







import requests
r=requests.get("http://www.baidu.com")
print(r.status_code)#用status_code来确定页面状态是否正常
type(r)
r.headersrequests库入门
- status_code可以用来检验网页状态是否正常
- type(r)返回r的类型
- r.headers返回该页面头部信
运行结果如下:
返回的头部信息:
requests对象属性
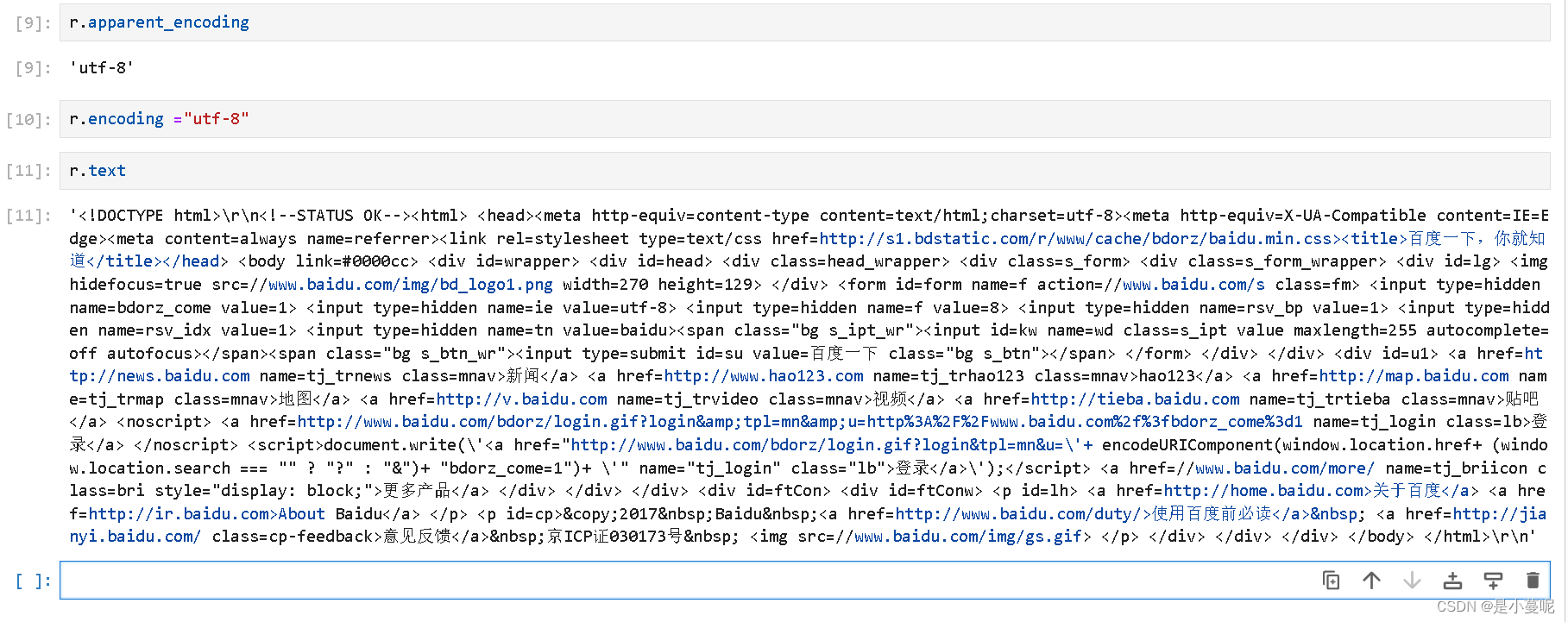
属性 说明 r.status_code HTTP请求返回状态,200表示连接成功,404表示失败 r.text HTTP响应内容的字符串形式,即url对应的页面内容 r.encoding 从HTTPheader中猜测的响应内容编码方式 r.apparent_encoding 从内容中分析出的内容编码方式 r.content HTTP响应内容的二进制形式 r.encoding和r.appatren_encoding的区别
r.encoding是从HTTP头部信息中的charset中获取的,当header中不存在charset时,则认为编码为“ISO-8859-1”
r.apparent_encoding则是从网页内容中分析出的编码形式
所以当我们利用r.text查看网页内容时,可看到返回是乱码的
此时利用r.apparent_encoding获取页面内容编码后将内容方式赋值给encoding后再次查看页面内容时则能正确解读后;所以当使用encoding不能正确解码内容时,我们就使用apparent_encoding。



requests库代码框架
import requests
def getHTMLText(url):
try:
r.requests.get(url,timeout=30)
r.raise_for_status#如果状态不是200,则会引发HTTPError
r.encoding=r.apparent_encoding#使得解码正常
return r.text
except:
return"产生错误"
if __name__=="__main__":
url="http//:www.baidu.com"
print(getHTMLText(url))













 7万+
7万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









