






HDFS产出背景及定义
1)HDFS产生背景
随着数据量越来越大,在一个操作系统存不下所有的数据,那么就分配到更多的操作系统管理的磁盘中,但是不方便管理和维护,迫切需要一种系统来管理多台机器上的文件,这就是分布式文件管理系统。HDFS只是分布式文件管理系统中的一种。
2)HDFS定义
HDFS(Hadoop Distributed File System),它是一个文件系统,用于存储文件,通过目录树来定位文件;其次,它是分布式的,由很多服务器联合起来实现其功能,集群中的服务器有各自的角色。
HDFS的使用场景:适合一次写入,多次读出的场景。一个文件经过创建、写入和关闭之后就不需要改变。
HDFS优缺点
1)HDFS优点
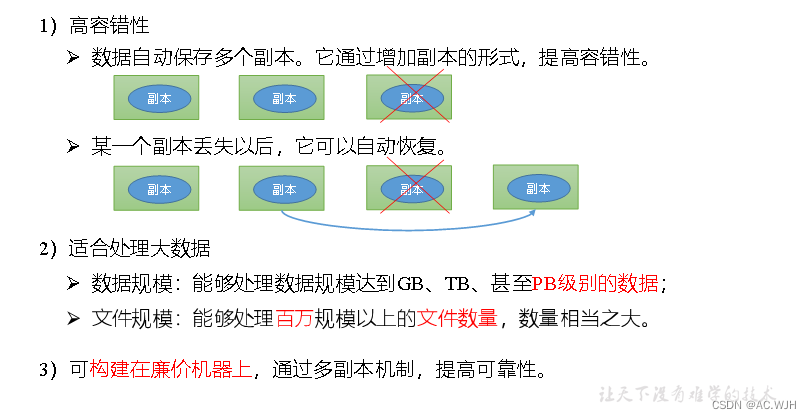
2)HDFS缺点

HDFS组成架构
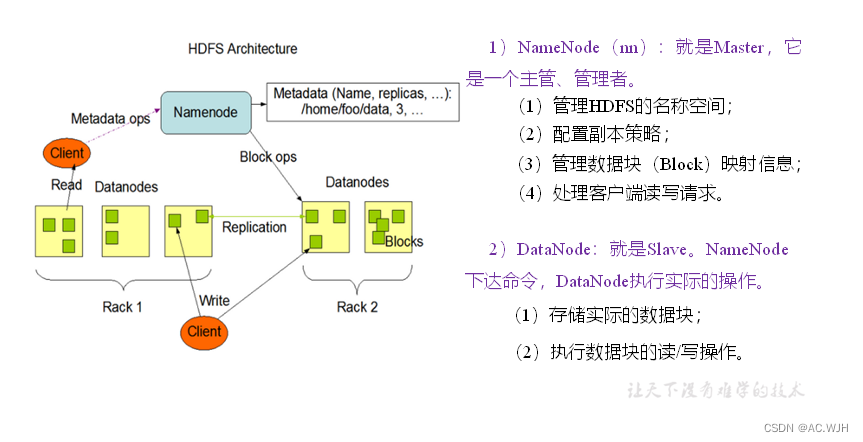
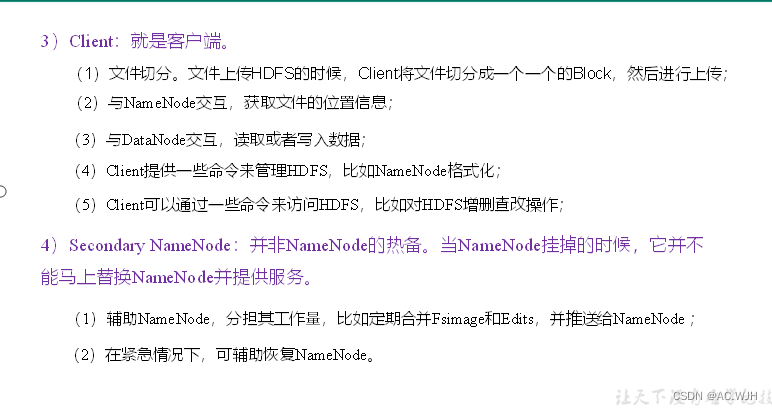
HDFS文件块大小

