






参考资料:(都写的很好!!!推!!!)
深度解析深度学习中的长短期记忆网络(LSTM)(含代码实现)_lstm 代码实现-CSDN博客
https://zhuanlan.zhihu.com/p/36101196
https://www.zhihu.com/question/34878706
RNN存在的问题:
当两个相关的词的间隔不断增大时,RNN 会丧失学习到连接如此远的信息的能力。在理论上,RNN 绝对可以处理这样的 长期依赖 问题,但在实践中,RNN 肯定不能够成功学习到这些知识。除此之外,当RNN也存在梯度消失和爆炸的问题。
LSTM网络:
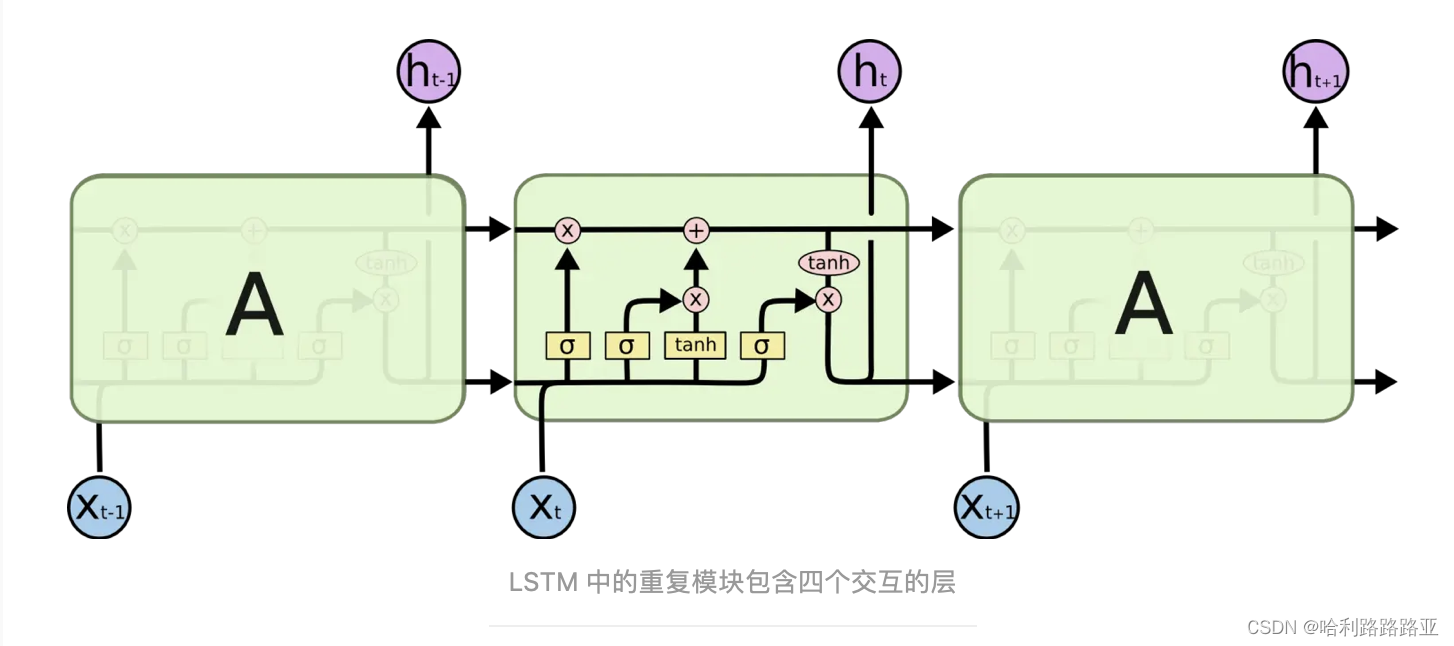
LSTM 的关键就是细胞状态,它直接在整个链上运行,只有一些少量的线性交互。信息在上面流传保持不变会很容易。

所以可以看见C状态改变的慢一点,Ct是在Ct-1的基础上加了些什么。
从这里可以来说一下梯度消失的问题,LSTM是RNN的改进版,它改进了共享的神经网络模块,引入了cell模块,同时把RNN里面的连乘符合改成了连加操作。所以这里的梯度流是最稳定,但是在其它路径里,梯度消失和爆炸依然是存在的。
