







目录
CAS是什么?
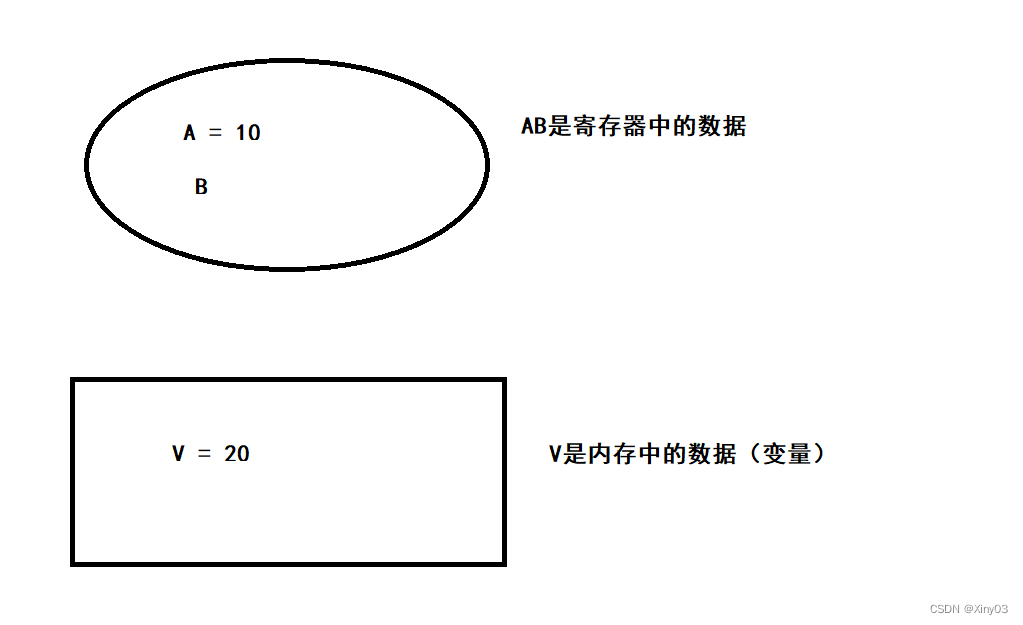
Compare and swap比较并交换,我们假设内存的原数据v,旧的预期值A,需要修改的新值B。1.比较A与V是否相等(比较)2.如果比较相等,将B写入V(交换)3.返回操作是否相等
CAS过程:AB是CPU寄存器中的数据,V是内存中的数据,如果V和A的值相等,那么就把V和B的值交换,一般交换过程中并不关心B后续的情况,更关心V这个变量的情况,这里说的交换,可以近似理解成“赋值”。如果V和A不同,就无事发生。
CAS这个操作,并非是通过一段代码实现的,而是通过一条CPU指令完成的,那就意味着CAS操作是原子的,就可以在一定程度上回避线程安全问题,因此在解决线程安全问题除了加锁之外,又有了一个新的方向。(CAS可以理解为是CPU提供的一个特殊指令,通过这个指令,就可以一定程度的处理线程安全问题)
CAS的应用场景
1.实现原子类
public class ThreadDemo{
public static void main(String[] args) throws InterruptedException {
AtomicInteger count = new AtomicInteger(0);
//使用原子类 来解决线程安全问题
Thread t1 = new Thread(() ->{
for(int i = 0;i <5000;i++){
count.getAndIncrement();//count++
//count.incrementAndGet();//++count
//count.getAndIncrement();//count--
//count.decrementAndGet();//--count
}
});
Thread t2 = new Thread(() ->{
for(int i = 0;i<5000;i++){
count.getAndIncrement();
}
});
t1.start();
t2.start();
t1.join();
t2.join();
System.out.println(count.get());
}
}原子类的伪代码
class AtomicInteger {
private int value;
public int getAndIncrement() {
int oldValue = value; //①
while ( CAS(value, oldValue, oldValue+1) != true) { //②
oldValue = value;
}
return oldValue;
}
}把旧的value用寄存器保存起来,这里的oldvalue可以理解为寄存器中的值 ,相当于是先把内存中的值读到寄存器中去了,这里CAS()正常情况下,oldValue应该和value是一样的,然后这里就会产生CAS,把oldValue+1写到value中,但是也有可能会有执行完读取value到寄存器之后,线程发生切换了,另外一个线程也修改了value的值,此时这个线程回来之后,再进行CAS判定,就认为不相等了,在①和②的代码之间,可能会发生线程调度。原子类的实现,每次修改之前,再确认一下这个值是否符合要求。
2.实现自旋锁
自旋锁的伪代码
public class SpinLock {
private Thread owner = null;//需要记录一下当前的锁是谁加的
public void lock(){
// 通过 CAS 看当前锁是否被某个线程持有.
// 如果这个锁已经被别的线程持有, 那么就自旋等待.