HDFS的Shell操作
-- 命令大全
[atguigu@hadoop102 hadoop-3.1.3]$ bin/hadoop fs
[-appendToFile <localsrc> ... <dst>]
[-cat [-ignoreCrc] <src> ...]
[-chgrp [-R] GROUP PATH...]
[-chmod [-R] <MODE[,MODE]... | OCTALMODE> PATH...]
[-chown [-R] [OWNER][:[GROUP]] PATH...]
[-copyFromLocal [-f] [-p] <localsrc> ... <dst>]
[-copyToLocal [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-count [-q] <path> ...]
[-cp [-f] [-p] <src> ... <dst>]
[-df [-h] [<path> ...]]
[-du [-s] [-h] <path> ...]
[-get [-p] [-ignoreCrc] [-crc] <src> ... <localdst>]
[-getmerge [-nl] <src> <localdst>]
[-help [cmd ...]]
[-ls [-d] [-h] [-R] [<path> ...]]
[-mkdir [-p] <path> ...]
[-moveFromLocal <localsrc> ... <dst>]
[-moveToLocal <src> <localdst>]
[-mv <src> ... <dst>]
[-put [-f] [-p] <localsrc> ... <dst>]
[-rm [-f] [-r|-R] [-skipTrash] <src> ...]
[-rmdir [--ignore-fail-on-non-empty] <dir> ...]
<acl_spec> <path>]]
[-setrep [-R] [-w] <rep> <path> ...]
[-stat [format] <path> ...]
[-tail [-f] <file>]
[-test -[defsz] <path>]
[-text [-ignoreCrc] <src> ...]实操演示
1.上传
1)-moveFromLocal:从本地剪切粘贴到HDFS
[atguigu@hadoop102 hadoop-3.1.3]$ vim shuguo.txt
输入:
shuguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -moveFromLocal ./shuguo.txt /sanguo2)-copyFromLocal:从本地文件系统中拷贝文件到HDFS路径去
[atguigu@hadoop102 hadoop-3.1.3]$ vim weiguo.txt
输入:
weiguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyFromLocal weiguo.txt /sanguo3)-put:等同于copyFromLocal,生产环境更习惯用put
[atguigu@hadoop102 hadoop-3.1.3]$ vim wuguo.txt
输入:
wuguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -put ./wuguo.txt /sanguo4)-appendToFile:追加一个文件到已经存在的文件末尾
[atguigu@hadoop102 hadoop-3.1.3]$ vim liubei.txt
输入:
liubei
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -appendToFile liubei.txt /sanguo/shuguo.txt2.下载
1)-copyToLocal 或者 -get :从HDFS拷贝到本地
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -copyToLocal /sanguo/shuguo.txt ./
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -get /sanguo/shuguo.txt ./shuguo2.txtHDFS的直接操作
1)-ls: 显示目录信息
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -ls /sanguo2)-cat:显示文件内容
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cat /sanguo/shuguo.txt3)-chgrp、-chmod、-chown:Linux文件系统中的用法一样,修改文件所属权限
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chmod 666 /sanguo/shuguo.txt
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -chown atguigu:atguigu /sanguo/shuguo.txt4)-mkdir:创建路径
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mkdir /jinguo5)-cp:从HDFS的一个路径拷贝到HDFS的另一个路径
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -cp /sanguo/shuguo.txt /jinguo6)-mv:在HDFS目录中移动文件
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/wuguo.txt /jinguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -mv /sanguo/weiguo.txt /jinguo7)-tail:显示一个文件的末尾1kb的数据
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -tail /jinguo/shuguo.txt8)-rm:删除文件或文件夹