总的远距离梯度 = 各条路径的远距离梯度之和,即便其他远距离路径梯度消失了,只要保证有一条远距离路径(就是上面说的那条高速公路)梯度不消失,总的远距离梯度就不会消失(正常梯度 + 消失梯度= 正常梯度)。因此 LSTM 通过改善一条路径上的梯度问题拯救了总体的远距离梯度消失。但同样的,对于梯度爆炸:总的远距离梯度 = 正常梯度 + 爆炸梯度 = 爆炸梯度,因此 LSTM 仍然有可能发生梯度爆炸。不过,由于 LSTM 的其他路径非常崎岖,和普通 RNN 相比多经过了很多激活函数(导数都小于 1),因此 LSTM 发生梯度爆炸的频率要低得多。实践中梯度爆炸一般通过梯度裁剪来解决。
LSTM的三个门:
遗忘门:决定丢弃什么信息。
LSTM 中的第一步是决定我们会从细胞状态中丢弃什么信息。遗忘门读取ht-1和xt,输出一个在0到1之间的数值给每个在细胞状态Ct-1中的数字,1表示完全保留,0表示完全舍弃。

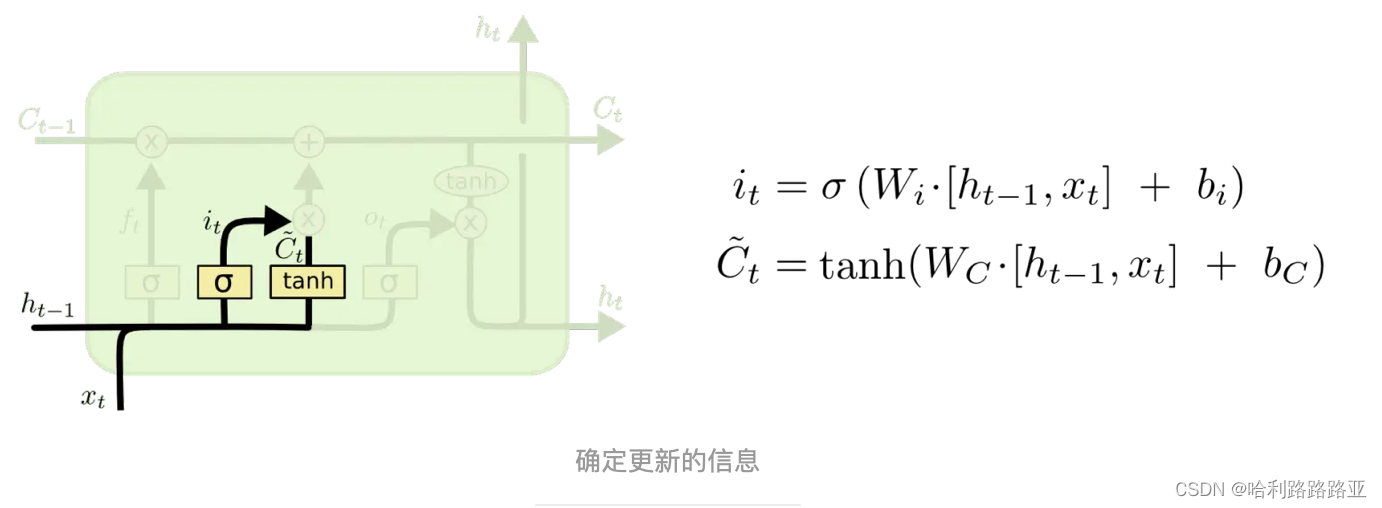
输入门:确定更新的信息
这里有两个部分,sigmoid层称 “输入门层” 决定什么值我们将要更新。然后,一个 tanh 层创建一个新的候选值向量,然后C~t会被加入到状态中。
