







一、MyISAM 引擎下的索引
MyISAM 存储引擎不支持行级锁,只有表级锁;不支持事务,也不支持外键,主要面向 OLAP 应用,是 MySQL 数据库5.5.8 版本之前默认的存储引擎,MyISAM 适用于不需要关心事务,读多写少的场景。
每张 MyISAM 表在磁盘上会创建三个文件:.frm,.MYD 和 .MYI,其中 .frm 文件为表结构文件,每个存储引擎都会有这个文件,.MYD 文件用来存储数据,.MYI 文件用来存储索引,也就是说 MyISAM 表的数据和索引是分开存储的,这一点和 InnoDB 不一样。
在 MySQL 5.0 之前,MyISAM 引擎默认支持的表只有 4GB,如果要修改默认表大小的话,需要修改参数 MAX_ROWS 和AVG_ROW_LENGTH 的大小,不过这一点在 MySQL5.0 之后得到了改善,默认大小为 256TB,这个大小在绝大部分应用应该都是可以满足要求的。
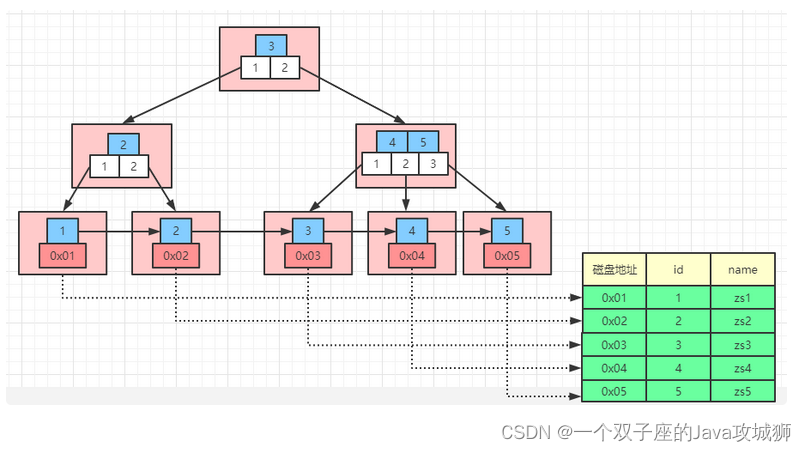
MyISAM 的 B+ 树里面,叶子节点存储的是当前索引的值以及当前数据文件对应的磁盘地址。所以如果从索引文件 .MYI 中找到键值后,会根据其存储的磁盘地址到数据文件 .MYD 中获取相应的数据记录,在 MyISAM 引擎中,主键索引和非主键索引没有差别,都是一样存储,查询速度也没有差别,MyISAM 索引大致结构如下图所示:
二、InnoDB 引擎下的索引
InnoDB 存储引擎支持事务,主要是为了面向在线事务处理(OLTP)的应用而生,支持行锁和外键,其通过使用多版本并发控制(MVCC)来提升高并发性能,实现了 SQL92 标准的 4 种隔离级别。
从 MySQL 数据库 5.5.8 版本开始,InnoDB 为 MySQL 默认存储引擎。每张 InnoDB 表在磁盘上会创建两个文件:.frm 和 .ibd,其中 .frm 文件和 MyISAM 引擎一样,用来存储表结构的,.ibd 文件存储的是索引和数据,InnoDB 中索引和数据放在同一个文件中。
在 InnoDB 引擎中的 B+ 树叶子节点直接存储的是整条数据记录,而不是记录磁盘地址。InnoDB 引擎和 MyISAM 引擎还有一个最大的不同就是 InnoDB 引擎是以主键索引来组织数据的(主键索引和非主键索引的存储结构是不同的),InnoDB 存储引擎中这种组织数据的方式被称之为索引组织表(index-organized table),其中的主键索引也被称之为聚集索引(clustered index)。
聚集索引
聚集索引(又称之为聚簇索引),聚集的术语表示的是索引键值和数据紧凑的存储在一起。而数据又不可能同时存在两个地方,所以 InnoDB 每张表都有且只有一个聚集索引。换言之,也就是说每张表都必须有且只有一个主键。说到这里可能很多人就要反问了,我建表的时候没有主键索引也可以建表成功,那么这又是为什么呢?
