






简要介绍
想要了解更多,可以看看我的个人博客 (ldf.icu)
最近看了shift-gcn的论文并学习了他的代码
收获最大的就是用它的作为例子学习了一点CUDA编程,基于CUDA编程可以利用GPUs的并行计算引擎来更加高效地解决比较复杂的计算难题。
对于一种典型的扩展情况,比如我们要设计一个全新的C++底层算子,其过程其实就三步:
第一步:使用C++编写算子的forward函数和backward函数
第二步:将该算子的forward函数和backward函数使用pybind11绑定到python上
第三步:使用setuptools/JIT/CMake编译打包C++工程为so文件
项目结构如下所示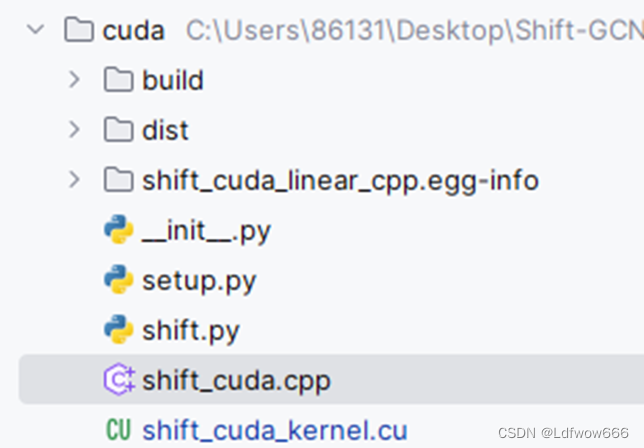
代码编写
shift-gcn中用CUDA编程实现的shift算子,用于时间的shift操作,公式如下所示:
先看看代码,做了注释说明,精华都在注释里
shift_cuda_kernel.cu
咱们需要些shift算子的forward函数和backward函数,咱们先在shift_cuda_kernel.cu写完底层的代码之后再封装到shift_cuda.cpp中。
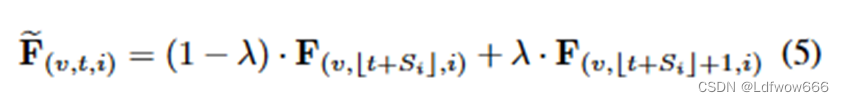
#include <ATen/ATen.h>
#include <cuda.h>
#include <cuda_runtime.h>
#include <vector>
#include <math.h>
#include <iostream>
namespace {
template <typename scalar_t>//c++的模板声明方法,使得函数、类或数据结构可以在不同的数据类型下工作
__global__ void shift_cuda_forward_kernel(//shift正向传递的操作的核函数
const scalar_t* __restrict__ input,
//传入的特征x,const scalar_t* __restrict__ 通过这种方式传入数据是cuda编程的特性,每个线程负责处理不同的数据。
//通过使用指针,可以在 GPU 设备上直接访问底层数据,从而提高计算效率。
scalar_t* output,//保存结果
scalar_t* xpos, //骨架维度的偏移值数组
scalar_t* ypos,//时间维度的偏移值数组
const int batch,//batch数量
const int channel,//通道数量
const int bottom_height,//时间维度的大小
const int bottom_width,//骨架点的数量,如果使用coco keypoints格式就是17
const int top_height,//时间大小除以步长(stride)
const int top_width,//骨架点数量
const int stride) //时间维度的步长
{
const int index = blockIdx.x * blockDim.x + threadIdx.x;//通过块id乘以块里边的线程数,加上在该块的线程的id,计算出是第几个进程
//(这里是一维的grid和一维的block,所以可以只用x计算索引,2维和三维有另外的计算方式)
//cuda编程中有块和线程,一个块里有多个线程,一般用一个线程运行一个核函数
if (index < batch*channel*top_height*top_width)
{
const int top_sp_dim = top_height * top_width;
//为骨架数乘以时间除以步长的值一个通道考虑步长所有数据的个数
const int bottom_sp_dim = bottom_height * bottom_width;
//时间乘以骨架点数,一个通道所有数据的个数
const int n = index/(channel * top_sp_dim);//第几个批次(考虑步长)
const int idx = index%(channel * top_sp_dim);//批次中第几个数据(考虑步长)
const int c_out = idx/top_sp_dim;//这个批次中第几个通道(考虑步长)
const int c_in = c_out;//这个批次中第几个通道(考虑步长)
const int sp_idx = idx%top_sp_dim; //通道里第几个数据(考虑步长)
const int h = sp_idx/top_width;//这个通道中第几帧
const int w = sp_idx%top_width;//这帧中第几个节点
const scalar_t* data_im_ptr = input + n*channel*bottom_sp_dim + c_in*bottom_sp_dim; //使得指针指向当前通道的第一个数据的位置,
//因为传入的数据在调用这个核函数时转换成了一维的数据所以可以这样处理。
const int h_offset = h * stride;//当前为第几帧
const int w_offset = w;// 当前为帧中第几个节点
scalar_t val = 0;
const scalar_t x = xpos[c_in];//该通道的骨架维度的可偏移参数,未训练时的初始值为0
const scalar_t y = ypos[c_in];//该通道的时间维度的可偏移参数,未训练时的初始值为0
//假设骨架维度的偏移值为u+du,时间维度的偏移值为w+dw,du为偏移值的小数部分,dw同理
int h_im, w_im;
int x1 = floorf(x);//向下取整u
int x2 = x1+1;//u+1
int y1 = floorf(y);//向下取整w
int y2 = y1+1;//w+1
h_im = h_offset + y1;//当前帧偏移w的位置
w_im = w_offset + x1;//当前骨架的位置偏移u的位置
scalar_t q11 = (h_im >= 0 && w_im >= 0 && h_im < bottom_height && w_im < bottom_width) ? data_im_ptr[h_im*bottom_width + w_im] : 0;
//如果偏移的位置不超过当前通道边界则取该值,如果超过边界则取0,下边同理
h_im = h_offset + y1;//当前帧偏移w的位置
w_im = w_offset + x2;//当前骨架的位置偏移u+1的位置
scalar_t q21 = (h_im >= 0 && w_im >= 0 && h_im < bottom_height && w_im < bottom_width) ? data_im_ptr[h_im*bottom_width + w_im] : 0;
h_im = h_offset + y2;//当前帧偏移w+1的位置