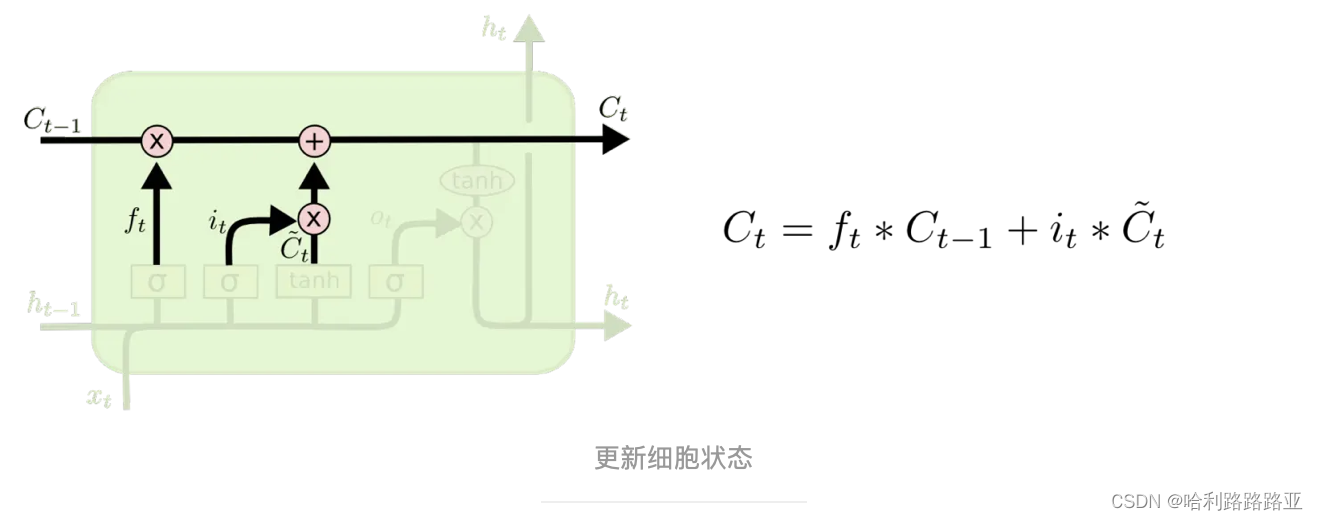
然后把旧状态与 ft 相乘,丢弃掉我们确定需要丢弃的信息。接着加上 it*c~t ,所以有了新的传递值。
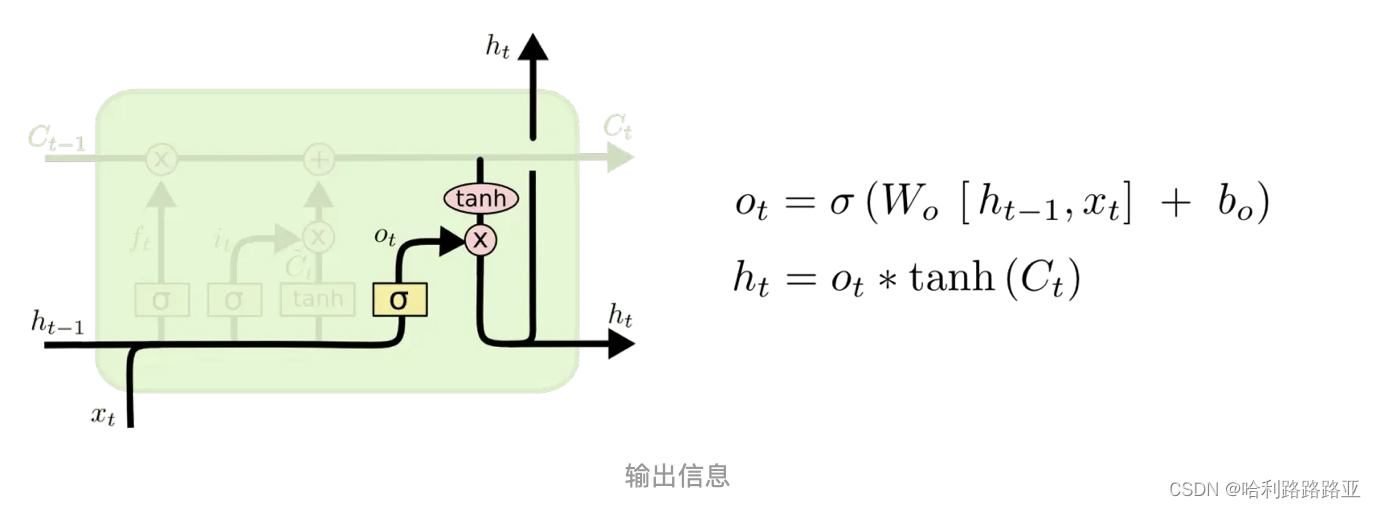
输出门:确定输出什么值
输出将会基于我们的细胞状态,但是也是一个过滤后的版本。首先,我们运行一个 sigmoid 层来确定细胞状态的哪个部分将输出出去。接着,我们把细胞状态通过 tanh 进行处理(得到一个在-1到1之间的值)并将它和 sigmoid 门的输出相乘,最终我们仅仅会输出我们确定输出的那部分。
激活函数:
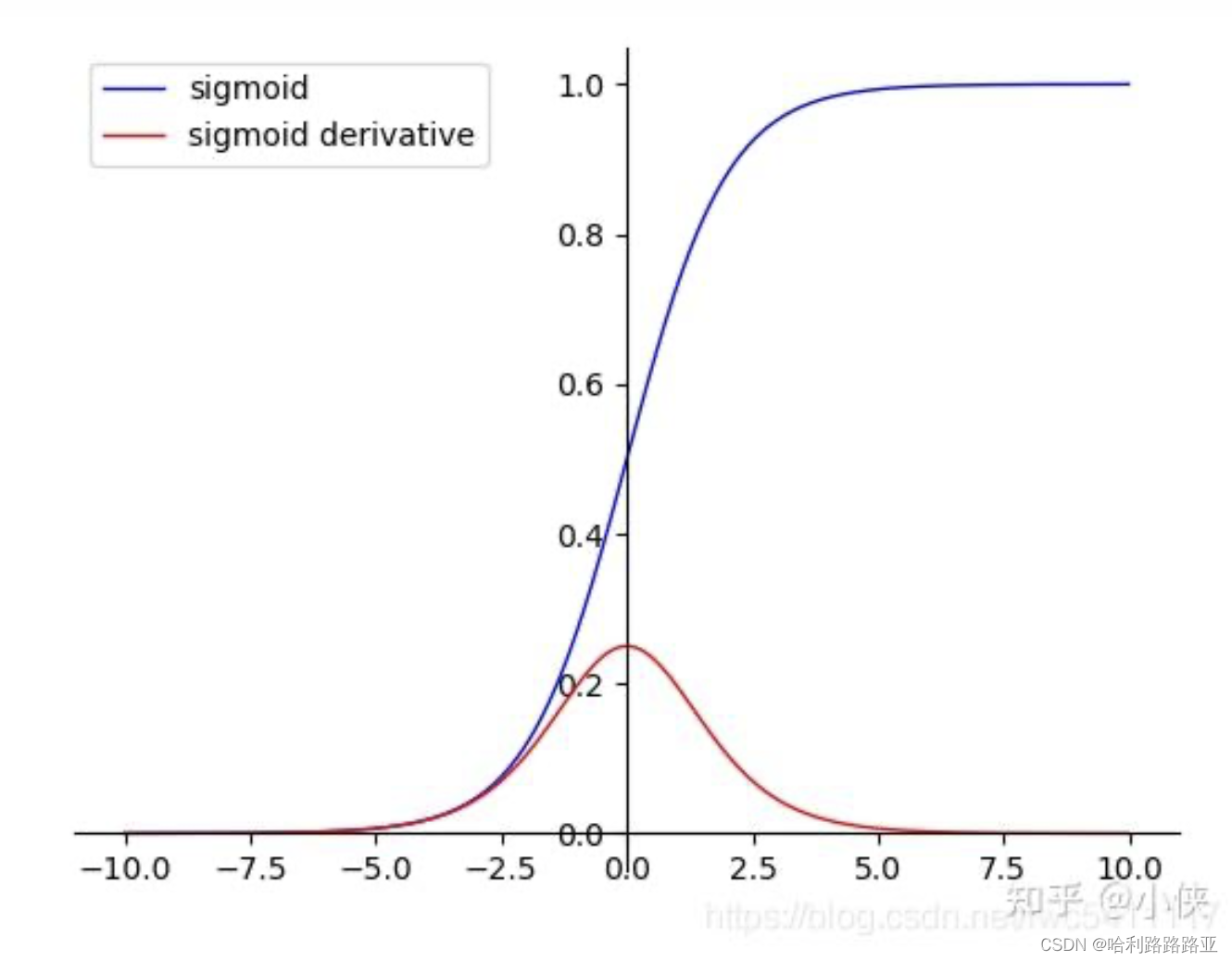
sigmoid函数:
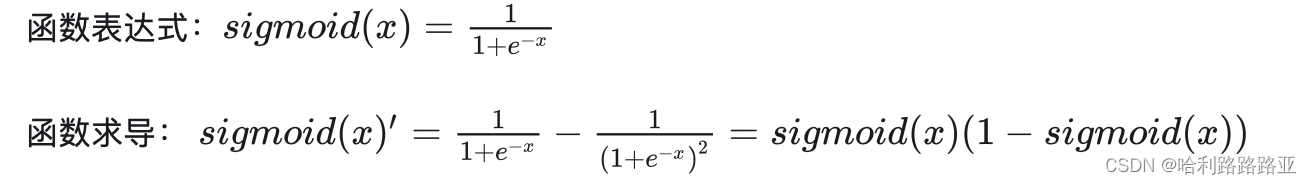
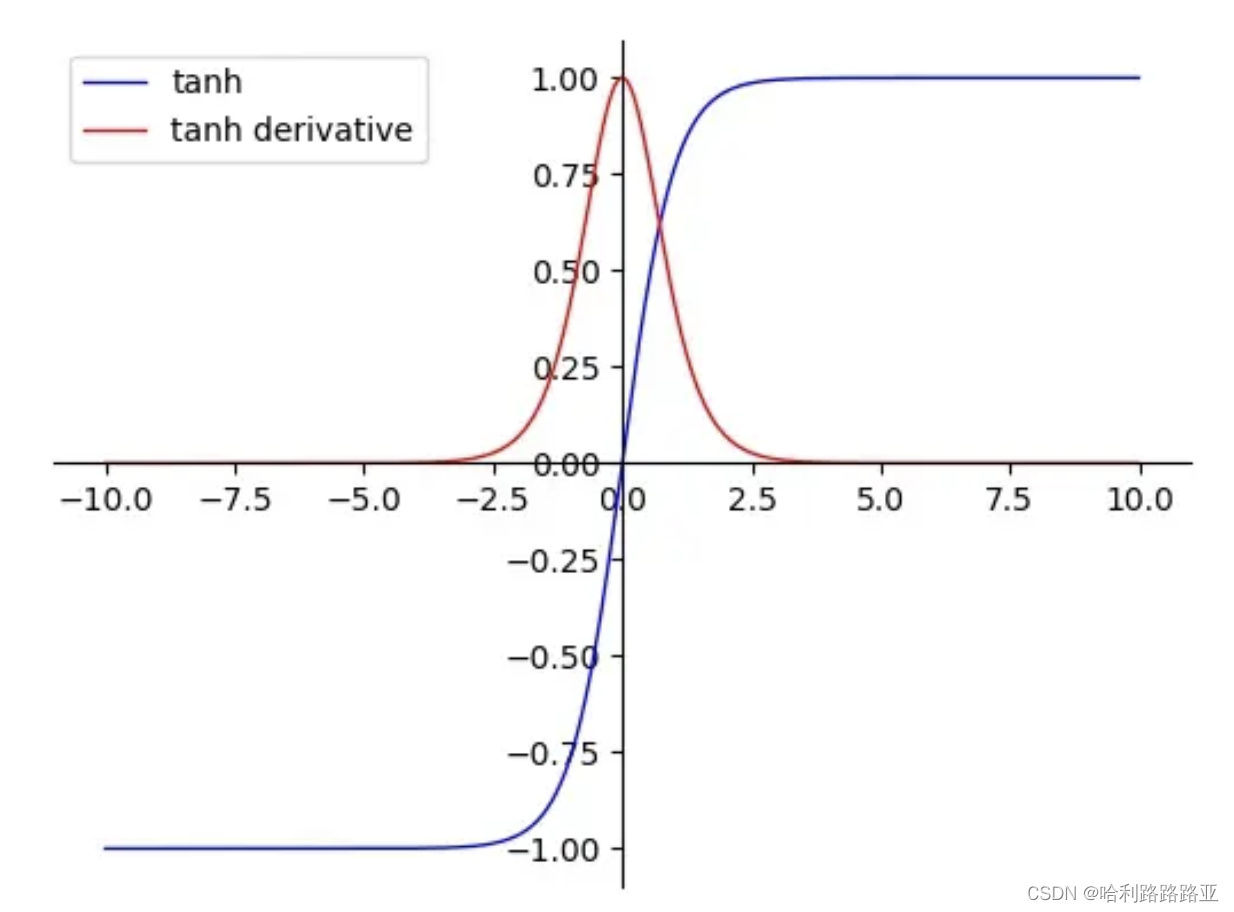
tanh激活函数:
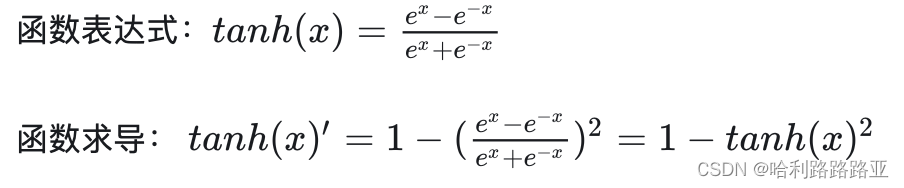
它和sigmoid相比:
- 在靠近0处的导数值较sigmoid更大,即神经网络的收敛速度相对于sigmoid更快;在一般的分类问题中,可将tanh用于隐藏层,sigmoid 函数用于输出层。