其实如果我们没有显示的指定主键,InnoDB 会选择一个非空的唯一索引列作为主键,如果我们也没有创建非空的唯一索引,那么 InnoDB 就会选择其自己内置的一个 6 字节长的 ROWID 自增列作为主键。InnoDB 中聚集索引叶子节点直接存储的是整条数据,也就是说索引搜索到叶子节点之后就可以直接返回数据了,无需再去磁盘获取数据。
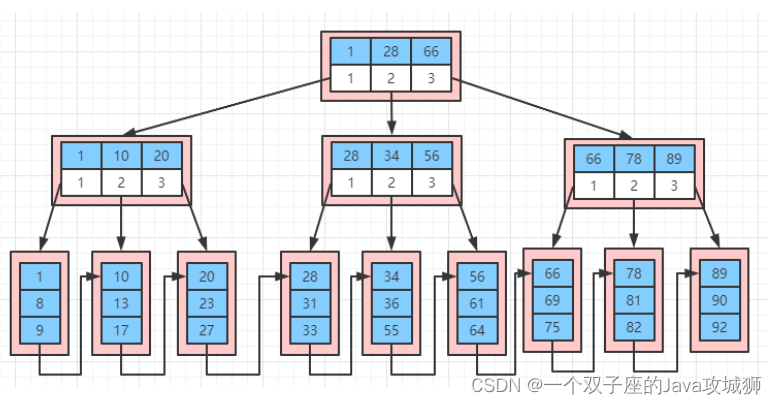
InnoDB 中聚集索引大致结构如下图所示:
接下来我们来验证一下 rowid 是否存在
进入数据库之后,我们创建两张表,一张表带有主键索引,一张表只带了一个普通索引
CREATE TABLE `test_index` (
`id` INT NOT NULL AUTO_INCREMENT,
`a` INT DEFAULT NULL,
`b` INT DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=INNODB DEFAULT CHARSET=utf8;
CREATE TABLE `test_noIndex` (
`id` int NOT NULL,
`a` int DEFAULT NULL,
`b` int DEFAULT NULL,
KEY `a_index` (`a`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
建表之后,在上面的两张表中分别插入两条数据:
INSERT INTO `test_index` (`id`, `a`, `b`) VALUES('1','11','11');
INSERT INTO `test_index` (`id`, `a`, `b`) VALUES('2','22','22');
INSERT INTO `test_noIndex` (`id`, `a`, `b`) VALUES('1','11','11');
INSERT INTO `test_noIndex` (`id`, `a`, `b`) VALUES('2','22','22');
最后执行以下两句查询:
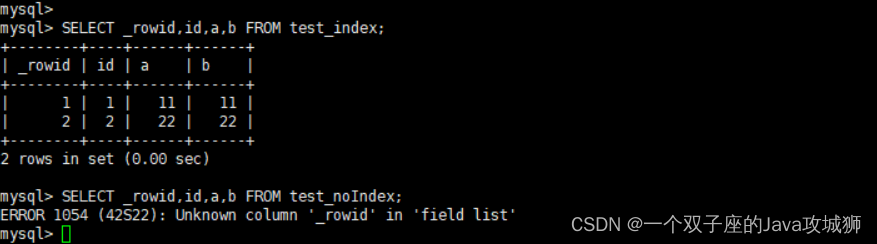
SELECT _rowid,id,a,b FROM test_index;
SELECT _rowid,id,a,b FROM test_noIndex;
可以看到,当我们存在主键索引时候,_rowid 就等于主键索引,而当不存在主键索引时,默认会采用其内置的算法,这个时候我们就无法直接查询
非聚集索引
除了主键索引之外的其他索引都是非聚集索引(Secondary Indexes),既然聚集索引的索引键值和数据行存放在一起,而聚集索引又只有一个,那么非聚集索引又是怎么存储数据的呢?
