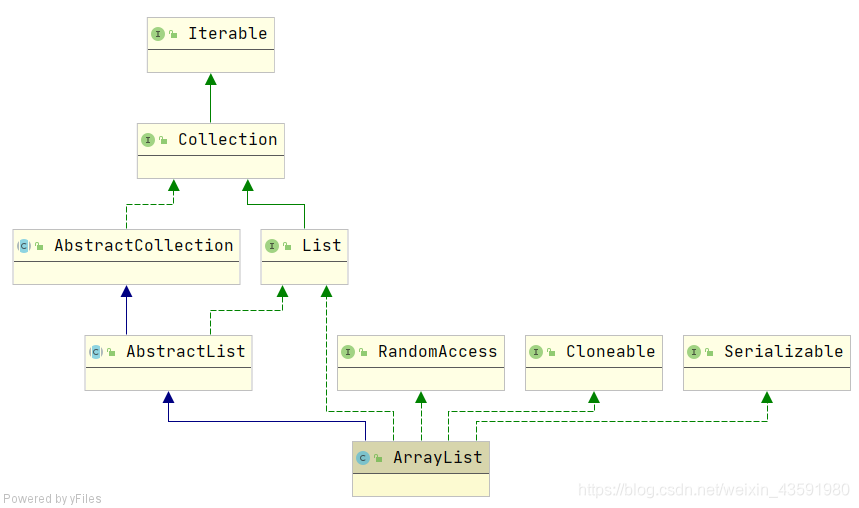
ArrayList 又称动态数组,底层是基于数组实现的List,与数组的区别在于,其具备动态扩展能力。从继承体系图中可看出ArrayList:
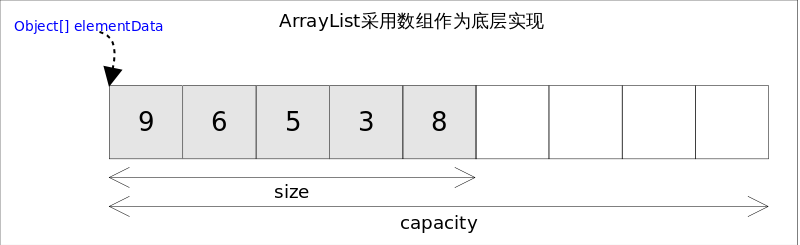
ArrayList实现了List接口,是顺序容器,即元素存放的数据与放进去的顺序相同,允许放入 null 元素,底层通过数组实现。除该类未实现同步外,其余跟Vector大 致相同。每个ArrayList都有一个容量(capacity),表示底层数组的实际大小,容器内存储元素的个数不能多于当前容量。当向容器中添加元素时,如果容量不足,容 器会自动增大底层数组的大小。前面已经提过,Java泛型只是编译器提供的语法糖,所以这里的数组是一个Object数组,以便能够容纳任何类型的对象。
size(), isEmpty(), get(), set()方法均能在常数时间内完成,add()方法的时间开销跟插入位置有关,addAll()方法的时间开销跟添加元素的个数成正比。其余方法大都是 线性时间。 为追求效率,ArrayList没有实现同步(synchronized),如果需要多个线程并发访问,用户可以手动同步,也可使用Vector替代。
size(), isEmpty(), get(), set()方法均能在常数时间内完成,add()方法的时间开销跟插入位置有关,addAll()方法的时间开销跟添加元素的个数成正比。其余方法大都是线性时间。
为追求效率,ArrayList没有实现同步(synchronized),如果需要多个线程并发访问,用户可以手动同步,也可使用Vector替代。
ArrayList实现了List接口,是顺序容器,即元素存放的数据与放进去的顺序相同,允许放入null元素,底层通过数组实现。除该类未实现同步外,其余跟Vector大致相同。每个ArrayList都有一个容量(capacity),表示底层数组的实际大小,容器内存储元素的个数不能多于当前容量。当向容器中添加元素时,如果容量不足,容器会自动增大底层数组的大小。前面已经提过,Java泛型只是编译器提供的语法糖,所以这里的数组是一个Object数组,以便能够容纳任何类型的对象。
实现了List, RandomAccess, Cloneable, java.io.Serializable等接口
实现了List,具备基础的添加、删除、遍历等操作
实现了RandomAccess,具备随机访问的能力
实现了Cloneable,可以被克隆(浅拷贝) list.clone()
实现了Serializable,可以被序列化
2. ArrayList 实现Cloneable,RandomAccess,Serializable接口
实现Cloneable接口,可以被浅拷贝
/**
* Returns a shallow copy of this <tt>ArrayList</tt> instance. (The
* elements themselves are not copied.)