// 如果这个锁没有被别的线程持有, 那么就把 owner 设为当前尝试加锁的线程.
while(!CAS(this.owner, null, Thread.currentThread())){
}
}
public void unlock (){
this.owner = null;
}
}解锁就是把owner置为空,加锁中用CAS()检测当前的owner是否为null,就进行交换,也就是把当前线程的引用赋值给owner,如果赋值成功,此时就循环结束,加锁完成了。如果当前锁,已经被别的线程占用了,CAS就会发现,this.owner不是null,CAS就不会产生赋值,也同时返回false,循环继续执行,并进行下次判定。
CAS的典型问题:ABA问题
CAS在运行中的核心,检查value和oldvalue是否一致,如果一致,就视为value中途没有被修改过,所以进行下一步交换操作是没有问题的,这里的一致,有两种情况,一种是可能没改过,一种是改过,但是还原回来了。
Synchronized原理
两个线程,针对同一个对象加锁,就会产生阻塞等待,synchronized内部其实还有一些优化机制,存在目的的就是为了让这个锁更高效,更好用
1.锁升级/锁膨胀
①无锁->②偏向锁->③轻量级锁->④重量级锁(偏向锁不是真加锁)
当代码执行到这个代码块中之后,加锁过程,就可能会经历这几个阶段,进行加锁的时候,首先会进入到偏向锁状态,偏向锁,并不是真正的加锁,而是占个位置,有需要了再真加锁,没需要就算了。上述过程,就是“偏向锁”这个过程,相当于“懒汉模式”提到的懒加载一样“非必要,不加锁”,synchronized的时候,并不是真的加锁,先偏向锁状态,做个标记(这个过程是非常轻量的),如果整个使用锁的过程中,都没有出现锁竞争,在synchronized执行完之后,取消偏向锁即可,但是,如果使用过程中,另一个线程也尝试加锁,在它加锁之前,迅速的把偏向锁升级成真正的加锁状态,另一个线程就只能阻塞等待了,当synchronized发生锁竞争的时候,就会从偏向锁,升级成轻量级锁,此时,synchronized发生锁竞争的时候,就会从偏向锁升级为轻量级锁,此时,synchronized相当于是通过自旋的方式,来进行加锁。如果要是很快别的线程释放了锁,自旋锁是划算的,但是如果迟迟拿不到锁,一直自旋,并不划算,那么自旋到一定程度之后,就会升级为重量级锁(挂起等待锁)。
挂起等待锁是操作系统内核提供的加锁功能,这个锁会影响到线程的调度,此时,如果线程进行了重量级锁的加锁,并且发生锁竞争,此时线程就会被放到阻塞队列里,暂时不参与CPU调度了,然后直到说,锁被释放了,这个线程才有机会被调度到,并且有机会获取到锁。一旦当前线程被切换出CPU,这就是个比较低效的事情了。
锁只能升级,不能降级
2.锁消除
在编译阶段,编译器去智能的判定,看当前的代码是否真的要加锁,如果这个场景不需要加锁,程序员加了,就自动把锁干掉。例如StringBuffer关键方法中带有synchronized,但是如果是单线程中使用StringBuffer,synchronized加了也白加,此时编译器就会直接把这些加锁操作消除了
3.锁粗化
锁的粒度:synchronized包含的代码越多,粒度就越粗,包含代码越少,粒度就越细
通常情况下,认为锁的粒度越细一点,比较好,加锁部分的代码,是不能并发执行的,锁的粒度越细,能并发的代码就越多;反之越少,也有的情况下,锁定粒度粗一些反而更好,两次加锁解锁之间,间隙非常少,此时,直接加一次大锁就更减少开销















 526
526











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









