







多道程序
- 在内存中可以同时存在多个进程
- 在满足某些条件的情况下,可以让执行流在这些进程之间切换
上下文切换
在之前实现的系统调用中,假设进程A 运行的过程中触发了系统调用,ecall指令陷入到内核,此时根据 __am_asm_trap() 的代码,A 的上下文结构将会被保存到 A 的栈上,系统调用处理完毕之后,__am_asm_trap() 会根据栈上保存的上下文结构来恢复 A 的上下文。要实现执行流在进程之间的切换,我们在系统调用处理完毕之后,__am_asm_trap() 就不着急恢复 A 的上下文,而是先将栈顶指针切换到另一个进程 B 的栈上,由于 B 的栈上存放了之前 B 保存的上下文结构,接下来的操作就会根据这一结构来恢复 B 的上下文。于是从 __am_asm_trap() 返回之后,我们已经在运行进程 B 了。
进程控制块PCB
用一个 cp 指针来记录上下文结构的位置,当想要找到其它进程的上下文结构的时候,只要寻找这个进程相关的 cp 指针即可。我们需要一个 cp 指针来记录上下文结构的位置,当想要找到其它进程的上下文结构的时候,只要寻找这个进程相关的 cp 指针即可。
PCB是一个联合体,提供一种方法可以选择不同的数据结构之一来进行存储
对于刚刚加载完的进程,只需要在进程的栈上人工创建一个上下文结构,使得将来切换的时候可以根据这个结构来正确地恢复上下文即可
这样的执行流有一个专门的名称,叫内核线程
创建内核线程上下文
| |
+---------------+ <---- kstack.end
| |
| context |
| |
+---------------+ <--+
| | |
| | |
| | |
| | |
+---------------+ |
| cp | ---+
+---------------+ <---- kstack.start
| |其中kstack是栈的范围, entry是内核线程的入口, arg则是内核线程的参数. 你需要在kstack的底部创建一个以entry为返回地址的上下文结构(目前你可以先忽略arg参数), 然后返回这一结构的指针.
根据栈的结构图,kstack.end是高地址,我们用kstack.end减去Context的大小,就可以得到栈中上下文结构体指针的起始地址,上下文结构存储在地址为kstack.end-sizeof(Context) ---- kstack.end 这一内存中
我们需要在 kstack 的底部创建一个以 entry 为返回地址的上下文结构,然后返回这一结构的指针
Context *kcontext(Area kstack, void (*entry)(void *), void *arg) {
Context *kctx = (Context *)(kstack.end-sizeof(Context));
kctx->empc=(uintptr_t) entry;
return kctx;
} 在Nanos-lite中, 我们可以通过一个context_kload()函数来进行进一步的封装: 它会调用kcontext()来创建上下文, 并把返回的指针记录到PCB的cp中:
void context_kload(PCB *pcb, void (*entry)(void *), void *arg) {
Area stack;
stack.start = pcb->stack;
stack.end = pcb->stack + STACK_SIZE;
pcb->cp = kcontext(stack, entry, arg);
}线程 / 进程调度
上下文的创建和切换是 CTE 的工作,而具体切换到哪个上下文,则是由操作系统来决定的,这项任务叫做进程调度
进程调度是由 schedule() 函数来完成,讲义直接把代码给出来了
- current->cp = prev; 保存当前正在运行的进程的上下文信息,以备将来切换回来,此时current可以是pcb[0],pcb[1],pcb[2]...
current = &pcb[0]:这一行将current指针指向pcb[0],也就是选择了要运行的下一个进程return current->cp:最后,函数返回了新选择的进程的上下文指针,以便在上下文切换之后从新进程的上下文中继续执行
Context* schedule(Context *prev) {
// save the context pointer
current->cp = prev;
// always select pcb[0] as the new process
current = &pcb[0];
// then return the new context
return current->cp;
}修改CTE中__am_asm_trap()的实现, 使得从__am_irq_handle()返回后, 先将栈顶指针切换到新进程的上下文结构, 然后才恢复上下文, 从而完成上下文切换的本质操作.
这一个任务中, 我们需要知道注册的user_handler其实就是irq.c里面的do_event函数, 它返回的上下文指针就是当前的我们即将要运行的进程的上下文, 并且还需要知道返回值是存储在a0寄存器里面, 栈顶指针是sp寄存器, 知道这些后这个任务就很简单了, 一行汇编代码就搞定了
--- abstract-machine/am/src/riscv/nemu/trap.S
+++ abstract-machine/am/src/riscv/nemu/trap.S
@@ -49,6 +49,7 @@ __am_asm_trap:
mv a0, sp
jal __am_irq_handle
+ mv sp, a0
LOAD t1, OFFSET_STATUS(sp)
LOAD t2, OFFSET_EPC(sp)实现上下文切换(2)
- 修改CTE的
kcontext()函数, 使其支持参数arg的传递
让
kcontext()按照调用约定将arg放置在正确的位置, 将来hello_fun()执行的时候就可以获取正确的参数RISC-V 调用约定:
在 RISC-V 中,常见的参数传递方式包括将参数放在通用寄存器中,通常是
a0到a7。如果参数数量较多,还可以使用栈来传递。一般规则如下:
a0到a7用于传递整数参数。f0到f7用于传递浮点参数。- 参数按照从左到右的顺序传递。
- 如果参数太多,会将其余参数放在栈上。
根据调用约定,我们把
arg放到a0寄存器即可,将来函数从__am_irq_handle()返回后,就会根据PCB切换到hello_fun执行。在函数hello_fun内部,使用a0寄存器来访问传递的参数值。如果需要传递多个参数,通常会将它们放在a0到a7寄存器中
Context *kcontext(Area kstack, void (*entry)(void *), void *arg) {
Context *kctx = (Context *)(kstack.end-sizeof(Context));
kctx->mepc=(uintptr_t) entry;
kctx->GPR2 = (uintptr_t)arg;//GPR2-> a0 -> gpr[10]
return kctx;
}- 通过
kcontext()创建第二个以hello_fun()为入口的内核线程, 并传递不同的参数
void init_proc() {
context_kload(&pcb[0], hello_fun, "A");
context_kload(&pcb[1], hello_fun, "B");
switch_boot_pcb();
...在hello_fun 以字符串的形式解析内核线程的参数 ( (const char *)arg )
- 修改Nanos-lite的
schedule()函数, 使其轮流返回两个上下文
Context* schedule(Context *prev) {
// save the context pointer
current->cp = prev;
current = ((current == &pcb[0]) ? &pcb[1] : &pcb[0]);
// then return the new context
return current->cp;
}用户进程
做到这里笔者对用户进程又有了不一样的理解, 用户进程的代码, 数据和堆栈都应该位于用户区, 而且需要保证用户进程能且只能访问自己的代码, 数据和堆栈. 为了区别开来, 我们把PCB中的栈称为内核栈, 位于用户区的栈称为用户栈.
