









一、基于Alex Net的花卉分类
1.1、项目背景
在当今快速发展的科技领域,计算机视觉已成为一个备受关注的研究方向。随着深度学习技术的不断进步,图像识别技术得到了显著提升,广泛应用于医疗、安防、自动驾驶等多个领域。其中,花卉分类作为计算机视觉中的一个重要应用,不仅能帮助园艺师和农业生产者优化作物管理,还能在生态研究、植物保护等方面发挥重要作用。
传统的花卉分类方法依赖于人工特征提取和机器学习算法,虽然在特定条件下能够取得较好效果,但在面对复杂的自然环境和大量不同花卉品种时,仍显得力不从心。而深度学习,尤其是卷积神经网络(CNN),凭借其强大的特征学习能力和卓越的表现,逐渐取代了传统方法。其中,AlexNet作为第一款在大规模图像分类竞赛中获得突破性成果的深度学习模型,广泛应用于各类图像识别任务,受到高度重视。
1.2、项目目的
在本项目中,我们的目标是构建一个深度学习模型,能够有效地识别和分类花卉的图像。通过使用卷积神经网络(CNN),尤其是著名的AlexNet架构,我们希望实现高精度的图像分类。完成该项目后,用户能够方便地将图像上传至应用程序,并获得该图像是何种花卉的预测结果。
1.3、网络描述
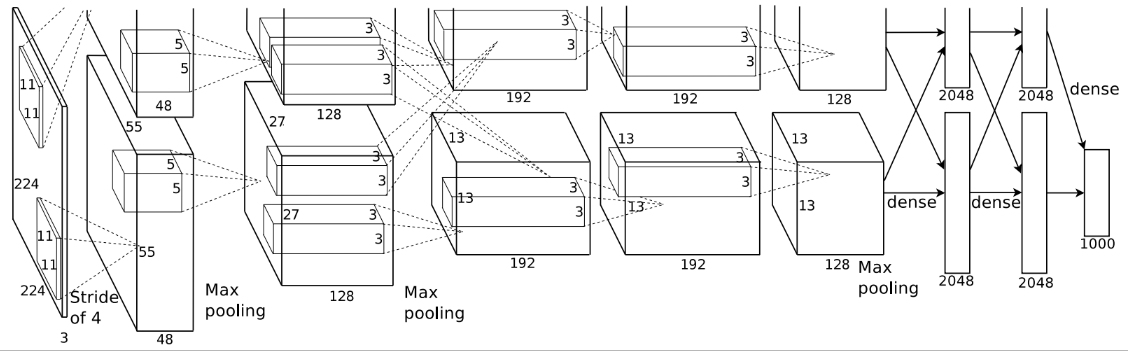
AlexNet 是由Alex Krizhevsky、Ilya Sutskever 和 Geoffrey Hinton 在2012年提出的深度学习模型。它在ImageNet大规模视觉识别挑战赛中取得了显著的成功,显著提高了图像分类的准确率。该模型采用了多个卷积层、ReLU激活函数、全连接层和Dropout正则化方法,以有效防止过拟合。AlexNet的成功不仅证明了深度学习在计算机视觉领域的潜力,还推动了后续更多深度学习模型的研究和应用。
1.4、数据集
examples = enumerate(val_loader)
batch_idx, (imgs, labels) = next(examples)
for i in range(4):
mean = np.array([0.5, 0.5, 0.5])
std = np.array([0.5, 0.5, 0.5])
image = imgs[i].numpy() * std[:, None, None] + mean[:, None, None]
# 将图片转成numpy数组,主要是转换通道和宽高位置
image = np.transpose(image, (1, 2, 0))
plt.subplot(2, 2, i+1)
plt.imshow(image)
plt.title(f"Truth: {labels[i]}")
plt.show()
二、设计思路
import os
import random
import numpy as np
import torch
from torch import nn
from torchvision import datasets,transforms
from torch.utils.data import DataLoader2.1、构建随机种子
# 设置随机种子以保证结果的可重复性
def setup_seed(seed):
np.random.seed(seed) # 设置 Numpy 随机种子
random.seed(seed) # 设置 Python 内置随机种子
os.environ['PYTHONHASHSEED'] = str(seed) # 设置 Python 哈希种子
torch.manual_seed(seed) # 设置 PyTorch 随机种子
if torch.cuda.is_available():
torch.cuda.manual_seed(seed) # 设置 CUDA 随机种子
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark = False # 关闭 cudnn 加速
torch.backends.cudnn.deterministic = True # 设置 cudnn 为确定性算法
# 设置随机种子
setup_seed(0)2.2、检测显卡还是cpu
# 检查是否有可用的 GPU,如果有则使用 GPU,否则使用 CPU
if torch.cuda.is_available():
device = torch.device("cuda") # 使用 GPU
print("CUDA is available. Using GPU.")