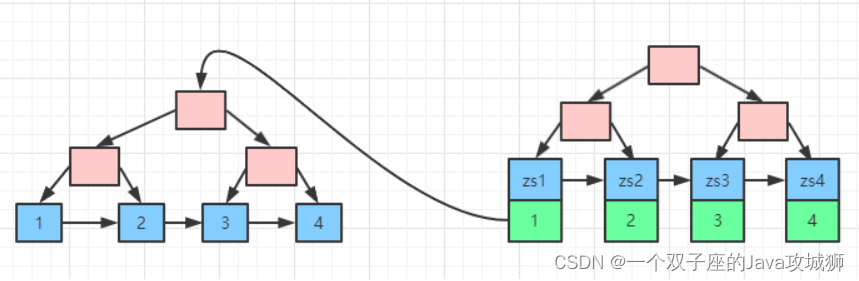
非聚集索引的叶子节点存储的是当前索引的键值和主键索引的键值。大致结构如下图所示(右边为非聚集索引,左边为聚集索引):
所以非聚集索引查询数据和聚集索引查询数据是不同的,因为非聚集索引的叶子节点只有当前索引的键值和主键的键值,也就是说查询数据的时候获取到非聚集索引的叶子节点只能拿到当前索引值和主键索引值。
回表
回表指的就是非聚集索引从叶子节点拿到数据(主键的键值)之后,还需要再根据主键键值去扫描主键索引的 B+ 树,这种操作就叫做回表。
三、为什么主键索引比其他索引快
上面提到的回表操作需要扫描两颗 B+ 树,这也就是为什么在 InnoDB 中主键索引的效率相比较其他索引是最高的,因为主键索引只需要扫描一棵 B+ 树。
下面我们来测试一下主键索引和非主键索引的速度。
首先创建一张表,这张表里面还有一个主键索引和一个普通索引:
CREATE TABLE `test_speed` (
`id` int NOT NULL,
`user_name` varchar(16) NOT NULL,
`job` varchar(16) NOT NULL,
`company` varchar(16) DEFAULT NULL,
PRIMARY KEY (`id`),
KEY `index_company` (`company`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8;
然后执行以下脚本,批量插入 100 万数据:
DROP PROCEDURE IF EXISTS proc1;
DELIMITER ;;
CREATE PROCEDURE proc1()
BEGIN
DECLARE i INT;
DECLARE company VARCHAR(128);
SET i=1;
WHILE(i<=250000) DO
IF i%6 = 0
THEN SET company= '证券';
ELSEIF i%6 = 1
THEN SET company= '银行';
ELSEIF i%6 = 2
THEN SET company= '保险';
ELSEIF i%6 = 3
THEN SET company= '科技';
ELSEIF i%6 = 4
THEN SET company= '金融';
ELSE
SET company ='传统';
END IF;
INSERT INTO test_speed VALUES(i, CONCAT('孤狼',i), CONCAT('程序员',i),company);
SET i=i+1;
END WHILE;
END;;
DELIMITER ;
CALL proc1();
因为一次性插入了 25 万数据,最后调用存储过程的时候会有点慢,大家可以耐心的等待一下,这里选择插入 25 万是为了对比的时候速度上能更直观的看出对比结果,数据量太少会导致对比不明显(25 万数据插入完成自测环境下是将近 10 分钟 )。