w_im = w_offset + x1;//当前骨架的位置偏移u的位置
scalar_t q12 = (h_im >= 0 && w_im >= 0 && h_im < bottom_height && w_im < bottom_width) ? data_im_ptr[h_im*bottom_width + w_im] : 0;
h_im = h_offset + y2;//当前帧偏移w+1的位置
w_im = w_offset + x2;//当前骨架的位置偏移u+1的位置
scalar_t q22 = (h_im >= 0 && w_im >= 0 && h_im < bottom_height && w_im < bottom_width) ? data_im_ptr[h_im*bottom_width + w_im] : 0;
scalar_t dx = x-x1;//du,骨架维度的偏移值的小数部分
scalar_t dy = y-y1;//dw,时间维度的偏移值的小数部分
val = q11*(1-dx)*(1-dy) + q21*dx*(1-dy) + q12*(1-dx)*dy + q22*dx*dy;
//用两个可偏移参数小数作为权重,权重之和为1
output[index] = val;//保存在out数组中
}
}
template <typename scalar_t>
__global__ void Shift_Bottom_Backward_Stride1(//通过负的偏移值将梯度传递给上一层(反向shift操作),大抵相当于将卷积中180度反转,将下一层的梯度乘以权重后传递给上一层,这个函数是不考虑步长的,步长默认为1
const scalar_t* __restrict__ grad_output,//每个不同进程处理不同的梯度(下一层传过来的)
scalar_t* grad_input,//用于返回给上一层的梯度值
scalar_t* xpos,//ctx保存的骨架维度的偏移值
scalar_t* ypos,//ctx保存的时间维度的偏移值
const int batch,//批次数
const int channel,//通道数
const int bottom_height,//同一通道的帧数
const int bottom_width) //同一帧的骨架节点数
{
const int index = blockIdx.x * blockDim.x + threadIdx.x;//和上一个核函数一样用于计算本线程是第几个线程
if (index < batch*channel*bottom_height*bottom_width)
{
const int top_sp_dim = bottom_height * bottom_width;//帧数乘以骨架的节点数,为通道的总数据大小
const int bottom_sp_dim = bottom_height * bottom_width;//和上边相等
const int n = index/(channel * bottom_sp_dim);//第几个批次
const int idx = index%(channel * bottom_sp_dim);//当前批次中第几个数据
const int c_in = idx/bottom_sp_dim;//当前批次中第几个通道
const int c_out = c_in;
const int sp_idx = idx%bottom_sp_dim;//通道中第几个数据
const int h_col = sp_idx/bottom_width;//当前通道中第几帧
const int w_col = sp_idx%bottom_width;//当前帧中第几个数据
const scalar_t* top_diff_ptr = grad_output + n*channel*top_sp_dim + c_out*top_sp_dim;。//将下一层传入进来的梯度的指针指向当前维度的第一个数据
const int h_offset = h_col;
const int w_offset = w_col;
scalar_t val = 0;
const scalar_t x = -xpos[c_in];//反向的偏移值
const scalar_t y = -ypos[c_in];//反向的偏移值
int h_im, w_im;
int x1 = floorf(x);//-u
int x2 = x1+1;//-(u-1)
int y1 = floorf(y);//-w
int y2 = y1+1;//-(w-1)
//q11
scalar_t q11 = 0;
h_im = (h_offset + y1);
w_im = (w_offset + x1);
q11 = (h_im >= 0 && w_im >= 0 && h_im < bottom_height && w_im < bottom_width) ? top_diff_ptr[h_im*bottom_width + w_im] : 0;//取相对(-w,-u)的梯度值
//q21
scalar_t q21 = 0;
h_im = (h_offset + y1);
w_im = (w_offset + x2);
q21 = (h_im >= 0 && w_im >= 0 && h_im < bottom_height && w_im < bottom_width) ? top_diff_ptr[h_im*bottom_width + w_im] : 0;//取相对(-w,-u+1)的梯度值
//q12
scalar_t q12 = 0;
h_im = (h_offset + y2);
w_im = (w_offset + x1);
q12 = (h_im >= 0 && w_im >= 0 && h_im < bottom_height && w_im < bottom_width) ? top_diff_ptr[h_im*bottom_width + w_im] : 0;//取相对(-w+1,-u)的梯度值
//q22
scalar_t q22 = 0;
h_im = (h_offset + y2);
w_im = (w_offset + x2);
q22 = (h_im >= 0 && w_im >= 0 && h_im < bottom_height && w_im < bottom_width) ? top_diff_ptr[h_im*bottom_width + w_im] : 0;//取相对(-w+1,-u+1)的梯度值
scalar_t dx = x-x1;//同样求小数部分作为权重
scalar_t dy = y-y1;
val = q11*(1-dx)*(1-dy) + q21*dx*(1-dy) + q12*(1-dx)*dy + q22*dx*dy;
//因为通道相同的的话,他的偏移参数相同,所以就像卷积核移动一样可以遍历所有的点,