* 返回此<tt> ArrayList </ tt>实例的拷贝副本。 (元素本身不会被复制。)
*
* @return a clone of this <tt>ArrayList</tt> instance
*/
public Object clone() {
try {
ArrayList<?> v = (ArrayList<?>) super.clone();
// 拷贝
v.elementData = Arrays.copyOf(elementData, size);
v.modCount = 0;
return v;
} catch (CloneNotSupportedException e) {
// this shouldn't happen, since we are Cloneable
throw new InternalError(e);
}
}
在java语言中,对象实现 Cloneable 接口时,能够对其进行深拷贝和浅拷贝,这里简述下,深拷贝和浅拷贝的区别:
下面来看浅拷贝实例:
@Test
public void test02() {
/**
* 简单演示ArrayList 浅拷贝:
*/
ArrayList list = new ArrayList();
//User 对象实例化
User user = new User("csp");
list.add("abc");// list添加简单字符类型
list.add(user);// list添加对象类型
System.out.println("------------原始ArrayList集合------------");
System.out.println("list:"+list);
// 浅拷贝
ArrayList clone = (ArrayList) list.clone();
System.out.println("------------浅拷贝后得到的新ArrayList集合------------");
System.out.println("二者地址是否相同:" + (list == clone));
System.out.println("------------未修改list中的User属性之前------------");
System.out.println("clone:"+clone);
System.out.println("------------当修改list中的User属性之后------------");
User u = (User) list.get(1);
u.setName("csp1999");
System.out.println("clone:"+clone);
System.out.println("clone中的user对象和原始list中的user对象地址是否相同:"+(list.get(1)==clone.get(1)));
}
------------原始ArrayList集合------------
list:[abc, User{name='csp'}]
------------浅拷贝后得到的新ArrayList集合------------
二者地址是否相同:false
------------未修改list中的User属性之前------------
clone:[abc, User{name='csp'}]
------------当修改list中的User属性之后------------
clone:[abc, User{name='csp1999'}]
clone中的user对象和原始list中的user对象地址是否相同:true
由结果可得出结论:
当最初的list 集合被克隆之后,实际上是产生了一个新的ArrayList对象,二者地址引用不相同
当从list集合中获取到user对象并修改其属性之后,clone集合中的user属性也对应发生了改变,这就说明,clone在复制list集合时,对复杂的对象类型数据元素,只是拷贝了其地址引用,并未对其进行新建对象
因此,执行list.get(1)==clone.get(1))代码的时候,二者存储的user是同一个user对象,地址和数据均相同
而如果进行深拷贝时,就会在list被克隆新创建克隆对象时,对其存储的复杂对象类型也进行对象新创建,复杂对象类型数据获得新的地址引用,而不是像浅拷贝那样,仅仅拷贝了复杂对象类型的地址引用。
实现RandomAccess接口,可以提高随机访问列表的效率
ArrayList 实现了RandomAccess接口,因此当执行随机访问列表的时候,效率要高于顺序访问列表的效率,我们来看一个例子:
@Test
public void test03() {
ArrayList arrayList = new ArrayList();
for (int i=0;i<=99999;i++){// 集合中添加十万条数据
arrayList.add(i);
}
// 测试随机访问的效率:
long startTime = System.currentTimeMillis();
for (int i = 0; i < arrayList.size(); i++) {// 随机访问
// 从集合中访问每一个元素
