







今天我们继续实验一接下来的内容。
一、pingpong(难度easy)
1.需求
编写一个程序,使用 UNIX 系统调用通过一对管道(每个方向一个管道)在两个进程之间 "ping-pong" 传递一个字节。父进程应该向子进程发送一个字节; 子进程应该打印
<pid>: received ping,其中<pid>是它的进程号,将管道上的字节写入父进程,然后退出; 父进程应该从子进程读取字节,打印<pid>: received pong,然后退出。您的解决方案应该在user/pingpong.c.文件中。2.提示
使用
pipe来创造管道使用
fork创建子进程使用
read从管道中读取数据,并且使用write向管道中写入数据使用
getpid获取调用进程的pid将程序加入到Makefile的
UPROGSxv6上的用户程序有一组有限的可用库函数。您可以在user/user.h中看到可调用的程序列表;源代码(系统调用除外)位于user/ulib.c、user/printf.c和user/umalloc.c中。
3.代码演示
#include "kernel/types.h" #include "user/user.h" int main(int argc, char *argv[]) { char buff; // 用于传送的字节 int parent_to_child[2]; // 父进程到子进程的管道 int child_to_parent[2]; // 子进程到父进程的管道 pipe(parent_to_child); pipe(child_to_parent); int pid = fork(); if (pid < 0) { fprintf(2, "fork failed!"); exit(1); } if (pid == 0) { // 子进程 close(parent_to_child[1]); // 关闭写端 close(child_to_parent[0]); // 关闭读端 read(parent_to_child[0], &buff, 1); // 从父进程读取进程 printf("%d: received ping\n", getpid()); write(child_to_parent[1], &buff, 1); // 向父进程写入字节 exit(0); } else { // 父进程 close(parent_to_child[0]); // 关闭读端 close(child_to_parent[1]); // 关闭写端 buff = 'p'; write(parent_to_child[1], &buff, 1); // 向父进程写入字节 read(child_to_parent[0], &buff, 1); // 从子进程读取字节 printf("%d: received pong\n", getpid()); exit(0); } exit(0); }4.测试结果
在xv6-labs-2020中,执行下面指令,测试程序
5.辅助图