//将下一层的梯度值乘以对应的权重,然后返回给上一层。
grad_input[index] = val;
}
}
template <typename scalar_t>
__global__ void Shift_Bottom_Backward(//这个函数与上面的函数作用是一样的只是这个考虑步长,所以就不做解释了
const scalar_t* __restrict__ grad_output,
scalar_t* grad_input,
scalar_t* xpos,
scalar_t* ypos,
const int batch,
const int channel,
const int bottom_height,
const int bottom_width)
{
const int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < batch*channel*bottom_height*bottom_width)
{
const int top_height = bottom_height/2;
const int top_width = bottom_width;
const int stride = 2;
const int top_sp_dim = top_height * top_width;
const int bottom_sp_dim = bottom_height * bottom_width;
const int n = index/(channel * bottom_sp_dim);
const int idx = index%(channel * bottom_sp_dim);
const int c_in = idx/bottom_sp_dim;
const int c_out = c_in;
const int sp_idx = idx%bottom_sp_dim;
const int h_col = sp_idx/bottom_width;
const int w_col = sp_idx%bottom_width;
const scalar_t* top_diff_ptr = grad_output + n*channel*top_sp_dim + c_out*top_sp_dim;
const int h_offset = h_col;
const int w_offset = w_col;
scalar_t val = 0;
const scalar_t x = -xpos[c_in];
const scalar_t y = -ypos[c_in];
int h_im, w_im;
int x1 = floorf(x);
int x2 = x1+1;
int y1 = floorf(y);
int y2 = y1+1;
//q11
scalar_t q11 = 0;
h_im = (h_offset + y1);
w_im = (w_offset + x1);
if(h_im%stride == 0)
{
h_im=h_im/stride;
q11 = (h_im >= 0 && w_im >= 0 && h_im < top_height && w_im < top_width) ? top_diff_ptr[h_im*top_width + w_im] : 0;
}
//q21
scalar_t q21 = 0;
h_im = (h_offset + y1);
w_im = (w_offset + x2);
if(h_im%stride == 0)
{
h_im=h_im/stride;
q21 = (h_im >= 0 && w_im >= 0 && h_im < top_height && w_im < top_width) ? top_diff_ptr[h_im*top_width + w_im] : 0;
}
//q12
scalar_t q12 = 0;
h_im = (h_offset + y2);
w_im = (w_offset + x1);
if(h_im%stride == 0)
{
h_im=h_im/stride;
q12 = (h_im >= 0 && w_im >= 0 && h_im < top_height && w_im < top_width) ? top_diff_ptr[h_im*top_width + w_im] : 0;
}
//q22
scalar_t q22 = 0;
h_im = (h_offset + y2);
w_im = (w_offset + x2);
if(h_im%stride == 0)
{
h_im=h_im/stride;
q22 = (h_im >= 0 && w_im >= 0 && h_im < top_height && w_im < top_width) ? top_diff_ptr[h_im*top_width + w_im] : 0;
}
scalar_t dx = x-x1;
scalar_t dy = y-y1;
val = q11*(1-dx)*(1-dy) + q21*dx*(1-dy) + q12*(1-dx)*dy + q22*dx*dy;
grad_input[index] = val;
}
} // namespace
template <typename scalar_t>//下面这三个函数用于原子加法,在代码中没有被调用
__inline__ __device__ void myAtomicAdd(scalar_t *buf, scalar_t val);
template <>
__inline__ __device__ void myAtomicAdd<float>(float *buf, float val)
{
atomicAdd(buf, val);
}
template <>
__inline__ __device__ void myAtomicAdd<double>(double *buf, double val)
{
//Not Supported
}
template <typename scalar_t>
__global__ void Shift_Position_Backward(//上面的两个函数都是用于求返回给上一级的梯度值,这个函数是求偏移值的梯度
const scalar_t* __restrict__ input,//正向传递的输入值
const scalar_t* __restrict__ grad_output,//下一层传过来的梯度值
scalar_t* grad_input,//返回给上一层的梯度值
scalar_t* xpos,//骨架维度的偏移值
scalar_t* ypos,//时间维度的偏移值
scalar_t* grad_xpos_bchw,//骨架维度偏移值的梯度值
scalar_t* grad_ypos_bchw,//时间维度的偏移值的梯度值
const int batch,//批次数