arrayList.get(i);
}
long endTime = System.currentTimeMillis();
System.out.println("执行随机访问所用时间:"+(endTime-startTime));
// 测试顺序访问的效率:
startTime = System.currentTimeMillis();
Iterator it = arrayList.iterator();// 顺序访问,也可以使用增强for
while (it.hasNext()){
// 从集合中访问每一个元素
it.next();
}
endTime = System.currentTimeMillis();
System.out.println("执行顺序访问所用时间:"+(endTime-startTime));
}
执行随机访问所用时间:1
执行顺序访问所用时间:3
可以看出实现RandomAccess接口的ArrayList 进行随机访问的效率高于进行顺序访问的效率。
作为对比我们再来看一下未实现RandomAccess接口的LinkedList集合,测试随机访问和顺序访问列表的效率对比:
@Test
public void test04() {
LinkedList linkedList = new LinkedList();
for (int i=0;i<=99999;i++){// 集合中添加十万条数据
linkedList.add(i);
}
// 测试随机访问的效率:
long startTime = System.currentTimeMillis();
for (int i = 0; i < linkedList.size(); i++) {// 随机访问
// 从集合中访问每一个元素
linkedList.get(i);
}
long endTime = System.currentTimeMillis();
System.out.println("执行随机访问所用时间:"+(endTime-startTime));
// 测试顺序访问的效率:
startTime = System.currentTimeMillis();
Iterator it = linkedList.iterator();// 顺序访问,也可以使用增强for
while (it.hasNext()){
// 从集合中访问每一个元素
it.next();
}
endTime = System.currentTimeMillis();
System.out.println("执行顺序访问所用时间:"+(endTime-startTime));
}
执行随机访问所用时间:4601
执行顺序访问所用时间:2
由结果可得出结论,没有实现RandomAccess接口的LinkedList集合,测试随机访问的效率远远低于顺序访问。
3. ArrayList 属性
/**
* Default initial capacity.
* 默认容量
*/
private static final int DEFAULT_CAPACITY = 10;
/**
* Shared empty array instance used for empty instances.
* 空数组,如果传入的容量为0时使用
*/
private static final Object[] EMPTY_ELEMENTDATA = {};
/**
* Shared empty array instance used for default sized empty instances.
* We distinguish this from EMPTY_ELEMENTDATA to know how much to inflate when first element is added.
* 默认空容量的数组,长度为0,传入容量时使用,添加第一个元素的时候会重新初始为默认容量大小
*/
private static final Object[] DEFAULTCAPACITY_EMPTY_ELEMENTDATA = {};
/**
* The array buffer into which the elements of the ArrayList are stored.
* The capacity of the ArrayList is the length of this array buffer. Any
* empty ArrayList with elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA
* will be expanded to DEFAULT_CAPACITY when the first element is added.
* 集合中真正存储数据元素的数组容器
*/
transient Object[] elementData; // non-private to simplify nested class access
/**
* The size of the ArrayList (the number of elements it contains).
