







一、题目简介
本题目是根据所学的大数据基础上的相关知识对提供的2020年美国新冠肺炎疫情数据作为数据集进行分析,并对分析结果进行可视化。
二、数据集说明
本次作业使用的数据集来自数据网站Kaggle的美国新冠肺炎疫情数据集,该数据集以数据表us-counties.csv组织,其中包含了美国发现首例新冠肺炎确诊病例至今(2020-05-19)的相关数据。数据包含以下字段:
字段名称 字段含义 例子
date 日期 2020/1/21;2020/1/22;etc
county 区县(州的下一级单位) Snohomish;
state 州 Washington
cases 截止该日期该区县的累计确诊人数 1,2,3…
deaths 截止该日期该区县的累计确诊人数 1,2,3…
三、步骤概述
完成课题,大致包含以下6个步骤:
(1)建立环境。(Hadoop、HBase、Hive、MySQL、Sqoop)
1、Hadoop已安装

启动Hadoop集群进行测试

2、Hbase已安装

启动Hbase集群进行测试
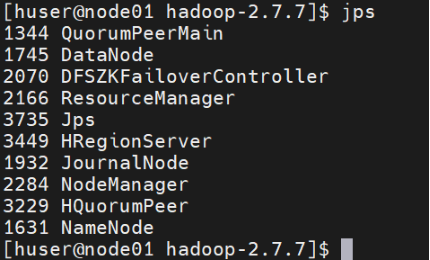
查看节点进程数
3、sqoop已安装

4、MySQL已安装
5、hive已安装

(2)创建数据源读取数据,并将数据存储进MySQL。
1、创建指定文件夹存储疫情数据
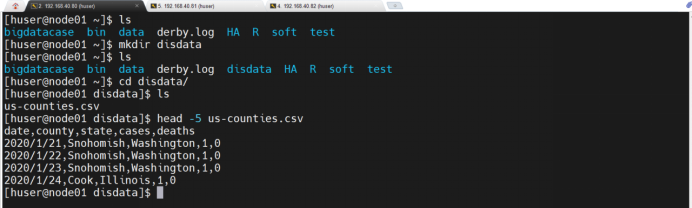
2、去除文档当中的标题行

3、编写数据规范化shell脚本对数据集进行数据预处理
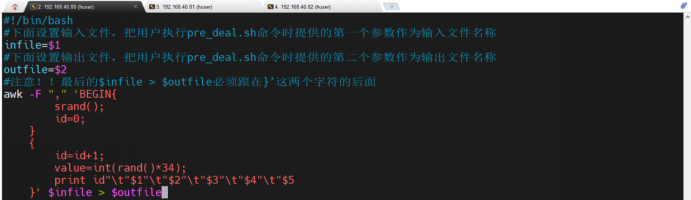
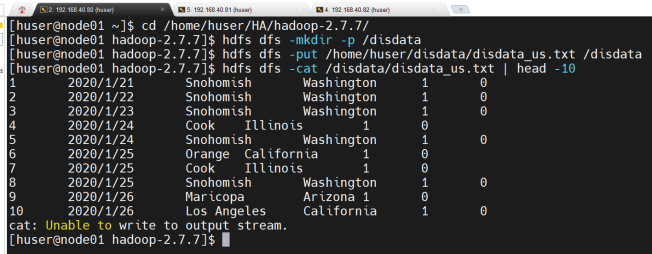
4、在HDFS当中创建相应文件夹并将预处理后的数据存入
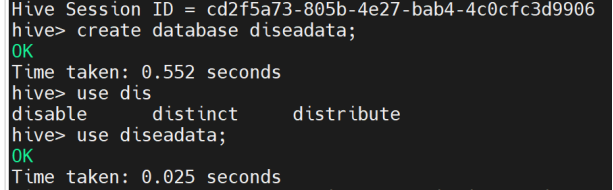
5、进入Hive,创建相应的数据库
6、在hive中对数据进行导入

7、查看表中的数据验证是否导入成功

8、在Hive当中创建临时表disease_action表

查看临时表是否创建成功
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2745
2745

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