const int channel,//通道数
const int bottom_height,//帧数
const int bottom_width,//骨架点数
const int stride) //步长
{
const int index = blockIdx.x * blockDim.x + threadIdx.x;//计算是第几个进程
const int top_height = bottom_height/stride;
const int top_width = bottom_width;
if (index < batch*channel*top_height*top_width)
{
const int top_sp_dim = top_height * top_width;//一个通道的总数据数(考虑步长)
const int bottom_sp_dim = bottom_height * bottom_width;//一个通道的总数据数
const int n = index/(channel * top_sp_dim);//第几个批次(考虑步长)
const int idx = index%(channel * top_sp_dim);//这个批次内第几个数据(考虑步长)
const int c_mul = 1;
const int c_out = idx/top_sp_dim;//当前批次的第几个通道(考虑步长)
const int c_in = c_out/c_mul;
const int sp_idx = idx%top_sp_dim;//当前通道的第几个数据(考虑步长)
const int h = sp_idx/top_width;//当前通道的第几帧(考虑步长)
const int w = sp_idx%top_width;//当前帧内第几个节点(考虑步长)
const scalar_t* data_im_ptr = input + n*channel*bottom_sp_dim + c_in*bottom_sp_dim;//定位到当前通道的第一个数据
const int h_offset = h * stride;//当前第几帧
const int w_offset = w;//当前是第几个节点
//output : 2*(C) x (1*H*W)
const int kernel_offset = top_sp_dim;
const int c_off = c_out % c_mul;
scalar_t val_x = 0, val_y = 0;
const scalar_t shiftX = xpos[c_in];//当前通道的骨架维度的偏移值
const scalar_t shiftY = ypos[c_in];//当前通道的时间维度的偏移值
const int ix1 = floorf(shiftX);//向下取整,u
const int ix2 = ix1+1;//u+1
const int iy1 = floorf(shiftY);//w
const int iy2 = iy1+1;//w+1
const scalar_t dx = shiftX-ix1;//du,骨架维度偏移值的小数部分
const scalar_t dy = shiftY-iy1;//dw,时间偏移值的小数部分
const int h_im1 = h_offset + iy1;//u
const int h_im2 = h_offset + iy2;//u+1
const int w_im1 = w_offset + ix1;//w
const int w_im2 = w_offset + ix2;//W+1
const scalar_t q11 = (h_im1 >= 0 && w_im1 >= 0 && h_im1 < bottom_height && w_im1 < bottom_width) ? data_im_ptr[h_im1*bottom_width + w_im1] : 0;
const scalar_t q21 = (h_im1 >= 0 && w_im2 >= 0 && h_im1 < bottom_height && w_im2 < bottom_width) ? data_im_ptr[h_im1*bottom_width + w_im2] : 0;
const scalar_t q12 = (h_im2 >= 0 && w_im1 >= 0 && h_im2 < bottom_height && w_im1 < bottom_width) ? data_im_ptr[h_im2*bottom_width + w_im1] : 0;
const scalar_t q22 = (h_im2 >= 0 && w_im2 >= 0 && h_im2 < bottom_height && w_im2 < bottom_width) ? data_im_ptr[h_im2*bottom_width + w_im2] : 0;
val_x = (1-dy)*(q21-q11)+dy*(q22-q12);//在原来计算公式中对du(骨架维度偏移值的小数部分)求导得到的公式,推导过程下面有图展示,这里x与y都是标量
val_y = (1-dx)*(q12-q11)+dx*(q22-q21);//在原来计算公式中对dw(时间维度偏移值的小数部分)求导分得到的公式
grad_xpos_bchw[index] = val_x * grad_output[index];
//根据链式法则将计算结果对du求导得到值相乘得到损失函数对du的,骨架维度的梯度值放入到对应的数组内
grad_ypos_bchw[index] = val_y * grad_output[index];
//时间维度的梯度值放入到对应的数组内
//可能有的同学想问整数部分不需要求梯度值吗,这里做解释因为整数部分做了取整的操作求不了导所以不能求梯度
}
} // namespace
template <typename scalar_t>
__global__ void applyShiftConstraint(//约束偏移值的梯度变化
scalar_t* grad_xpos,
scalar_t* grad_ypos,
const int channel)
{
const int index = blockIdx.x * blockDim.x + threadIdx.x;
if (index < channel)
{
const scalar_t dx = grad_xpos[index];
const scalar_t dy = grad_ypos[index];
const scalar_t dr = sqrt(dy*dy);
if(dr!=0)
{
grad_xpos[index] = dx/dr*0.0;
grad_ypos[index] = dy/dr*0.01;
}
else // without this, the grad_ypos may be large.