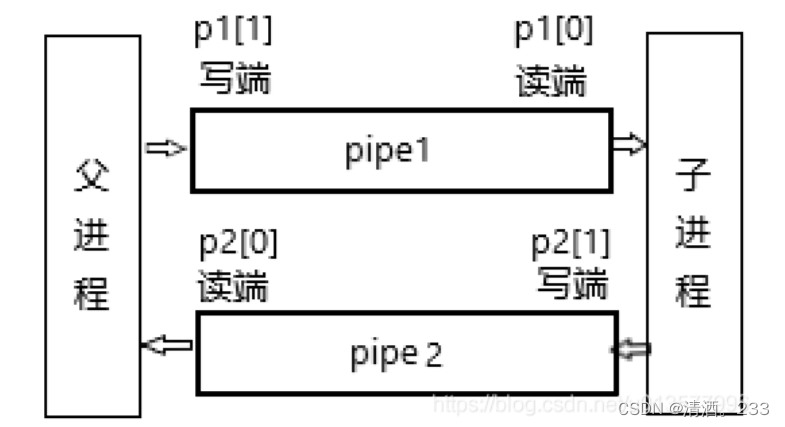
二、primes实验(素数,难度Hard)
1.需求
您的目标是使用
pipe和fork来设置管道。第一个进程将数字2到35输入管道。对于每个素数,您将安排创建一个进程,该进程通过一个管道从其左邻居读取数据,并通过另一个管道向其右邻居写入数据。由于xv6的文件描述符和进程数量有限,因此第一个进程可以在35处停止。您的解决方案应该在user/primes.c.文件中。2.提示
使用
pipe来创造管道使用
fork创建子进程使用
read从管道中读取数据,并且使用write向管道中写入数据使用
getpid获取调用进程的pid将程序加入到Makefile的
UPROGS3.代码演示
#include "kernel/types.h" #include "user/user.h" void get_primes(int *input, int num) { if (num == 1) { printf("prime %d\n", *input); return; } int p[2], i; int prime = *input; int temp; printf("prime %d\n", prime); pipe(p); if (fork() == 0) { for (i = 0; i < num; i++) { temp = *(input + i); write(p[1], (char *)(&temp), 4); } exit(0); } close(p[1]); if (fork() == 0) { int counter = 0; char buffer[4]; while (read(p[0], buffer, 4) != 0) { temp = *((int *)buffer); if (temp % prime != 0) { *input = temp; input += 1; counter++; } } get_primes(input - counter, counter); exit(0); } wait(0); wait(0); } int main() { int input[34]; int i = 0; for (; i < 34; i++) { input[i] = i + 2; } get_primes(input, 34); exit(0); }这段代码是用C语言编写的,它的目的是找出2到35之间的所有素数(不包括2,因为2是第一个素数)。代码使用了进程间的管道通信来实现这一目标。下面是代码的详细解释:
get_primes函数:这个函数接收一个整型数组input和一个整型变量num作为参数。input数组存储了一系列待检查的整数,num表示数组中整数的数量。在
get_primes函数中,首先检查num是否等于1。如果是,那么input数组中只剩下一个整数,这个整数就是素数,将其打印出来并返回。如果
num大于1,首先创建一个管道p。管道用于在父子进程之间传递数据。使用
fork()创建一个子进程。在子进程中,遍历input数组,将每个元素写入管道p的写入端。在父进程中,再次调用
fork()创建另一个子进程。在这个子进程中,从管道p的读取端读取数据,检查每个读取到的整数是否可以被prime整除。如果不能,说明它是素数,将其存储回input数组,并更新计数器counter。当子进程读取完所有数据后,递归调用
get_primes函数,将剩余的素数继续传递给下一个子进程。在
main函数中,首先初始化一个长度为34的input数组,存储2到35之间的所有整数。然后调用get_primes函数,开始查找素数。最后,程序退出。
4.测试结果
三、find实验(难度Moderate)
1.需求
写一个简化版本的UNIX的
find程序:查找目录树中具有特定名称的所有文件,你的解决方案应该放在user/find.c。2.提示
- 查看user/ls.c文件学习如何读取目录
- 使用递归允许
find下降到子目录中- 不要在“
.”和“..”目录中递归- 对文件系统的更改会在qemu的运行过程中一直保持;要获得一个干净的文件系统,请运行
make clean,然后make qemu- 你将会使用到C语言的字符串,要学习它请看《C程序设计语言》(K&R),例如第5.5节
- 注意在C语言中不能像python一样使用“
==”对字符串进行比较,而应当使用strcmp()- 将程序加入到Makefile的
UPROGS
3.代码演示#include "kernel/types.h" #include "kernel/stat.h" #include "user/user.h" #include "kernel/fs.h" char *get_fname(char *path) // 获取当前文件名 { char *p; for (p = path + strlen(path); p >= path && *p != '/'; p--) ; p++; return p; } void find(char *path, char *str) // 类Unix系统中,目录被视为一种特殊类型的文件 { char buff[512]; // 存储路径 struct dirent de; // 目录结构体 struct stat st; // 文件结构体 int fd = open(path, 0); // 0表示以标准模式(读写模式)打开 if (fd < 0) { fprintf(2, "find: cannot open %s\n", path); return; } if (fstat(fd, &st) < 0) // 通过文件描述符将对应的文件信息放入文件结构体stat中,若失败则返回-1 { fprintf(2, "find: cannot stat %s\n", path); close(fd); return; } switch (st.type) // 判断打开类型 { case T_DEVICE: // 判断为设备文件 case T_FILE: // 判断为普通文件 if (!strcmp(str, get_fname(path))) { printf("%s\n", path); } break; case T_DIR: // 判定为目录 if (strlen(path) + 1 + DIRSIZ + 1 > sizeof buff) { printf("find: path too long\n"); break; } strcpy(buff, path); char *p = buff + strlen(buff); *p = '/'; p++; while (read(fd, &de, sizeof(de)) == sizeof(de)) // 使用read从目录文件中读取目录条目,处理目录中文件 { if (de.inum == 0) // 该目录条目为空或未使用 continue; memmove(p, de.name, DIRSIZ); p[DIRSIZ] = 0; if (stat(buff, &st) < 0) { printf("find: cannot stat %s\n", buff); continue; } if (st.type == T_DEVICE || st.type == T_FILE) { // 判断为非目录文件 if (!strcmp(str, get_fname(buff))) printf("%s\n", buff); } else if (st.type == T_DIR && strcmp(".", get_fname(buff)) && strcmp("..", get_fname(buff))) // 判定为子目录,递归处理,注意不要重复进入本目录以及父目录 find(buff, str); } break; } close(fd); return; } int main(int argc, char *argv[]) { if (argc == 3) find(argv[1], argv[2]); else printf("argument error\n"); exit(0); }这段代码是一个简单的类Unix系统下的文件查找程序,它接受两个命令行参数:一个路径和一个字符串。程序会递归地在指定路径下查找与给定字符串匹配的文件名,并打印出匹配文件的完整路径。
以下是代码的主要部分的解释:
get_fname函数:接受一个路径字符串,返回该路径中最后一个斜杠('/')之后的文件名部分。如果路径中没有斜杠,则返回整个路径。
find函数:接受一个路径和一个字符串,用于递归地在路径中查找与字符串匹配的文件名。
- 打开路径,使用
open函数。- 使用
fstat函数获取文件状态,判断文件类型。- 如果是文件或设备文件,并且文件名与字符串匹配,打印路径。
- 如果是目录,递归地调用
find函数。
main函数:检查命令行参数的数量,如果正确,调用find函数开始查找。这个程序的工作原理是,对于每个目录,它都会读取目录中的所有条目,忽略
.和..这两个特殊条目,然后对于每个条目,它会检查是否是文件或目录。如果是文件,它会检查文件名是否与给定的字符串匹配;如果是目录,它会递归地调用find函数。4.测试结果

