







缓存穿透
- 缓存穿透 :缓存穿透是指查询一个一定不存在的数据,如果从存储层查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,可能导致数据库挂掉。(这种情况大概率是遭到了攻击)
- 常见的解决方案有两种:
- 缓存空对象
- 优点:实现简单,维护方便
- 缺点:
- 额外的内存消耗
- 可能造成数据短期的不一致(一开始查询不到,缓存存储上了null值,后面数据库添加上了,但是缓存中还是null,查询的时候就会返回缓存中的null了,这就导致了数据不一致了)
- 布隆过滤(准确性不能够保证)
- 优点:内存占用较少,没有多余key
- 缺点:
- 实现复杂
- 存在误判可能
- 缓存空对象
- 缓存穿透的其他解决方案:
- 增强id的复杂度,避免被猜测id规律
- 做好数据的基础格式校验
- 加强用户权限校验
- 做好热点参数的限流
解决方案一:缓存空对象
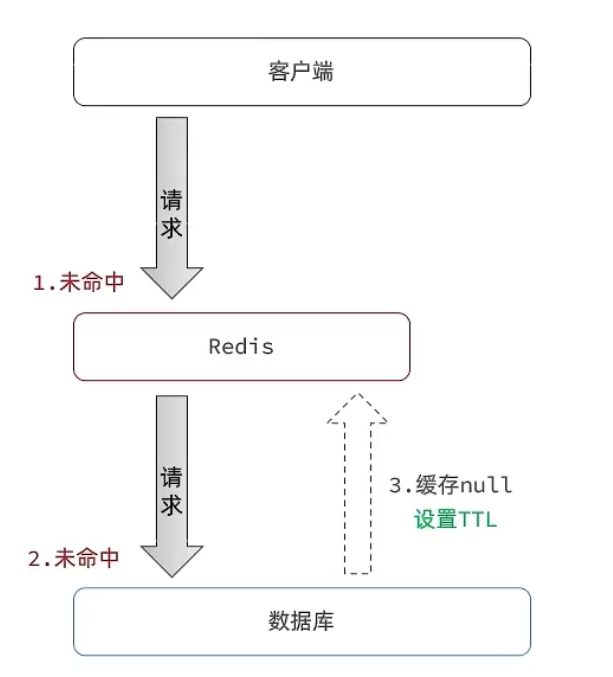
- 缓存空对象思路分析:当我们客户端访问不存在的数据时,先请求redis,但是此时redis中没有数据,此时会访问到数据库,但是数据库中也没有数据,这个数据穿透了缓存,直击数据库,我们都知道数据库能够承载的并发不如redis这么高,如果大量的请求同时过来访问这种不存在的数据,这些请求就都会访问到数据库,简单的解决方案就是
哪怕这个数据在数据库中也不存在,我们也把这个数据存入到redis中去,这样,下次用户过来访问这个不存在的数据,那么在redis中也能找到这个数据就不会进入到缓存了。(如果数据库里面的数据修改了,对应的缓存会被删除的,上面的缓存更新策略里面说过)