{
grad_xpos[index] = 0.0;
grad_ypos[index] = 0.0001;
}
}
} // namespace
}
at::Tensor shift_cuda_forward(//shift的forward操作,并行调用shift_cuda_forward_kernel核函数实现
at::Tensor input,at::Tensor xpos,at::Tensor ypos,const int stride) {
auto output = at::zeros({input.size(0), input.size(1), input.size(2)/stride, input.size(3)}, input.options());//初始化结果张量
const dim3 blocks((input.size(0)*input.size(1)*input.size(2)*input.size(3)/stride+1024-1)/1024);//计算需要几个块(一维)
const int threads = 1024;//定义一个块有几个线程(一维)
AT_DISPATCH_FLOATING_TYPES(input.type(), "shift_forward_cuda", ([&] {
shift_cuda_forward_kernel<scalar_t><<<blocks, threads>>>(
input.data<scalar_t>(),
output.data<scalar_t>(),
xpos.data<scalar_t>(),
ypos.data<scalar_t>(),
input.size(0),
input.size(1),
input.size(2),
input.size(3),
input.size(2)/stride,
input.size(3),
stride);
}));
//AT_DISPATCH_FLOATING_TYPES是一个封装的接口,可以替换成AT_DISPATCH_ALL_TYPES。
//它有三个参数,第一个是tensor的数据类型,第二个是用于显示错误的信息,第三个是个匿名函数,
//([&]{ })内写cuda的__global__ kernel函数。
//input.data<scalar_t>() 把input的数据转换成scalar_t类型并且返回一个头指针,
//该数据是一个一维的连续存储的地址,访问数据的方式和c语言指针使用方法一样。
return output;
}
std::vector<at::Tensor> shift_cuda_backward(
at::Tensor grad_output,//这是下一层传递过来的梯度值
at::Tensor input,//保存的正向传播的这一层的输入
at::Tensor output,//保存的正向传播的这一层的输出
at::Tensor xpos,//保存的骨架维度的偏移值数组
at::Tensor ypos,//保存的时间维度的偏移值数组
const int stride) {//保存的步长
auto grad_input = at::zeros_like(input);//初始化返回给上一层的梯度值
//shift的backward函数线先调用Shift_Bottom_Backward_Stride1_或Shift_Bottom_Backward_函数,
//计算返回给上一层的梯度值,再调用Shift_Position_Backward_函数计算时间维度以及骨架维度的偏移值的梯度值
//最后调用applyShiftConstraint_函数对偏移值梯度值的大小做约束
const dim3 blocks((input.size(0)*input.size(1)*input.size(2)*input.size(3)+1024-1)/1024);//计算块数(一维)
const int threads = 1024;//计算线程数(一维)
if(stride==1)
{
AT_DISPATCH_FLOATING_TYPES(input.type(), "Shift_Bottom_Backward_Stride1_", ([&] {
Shift_Bottom_Backward_Stride1<scalar_t><<<blocks, threads>>>(
grad_output.data<scalar_t>(),
grad_input.data<scalar_t>(),
xpos.data<scalar_t>(),
ypos.data<scalar_t>(),
input.size(0),
input.size(1),