进程控制块(PCB)通常是在系统启动时就创建好的。在没有进程加载的时候,系统会预留一些数据结构用于存储进程的信息,其中就包括了 PCB。这样,在进程被加载之前,系统就已经准备好了管理进程的数据结构。
当一个进程被加载到系统中时,会在其对应的 PCB 中分配一块栈空间,并将进程的上下文信息(如寄存器状态等)保存到这个栈空间中。这个栈空间是为了在进程切换时暂存和恢复上下文而设计的。另一方面,加载的进程会有自己的独立栈空间,用于存储函数调用的局部变量、临时数据等。这个独立的栈空间是用于实际执行进程代码的地方。PCB 中的栈空间是一个用于保存上下文信息的缓冲区,而加载的进程有自己的独立栈空间,用于实际的执行。
PCB 栈:
- 上下文信息: PCB 栈主要用于保存进程的上下文,包括寄存器的值(例如,通用寄存器、程序计数器等)。
- 进程状态: 保存进程的状态,例如就绪、运行、阻塞等。
- 调度信息: 可能包括进程的优先级、时间片大小等调度相关的信息。
用户栈:
- 局部变量: 函数内部声明的变量会存储在实际栈上。
- 函数参数: 被调用函数的参数通常也存储在实际栈上。
- 返回地址: 当函数被调用时,返回地址会被存储在实际栈上,以便函数执行完毕后返回到调用者。
- 临时数据: 函数执行期间产生的临时数据也存储在实际栈上。
回顾PA3的知识,nanos-lite执行用户程序的流程是怎样的
在nanos-lite在main函数中,调用init_proc(),在PA3中,init_proc()会调用naive_uload()从而通过loader()来把用户程序加载到正确的内存位置, 然后执行用户程序
#ifdef HAS_CTE//此时已经定义
init_irq();
#endif
init_fs();
init_proc();
。
Log("Finish initialization");
#ifdef HAS_CTE
yield();naive_uload()的代码可以看出,通过loader返回了用户程序的入口entry,((void(*)())entry) ();将 entry 强制类型转换为函数指针,然后立即调用该函数
void naive_uload(PCB *pcb, const char *filename) {
uintptr_t entry = loader(pcb, filename);
Log("Jump to entry = %p", entry);
((void(*)())entry) ();
}用户程序的入口位于navy-apps/libs/libos/src/crt0/start/riscv32.S中的_start()函数,_start()函数会调用navy-apps/libs/libos/src/crt0/crt0.c中的call_main()函数
.globl _start
_start:
move s0, zero
jal call_main
然后调用用户程序的main()函数, 从main()函数返回后会调用exit()结束运行
int main(int argc, char *argv[], char *envp[]);
extern char **environ;
void call_main(uintptr_t *args) {
char *empty[] = {NULL };
environ = empty;
exit(main(0, empty, empty));
assert(0);
}
通过函数调用转移到用户进程的代码, 那时候使用的还是内核区的栈, 万一发生了栈溢出, 确实会损坏操作系统的数据,在多道程序操作系统中, 系统中运行的进程就不止一个了, 如果让用户进程继续使用内核区的栈, 万一发生了栈溢出, 就会影响到其它进程的运行
因此, 和内核线程不同, 用户进程的代码, 数据和堆栈都应该位于用户区, 而且需要保证用户进程能且只能访问自己的代码
用户进程需要一个合适的状态来开始执行。这个状态通常包括以下几个方面:
-
程序计数器(PC)的值:指向用户程序的入口点,即用户程序要开始执行的位置。
-
用户栈指针:指向用户进程的用户栈顶,用于管理用户进程的函数调用和局部变量等。
-
数据段指针:指向用户进程的数据区,用于存储全局变量和静态变量等数据。
-
堆指针:指向用户进程的堆区,用于动态分配内存。
-
寄存器状态:包括通用寄存器和特殊目的寄存器等,确保用户进程开始执行时的寄存器状态是正确的。
这些状态的准备工作通常通过初始化上下文结构来完成,当用户进程开始执行时,它需要处于一个可以顺利执行的状态,以便正确地执行用户程序的指令和处理相应的数据。
ucontext()实现和 kcontext() 几乎一样
Context *ucontext(AddrSpace *as, Area kstack, void *entry) {
Context *uctx = (Context *)(kstack.end-sizeof(Context));
uctx->mepc=(uintptr_t) entry;
return uctx;
}Nanos-lite把heap.end作为用户进程的栈顶,然后把栈顶位置设置到GPRx中, 然后由Navy里面的_start来把栈顶位置真正设置到栈指针寄存器中,但是注意用户进程的上下文,即context的mepc指针是在PCB栈中的,而不是用户栈中,意思就是说在这里传入uncontext()的参数是PCB的stack而不是用户栈(heap).在context_uload实现这一思路
void context_uload(PCB *pcb, const char *filename) {
//这里用PCB的stack
Area stack;
stack.start = pcb->stack;
stack.end = pcb->stack + STACK_SIZE;
uintptr_t entry = loader(pcb, filename);
pcb->cp = ucontext(NULL, stack, (void*)entry);
//这里用heap,表示用户栈
pcb->cp->GPRx = (uintptr_t) heap.end;
}将栈顶位置存到 GPRx 后,恢复上下文时就可以保证 GPRx 中就是栈顶位置,紧接着就是用户进程的 _start:
.globl _start
_start:
move s0, zero
# set heap.end to the stack pointer register
mv sp, a0
jal call_main总体来说,通过 context_uload()加载进程到系统中,当nanos-lite执行到yield()后,就会执行__am_asm_trap(),在__am_asm_trap()中的__am_irq_handle()就会把 context_uload()创造的用户进程上下文返回,__am_asm_trap()会根据这个上下文的cp指针通过crsw指令解析出我们设置好的mepc和GPRx,然后根据mepc也就是设置的用户程序入口entry就会走到navy的_srart,并根据GPRx的值赋值给sp栈指针寄存器,然后就可以执行用户程序了
一山不能藏二虎?