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm /sanguo/shuguo.txt9)-rm -r:递归删除目录及目录里面内容
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -rm -r /sanguo10)-du统计文件夹的大小信息
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -s -h /jinguo
27 81 /jinguo
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -du -h /jinguo
14 42 /jinguo/shuguo.txt
7 21 /jinguo/weiguo.txt
6 18 /jinguo/wuguo.tx
-- 说明:27表示文件大小;81表示27*3个副本;/jinguo表示查看的目录11)-setrep:设置HDFS中文件的副本数量
[atguigu@hadoop102 hadoop-3.1.3]$ hadoop fs -setrep 10 /jinguo/shuguo.txtHDFS的API操作案例实操
package com.atguigu.hdfs.Hdfs;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.FileSystem;
import org.apache.hadoop.fs.Path;
import org.junit.After;
import org.junit.Before;
import org.junit.Test;
import java.io.IOException;
import java.net.URI;
import java.net.URISyntaxException;
public class Client {
private FileSystem fs;
@Before
public void init() throws Exception {
Configuration configuration = new Configuration();
/**
* 参数优先级
* hdfs-default.xml => hdfs.site.xml => 在项目资源目录下的配置文件=> 代码里面的配置文件
*/
configuration.set("dfs.replication","2");
URI uri = new URI("hdfs://hadoop102:8020");
fs = FileSystem.get(uri, configuration, "atguigu");
}
@After
public void close() throws IOException { // 3 关闭资源
fs.close();
}
@Test
public void testMkdirs() throws Exception {
// 2 创建目录
fs.mkdirs(new Path("/xiyou/huaguoshan/"));
}
@Test //复制上传
public void testPut() throws Exception {
//参数解读 参数一:表示删除原数据(相当于move) 参数二:是否允许覆盖 参数三:原数据路径 参数四:目的地路径
fs.copyFromLocalFile(false,true,new Path("D:\\a.txt"),new Path("/xiyou/huaguoshan/"));
}
@Test //文件下载
public void testGet() throws Exception{
//参数解读 参数一:表示源文件是否删除 参数二:原路径HDFS 参数三:目标路径 参数四:是否开启本地校验;
fs.copyToLocalFile(false,new Path("hdfs://hadoop102/xiyou/huaguoshan"),new Path("D:\\ab.txt"),false);
}
@Test
public void testRm() throws Exception{
// 参数解读: 参数1:要删除的路径; 参数2:是否递归删除
//删除文件
fs.delete(new Path("***.txt"),false);
//删除目录 非空目录参数2得为true
fs.delete(new Path("/xiyou"),false);
}
//文件的更名和移动
public void testMv() throws Exception{
//参数解读:参数1:原文件路径; 参数2:目标文件路径
//文件的移动和更名
fs.rename(new Path("/xxxx/xxx.txt"),new Path("/xxxx/xxx.txt"));
}
}HDFS读写数据流程
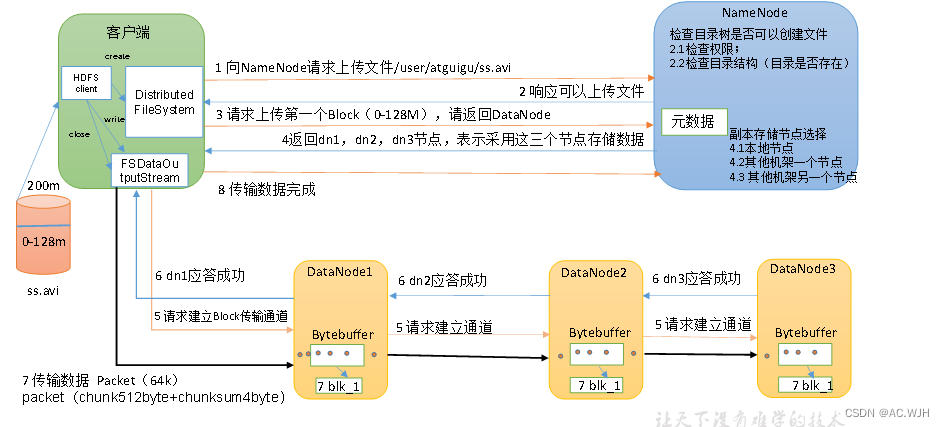
(1)客户端通过Distributed FileSystem模块向NameNode请求上传文件,NameNode检查目标文件是否已存在,父目录是否存在。
(2)NameNode返回是否可以上传。
(3)客户端请求第一个 Block上传到哪几个DataNode服务器上。
(4)NameNode返回3个DataNode节点,分别为dn1、dn2、dn3。
(5)客户端通过FSDataOutputStream模块请求dn1上传数据,dn1收到请求会继续调用dn2,然后dn2调用dn3,将这个通信管道建立完成。
(6)dn1、dn2、dn3逐级应答客户端。
(7)客户端开始往dn1上传第一个Block(先从磁盘读取数据放到一个本地内存缓存),以Packet为单位,dn1收到一个Packet就会传给dn2,dn2传给dn3;dn1每传一个packet会放入一个应答队列等待应答。
(8)当一个Block传输完成之后,客户端再次请求NameNode上传第二个Block的服务器。(重复执行3-7步)。
网络拓扑-节点距离计算
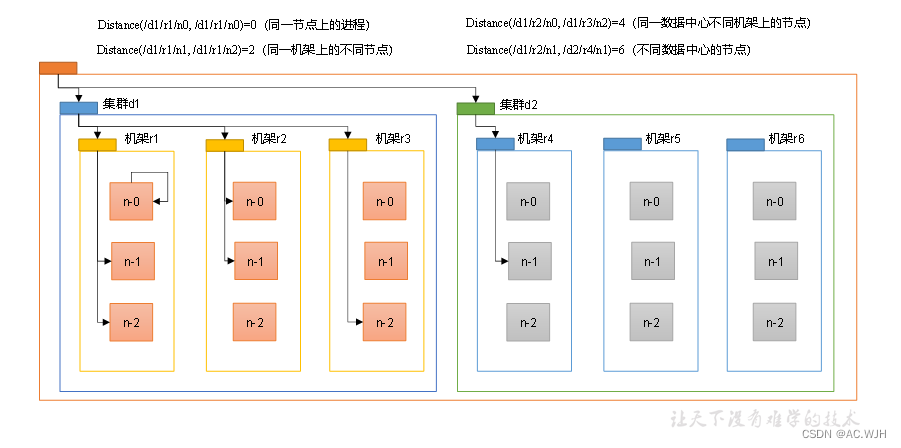
这里可以用离散数学中的树来理解,能秒懂这个距离的计算
NameNode和SecondaryNameNode
NN和2NN的工作机制