input.size(2),
input.size(3));
}));
}
else
{
AT_DISPATCH_FLOATING_TYPES(input.type(), "Shift_Bottom_Backward_", ([&] {
Shift_Bottom_Backward<scalar_t><<<blocks, threads>>>(
grad_output.data<scalar_t>(),
grad_input.data<scalar_t>(),
xpos.data<scalar_t>(),
ypos.data<scalar_t>(),
input.size(0),
input.size(1),
input.size(2),
input.size(3));
}));
}
auto grad_xpos_bchw = at::zeros({output.size(0), output.size(1), output.size(2), output.size(3)}, output.options()); // (b,c,h,w),初始化骨架维度的偏移值的梯度
auto grad_ypos_bchw = at::zeros({output.size(0), output.size(1), output.size(2), output.size(3)}, output.options()); // (b,c,h,w),初始化时间维度的偏移值的梯度
const dim3 blocks_output((output.size(0)*output.size(1)*output.size(2)*output.size(3)+1024-1)/1024);
AT_DISPATCH_FLOATING_TYPES(input.type(), "Shift_Position_Backward_", ([&] {
Shift_Position_Backward<scalar_t><<<blocks_output, threads>>>(
input.data<scalar_t>(),
grad_output.data<scalar_t>(),
grad_input.data<scalar_t>(),
xpos.data<scalar_t>(),
ypos.data<scalar_t>(),
grad_xpos_bchw.data<scalar_t>(),
grad_ypos_bchw.data<scalar_t>(),
input.size(0),
input.size(1),
input.size(2),
input.size(3),
stride);
}));
auto grad_xpos_chw = at::mean(grad_xpos_bchw, 0, false);//对批次维度的梯度值求平均
auto grad_xpos_ch = at::sum(grad_xpos_chw, 2, false);//对骨架维度的梯度求和
auto grad_xpos_c = at::sum(grad_xpos_ch, 1, false);//对时间维度的梯度求和
auto grad_xpos = grad_xpos_c;//每个通道都有一个梯度值用于每个通道的骨架的偏移值的更新
auto grad_ypos_chw = at::mean(grad_ypos_bchw, 0, false);//同理
auto grad_ypos_ch = at::sum(grad_ypos_chw, 2, false);
auto grad_ypos_c = at::sum(grad_ypos_ch, 1, false);
auto grad_ypos = grad_ypos_c;//每个通道都有一个梯度用于时间维度的偏移值的更新
const dim3 blocks_norm((output.size(1)+1024-1)/1024);//确定接下来的约束操作需要多少个块
AT_DISPATCH_FLOATING_TYPES(input.type(), "applyShiftConstraint_", ([&] {
applyShiftConstraint<scalar_t><<<blocks_norm, threads>>>(
grad_xpos.data<scalar_t>(),
grad_ypos.data<scalar_t>(),
output.size(1));
}));
return {grad_input,grad_xpos,grad_ypos};//返回,给上一层的梯度值以及骨架维度、时间维度的偏移值的梯度值
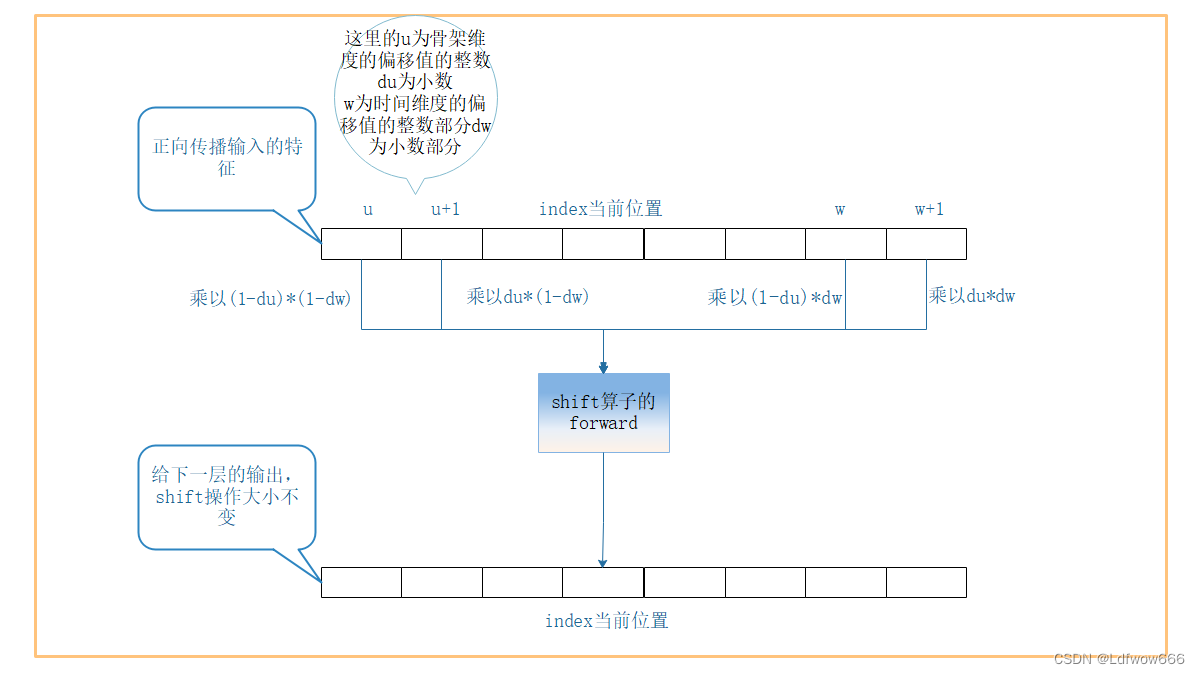