* 集合中元素的个数
* @serial
*/
private int size;
DEFAULT_CAPACITY:集合的默认容量,默认为10,通过new ArrayList()创建List集合实例时的默认容量是10。
EMPTY_ELEMENTDATA:空数组,通过new ArrayList(0)创建List集合实例时用的是这个空数组。
DEFAULTCAPACITY_EMPTY_ELEMENTDATA:默认容量空数组,这种是通过new ArrayList()无参构造方法创建集合时用的是这个空数组,与EMPTY_ELEMENTDATA的区别是在添加第一个元素时使用这个空数组的会初始化为DEFAULT_CAPACITY(10)个元素。
elementData:存储数据元素的数组,使用transient修饰,该字段不被序列化。
size:存储数据元素的个数,elementData数组的长度并不是存储数据元素的个数。
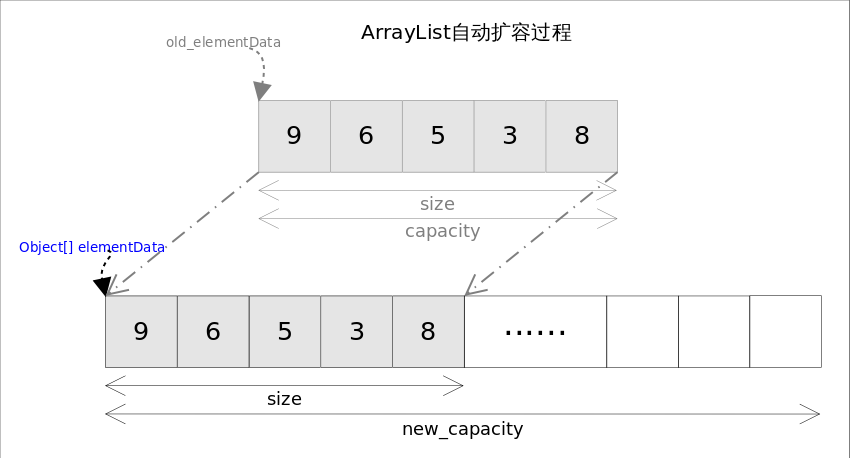
自动扩容
每当向数组中添加元素时,都要去检查添加后元素的个数是否会超出当前数组的长度,如果超出,数组将会进行扩容,以满足添加数据的需求。数组扩容通过一个公 开的方法ensureCapacity(int minCapacity)来实现。在实际添加大量元素前,我也可以使用ensureCapacity来手动增加ArrayList实例的容量,以减少递增式再分配的数 量。 数组进行扩容时,会将老数组中的元素重新拷贝一份到新的数组中,每次数组容量的增长大约是其原容量的1.5倍。这种操作的代价是很高的,因此在实际使用时,我 们应该尽量避免数组容量的扩张。当我们可预知要保存的元素的多少时,要在构造ArrayList实例时,就指定其容量,以避免数组扩容的发生。或者根据实际需求,通 过调用ensureCapacity方法来手动增加ArrayList实例的容量。
4. ArrayList 构造方法
ArrayList(int initialCapacity)有参构造方法
/**
* Constructs an empty list with the specified initial capacity.
* 构造具有指定初始容量的空数组
*
* @param initialCapacity the initial capacity of the list 列表的初始容量
* @throws IllegalArgumentException if the specified initial capacity is negative
*
* 传入初始容量,如果大于0就初始化elementData为对应大小,如果等于0就使用EMPTY_ELEMENTDATA空数组,
* 如果小于0抛出异常。
*/
// ArrayList(int initialCapacity)构造方法
public ArrayList(int initialCapacity) {
if (initialCapacity > 0) {
this.elementData = new Object[initialCapacity];
} else if (initialCapacity == 0) {
this.elementData = EMPTY_ELEMENTDATA;
} else {
throw new IllegalArgumentException("不合理的初识容量: " +
initialCapacity);
}
}
ArrayList()空参构造方法
/**
* Constructs an empty list with an initial capacity of ten.
* 构造一个初始容量为10的空数组
*
* 不传初始容量,初始化为DEFAULTCAPACITY_EMPTY_ELEMENTDATA空数组,
* 会在添加第一个元素的时候扩容为默认的大小,即10。
*/
public ArrayList() {
this.elementData = DEFAULTCAPACITY_EMPTY_ELEMENTDATA;
}
ArrayList(Collection c)有参构造方法
/**
* Constructs a list containing the elements of the specified
* collection, in the order they are returned by the collection's
* iterator.