- 案例实现:
- 如果这个数据不存在,我们不会返回404 ,还是会把这个数据写入到Redis中,并且将value设置为空,当再次发起查询时,我们如果发现命中之后,判断这个value是否是null,如果是null,则是之前写入的数据,证明是缓存穿透数据,如果不是,则直接返回数据。
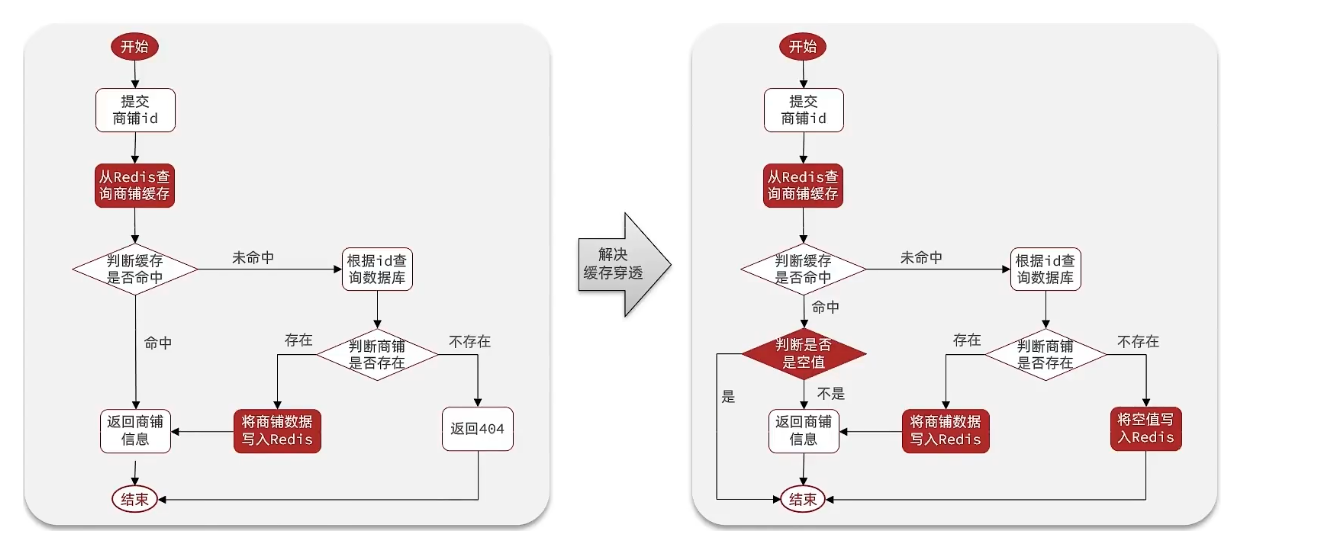
- 如果这个数据不存在,我们不会返回404 ,还是会把这个数据写入到Redis中,并且将value设置为空,当再次发起查询时,我们如果发现命中之后,判断这个value是否是null,如果是null,则是之前写入的数据,证明是缓存穿透数据,如果不是,则直接返回数据。
解决方案二:布隆过滤(常用)
-
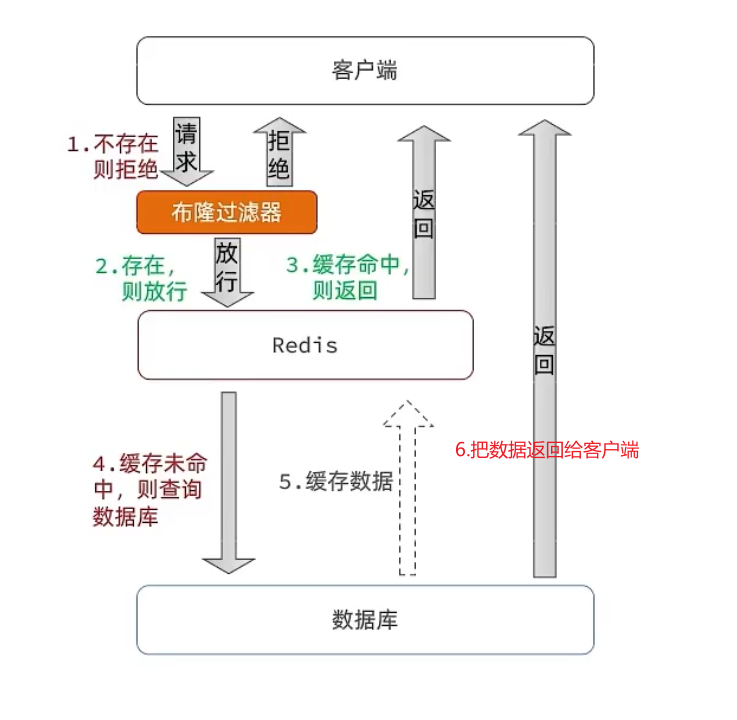
布隆过滤:布隆过滤器其实采用的是哈希思想来解决这个问题,通过一个
庞大的二进制数组,走哈希思想去判断当前这个要查询的这个数据是否存在,如果布隆过滤器判断存在,则放行,这个请求会去访问redis,哪怕此时redis中的数据过期了,但是数据库中一定存在这个数据,在数据库中查询出来这个数据后,再将其放入到redis中,假设布隆过滤器判断这个数据不存在,则直接返回。- 这种方式优点在于节约内存空间,存在误判,误判原因在于:布隆过滤器走的是哈希思想,只要哈希思想,就可能存在哈希冲突
-
使用布隆过滤器的前提:
在做缓存预热的时候,需要把布隆过滤器预热了。 -
缓存预热:缓存预热就是系统上线后,将相关的缓存数据直接加载到缓存系统。这样就可以避免在用户请求的时候,先查询数据库,然后再将数据缓存的问题!用户直接查询事先被预热的缓存数据!
