






1. 爬虫及爬虫的步骤
1. 爬虫是什么?
爬虫就是写一段代码让计算机模仿人类自动访问网站。
2. 爬虫的作用
爬虫可以代替人们自动地在互联网中进行数据信息的采集与整理。
比如,可以爬取国庆节期间丽江客栈的价格。
比如,可以抢票,可以批量下载图片、文档、视频等等。
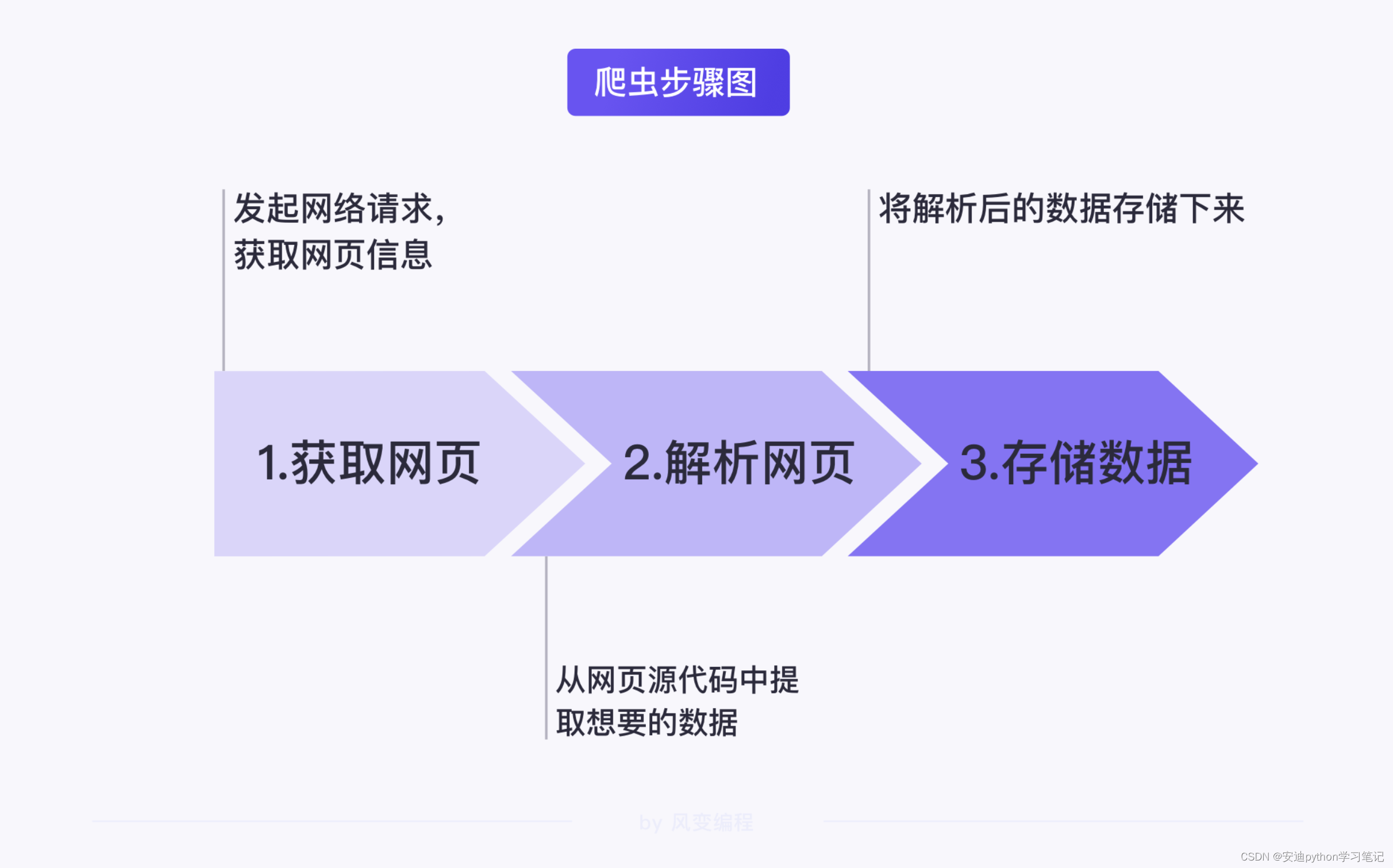
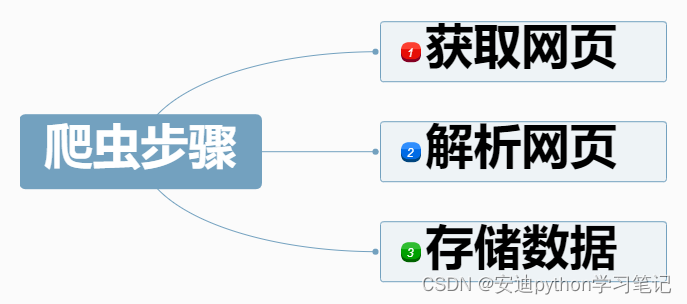
3. 爬虫步骤
【爬虫通常分为3步】
-
获取网页
-
解析网页
-
存储数据
【备注】
图片来源于《风变编程》。
3.1 获取网页
获取网页既获取网页信息。
在网络爬虫技术中这里获取的就是网页源代码。
3.2 解析网页
解析网页,指的是从网页源代码中提取想要的数据。
由于网页的结构有一定的规则,配合 Python 的一些第三方库我们可以高效地从中提取网页数据。
解析网页就是通过一定的方法从网页源代码中提取到我们要的数据。
这些数据可能是视频的链接、图片的下载地址、文件的标题等等。
3.3 存储数据
存储数据就是将获取的数据以某种形式(文字、图片、视频等)存储下来。
存储其实就是一个写并保存的过程。
将提取到的数据写入csv、Word、Excel或数据库中,或者是保存到文件夹等等。
4. 总结














 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









