






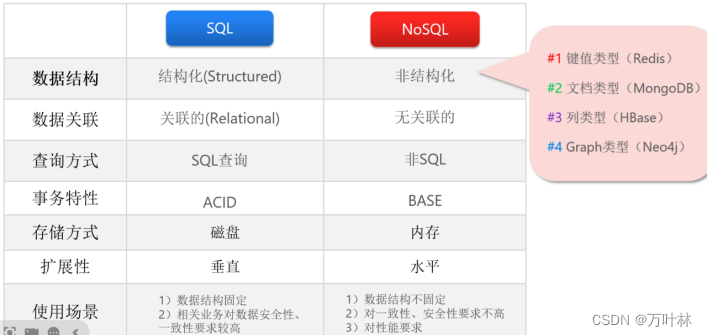
1.关系型数据库和非关系型数据库的区别:

2.redis的优点特征:

·Redis底层基于c语言编写,运行效率高。
·Redis单线程但效率却很高:基于内存,io多路复用,良好的编码。
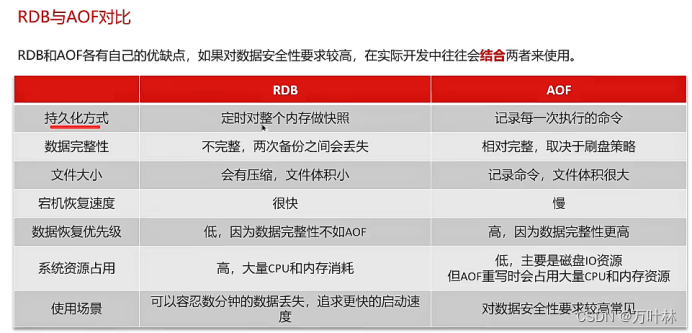
·关系型数据库为了持久化,将数据存储在磁盘,防止断电丢失。但是redis存储于内存,为什么也支持持久化呢?RDB和AOF
·主从集群:从节点可以备份主节点的数据,防止主节点宕机数据丢失,主从可以读写分离提高查询效率。mysql同样支持主从集群。

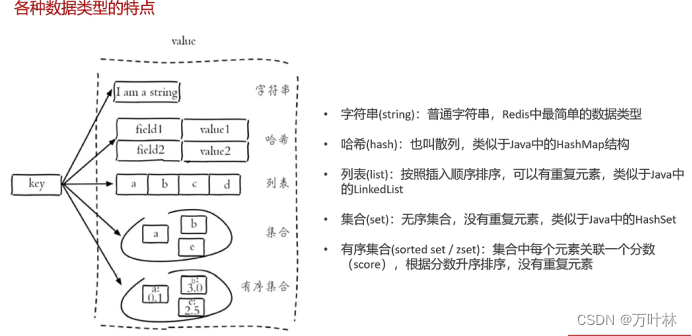
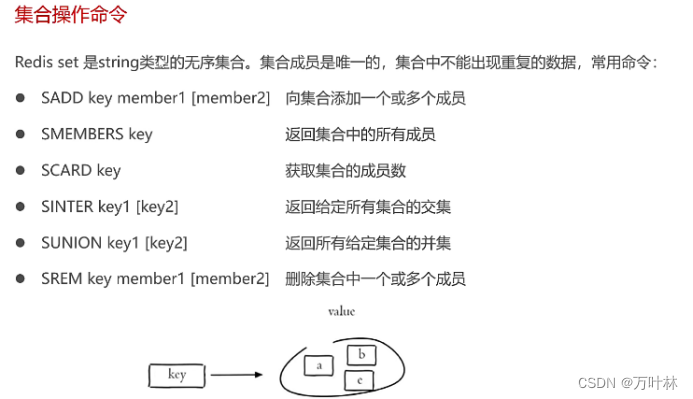
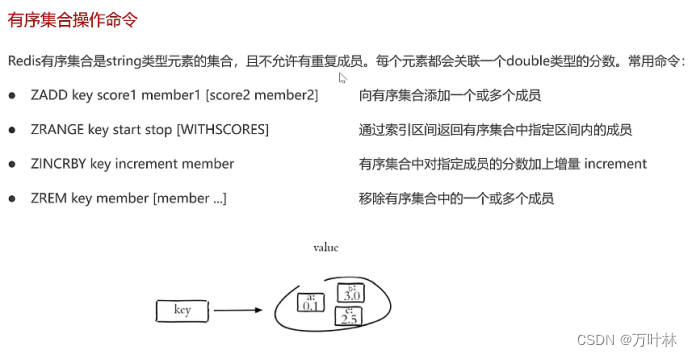
redis常见命令:

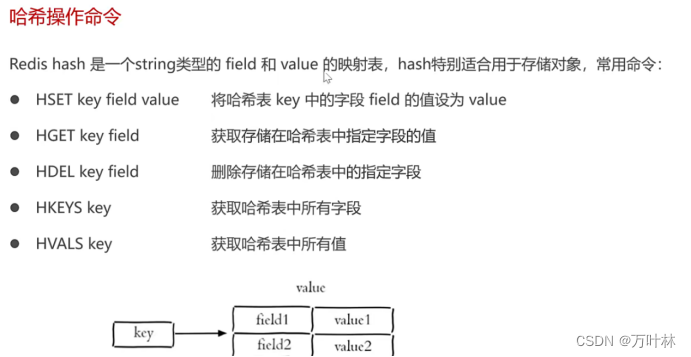
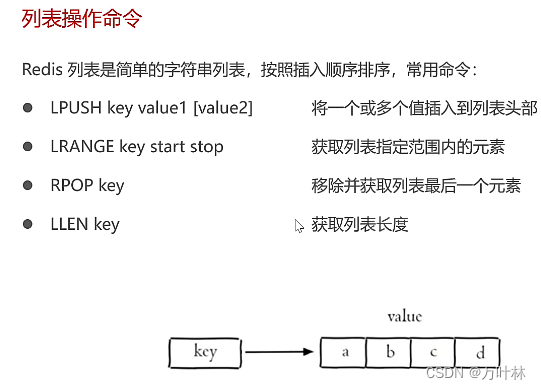

Java中操作redis:
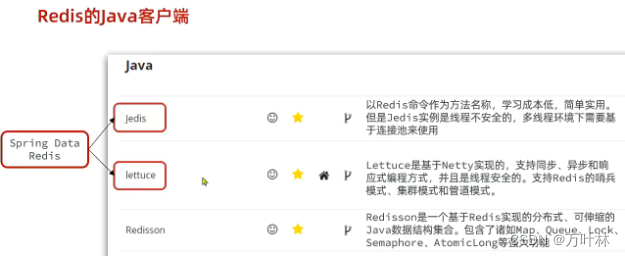
Spring不会造轮子,只会整合。
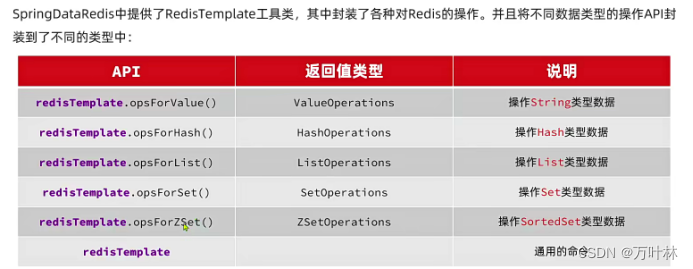
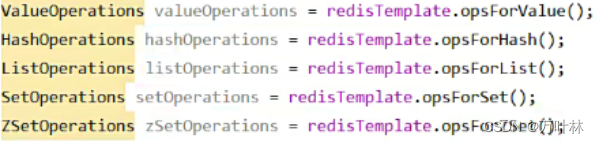
springdataredis的操作对象可以接受一切类型的对象,最终都被序列化存取和反序列化读取,所以我们可以自定义序列化规则:

这样依赖,key都成了string,其他…
目录:
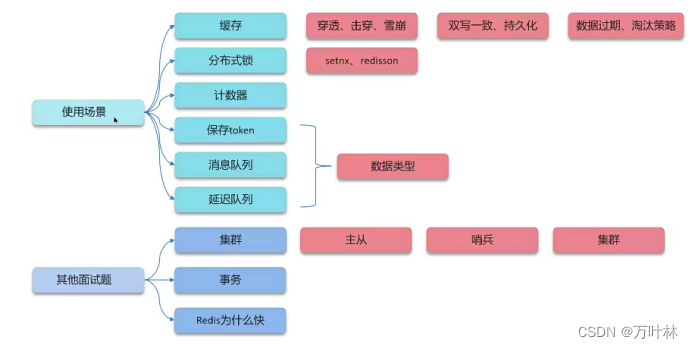

缓存
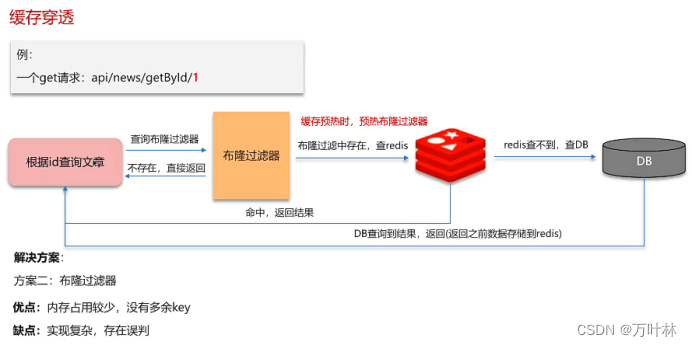
缓存穿透:


缓存击穿:
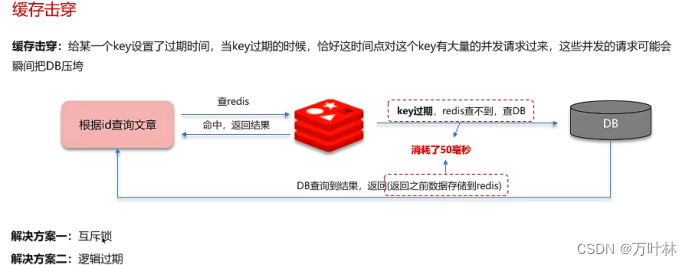
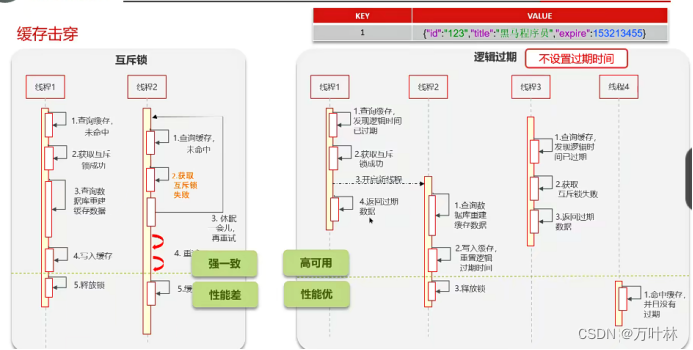
逻辑过期:如果查询的数据没有过期,就返回没过期的数据;如果过期了,就返回过期的数据,并拿到锁开启新的线程去更新过期数据。所以就要给每个数据设置过期时间,超过过期时间不会删除,而是以过期的形式仍然保存。
互斥锁:发现数据过期,就上锁并更新,其他进程只能等待。
缓存雪崩:


双写一致性:

一致性要求高:
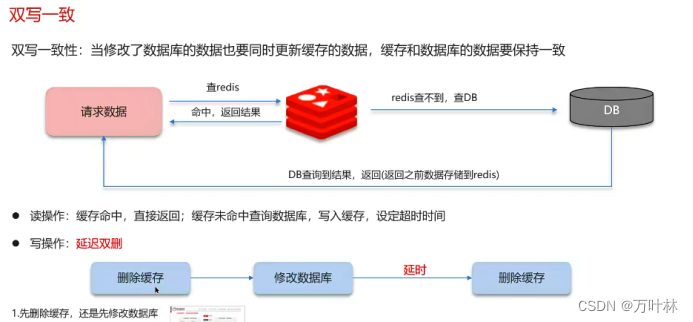
先删除还是先修改都不行,于是采用延迟双删:
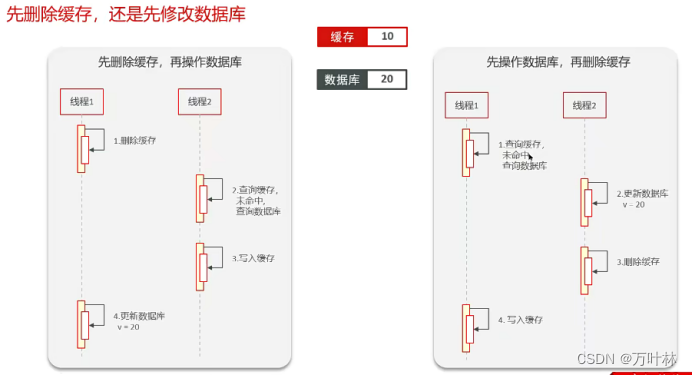
延迟双删也不能保证完全的一致性,因为现在的数据库都是主从模式。想要实现强一致性,可以采用互斥锁。但是互斥锁又会影响性能,而且放入缓存的数据基本都是读多写少,于是我们可以略做优化:读操作加上共享锁,写操作加上排他锁。