编译Navy-apps中的程序时, 我们都把它们链接到0x83000000的内存位置(见navy-apps/scripts/$ISA.mk中的LDFLAGS变量)., 我们在加载第二个用户进程的时候, 就会覆盖第一个进程的内容
给用户进程传递参数
用户进程的上下文(mepc指针等)存储在PCB栈,而函数参数之类的数据存储在用户栈,PCB栈和用户栈是完全分开的,进程加载后只会把上下文放进PCB中,数据还是在自己的用户栈。这里要求要传参数给函数,就把这些数据放用户栈(heap),然后在call_main中从用户栈中拿这些信息,之后调用main
void context_uload(PCB *pcb, const char *filename, char *const argv[], char *const envp[]) {
// 定义用户栈的区域
Area stack;
stack.start = pcb->stack;
stack.end = pcb->stack + STACK_SIZE;
// 调用 loader 函数加载用户程序,获取入口地址
uintptr_t entry = loader(pcb, filename);
// 计算 argc、envc 的值
int argc = 0;
while (argv[argc] != NULL) argc++;
int envc = 0;
while (envp[envc] != NULL) envc++;
// 分配用户栈空间,用于存储 argv 和 envp 指针
uintptr_t* user_stack = (uintptr_t*)heap.end;
// 将 argv 字符串逆序拷贝到用户栈
for (int i = argc - 1; i >= 0; i--) {
size_t len = strlen(argv[i]) + 1; // 包括 null 终止符
user_stack -= len;
strncpy((char*)user_stack, argv[i], len);
}
// 对齐到 uintptr_t 边界
user_stack = (uintptr_t*)((uintptr_t)user_stack & ~(sizeof(uintptr_t) - 1));
// 将 envp 字符串逆序拷贝到用户栈
for (int i = envc - 1; i >= 0; i--) {
size_t len = strlen(envp[i]) + 1; // 包括 null 终止符
user_stack -= len;
strncpy((char*)user_stack, envp[i], len);
}
// 对齐到 uintptr_t 边界
user_stack = (uintptr_t*)((uintptr_t)user_stack & ~(sizeof(uintptr_t) - 1));
// 将 argv 和 envp 指针拷贝到用户栈
user_stack -= (argc + envc + 4); // +4 为 NULL 结尾和 argc/envc 的值
uintptr_t* user_argv = user_stack;
// 设置 argc 的值
user_stack[0] = argc;
// 设置 argv 指针
for (int i = 0; i < argc; i++) {
user_stack[i + 1] = (uintptr_t)heap.end - (argc - i - 1) * sizeof(uintptr_t);
}
// 设置 argv 的 NULL 终止符
user_stack[argc + 1] = 0;
// 设置 envc 的值
user_stack[argc + 2] = envc;
// 设置 envp 指针
for (int i = 0; i < envc; i++) {
user_stack[argc + 3 + i] = (uintptr_t)heap.end - (argc + 3 + envc - i - 1) * sizeof(uintptr_t);
}
// 设置 envp 的 NULL 终止符
user_stack[argc + 3 + envc] = 0;
// 调用 ucontext 函数创建用户上下文,传入入口地址和用户栈
pcb->cp = ucontext(pcb->cp, stack, (void*)entry);
// 将用户栈的顶部地址赋给 GPRx 寄存器
pcb->cp->GPRx = (uintptr_t)user_stack;
}_start已经把ao(GPRX,即用户栈的栈顶)赋值给sp寄存器,让call_main可以使用
在call_main函数中,你需要从传递的参数args中解析出真正的argc/argv/envp,这里用到了字符串数组,即指向字符指针的指针(char **),在C语言中,一个字符串通常是以字符数组的形式表示的,以 null 结尾,这个字符数组的地址通常由一个指向字符的指针(char *)来表示。而一个字符串数组实际上就是一个包含多个字符串的数组,每个字符串是一个字符数组。char ** 表示一个指针,该指针指向其他指针,而这些指针又指向字符
这里argv和envp都是字符串数组,所以用(char **)
void call_main(uintptr_t *args) {
// 从参数中获取argc的值
int argc = (int)args[0];
// 从参数中获取argv的地址
char **argv = (char **)(args + 1);
// 从参数中获取envp的地址
char **envp = (char **)(args + argc + 1);
// 设置environ为envp
environ = envp;
// 调用main函数
exit(main(argc, argv, envp));
assert(0);
}实现带参数的execve()
我们之前给用户进程传递参数是在nanos-lite/src/proc.c的init_proc()函数中调用context_uload()把用户进程加载进系统的时候传递了参数,这是我们在操作系统层实现的(nanos-lite),我们需要在用户层实现,即在navy的用户程序上通过调用 execve()进而触发_execve()系统调用,这个过程为
用户进程 A 执行到 SYS_execve 调用: 在用户进程 A 执行过程中,如果遇到了 SYS_execve 系统调用,那么 A 希望加载并执行另一个程序 B。
Nanos-lite 处理 SYS_execve: 当系统调用处理程序