}shift算子的foward的示意图,注意同一通道的偏移值是相同的:
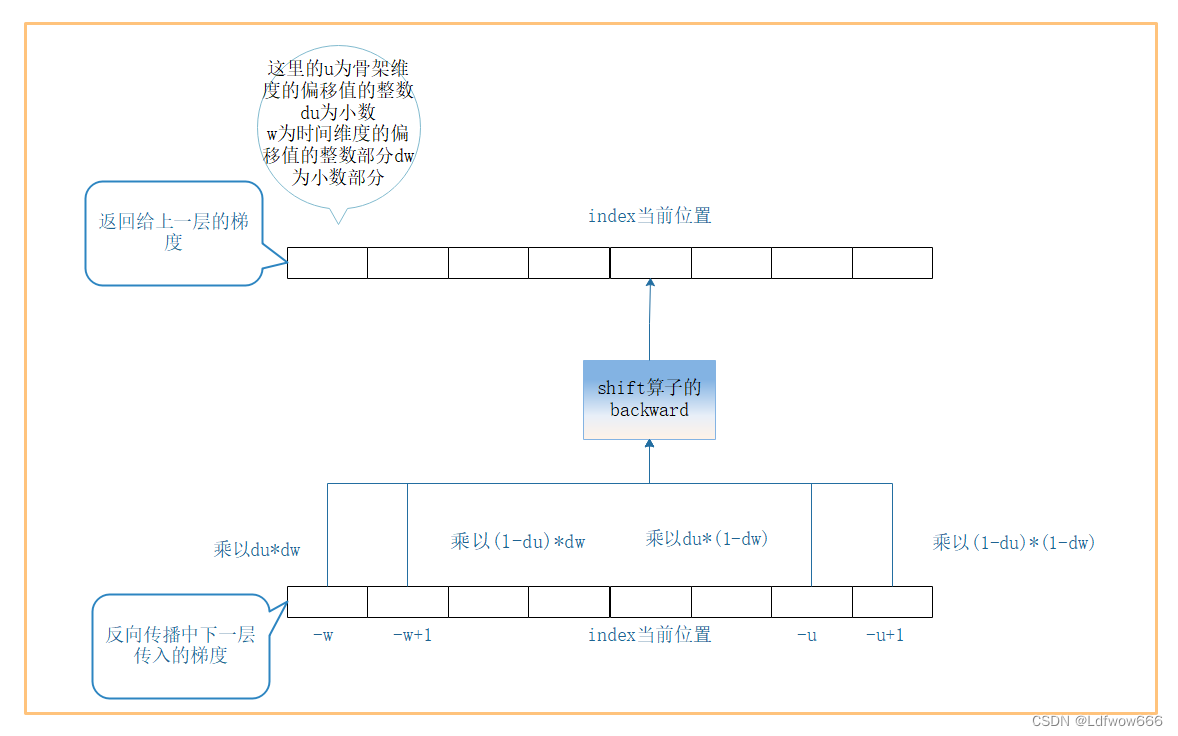
shift算子反向传播的示意图,注意同一通道的偏移值是相同的:
两个偏移值计算式子的求导过程:

shift_cuda.cpp
shift_cuda.cpp编写包装函数并调用PYBIND11_MODULE对算子进行封装。
#include <torch/torch.h>
#include <vector>
at::Tensor shift_cuda_forward(
at::Tensor input,at::Tensor xpos,at::Tensor ypos,const int stride);
//声明cuda编程中写的shift算子的forward函数
std::vector<at::Tensor> shift_cuda_backward(
at::Tensor grad_output,
at::Tensor input,
at::Tensor output,
at::Tensor xpos,
at::Tensor ypos,
const int stride);
//声明cuda编程中写的shift算子的backward函数
#define CHECK_CUDA(x) AT_ASSERTM(x.type().is_cuda(), #x " must be a CUDA tensor")
#define CHECK_CONTIGUOUS(x) AT_ASSERTM(x.is_contiguous(), #x " must be contiguous")
#define CHECK_INPUT(x) CHECK_CUDA(x); CHECK_CONTIGUOUS(x)
//CHECK_INPUT(x) 的含义是:检查张量 x 是否为 CUDA 张量且是否为连续存储的,如果不是,则抛出异常并打印错误消息。
at::Tensor shift_forward(//检查输入的值并封装cuda编程中的shift_cuda_forward
at::Tensor input,at::Tensor xpos,at::Tensor ypos,const int stride) {
CHECK_INPUT(input);
return shift_cuda_forward(input,xpos,ypos,stride);
}
std::vector<at::Tensor> shift_backward(//检查输入以及下一层传进来的梯度值并封装cuda编程中的shift_backward
at::Tensor grad_output,
at::Tensor input,
at::Tensor output,
at::Tensor xpos,
at::Tensor ypos,
const int stride)
{
CHECK_INPUT(grad_output);
CHECK_INPUT(output);
return shift_cuda_backward(
grad_output,
input,
output,
xpos,
ypos,
stride);
}
PYBIND11_MODULE(TORCH_EXTENSION_NAME, m) {
//PYBIND11_MODULE 是 Pybind11 提供的宏,用于定义 Python 扩展模块。
//TORCH_EXTENSION_NAME 是扩展模块的名称,这通常在其他地方定义。
m.def("forward", &shift_forward, "shift forward (CUDA)");
//m.def 用于在 Python 模块中定义一个函数。
//"forward" 是 Python 中调用该函数的名称。
//&shift_forward 是要绑定到 Python 函数的 C++ 函数的地址。
//在这里,它绑定到名为 shift_forward 的函数。
//"shift forward (CUDA)" 是函数的文档字符串,用于描述该函数的作用和用法。
m.def("backward", &shift_backward, "shift backward (CUDA)");//同理
}
//这段代码使用 Pybind11 来定义一个名为 TORCH_EXTENSION_NAME 的 PyTorch 扩展模块,并注册两个函数 forward 和 backward。setup.py
新建setup.py文件配置编译信息,利用setuptools对算子打包。
from setuptools import setup