* 把传入集合的元素初始化到ArrayList中
*
* @param c the collection whose elements are to be placed into this list
* @throws NullPointerException if the specified collection is null
*/
public ArrayList(Collection<? extends E> c) {
// 将构造方法中的集合参数转换成数组
elementData = c.toArray();
if ((size = elementData.length) != 0) {
// 检查c.toArray()返回的是不是Object[]类型,如果不是,重新拷贝成Object[].class类型
if (elementData.getClass() != Object[].class)
// 数组的创建与拷贝
elementData = Arrays.copyOf(elementData, size, Object[].class);
} else {
// 如果c是空的集合,则初始化为空数组EMPTY_ELEMENTDATA
this.elementData = EMPTY_ELEMENTDATA;
}
}
5. ArrayList 相关操作方法
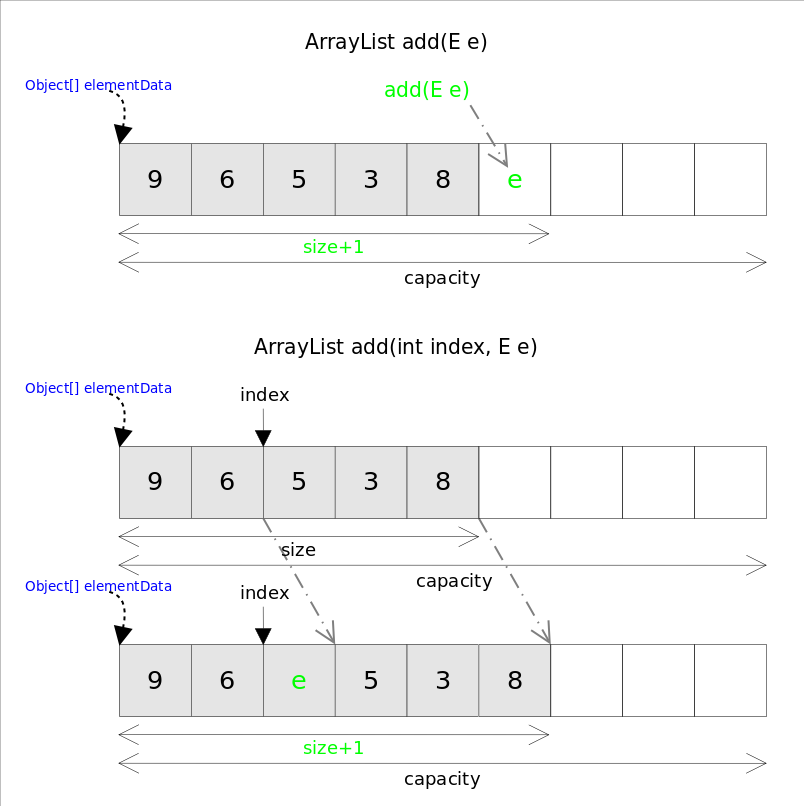
添加元素到末尾,平均时间复杂度为O(1):
/**
* Appends the specified element to the end of this list.
* 添加元素到末尾,平均时间复杂度为O(1)
* * @param e element to be appended to this list
* @return <tt>true</tt> (as specified by {@link Collection#add})
*/
public boolean add(E e) {
// 每加入一个元素,minCapacity大小+1,并检查是否需要扩容
ensureCapacityInternal(size + 1); // Increments modCount!!
// 把元素插入到最后一位
elementData[size++] = e;
return true;
}
// 计算最小容量
private static int calculateCapacity(Object[] elementData, int minCapacity) {
// 如果是空数组DEFAULTCAPACITY_EMPTY_ELEMENTDATA
if (elementData == DEFAULTCAPACITY_EMPTY_ELEMENTDATA) {
// 返回DEFAULT_CAPACITY 和 minCapacity的大一方
return Math.max(DEFAULT_CAPACITY, minCapacity);
}
return minCapacity;
}
// 检查是否需要扩容
private void ensureCapacityInternal(int minCapacity) {
ensureExplicitCapacity(calculateCapacity(elementData, minCapacity));
}
private void ensureExplicitCapacity(int minCapacity) {
modCount++;// 数组结构被修改的次数+1
// overflow-conscious code 储存元素的数据长度小于需要的最小容量时
if (minCapacity - elementData.length > 0)
// 扩容
grow(minCapacity);
}
/**
* 扩容
* Increases the capacity to ensure that it can hold at lea
* number of elements specified by the minimum capacity arg
* 增加容量以确保它至少可以容纳最小容量参数指定的元素数量
* @param minCapacity the desired minimum capacity
*/
private void grow(int minCapacity) {
// 原来的容量
int oldCapacity = elementData.length;
// 新容量为旧容量的1.5倍
int newCapacity = oldCapacity + (oldCapacity >> 1);
// 如果新容量发现比需要的容量还小,则以需要的容量为准
if (newCapacity - minCapacity < 0)
newCapacity = minCapacity;
// 如果新容量已经超过最大容量了,则使用最大容量
if (newCapacity - MAX_ARRAY_SIZE > 0)
newCapacity = hugeCapacity(minCapacity);
// 以新容量拷贝出来一个新数组
elementData = Arrays.copyOf(elementData, newCapacity);
}
// 使用最大容量
private static int hugeCapacity(int minCapacity) {
if (minCapacity < 0) // overflow
throw new OutOfMemoryError();
return (minCapacity > MAX_ARRAY_SIZE) ?