sys_execve()在内核中运行时,它会调用context_uload()函数,该函数负责准备用户进程 B 的执行环境。新用户栈的分配: 由于 A 的用户栈不能被 B 复用,
context_uload()会通过new_page()函数分配一段新的内存,用作用户进程 B 的用户栈。参数的拷贝:
context_uload()负责将参数(例如 argv、envp)拷贝到新的用户栈中,以便用户进程 B 可以正确访问这些参数。用户进程 B 的创建: 因为当前进程的内核栈是空的,所以
context_uload()调用ucontext()并传入current指针创建用户进程 B 的上下文,并设置其初始状态。其实也就是B 可以安全使用 A 在 PCB 中的内核栈,但是B的用户栈必须靠自己申请。切换到用户进程 B: 用户进程 B 创建完毕后,调用
switch_boot_pcb()修改当前的current指针,为的是在之后的yield中保存当前A进程的上下文到pcb_boot进程调度: 调用
yield()或者触发调度器的功能,首先是把A进程上下文赋值给当前current(pcb_boot),然后会在下一次调度时选择用户进程 B 来执行。用户进程 B 执行完毕: 当用户进程 B 执行完毕时,可能会发生进程退出或者其他的终止条件。
返回用户进程 A: 在用户进程 B 执行结束后,调度器会再次被触发,选择用户进程 A 来执行。此时,之前保存的 A 的状态会被恢复,从上一次执行的位置继续执行。
首先修改context_uload(),这个函数笔者放在loader.c,因为函数内部要调用loader(),把之前的heap改成调用new_page()
// 分配用户栈空间,用于存储 argv 和 envp 指针
uintptr_t* user_stack = (uintptr_t*)new_page(8);PGSIZE 为 4KB
void* new_page(size_t nr_page) {
pf += nr_page * PGSIZE;
return pf;
}用户层
int _execve(const char *fname, char * const argv[], char *const envp[]) {
return _syscall_(SYS_execve, (intptr_t)fname, (intptr_t)argv, (intptr_t)envp);
}操作系统部分(软件层)
case SYS_execve:
sys_execve((const char *)c->GPR2, (char * const*)c->GPR3, (char * const*)c->GPR4);
while(1);系统调用处理函数
int sys_execve(const char *fname, char *const argv[], char *const envp[]) {
context_uload(current, fname, argv, envp);
switch_boot_pcb();
yield();
return -1;
}虚实交错的魔法
分段
在计算机内存管理中,段(Segment)是一种将程序的地址空间划分为不同区域的机制。每个段通常包含一组相关的数据或代码,并且每个段都有自己的基址(Segment Base)和长度(Segment Limit)。这种机制被称为分段机制,用于划分和管理程序的地址空间。
当程序被加载到内存时,操作系统负责将程序的各个段加载到内存中的不同位置。加载的过程包括将程序的代码段、数据段等加载到相应的内存地址,使得程序可以在运行时访问这些段。下面是一个简化的加载过程:
程序编译: 在程序编译的过程中,编译器将源代码翻译成机器代码,并为程序的不同部分生成相应的段。
段选择: 在程序执行之前,操作系统负责分配内存并为程序的各个段选择合适的内存位置。这个过程中,为每个段分配一个基址,也就是段基址(Segment Base)。这个基址用于计算段内偏移。
加载到内存: 当程序被加载到内存时,操作系统将程序的各个段复制到相应的内存位置。这时,计算机的内存中就包含了程序的代码段、数据段等。
段基址修正: 在加载的过程中,操作系统需要修正程序中的地址引用,以确保程序中的段基址与实际加载到内存的基址相匹配。这样,程序在运行时使用的虚拟地址经过修正后,能正确映射到实际的物理内存地址。
分页
分页机制是一种将物理内存和虚拟内存划分为固定大小的页面(Page)的内存管理方案。每个页面通常是2的幂次方大小(例如4KB),并且具有唯一的页号。分页机制的核心思想是将虚拟地址空间和物理地址空间划分为相同大小的页面,并通过页表来建立虚拟地址到物理地址的映射。
页面大小的定义: 首先,定义操作系统使用的页面大小,例如4KB。这个页面大小决定了虚拟地址和物理地址空间的划分粒度。
程序编译: 在程序编译的过程中,编译器将源代码翻译成机器代码,并且将程序的地址空间划分为页面大小的块,这些块被称为页面。
页表的建立: 操作系统在运行时维护一个页表,其中包含了虚拟地址到物理地址的映射关系。每个页表项包括了一个有效位(表示该页是否有效)、页框号(物理页面的位置)等信息。
按需分配: 当程序运行时,操作系统不必一次性将整个程序加载到内存中。而是根据需要,按页将程序的不同部分加载到内存。
虚拟地址到物理地址的映射: 当程序访问虚拟地址时,CPU使用页表将虚拟地址映射到相应的物理地址。这个过程包括了从虚拟地址中提取页号和页内偏移,然后通过页表找到对应的物理页框号,最终计算得到物理地址。
在这个过程中,如果程序的某个段很大,而实际运行时只使用了其中的一小部分,仍然需要加载整个段到内存。这可能导致内存的浪费,特别是对于大型程序来说。因为在分段机制中,段的基本单位是段,而不是较小的页面。
与之相比,分页机制将内存划分为固定大小的页面,每个页面可以独立分配和管理。这允许操作系统在需要时只加载实际使用的
页面,而不必加载整个段。这提供了更灵活的内存管理方式,特别适用于按需加载的情况,避免了不必要的内存浪费。
理解i386的分页机制
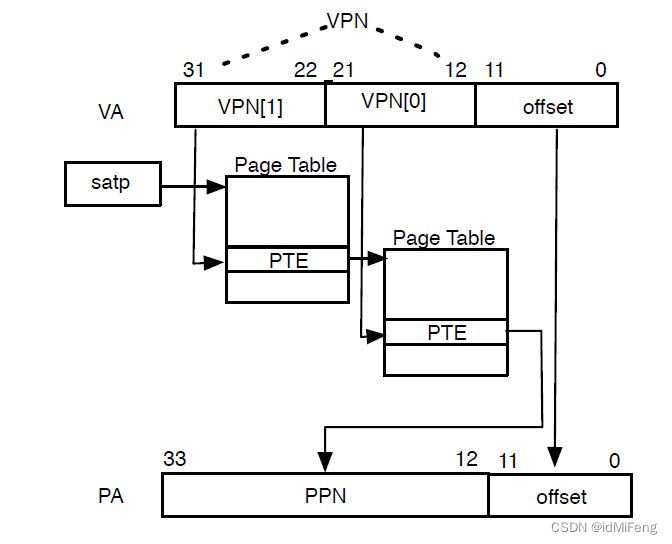
在多级页表的机制下,每个进程通常会有自己的页表结构,划分内存后,包括一个页目录(Page Directory)和多张页表(Page Tables)。每个页目录有多个表项,每个表项对应一个页表的基地址。页目录的基地址从CR3寄存器获取。
页目录:存放页表基地址
页表:存放物理页基地址
一次 Page Table Walk 的过程:
虚拟地址拆分:
- 对于32位虚拟地址,最高的10位用于索引页目录,接下来的10位用于索引页表,最低的12位用于页内偏移。
- 例如,虚拟地址
0xABCD1234的前10位(0xABCD1)用于页目录索引,接下来的10位(0x234)用于页表索引,最后的12位(0x1234)是页内偏移。页目录索引:
- 使用虚拟地址的前10位作为索引,在页目录中找到对应的页目录项。
- 这个页目录项包含了指向页表的基地址(Page Table Frame Number)和一些标志位。
页表索引:
- 使用虚拟地址的中间10位作为索引,在找到的页表中找到对应的页表项。
- 这个页表项中包含了物理页的基地址和一些标志位。
页内偏移:
- 使用虚拟地址的最后12位作为页内偏移,加上找到的页表项中的物理页基地址,得到最终的物理地址。
权限检查:
- 在这个过程中,还需要检查相应的标志位,确保访问是合法的,比如检查 PTE 的 Present 位、R/W 位以及用户态/内核态权限位等。
将虚存管理抽象成 VME
物理内存
abstract-machine/am/src/riscv/nemu/vme.c
static Area segments[] = { // Kernel memory mappings
NEMU_PADDR_SPACE
};abstract-machine/am/src/platform/nemu/include/nemu.h
#define NEMU_PADDR_SPACE \
RANGE(&_pmem_start, PMEM_END), \
RANGE(FB_ADDR, FB_ADDR + 0x200000), \
RANGE(MMIO_BASE, MMIO_BASE + 0x1000) /* serial, rtc, screen, keyboard */0x80000000 ~ 0x88000000:内核区和用户区,在无 VME 下,用户程序被链接到内存位置0x83000000附近0xa1000000 ~ 0xa1200000:显存0xa0000000 ~ 0xa0001000:其余设备
虚拟内存
abstract-machine/am/src/riscv/nemu/vme.c
#define USER_SPACE RANGE(0x40000000, 0x80000000)0x40000000 ~ 0x80000000
protect()创建一个默认的地址空间
void protect(AddrSpace *as) {
PTE *updir = (PTE*)(pgalloc_usr(PGSIZE));//调用pgalloc_usr()返回分配的物理页的首地址
as->ptr = updir; //物理页首地址也就是页目录地址赋值给ptr
as->area = USER_SPACE; //虚拟内存0x40000000 ~ 0x80000000,虚拟地址空间中用户态的范围,每个进程都会访问这一范围虚拟地址
as->pgsize = PGSIZE;//页面的大小4kb
// map kernel space
memcpy(updir, kas.ptr, PGSIZE);//将内核地址空间的内容复制到新分配的用户页目录
}内核虚拟地址空间(kas)的定义,
static AddrSpace kas = {};但是在vme_init()中,包含如下部分代码,它从segments中获取真实物理地址赋值给va,然后调用map(),且map的"va","pa"参数均传的是真实物理地址,这样在分页模式下, Nanos-lite可以把内存的物理地址直接当做虚拟地址来访问,因为它们都是相同的
kas.ptr = pgalloc_f(PGSIZE);//调用用户提供的页面分配函数 pgalloc_f 来为 kas 分配一个页4kb大小的内存,把物理页首地址即页目录地址赋值给ptr
int i;
for (i = 0; i < LENGTH(segments); i ++) {
void *va = segments[i].start;
for (; va < segments[i].end; va += PGSIZE) {
map(&kas, va, va, 0);
}
}每个进程访问这一范围的虚拟内存,需要把它映射到物理内存的访问
riscv32的Sv32 分页方案
Sv32 采用两级页表结构,页目录基地址和分页使能位都是位于satp寄存器中
satp 寄存器的位域包括 MODE、ASID(Address Space ID)、PPN(Page Table Base Physical Address)等字段。

-
MODE:
satp寄存器的最高位是 MODE,用于指定页表的模式。在 Sv32 模式下,MODE 的值为 1,表示使用两级页表结构。其他模式的定义取决于 RISC-V 的扩展。 -
ASID:Address Space ID 是用来区分不同的地址空间的标识符。ASID 的存在使得处理器能够支持多任务,因为不同的任务可以有不同的 ASID。ASID 的作用是在 TLB(Translation Lookaside Buffer,地址翻译缓冲区)中标识不同的地址空间。在同一个 ASID 下,TLB 可以缓存之前的地址翻译结果,提高效率。
-
PPN:Page Table Base Physical Address,即页表的基地址。PPN 指定了页表的物理地址。在 Sv32 模式下,页表是一个两级结构,PPN 指向第一级页表的物理地址。通过多级的页表结构,可以有效地管理和翻译大范围的虚拟地址空间。
这对应了 vme_init 在映射后 set_satp:
riscv_xlen是32,把1左移31位赋值给mode,得到MODE位,此时MODE 的值为 1,表示使用两级页表结构,pdir右移12位得到的是pdir的高20位,即一级页表的基地址,它作为PPN位,与mode按位或操作,得到32位数据赋值给satp寄存器
static inline void set_satp(void *pdir) {
uintptr_t mode = 1ul << (__riscv_xlen - 1);
asm volatile("csrw satp, %0" : : "r"(mode | ((uintptr_t)pdir >> 12)));
}页表项结构:

-
Valid(V)位:表示页表项是否有效。如果 V 为 0,说明这个页表项无效,可能是空的;如果 V 为 1,表示这个页表项有效。
-
Read(R)位、Write(W)位、Execute(X)位:这三个位表示对应页的读、写、执行权限。如果 R/W/X 为 1,表示可以读/写/执行;如果为 0,表示不可对应的操作。如果这三个位都是 0,那么这个页表项是指向下一级页表的指针,否则它是页表树的一个叶节点。
-
PPN(Physical Page Number):物理页号,指向下一级页表或者是叶子节点(基页)的物理地址。这个 PPN 只使用了低 20 位,因为 32 位地址空间只需要 20 位表示物理地址。
地址转换过程:
(一张图片解释得非常清楚!!!)
