






先看大模型的训练流程图:
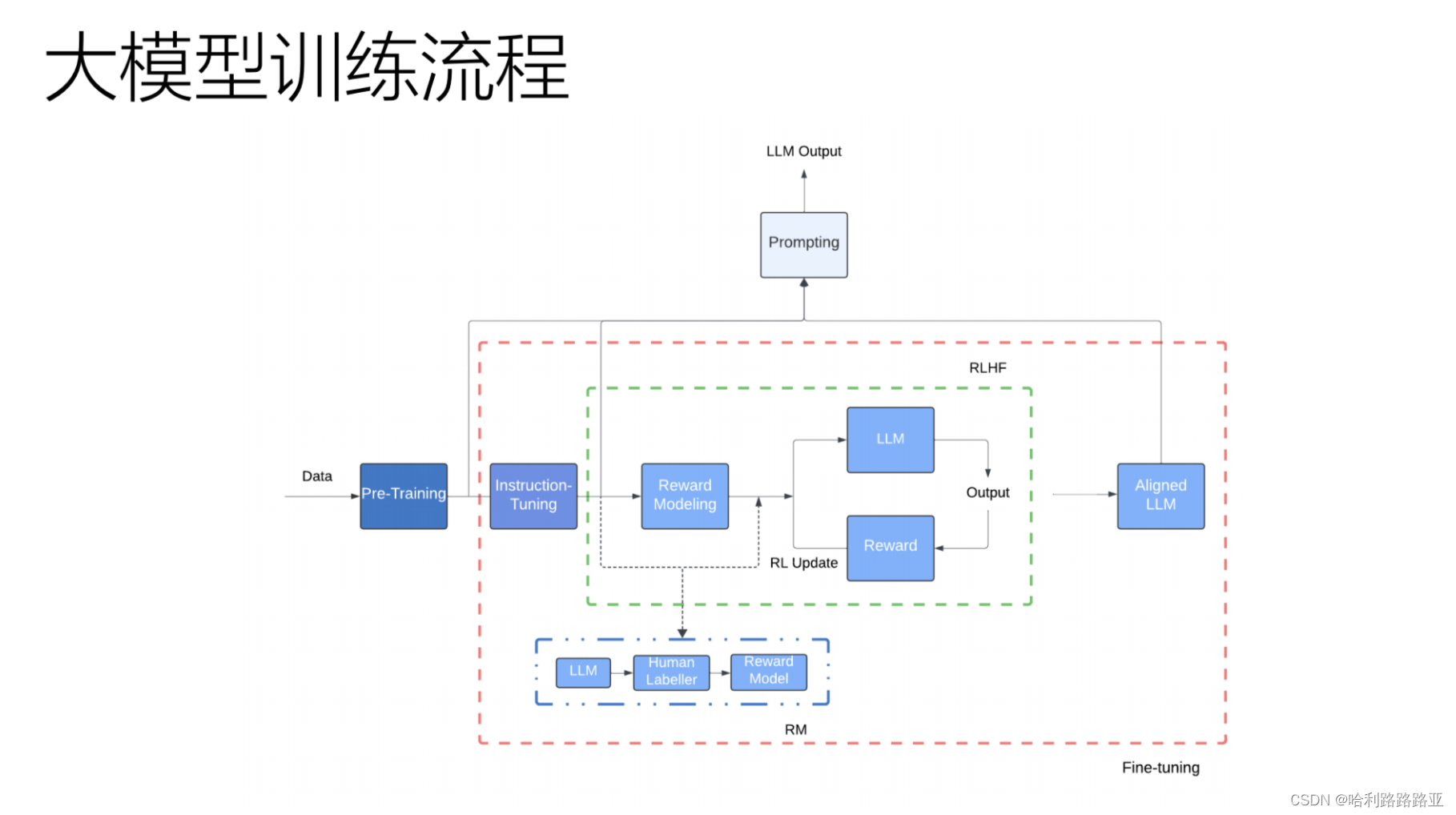
接下来,一步一步的来看:
Pre-Taining(预训练
预训练得到的是base模型,它只是预测下一个词的模型。(是不是和迁移学习类似?
Instruction-Tuning(指令微调
对齐
没有对齐的话,模型的回复可能和我们的问题没有关系。对齐的目的是让模型理解我们的问题,并且根据我们的问题来回答我们的问题。那么如何对齐呢?
强化学习RLHF
让模型输出2句话,人类选择哪一种更好。
Supervised Fine- Tuning(SFT监督微调
概念:
这个有点像迁移学习,要求目标函数和源数据集类似,然后只需要修改源模型的输出层。
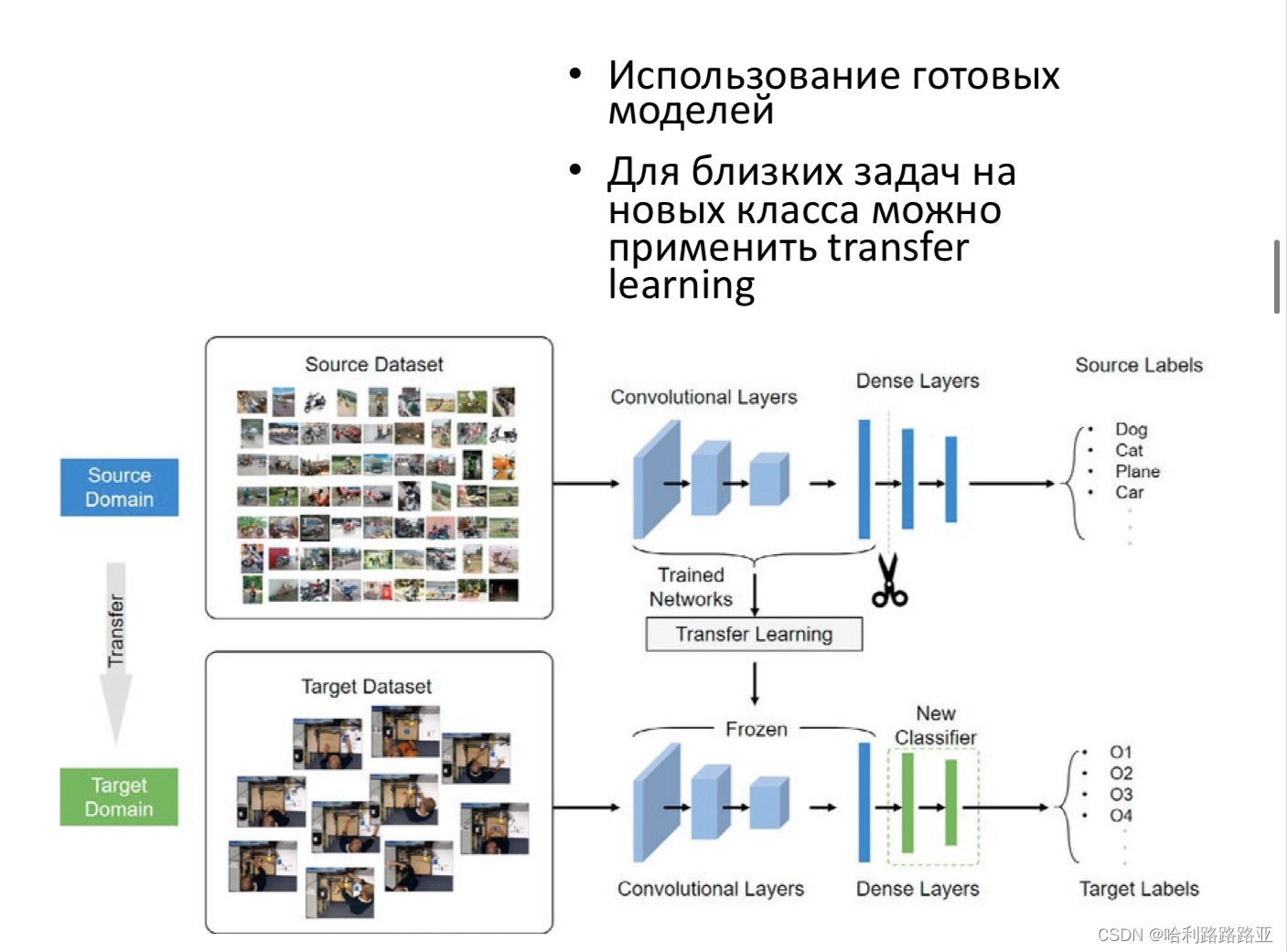
步骤:
预训练:在一个大规模的数据集上训练一个深度学习模型。
微调:使用目标任务的训练集对预训练模型进行微调。
评估:使用目标任务的测试集对微调后的模型进行评估。
特点:
监督微调能够利用预训练模型的参数和结构,避免从头开始训练模型。从而加速模型的训练过程,并且能够提高模型在目标任务上的表现。缺点:需要大量的标注数据用于目标任务的微调,如果标注数据不足,可能导致微调后的模型表现不佳,(那么这个数据量大概是多少呢?)其次,由于预训练模型的参数对微调后的模型性能影响很大,所以选择合适的预训练模型很重要。
RLHF(基于人类反馈的强化学习
RLHF是强化学习的微调,比如ChatGPT3.5是在GPT3.5的预训练模型上引入“人工标注数据+强化学习”来不断Fine-tune预训练语言模型,主要目的是让LLM模型学会理解人类的命令指令的含义。
这里,我们会需要来讲一为什么需要微调。
预训练模型够输出下一个词是什么,那么微调的好处:
能够得到更一致的输出。
减少幻觉。防止模型胡编乱造。















 1850
1850

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