from torch.utils.cpp_extension import BuildExtension, CUDAExtension, CppExtension
setup(
name='shift_cuda_linear_cpp',//包名
ext_modules=[#注意这里的shift_cuda才是在python文件中导入的模块名不是上面的报名
CUDAExtension('shift_cuda', [
'shift_cuda.cpp',
'shift_cuda_kernel.cu',
]),#其中第一个参数为对应模块的名字,第二个参数为包含所有文件路径的列表。
],
cmdclass={
'build_ext': BuildExtension
})直接在终端运行python setup.py install就可以编译安装shift_cuda_kernel.cu、shift_cuda.cpp两个文件。
注意先切好需要的虚拟环境喔。
shift.py
为了让自定义算子能够正常正向传播、反向传播,我们需要继承torch.autograd.Function进行算子包装。
自定义的torch.autograd.Function类型要实现forward、backward函数,并声明为静态成员函数。
如果算子不需要考虑反向传播,可以用ctx.mark_non_differentiable(ans) 将函数的输出标记不需要微分。
注意:backward的输入对应forward的输出,输出对应forward的输入
如ShiftFunction所示
最后使用ShiftFunction.apply()获取最终的函数形式
然后使用继承了Module的shift将其ShiftFunction封装起来
from torch.nn import Module, Parameter
from torch.autograd import Function
import torch
import shift_cuda
import numpy as np
class ShiftFunction(Function):
@staticmethod
def forward(ctx, input,xpos,ypos,stride=1):
if stride==1:
xpos = xpos
ypos = ypos
else:
ypos = ypos + 0.5
# ypos = ypos + 0.5
output = shift_cuda.forward(input,xpos,ypos,stride)
ctx.save_for_backward(input, output, xpos, ypos)
ctx.stride = stride
return output
@staticmethod
def backward(ctx, grad_output):
grad_output = grad_output.contiguous()
input, output, xpos, ypos = ctx.saved_variables
grad_input,grad_xpos,grad_ypos = shift_cuda.backward(grad_output, input, output, xpos, ypos, ctx.stride)
return grad_input, grad_xpos, grad_ypos, None
class Shift(Module):
def __init__(self, channel, stride, init_scale=3):
super(Shift, self).__init__()
self.stride = stride
self.xpos = Parameter(torch.zeros(channel,requires_grad=True,device='cuda')*1.5)
self.ypos = Parameter(torch.zeros(channel,requires_grad=True,device='cuda')*1.5)
self.xpos.data.uniform_(-1e-8,1e-8)
self.ypos.data.uniform_(-init_scale,init_scale)
def forward(self, input):
return ShiftFunction.apply(input,self.xpos,self.ypos,self.stride)














 585
585











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