首先实现pg_alloc(),pg_alloc()的参数是分配空间的字节数,调用 new_page 分配 n 字节大小的内存,并返回这块内存的起始地址,这个起始地址用作页目录的基地址
#ifdef HAS_VME
static void* pg_alloc(int n) {
int nr_page = n / PGSIZE;
assert(nr_page * PGSIZE == n);
void *end = new_page(nr_page);
void *start = end - n;
memset(start, 0, n);
return start;
}
#endif 然后按照上述思想实现VME的map(),来填写虚拟地址空间的页目录和页表. 页表结构的组织通过页表地址的转换过程反推.通过as->ptr获取页目录的基地址. 若需要申请新的页表, 可以通过回调函数pgalloc_usr()向Nanos-lite获取一页空闲的物理页.有注释,其中PTE_V等标志位定义在abstract-machine/am/src/riscv/riscv.h
举个例子更明白一些,类似vme_init()中map()的执行过程,首先是恒等映射,那我们假设va和pa此时传入的都是0x80000000,对map()的参数pa,0x80000000的高20位被赋值给ppn也就是二级页表的页表项,对map()的参数va(也是0x80000000),提取它的高 10 位赋值给vpn_1,即一级页号,提取它的低10位赋值给vpn_0,即二级页号。然后通过as->ptr得到一级页表的基地址,加上一级页号,就得到了一级页表的页表项,此时这个地址中并没有数据,所以解引用得到0,我们要让这个页表项存着二级页表的基地址,就调用pg_alloc()分配一个物理页并把起始地址赋值给该页表项,因为它是二级页表的基地址,所以加上二级页号就得到了二级页表的页表项,此时这里也没有数据,我们就把map()的pa参数的高二十位(之前的ppn)与V /R / W / X 位等结合成物理页的基地址,存放在这个二级页表的页表项中,注意map()只是填写一级页表的页表项和二级页表的页表项,填写的内容分别是二级页表的基地址和真实物理地址的基地址,并不涉及偏移量的操作,偏移量的操作是放在硬件部分的转换函数isa_mmu_translate()处理的!
#define VA_OFFSET(addr) (addr & 0x00000FFF) //提取虚拟地址的低 12 位,即在页面内的偏移。
#define VA_VPN_0(addr) ((addr >> 12) & 0x000003FF) //提取虚拟地址的中间 10 位,即一级页号
#define VA_VPN_1(addr) ((addr >> 22) & 0x000003FF) //提取虚拟地址的高 10 位,即二级页号
#define PA_OFFSET(addr) (addr & 0x00000FFF)//提取物理地址的低 12 位,即在页面内的偏移
#define PA_PPN(addr) ((addr >> 12) & 0x000FFFFF)//提取物理地址的高 20 位,即物理页号
#define PTE_PPN 0xFFFFF000 // 31 ~ 12
void map(AddrSpace *as, void *va, void *pa, int prot) {
uintptr_t va_trans = (uintptr_t) va;
uintptr_t pa_trans = (uintptr_t) pa;
assert(PA_OFFSET(pa_trans) == 0);
assert(VA_OFFSET(va_trans) == 0);
//提取虚拟地址的二级页号和一级页号,以及物理地址的物理页号
uint32_t ppn = PA_PPN(pa_trans);
uint32_t vpn_1 = VA_VPN_1(va_trans);
uint32_t vpn_0 = VA_VPN_0(va_trans);
//获取地址空间的页表基址和一级页表的目标位置
PTE * page_dir_base = (PTE *) as->ptr;
PTE * page_dir_target = page_dir_base + vpn_1;
//如果一级页表中的页表项的地址(二级页表的基地址)为空,创建并填写页表项
if (*page_dir_target == 0) {
//通过 pgalloc_usr 分配一页物理内存,作为二级页表的基地址
PTE * page_table_base = (PTE *) pgalloc_usr(PGSIZE);
//将这个基地址填写到一级页表的页表项中,同时设置 PTE_V 表示这个页表项是有效的。
*page_dir_target = ((PTE) page_table_base) | PTE_V;
//计算在二级页表中的页表项的地址
PTE * page_table_target = page_table_base + vpn_0;
//将物理页号 ppn 左移 12 位,即去掉低 12 位的偏移,与权限标志 PTE_V | PTE_R | PTE_W | PTE_X 组合,填写到二级页表的页表项中。
*page_table_target = (ppn << 12) | PTE_V | PTE_R | PTE_W | PTE_X;
} else {
//取得一级页表项的内容,然后 & PTE_PPN 通过按位与操作提取出页表的基地址,提取高20位,低 12 位为零
PTE * page_table_base = (PTE *) ((*page_dir_target) & PTE_PPN);
//通过加上 vpn_0 计算得到在二级页表中的目标项的地址
PTE * page_table_target = page_table_base + vpn_0;
//将物理页号 ppn 左移 12 位,即去掉低 12 位的偏移,与权限标志 PTE_V | PTE_R | PTE_W | PTE_X 组合,填写到二级页表的目标项中。
*page_table_target = (ppn << 12) | PTE_V | PTE_R | PTE_W | PTE_X;
}
}在NEMU中实现分页机制
在 riscv32_CPU_state 结构体要添加 satp 寄存器
typedef struct {
word_t mcause;
vaddr_t mepc;
word_t mstatus;
word_t mtvec;
word_t satp;
} riscv32_CSRs;
typedef struct {
word_t gpr[32];
vaddr_t pc;
riscv32_CSRs csr;