Integer.MAX_VALUE :
MAX_ARRAY_SIZE;
}
执行流程:
检查是否需要扩容;
如果elementData等于DEFAULTCAPACITY_EMPTY_ELEMENTDATA则初始化容量大小为DEFAULT_CAPACITY;
新容量是老容量的1.5倍(oldCapacity + (oldCapacity >> 1)),如果加了这么多容量发现比需要的容量还小,则以需要的容量为准;
创建新容量的数组并把老数组拷贝到新数组;
add(int index, E element)添加元素到指定位置
添加元素到指定位置,平均时间复杂度为O(n):
/**
* Inserts the specified element at the specified position in this
* list. Shifts the element currently at that position (if any) and
* any subsequent elements to the right (adds one to their indices).
* 添加元素到指定位置,平均时间复杂度为O(n)。
* * @param index 指定元素要插入的索引
* @param element 要插入的元素
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public void add(int index, E element) {
// 检查是否越界
rangeCheckForAdd(index);
// 检查是否需要扩容
ensureCapacityInternal(size + 1); // Increments modCount!!
// 将inex及其之后的元素往后挪一位,则index位置处就空出来了
// **进行了size-索引index次操作**
System.arraycopy(elementData, index, elementData, index + 1,
size - index);
// 将元素插入到index的位置
elementData[index] = element;
// 元素数量增1
size++;
}
/**
* A version of rangeCheck used by add and addAll.
* add和addAll方法使用的rangeCheck版本
*/
// 检查是否越界
private void rangeCheckForAdd(int index) {
if (index > size || index < 0)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
执行流程:
- 检查索引是否越界;
- 检查是否需要扩容;
- 把插入索引位置后的元素都往后挪一位;
- 在插入索引位置放置插入的元素;
- 元素数量增1;
addAll(Collection c)添加所有集合参数中的所有元素
求两个集合的并集:
/**
* Appends all of the elements in the specified collection to the end of
* this list, in the order that they are returned by the
* specified collection's Iterator. The behavior of this operation is
* undefined if the specified collection is modified while the operation
* is in progress. (This implies that the behavior of this call is
* undefined if the specified collection is this list, and this
* list is nonempty.)
* 将集合c中所有元素添加到当前ArrayList中
* * @param c collection containing elements to be added to this list
* @return <tt>true</tt> if this list changed as a result of the call
* @throws NullPointerException if the specified collection is null
*/
public boolean addAll(Collection<? extends E> c) {
// 将集合c转为数组
Object[] a = c.toArray();
int numNew = a.length;
// 检查是否需要扩容
ensureCapacityInternal(size + numNew); // Increments modCount
// 将c中元素全部拷贝到数组的最后
System.arraycopy(a, 0, elementData, size, numNew);
// 集合中元素的大小增加c的大小
size += numNew;
// 如果c不为空就返回true,否则返回false
return numNew != 0;
}
执行流程:
- 拷贝c中的元素到数组a中;
- 检查是否需要扩容;
- 把数组a中的元素拷贝到elementData的尾部;
get(int index)获取指定索引位置的元素
获取指定索引位置的元素,时间复杂度为O(1)。
/**
* Returns the element at the specified position in this list.