else:
device = torch.device("cpu") # 使用 CPU
print("CUDA is not available. Using CPU.")2.3、数据预处理和加载数据集
transform={
'train':transforms.Compose([
transforms.RandomResizedCrop(244),
transforms.RandomVerticalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
]),
'val':transforms.Compose([
transforms.Resize((224,224)),
transforms.RandomVerticalFlip(p=0.5),
transforms.ToTensor(),
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5))
])
}train_loader=DataLoader(train_dataset,batch_size=32,shuffle=True)
val_loader=DataLoader(val_dataset,batch_size=32,shuffle=False)2.4、构建Alex Net网络
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 96, 11, 4, 2),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2),
nn.Conv2d(96, 256, 5, 1, 2),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2),
nn.Conv2d(256, 384, 3, 1, 1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 384, 3, 1, 1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, 3, 1, 1),
nn.ReLU(inplace=True),
nn.MaxPool2d(3, 2),
)
self.classifier = nn.Sequential(
nn.Dropout(p=0.5),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(p=0.5),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
model=AlexNet().to(device)2.5、损失函数优化器
cri=torch.nn.CrossEntropyLoss()
optim=torch.optim.Adam(model.parameters(),lr=0.001)2.6、训练模型
epoches = 100
for epoch in range(epoches):
model.train()
total_loss = 0
for i, (images, labels) in enumerate(train_loader):
# 数据放在设备上
images = images.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(images)
loss = cri(outputs, labels)
# 反向传播
optim.zero_grad()
loss.backward()
optim.step()
total_loss += loss
print(f"Epoch [{epoch + 1}/{epoches}], Iter [{i}/{len(train_loader)}], Loss {loss:.4f}")
avg_loss = total_loss / len(train_loader)
print(f"Epoch [{epoch + 1}/{epoches}], Loss {avg_loss:.4f}")
if (epoch+1) % 10 == 0:
torch.save(model.state_dict(), f"./model/model_{epoch}.pth")2.7、验证模型
model.load_state_dict(torch.load("model_best.pth"))
model.eval()
total = 0
correct = 0
predicted_labels = []
true_labels = []
with torch.no_grad():
for images, labels in val_loader:
images = images.to(device)
labels = labels.to(device)
outputs = model(images)
_, predicted = torch.max(outputs.data, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
predicted_labels.extend(predicted.cpu().numpy())
true_labels.extend(labels.cpu().numpy())
print(f"ACC {correct / total * 100}%")
# 生成混淆矩阵
conf = confusion_matrix(true_labels, predicted_labels)
# 可视化
sns.heatmap(conf, annot=True, fmt="d", cmap="Blues")
plt.xlabel("predict")
plt.ylabel("true")
plt.show()2.8、完整代码
import os
import random
import numpy as np
import torch
from torch import nn
from torchvision import datasets,transforms
from torch.utils.data import DataLoader
# 设置随机种子,保证实验的可重复性
def setup_seed(seed):
np.random.seed(seed)
random.seed(seed)
os.environ['PYTHONHASHSEED']=str(seed)
torch.manual_seed(seed)
if torch.cuda.is_available():
torch.cuda.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
torch.backends.cudnn.benchmark=False # 关闭cudnn的benchmark模式,保证每次运行结果一致
torch.backends.cudnn.deterministic=True # 使cudnn的卷积计算具有确定性
setup_seed(42) # 设置随机种子为42
# 判断是否有CUDA可用,并设置设备
if torch.cuda.is_available():
device=torch.device('cuda')
print('cuda is available')
else:
device=torch.device('cpu')
print('cuda is not available')
# 定义数据预处理的转换
transform={
'train':transforms.Compose([
transforms.RandomResizedCrop(224), # 随机裁剪到224x224
transforms.RandomHorizontalFlip(p=0.5), # 以0.5的概率进行水平翻转
transforms.ToTensor(), # 将PIL图像或NumPy数组转换为Tensor
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)) # 对图像进行标准化,均值为0.5,标准差为0.5
]),
'val':transforms.Compose([
transforms.Resize((224,224)), # 调整图像大小到224x224
transforms.RandomHorizontalFlip(p=0.5), # 以0.5的概率进行水平翻转
transforms.ToTensor(), # 将PIL图像或NumPy数组转换为Tensor