} riscv32_CPU_state;nemu/src/isa/riscv32/inst.c
static vaddr_t *csr_register(word_t imm) {
switch (imm)
{
case 0x341: return &(cpu.csr.mepc);
case 0x342: return &(cpu.csr.mcause);
case 0x300: return &(cpu.csr.mstatus);
case 0x305: return &(cpu.csr.mtvec);
case 0x180: return &(cpu.csr.satp);
default: panic("Unknown csr");
}
}实现isa_mmu_check()(在nemu/src/isa/$ISA/include/isa-def.h中定义) 和isa_mmu_translate()(在nemu/src/isa/$ISA/system/mmu.c中定义)
以下是文档介绍
int isa_mmu_check(vaddr_t vaddr, int len, int type);检查当前系统状态下对内存区间为
[vaddr, vaddr + len), 类型为type的访问是否需要经过地址转换. 其中type可能为:
MEM_TYPE_IFETCH: 取指令MEM_TYPE_READ: 读数据MEM_TYPE_WRITE: 写数据函数返回值可能为:
MMU_DIRECT: 该内存访问可以在物理内存上直接进行MMU_TRANSLATE: 该内存访问需要经过地址转换MMU_FAIL: 该内存访问失败, 需要抛出异常(如RISC架构不支持非对齐的内存访问)paddr_t isa_mmu_translate(vaddr_t vaddr, int len, int type);对内存区间为
[vaddr, vaddr + len), 类型为type的内存访问进行地址转换. 函数返回值可能为:
pg_paddr|MEM_RET_OK: 地址转换成功, 其中pg_paddr为物理页面的地址(而不是vaddr翻译后的物理地址)MEM_RET_FAIL: 地址转换失败, 原因包括权限检查失败等不可恢复的原因, 一般需要抛出异常MEM_RET_CROSS_PAGE: 地址转换失败, 原因为访存请求跨越了页面的边界
isa_mmu_check(),检查 satp 寄存器的 MODE 域即可:
#define isa_mmu_check(vaddr, len, type) ((((cpu.satp & 0x80000000) >> 31) == 1) ? MMU_TRANSLATE : MMU_DIRECT)
isa_mmu_translate(),首先从 satp 寄存器获取页表的基址,然后按照页表的层次结构逐级访问,最终计算出物理地址。在这个过程中,函数还会进行一系列的合法性检查,确保地址转换的正确性。如果发现某个表项无效,或者权限不足,函数将触发断言失败。
#define VA_OFFSET(addr) (addr & 0x00000FFF)
#define VA_VPN_0(addr) ((addr >> 12) & 0x000003FF)
#define VA_VPN_1(addr) ((addr >> 22) & 0x000003FF)
#define PTE_V(item) (item & 0x1)
#define PTE_R(item) ((item >> 1) & 0x1)
#define PTE_W(item) ((item >> 2) & 0x1)
#define PTE_X(item) ((item >> 3) & 0x1)
#define PTE_PPN(item) ((item >> 12) & 0xFFFFF)
typedef vaddr_t PTE;
typedef uint32_t rtlreg_t;
paddr_t isa_mmu_translate(vaddr_t vaddr, int len, int type) {
// 从 satp 寄存器获取页表基址
rtlreg_t satp = cpu.csr.satp;
PTE page_dir_base = satp << 12;
// 提取虚拟地址中的偏移、一级页号和二级页号
uint32_t offset = VA_OFFSET(vaddr);
uint32_t vpn_1 = VA_VPN_1(vaddr);
uint32_t vpn_0 = VA_VPN_0(vaddr);
// 计算一级页表项的地址
PTE page_dir_target = page_dir_base + vpn_1 * 4;
// 读取一级页表项的内容
word_t page_dir_target_item = paddr_read(page_dir_target, 4);
// 检查一级页表项是否有效,否则断言失败
if (PTE_V(page_dir_target_item) == 0) assert(0);
// 计算二级页表的基址
PTE page_table_base = PTE_PPN(page_dir_target_item) << 12;
// 计算二级页表项的地址
PTE page_table_target = page_table_base + vpn_0 * 4;
// 读取二级页表项的内容
word_t page_table_target_item = paddr_read(page_table_target, 4);
// 检查二级页表项是否有效,否则断言失败
if (PTE_V(page_table_target_item) == 0) assert(0);
// 根据访存类型检查权限位
switch (type) {
case MEM_TYPE_IFETCH: if (PTE_X(page_table_target_item) == 0) assert(0); break;
case MEM_TYPE_READ: if (PTE_R(page_table_target_item) == 0) assert(0); break;
case MEM_TYPE_WRITE: if (PTE_W(page_table_target_item) == 0) assert(0); break;
default: assert(0); break;
}
// 计算物理地址
paddr_t ppn = PTE_PPN(page_table_target_item) << 12;
paddr_t paddr = ppn | offset;
// 检查计算的物理地址是否与虚拟地址相等,否则断言失败
assert(paddr == vaddr);
return paddr;