* * @param index index of the element to return
* @return the element at the specified position in this list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
// 检查是否越界
rangeCheck(index);
// 返回数组index位置的元素
return elementData(index);
}
/**
* Checks if the given index is in range. If not, throws an appropriate
* runtime exception. This method does *not* check if the index is
* negative: It is always used immediately prior to an array access,
* which throws an ArrayIndexOutOfBoundsException if index is negative.
* 检查给定的索引是否在集合有效元素数量范围内
*/
private void rangeCheck(int index) {
if (index >= size)
throw new IndexOutOfBoundsException(outOfBoundsMsg(index));
}
@SuppressWarnings("unchecked")
E elementData(int index) {
return (E) elementData[index];
}
执行流程:
- 检查索引是否越界,这里只检查是否越上界,如果越上界抛出IndexOutOfBoundsException异常,如果越下界抛出的是ArrayIndexOutOfBoundsException异常。
- 返回索引位置处的元素;
remove(int index)删除指定索引位置的元素
删除指定索引位置的元素,时间复杂度为O(n)。
/**
* Removes the element at the specified position in this list.
* Shifts any subsequent elements to the left (subtracts one from their
* indices).
* 删除指定索引位置的元素,时间复杂度为O(n)。
* * @param index the index of the element to be removed
* @return the element that was removed from the list
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E remove(int index) {
// 检查是否越界
rangeCheck(index);
// 集合底层数组结构修改次数+1
modCount++;
// 获取index位置的元素
E oldValue = elementData(index);
int numMoved = size - index - 1;
// 如果index不是最后一位,则将index之后的元素往前挪一位
if (numMoved > 0)
// **进行了size-索引index-1次操作**
System.arraycopy(elementData, index + 1, elementData, index,
numMoved);
// 将最后一个元素删除,帮助GC
elementData[--size] = null; // clear to let GC do its work
// 返回旧值
return oldValue;
}
执行流程:
- 检查索引是否越界;
- 获取指定索引位置的元素;
- 如果删除的不是最后一位,则其它元素往前移一位;
- 将最后一位置为null,方便GC回收;
- 返回删除的元素。
注意:从源码中得出,ArrayList删除元素的时候并没有缩容。
remove(Object o)删除指定元素值的元素
删除指定元素值的元素,时间复杂度为O(n)。
/**
* Removes the first occurrence of the specified element from this list,
* if it is present. If the list does not contain the element, it is
* unchanged. More formally, removes the element with the lowest index
* <tt>i</tt> such that
* <tt>(o==null ? get(i)==null : o.equals(get(i)))</tt>
* (if such an element exists). Returns <tt>true</tt> if this list
* contained the specified element (or equivalently, if this list
* changed as a result of the call).
* 删除指定元素值的元素,时间复杂度为O(n)。
* * @param o element to be removed from this list, if present
* 要从此列表中删除的元素(如果存在的话)
* @return <tt>true</tt> if this list contained the specified element
*/
public boolean remove(Object o) {
if (o == null) {
// 遍历整个数组,找到元素第一次出现的位置,并将其快速删除
for (int index = 0; index < size; index++)
// 如果要删除的元素为null,则以null进行比较,使用==
if (elementData[index] == null) {
fastRemove(index);
return true;
}
} else {
// 遍历整个数组,找到元素第一次出现的位置,并将其快速删除
for (int index = 0; index < size; index++)
// 如果要删除的元素不为null,则进行比较,使用equals()方法
if (o.equals(elementData[index])) {
fastRemove(index);
return true;
}
}
return false;
}
/*
* Private remove method that skips bounds checking and does not
* return the value removed.
* 专用的remove方法,跳过边界检查,并且不返回删除的值。
*/
private void fastRemove(int index) {
// 少了一个越界的检查
modCount++;
// 如果index不是最后一位,则将index之后的元素往前挪一位
int numMoved = size - index - 1;
if (numMoved > 0)
System.arraycopy(elementData, index + 1, elementData, index,
numMoved);
// 将最后一个元素删除,帮助GC
elementData[--size] = null; // clear to let GC do its work
}
执行流程:
- 找到第一个等于指定元素值的元素;
- 快速删除;
fastRemove(int index)相对于remove(int index)少了检查索引越界的操作,可见jdk将性能优化到极致。
retainAll(Collection c)求两个集合的交集
/**
* 求两个集合的交集
* Retains only the elements in this list that are contained in the
* specified collection. In other words, removes from this list all
* of its elements that are not contained in the specified collection.