允许延迟一致:(这个才是主流)
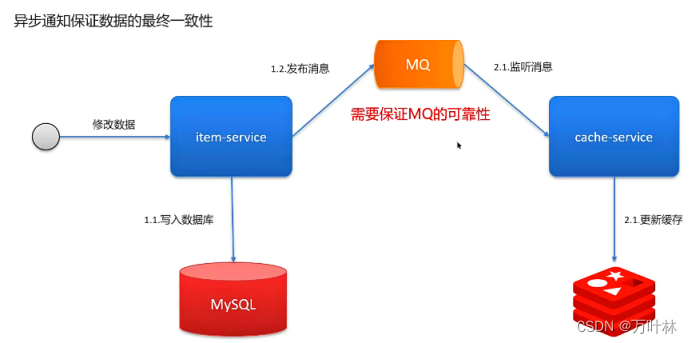
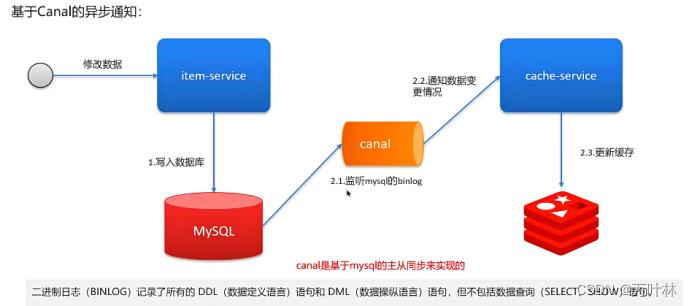

持久化:


手动备份:
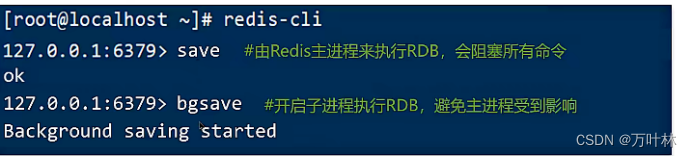
自动备份:
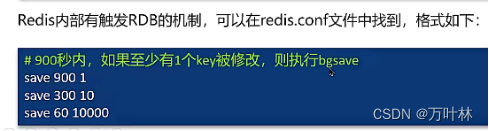
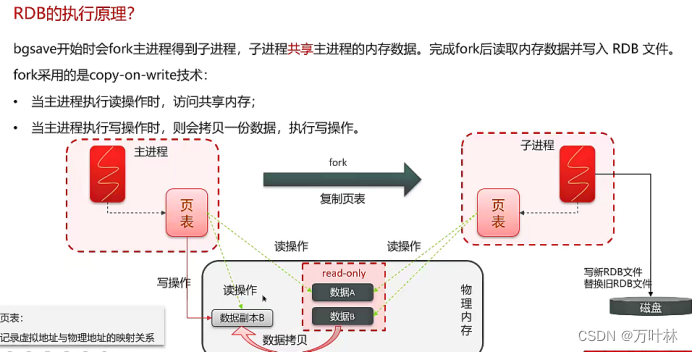


数据过期策略:



数据淘汰策略:(重点是LRU和LFU)



Redis三大集群方案:主从复制,哨兵模式,分片集群
主从复制:(保证redis的高并发)
主节点负责写操作,从节点负责读操作,满足redis读多写少的特性,每次写操作之后由主节点向从节点更新数据。
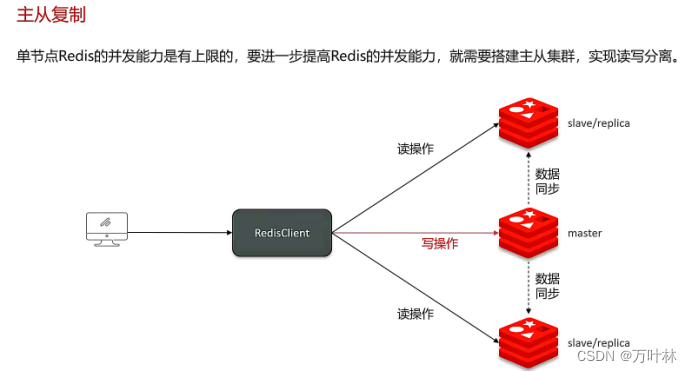