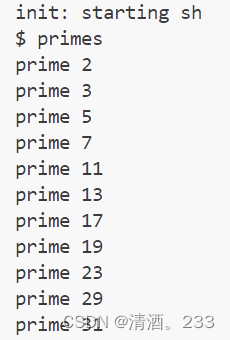
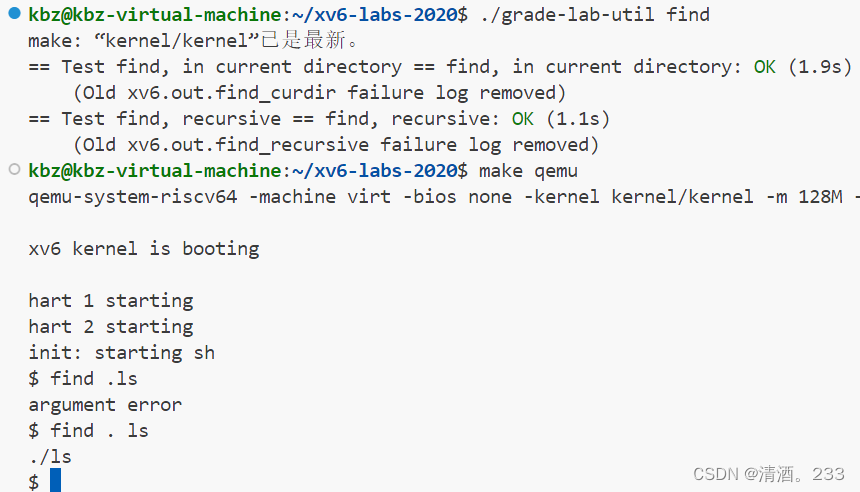
四、xargs(难度Moderate)
1.需求
编写一个简化版UNIX的
xargs程序:它从标准输入中按行读取,并且为每一行执行一个命令,将行作为参数提供给命令。你的解决方案应该在user/xargs.c2.提示
提示:
- 使用
fork和exec对每行输入调用命令,在父进程中使用wait等待子进程完成命令。- 要读取单个输入行,请一次读取一个字符,直到出现换行符('\n')。
- kernel/param.h声明
MAXARG,如果需要声明argv数组,这可能很有用。- 将程序添加到Makefile中的
UPROGS。- 对文件系统的更改会在qemu的运行过程中保持不变;要获得一个干净的文件系统,请运行
make clean,然后make qemu
3.代码演示#include "kernel/types.h" #include "user/user.h" #include "kernel/param.h" int main(int argc, char *argv[]) { char *p[MAXARG]; int i; if (argc < 2) { fprintf(2, "Usage: %s <command> [args...]\n", argv[0]); exit(1); } for (i = 1; i < argc; i++) { p[i - 1] = argv[i]; } char buffer[512]; // 缓冲区用于存储从标准输入读取的行 while (gets(buffer, sizeof(buffer))) { if (buffer[0] == 0) // 空行跳过 continue; // 去掉行末的换行符 if (buffer[strlen(buffer) - 1] == '\n') buffer[strlen(buffer) - 1] = 0; // 将输入行添加到参数数组 p[argc - 1] = buffer; p[argc] = 0; // 确保参数数组以 NULL 结尾 int pid = fork(); if (pid < 0) { fprintf(2, "fork failed\n"); exit(1); } else if (pid == 0) { exec(argv[1], p); // exec 如果成功,下面的代码不会执行 fprintf(2, "exec %s failed\n", argv[1]); exit(1); } else { wait(0); // 父进程等待子进程结束 } } exit(0); }这段代码是一个简单的Unix-like shell程序,它接受命令行参数中的第一个参数作为要执行的命令,然后从标准输入读取每一行,将每一行作为参数传递给该命令,并执行它。
以下是代码的主要部分的解释:
main函数首先检查命令行参数的数量,如果小于2,则打印使用说明并退出。然后将命令行参数(除了第一个参数,即程序名称本身)复制到一个新的参数数组
p中。使用
gets函数从标准输入读取一行,存储在buffer中。如果读取的是空行,则跳过。去掉行末的换行符,并将读取的行添加到参数数组
p的末尾,确保数组以NULL结尾,这是exec函数要求的。使用
fork函数创建一个新的进程。如果fork失败,则打印错误信息并退出。在子进程中,使用
exec函数执行命令行参数中指定的命令,并传递参数数组p。如果exec失败,则打印错误信息并退出。在父进程中,使用
wait函数等待子进程结束。重复步骤3-7,直到标准输入结束。
程序退出。
4.测试结果
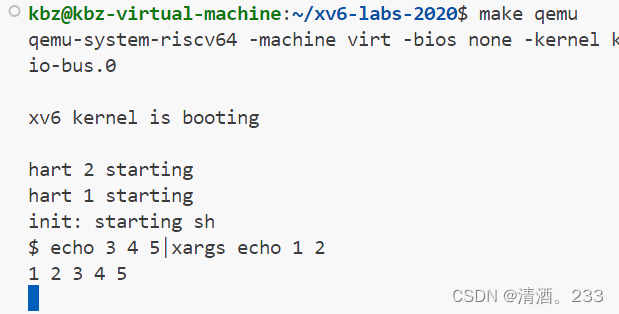
















 182
182











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