- tanh导数范围在(0, 1)之间,相比sigmoid导数的范围(0, 0.25),梯度消失问题会得到缓解,但仍然存在。
使用pytorch实现一个简单的LSTM模型:
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
class LSTMModel(nn.Module):
def __init__(self,input_size,hidden_size,num_layers,output_size):
super(LSTMModel,self).__init__()
self.hidden_size = hidden_size
self.num_layers = num_layers
self.lstm = nn.LSTM(input_size,hidden_size,num_layers,batch_first = True)#batch_first也就是指在input的维度顺序是(batch_size,seq_len,input_size)
self.fc = nn.Linear(hidden_size,output_size)
def forward(self,x):
h0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)#(层数,batch,隐藏层大小)
print(h0.size())
c0 = torch.zeros(self.num_layers, x.size(0), self.hidden_size)
out,(_,_) = self.lstm(x,(h0,c0))
out = self.fc(out[:,-1, :])
return out
inputs = new_inputs = torch.randn(3,5,1,dtype=torch.float) #(batch_size,seq_len,input_size)
labels = torch.tensor([0,1,1])
input_size = 1 #表示一个单词只用一个向量表示
hidden_size = 64
num_layers = 1
output_size = 2
model = LSTMModel(input_size,hidden_size,num_layers,output_size)
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
num_epochs = 5
for epoch in range(num_epochs):
outputs = model(inputs)
loss = criterion(outputs,labels)
#模型参数更新
optimizer.zero_grad()
loss.backward()
optimizer.step()
只迭代了5次的结果:
outputs = model(new_inputs)
print(outputs)
predicted = torch.argmax(outputs,dim = 1)#这个dim = 1 指的是按行来找最大值,dim = 0 是按列来找
print(predicted)
#输出
tensor([[-0.1003, 0.0417],
[-0.1050, 0.0573],
[-0.1077, 0.0854]], grad_fn=<AddmmBackward0>)
tensor([1, 1, 1])














 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