} 在客户程序运行的过程中, 总是使用vaddr_read()和vaddr_write() (在nemu/src/memory/vaddr.c中定义)来访问模拟的内存,所以要修改 vaddr.c,type为MMU_TRANSLATE需要进行地址转换再访问
word_t vaddr_ifetch_or_read(vaddr_t addr, int len, int type) {
int flag = isa_mmu_check(addr, len, type);
paddr_t paddr = addr;
switch (flag) {
case MMU_DIRECT:
// do nothing
break;
case MMU_TRANSLATE:
paddr = isa_mmu_translate(addr, len, type); // assert in isa_mmu_translate
break;
case MMU_FAIL:
assert(0);
}
return paddr_read(paddr, len);
}
word_t vaddr_ifetch(vaddr_t addr, int len) {
return vaddr_ifetch_or_read(addr, len, MEM_TYPE_IFETCH);
}
word_t vaddr_read(vaddr_t addr, int len) {
return vaddr_ifetch_or_read(addr, len, MEM_TYPE_READ);
}
void vaddr_write(vaddr_t addr, int len, word_t data) {
int flag = isa_mmu_check(addr, len, MEM_TYPE_WRITE);
paddr_t paddr = addr;
switch (flag) {
case MMU_DIRECT:
// do nothing
break;
case MMU_TRANSLATE:
paddr = isa_mmu_translate(addr, len, MEM_TYPE_WRITE); // assert in isa_mmu_translate
break;
case MMU_FAIL:
assert(0);
}
paddr_write(paddr, len, data);
}在分页机制上运行用户进程
(这部分有歧义,自己太菜了,以后有空再看看,唉...)
硬件中断
mstatus寄存器的位

MIE位:在mstatus寄存器的第3位MPIE位:在mstatus寄存器的第7位在处理异常或中断时,为了避免在异常处理过程中发生新的中断,系统通常会禁用中断(将
MIE置为0)。而MPIE则用于保存在进入异常处理之前的中断使能状态,以便在退出异常处理时能够还原这个状态,保持中断处理的一致性。具体的操作流程如下:
- 异常或中断处理前,将
MIE的值保存到MPIE。- 将
MIE置为0,禁用中断。- 执行异常或中断处理。
- 处理结束后,将
MIE恢复为MPIE的值,以还原之前的中断使能状态
实现抢占多任务
在 cpu_exec() 中 for 循环的末尾添加轮询 INTR 引脚的代码,每次执行完一条指令就查看是否有硬件中断到来,这里cpu.pc要减4,因为进入isa_raise_intr()函数我让pc加4了(PA3中实现),但是中断操作和系统调用不同,中断操作执行完回到执行前的pc,系统调用执行完回到执行前的pc的下一条指令
word_t intr = isa_query_intr();
if (intr != INTR_EMPTY) {
cpu.pc = isa_raise_intr(intr, cpu.pc-4);
}实现isa_query_intr(),MIE开启“且“cpu中断引脚高电平“时, 接收中断
#define MIE_OFFSET 3
word_t isa_query_intr() {
if ((cpu.mstatus & (1 << MIE_OFFSET))&& cpu.INTR) {
cpu.INTR = false;
return IRQ_TIMER;
}
return INTR_EMPTY;
}修改isa_raise_intr()中的代码, 让处理器进入关中断状态,将mstatus.MIE保存到mstatus.MPIE中, 然后将mstatus.MIE位置为0。你还需要修改mret指令的实现, 将mstatus.MPIE还原到mstatus.MIE中, 然后将mstatus.MPIE位置为1
restore_interrupt()在mret指令的执行操作中调用
#define MPIE_OFFSET 7
#define MIE_OFFSET 3
word_t isa_raise_intr(word_t NO, vaddr_t epc) {
/* TODO: Trigger an interrupt/exception with ``NO''.
* Then return the address of the interrupt/exception vector.
*/
// 保存当前的 MIE 到 MPIE
cpu.mstatus = (cpu.mstatus & ~(1 << MPIE_OFFSET)) | ((cpu.mstatus >> MIE_OFFSET) & 0x1) << MPIE_OFFSET ;
// 将 MIE 置为 0
cpu.mstatus &= ~(1 << MIE_OFFSET);
epc+=4;
cpu.csr.mcause = NO;
cpu.csr.mepc = epc;
return cpu.csr.mtvec;
}
void restore_interrupt() {
// 还原之前保存的 MPIE 到 MIE
cpu.mstatus = (cpu.mstatus & ~(1 << MIE_OFFSET)) | ((cpu.mstatus >> MPIE_OFFSET) & 0x1)<< MIE_OFFSET;
// 将 MPIE 位置为 1
cpu.mstatus |= (1 << MPIE_OFFSET);
}修改 kcontext() 和 ucontext()
在构造上下文的时候,设置正确中断状态,使得将来恢复上下文之后 CPU 处于开中断状态
只需要设置 MPIE 为 1 即可(mstatus = 1 << 7),在切换到内核线程或用户进程时便会将 mstatus.MPIE 还原到 mstatus.MIE 中


















 3056
3056

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