transforms.Normalize((0.5,0.5,0.5),(0.5,0.5,0.5)) # 对图像进行标准化,均值为0.5,标准差为0.5
])
}
# 加载训练数据集
train_dataset=datasets.ImageFolder(
'./flower_data/train', # 训练数据文件夹路径
transform=transform['train'] # 应用训练集的数据预处理
)
# 加载验证数据集
val_dataset=datasets.ImageFolder(
'./flower_data/val', # 验证数据文件夹路径
transform=transform['val'] # 应用验证集的数据预处理
)
# 创建训练数据加载器
train_loader=DataLoader(train_dataset,batch_size=32,shuffle=True) # 批量大小为32,打乱数据
# 创建验证数据加载器
val_loader=DataLoader(val_dataset,batch_size=32,shuffle=False) # 批量大小为32,不打乱数据
# 定义AlexNet模型
class AlexNet(nn.Module):
def __init__(self,num_classes=1000): # num_classes为分类的类别数,默认为1000
super().__init__()
self.features=nn.Sequential(
nn.Conv2d(3,48*2,kernel_size=11,stride=4,padding=2), # 卷积层1:输入通道3,输出通道96,卷积核11x11,步长4,填充2
nn.ReLU(inplace=True), # ReLU激活函数,inplace=True表示直接修改输入
nn.MaxPool2d(kernel_size=3,stride=2), # 最大池化层1:池化窗口3x3,步长2
nn.Conv2d(48*2,128*2,kernel_size=5,padding=2), # 卷积层2:输入通道96,输出通道256,卷积核5x5,填充2
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2), # 最大池化层2:池化窗口3x3,步长2
nn.Conv2d(128*2,192*2,kernel_size=3,padding=1), # 卷积层3:输入通道256,输出通道384,卷积核3x3,填充1
nn.ReLU(inplace=True),
nn.Conv2d(192*2,192*2,kernel_size=3,padding=1), # 卷积层4:输入通道384,输出通道384,卷积核3x3,填充1
nn.ReLU(inplace=True),
nn.Conv2d(192*2,128*2,kernel_size=3,padding=1), # 卷积层5:输入通道384,输出通道256,卷积核3x3,填充1
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3,stride=2) # 最大池化层3:池化窗口3x3,步长2
)
self.classifier=nn.Sequential(
nn.Dropout(p=0.5), # Dropout层1:丢弃概率为0.5
nn.Linear(128*2*6*6,2048*2), # 全连接层1:输入特征数量为最后一个卷积层的输出大小,输出特征数量为4096
nn.ReLU(inplace=True),
nn.Dropout(p=0.5), # Dropout层2:丢弃概率为0.5
nn.Linear(4096,4096), # 全连接层2:输入特征数量为4096,输出特征数量为4096
nn.ReLU(inplace=True),
nn.Linear(4096,num_classes) # 全连接层3:输出层,输出特征数量为类别数
)
def forward(self,x):
x=self.features(x) # 通过特征提取层
x=torch.flatten(x,1) # 将多维特征展平成一维
x=self.classifier(x) # 通过分类器层
return x
# 实例化AlexNet模型并将其移动到指定的设备上
model=AlexNet(num_classes=len(train_dataset.classes)).to(device) # 根据训练集类别数设置输出类别数
# 定义损失函数为交叉熵损失
cri=torch.nn.CrossEntropyLoss()
# 定义优化器为Adam优化器,学习率为0.001
optim=torch.optim.Adam(model.parameters(),lr=0.001)
# 设置训练的轮数
epoches=200
# 开始训练循环
for epoch in range(epoches):
most_acc = 0 # 初始化最佳验证集准确率
model.train() # 设置模型为训练模式
total_loss = 0 # 初始化训练总损失
# 遍历训练数据加载器
for i, (images, labels) in enumerate(train_loader):
# 将数据移动到指定的设备上
images = images.to(device)
labels = labels.to(device)
# 前向传播,计算模型输出
outputs = model(images)
# 计算损失
loss = cri(outputs, labels)
# 反向传播前清空梯度
optim.zero_grad()
# 反向传播,计算梯度
loss.backward()
# 更新模型参数
optim.step()
# 累加每个批次的损失
total_loss += loss
# 打印训练信息
print(f"Epoch [{epoch + 1}/{epoches}], Iter [{i}/{len(train_loader)}], Loss {loss:.4f}")
# 计算平均训练损失
avg_loss = total_loss / len(train_loader)
print(f"Train Data: Epoch [{epoch + 1}/{epoches}], Loss {avg_loss:.4f}")
# 进入评估模式
model.eval()
total, correct, test_loss, total_loss= 0, 0, 0, 0
# 在验证集上进行评估,禁用梯度计算
with torch.no_grad():
# 遍历验证数据加载器
for images, labels in val_loader:
# 将数据移动到指定的设备上
images = images.to(device)
labels = labels.to(device)
# 前向传播,计算模型输出
outputs = model(images)
# 计算验证损失
test_loss = cri(outputs, labels)
# 累加每个批次的验证损失
total_loss += test_loss
# 获取预测结果
_, predicted = torch.max(outputs.data, 1)
# 统计总样本数
total += labels.size(0)
# 统计预测正确的样本数
correct += (predicted == labels).sum().item()
# 计算平均验证损失
avg_test_loss = total_loss / len(val_loader)
# 计算验证准确率
acc = correct / total
print(f"Test Data: Epoch [{epoch+1}/{epoches}], Loss {avg_test_loss:.4f}, Accuracy {acc * 100}%")
# 如果当前验证准确率是最高的,则保存模型
if acc > most_acc:
torch.save(model.state_dict(), f"model_best.pth")
most_acc = acc
# 每隔10个epoch保存一次模型
if (epoch+1) % 10 == 0:
torch.save(model.state_dict(), f"model_{epoch+1}.pth")

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