数据初始化完成之后,我们继续执行以下两句 sql 进行对比:
SELECT * FROM test_speed ORDER BY id LIMIT 240000,5;-- 使用主键索引(聚集索引)
SELECT * FROM test_speed ORDER BY company LIMIT 240000,5;-- 使用非主键索引(非聚集索引)
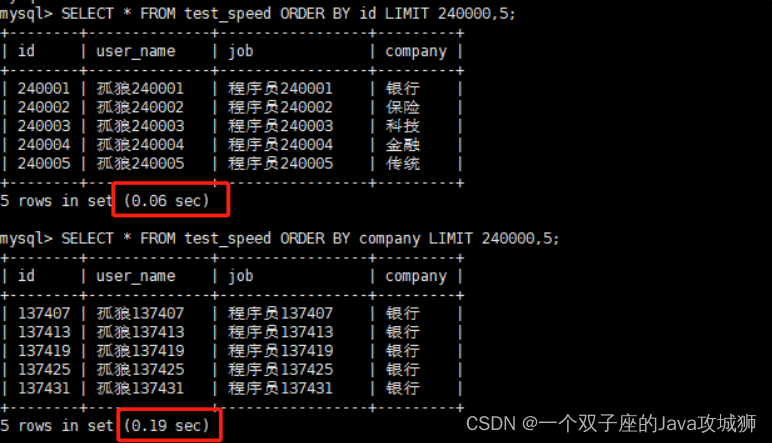 从结果中,可以很明显的看到,使用主键索引相比较非主键索引,速度会更快。
从结果中,可以很明显的看到,使用主键索引相比较非主键索引,速度会更快。
覆盖索引
上面我们说到了回表操作,那么就还有这么一种场景是不需要回表的:比如说我们一个查询只需要查询当前索引的值和主键的值,而不需要查其他数据,这时候就不需要回表了,直接就可以返回,这种也称之为覆盖索引。
因为非聚集索引中存储了当前索引的值和主键的值,所以如果我们不需要获取当前索引值和主键索引值之外的其他信息,那么在拿到主键索引值之后就可以直接返回,也就是只需要扫描一棵非聚集索引的 B+ 树,而因为非聚集索引不存储数据,所以非聚集索引的 B+ 树占用的空间是小于主键索引 B+ 树的,所以查询速度会更快。
这也是为什么通常不建议写 select * 语句的原因,因为 select * 肯定无法用到覆盖索引(除非整张表的字段是一个联合索引),而覆盖索引可以少扫描一棵聚集索引的 B+ 树,而且因为辅助索引不会存储整条数据,所以大小也要远小于聚集索引的 B+ 树,故而对性能有较大的提升。
需要注意的是,MyISAM 引擎中如果查找的数据也包含在索引内,不需要去磁盘找数据,也可以认为是覆盖索引,但是一般情况下我们说的覆盖索引都是针对 InnoDB 引擎而言。
接下来我们再测试一下使用到覆盖索引和使用主键索引的查询速度对比:
SELECT * FROM test_speed ORDER BY id LIMIT 240000,5;-- 使用主键索引
SELECT id,company FROM test_speed ORDER BY company LIMIT 240000,5;-- 使用覆盖索引
这里的第二句话使用到了 company 字段上的索引,而 company 索引上存储了主键的值,所以当我们仅查询主键和当前使用索引的字段时,就可以直接使用到覆盖索引。
执行之后,对比结果如下图所示:
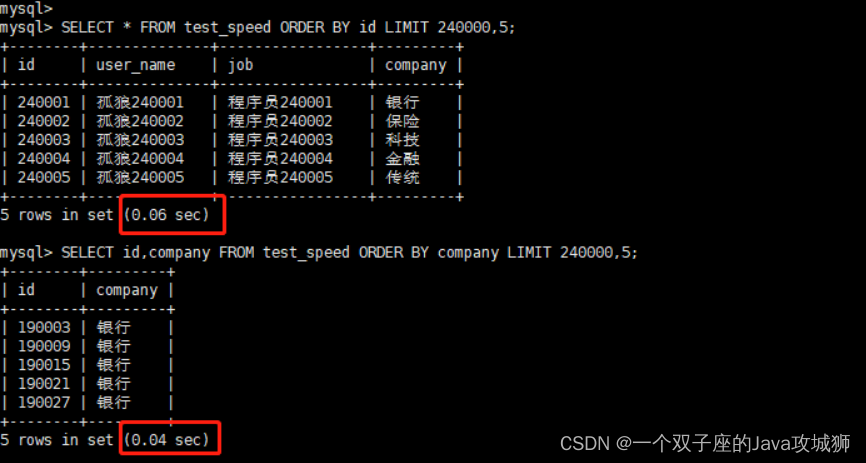
从结果也可以看到,使用覆盖索引的速度会比主键索引更快。当然,因为我们的测试数据相对比较简单,所以有时候数据量过少的话对比不会很明显。
















 1167
1167











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