* * @param c collection containing elements to be retained in this list
* @return {@code true} if this list changed as a result of the call
* @throws ClassCastException if the class of an element of this list
* is incompatible with the specified collection
* (<a href="Collection.html#optional-restrictions">opti
* @throws NullPointerException if this list contains a null element and the
* specified collection does not permit null elements
* (<a href="Collection.html#optional-restrictions">opti
* or if the specified collection is null
* @see Collection#contains(Object)
*/
public boolean retainAll(Collection<?> c) {
// 集合c不能为null
Objects.requireNonNull(c);
// 调用批量删除方法,这时complement传入true,表示删除不包含在c中的元素
return batchRemove(c, true);
}
/**
* 批量删除元素
* complement为true表示删除c中不包含的元素
* complement为false表示删除c中包含的元素
* @param c
* @param complement
* @return
*/
private boolean batchRemove(Collection<?> c, boolean complement) {
final Object[] elementData = this.elementData;
/**
* 使用读写两个指针同时遍历数组
* 读指针每次自增1,写指针放入元素的时候才加1
* 这样不需要额外的空间,只需要在原有的数组上操作就可以了
*/
int r = 0, w = 0;
boolean modified = false;
try {
// 遍历整个数组,如果c中包含该元素,则把该元素放到写指针的位置(以complement为准)
for (; r < size; r++)
if (c.contains(elementData[r]) == complement)
elementData[w++] = elementData[r];
} finally {
// 正常来说r最后是等于size的,除非c.contains()抛出了异常
if (r != size) {
// 如果c.contains()抛出了异常,则把未读的元素都拷贝到写指针之后
System.arraycopy(elementData, r,
elementData, w,
size - r);
w += size - r;
}
if (w != size) {
// 将写指针之后的元素置为空,帮助GC
for (int i = w; i < size; i++)
elementData[i] = null;
modCount += size - w;
// 新大小等于写指针的位置(因为每写一次写指针就加1,所以新大小正好等于写指针的位置)
size = w;
modified = true;
}
}
// 有修改返回true
return modified;
}
执行流程:
- 遍历elementData数组;
- 如果元素在c中,则把这个元素添加到elementData数组的w位置并将w位置往后移一位;
- 遍历完之后,w之前的元素都是两者共有的,w之后(包含)的元素不是两者共有的;
- 将w之后(包含)的元素置为null,方便GC回收;
ArrayList所使用的toString()方法分析:
我们都知道ArrayList集合是可以直接使用toStrin()方法的,那么我们来挖一下ArrayList的toString方法如何实现的:
在ArrayList源码中并没有直接的toString()方法,我们需要到其父类AbstractList的父类AbstractCollection中寻找:
/**
* Returns a string representation of this collection. The string
* representation consists of a list of the collection's elements in the
* order they are returned by its iterator, enclosed in square brackets
* (<tt>"[]"</tt>). Adjacent elements are separated by the characters
* <tt>", "</tt> (comma and space). Elements are converted to strings as
* by {@link String#valueOf(Object)}.
*
* @return a string representation of this collection
*/
public String toString() {
Iterator<E> it = iterator();// 获取迭代器
if (! it.hasNext())//如果为空直接返回
return "[]";
// StringBuilder进行字符串拼接
StringBuilder sb = new StringBuilder();
sb.append('[');
for (;;) {// 无限循环 == while(true)
E e = it.next();// 迭代器 next方法取元素,并将光标后移
sb.append(e == this ? "(this Collection)" : e);// 三元判断
if (! it.hasNext())
return sb.append(']').toString();// 没有元素了,则拼接右括号
sb.append(',').append(' ');// 还有元素存在
}
}
















 1510
1510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