-
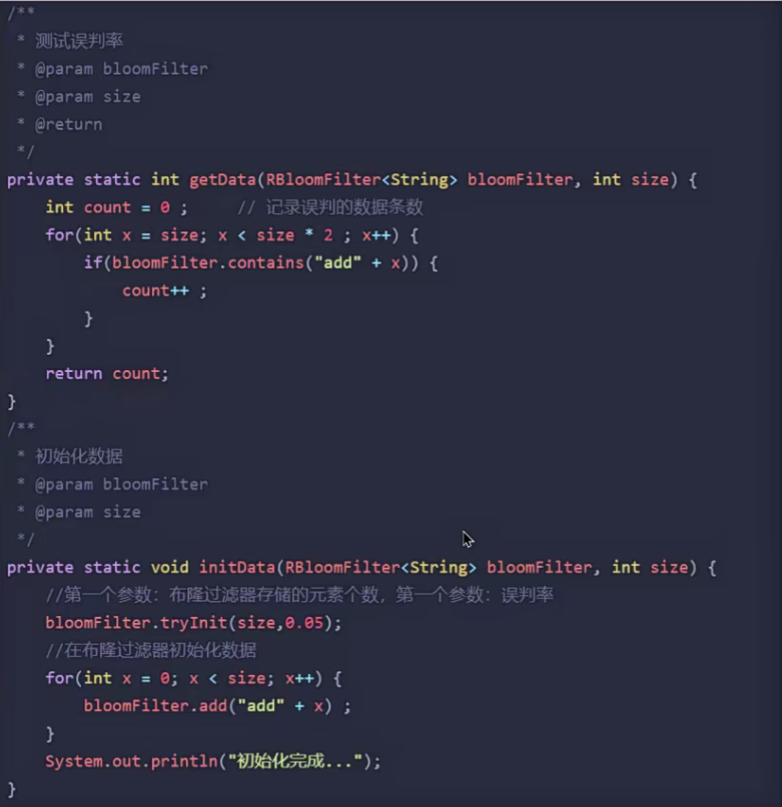
案例描述:解决思路
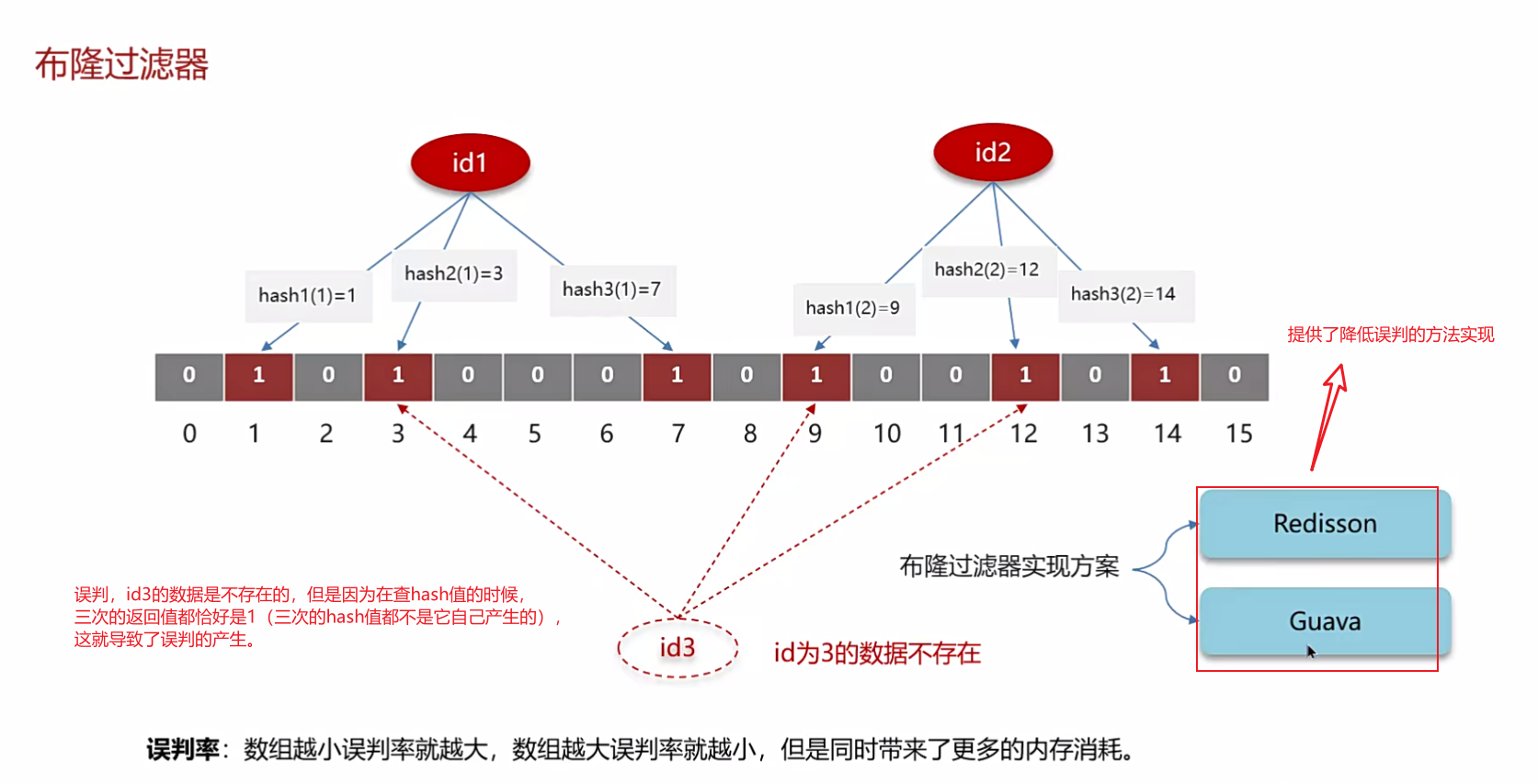
- 布隆过滤器主要是
用于检索一个元素是否在一个集合中。以使用的是redisson实现的布隆过滤器为例子。- 它的底层主要是
先去初始化一个比较大数组,里面存放的二进制0或1。在一开始都是0,当一个key来了之后经过3次hash计算,模余数组长度找到数据的下标然后把数组中原来的0改为1,这样的话,三个数组的位置就能标明一个key的存在。查找的过程也是一样的。
- 它的底层主要是
- 当然是有缺点的,布隆过滤器有可能会
产生一定的误判,我们一般可以设置这个误判率,大概不会超过5%,其实这个误判是必然存在的,要不就得增加数组的长度,其实已经算是很划分了,5%以内的误判率一般的项目也能接受,不至于高并发下压倒数据库。
- 布隆过滤器主要是
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