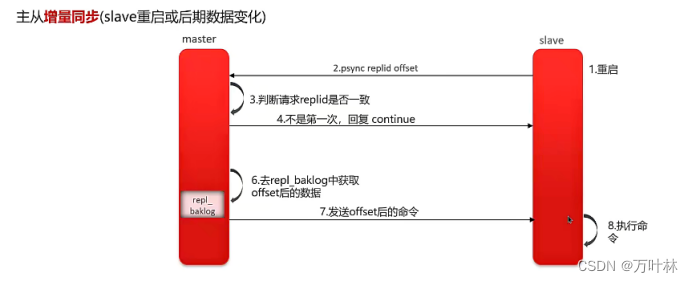
主从模式一旦主节点宕机就没办法写数据,不能满足高可用性,可以使用哨兵模式。
哨兵模式:(保证redis的高可用)
哨兵机制实现主从集群的自动故障恢复。
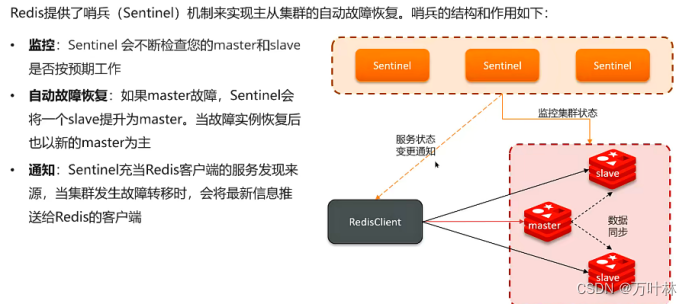
哨兵模式可能会产生脑裂, 假如由于网络原因,主节点和哨兵处于不同的网络分区,哨兵检测不到主节点就会选举新的主节点,一旦网络恢复就存在了两个大脑,旧的大脑强制降级为从节点并与新大脑同步数据,这样网络波动阶段的数据流就丢失了。如下图:
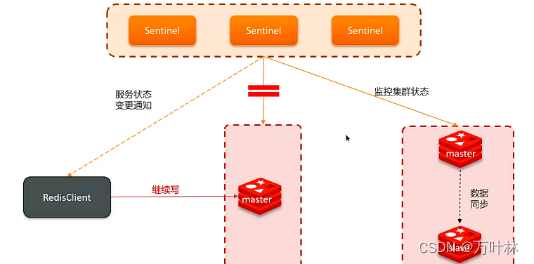
解决方案:必须满足以下两点,否则拒绝请求。

分片集群(在以上两个模式的基础上解决海量数据存储和高并发写的问题)
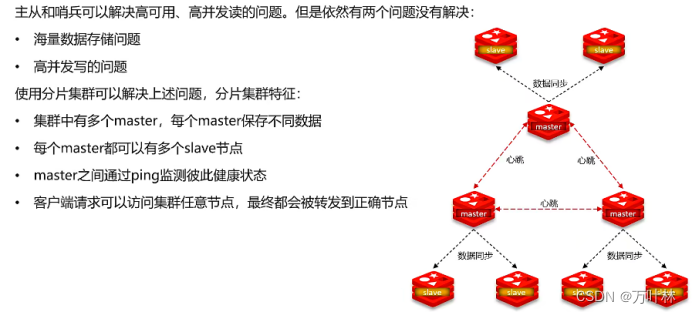
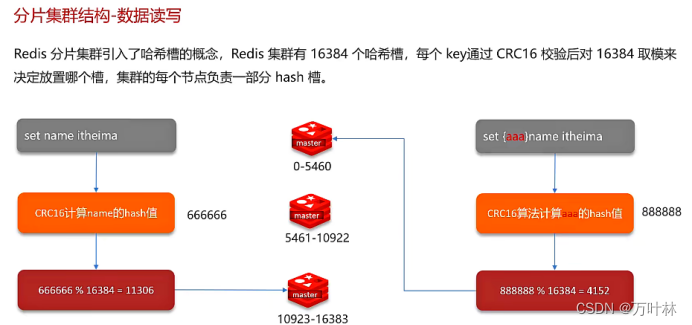
分片集群有多个主节点,客户端读写数据怎么知道去哪一个节点呢?采用哈希槽:

I/o多路复用
















 21万+
21万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