1)第一阶段:NameNode启动
(1)第一次启动NameNode格式化后,创建Fsimage和Edits文件。如果不是第一次启动,直接加载编辑日志和镜像文件到内存。
(2)客户端对元数据进行增删改的请求。
(3)NameNode记录操作日志,更新滚动日志。
(4)NameNode在内存中对元数据进行增删改。
2)第二阶段:Secondary NameNode工作
(1)Secondary NameNode询问NameNode是否需要CheckPoint。直接带回NameNode是否检查结果。
(2)Secondary NameNode请求执行CheckPoint。
(3)NameNode滚动正在写的Edits日志。
(4)将滚动前的编辑日志和镜像文件拷贝到Secondary NameNode。
(5)Secondary NameNode加载编辑日志和镜像文件到内存,并合并。
(6)生成新的镜像文件fsimage.chkpoint。
(7)拷贝fsimage.chkpoint到NameNode。
(8)NameNode将fsimage.chkpoint重新命名成fsimage。
Fsimage和Edits解析

1)ovi查看Fsimage文件
基本语法 : hdfs oiv -p 文件类型 -i镜像文件 -o 转换后文件输出路径
[atguigu@hadoop102 current]$ pwd
/opt/module/hadoop-3.1.3/data/dfs/name/current
[atguigu@hadoop102 current]$ hdfs oiv -p XML -i fsimage_0000000000000000025 -o /opt/module/hadoop-3.1.3/fsimage.xml
[atguigu@hadoop102 current]$ cat /opt/module/hadoop-3.1.3/fsimage.xml2)oev 查看Edits文件
基本语法 :hdfs oev -p 文件类型 -i编辑日志 -o 转换后文件输出路径
[atguigu@hadoop102 current]$ hdfs oev -p XML -i edits_0000000000000000012-0000000000000000013 -o /opt/module/hadoop-3.1.3/edits.xml
[atguigu@hadoop102 current]$ cat /opt/module/hadoop-3.1.3/edits.xml














 220
220











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









