









一、论文

1.1、论文基本信息
-
标题:MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
-
作者:Andrew G. Howard, Menglong Zhu, Bo Chen, Weijun Wang, Tobias Weyand, Marco Andreetto, Dmitry Kalenichenko, Hartwig Adam
-
单位:Google Inc.
-
主要贡献:提出了一类称为MobileNets的高效模型,用于移动和嵌入式视觉应用。
1.2、主要内容
1.2.1、Depthwise Separable Convolution(深度可分离卷积)
MobileNets模型基于深度可分离卷积构建,这是一种将标准卷积分解为深度卷积和1x1卷积(称为逐点卷积)的卷积分解形式。 深度卷积将单个滤波器应用于每个输入通道,而逐点卷积则用于组合深度卷积的输出。 这种分解大大减少了计算量和模型大小。
1.2.2、MobileNet 网络结构
MobileNet 结构基于深度可分离卷积构建,除了第一层是完整卷积外。 所有层都后接 batchnorm 和 ReLU 非线性激活,除了最终的完全连接层。 下采样通过深度卷积和第一层中的跨步卷积实现。 最终的平均池化层在完全连接层之前将空间分辨率降低到 1。
1.2.3、Width Multiplier(宽度乘数)
引入了一个称为宽度乘数 α 的参数,以构建更小、计算量更少的模型。 宽度乘数 α 的作用是在每一层均匀地减少网络。 宽度乘数 α 可以应用于任何模型结构,以定义具有合理精度、延迟和大小权衡的新型更小模型。
1.2.4、Resolution Multiplier(分辨率乘数)
第二个减少神经网络计算成本的超参数是分辨率乘数 ρ。 分辨率乘数 ρ 应用于输入图像,并且每一层的内部表示也按相同的乘数减少。 分辨率乘数 ρ 的作用是减少计算成本。
1.3、作用
-
MobileNets 旨在为移动和嵌入式视觉应用提供高效的卷积神经网络。
-
它们在准确性和计算成本之间实现了有效的权衡,使其适用于资源受限的平台。
1.4、影响
-
MobileNets 已经对移动视觉领域产生了重大影响,为在资源受限的设备上部署深度学习模型提供了一种有效的方法。
-
它们已被广泛应用于各种移动视觉任务,包括图像分类、目标检测和人脸识别。
1.5、优点
高效性:MobileNets 的主要优势在于其高效性。 深度可分离卷积的使用大大减少了计算量和模型大小,使其能够在移动设备上运行。
可调性:宽度乘数和分辨率乘数提供了简单的超参数,可以有效地在延迟和准确性之间进行权衡, 使模型构建者能够根据其应用的约束选择合适大小的模型。
性能:MobileNets 在 ImageNet 分类上表现出强大的性能,并且在各种应用和用例中都是有效的,包括目标检测、细粒度分类、人脸属性和大规模地理定位。
1.6、缺点
精度限制:虽然 MobileNets 在效率方面表现出色,但与其他更大型、更复杂的模型相比,它们可能无法实现最高的精度。
权衡:宽度乘数和分辨率乘数的使用需要在准确性和效率之间进行权衡。 减少这些超参数会降低计算成本,但也会降低模型的准确性。
论文地址:
[1704.04861] MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
二、 MobileNetV1
2.1、网络的背景
传统的卷积神经网络要想有一个很好的效果的话,需要很大的参数量,同时由于参数 量大,导致网络在预测时要求的算力也是非常大的,那么对于我们的手机、嵌入式等 设备是非常不友好的,例如VGG16网络模型的权重大小大概有490M,ResNet的网络 152层的模型的权重大概有644M,这种数据量,是不可能在移动端进行部署的,暂 不提它的运算有多慢,如果手机的人脸识别用的ResNet的152层网络,那么光解锁这 个功能就需要占用手机600多M的存储空间,这是非常不合理的,但是AI最终的部署 除了服务器,更多的是我们平时使用的终端设备,例如:手机、人脸识别的打卡机 等,那么就需要能够在嵌入式端进行部署的网络,以服务我们的生活。
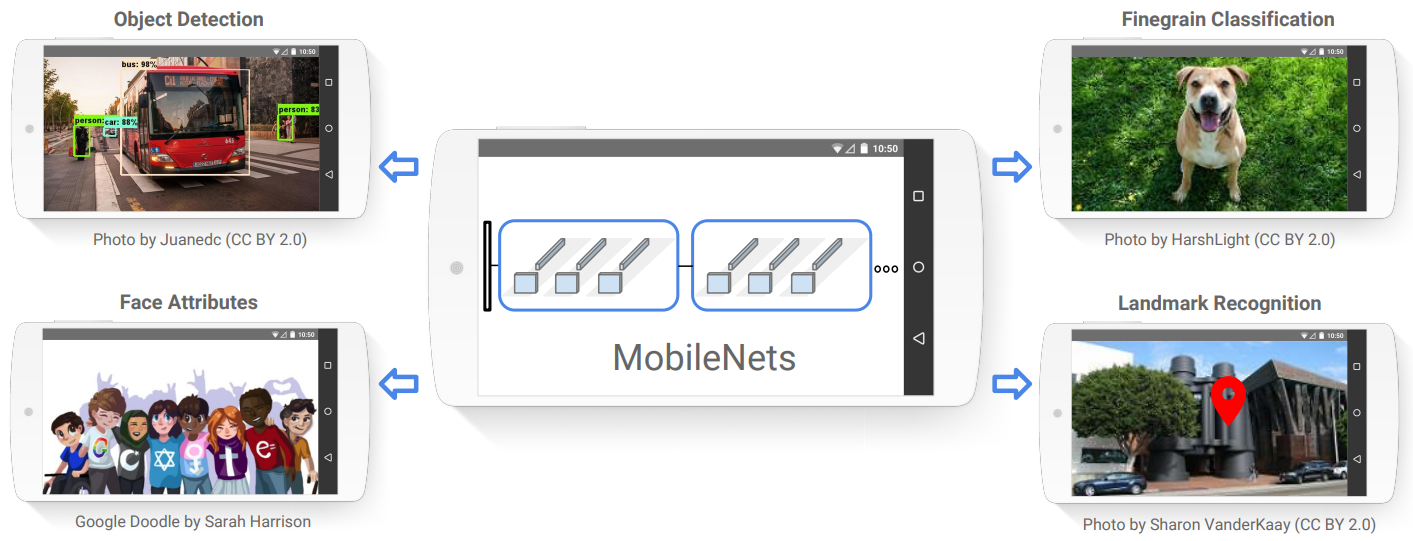
MobileNet网络是由谷歌团队在2017年提出的,专注于移动端或者嵌入式设备中轻量 级的卷积神经网络,相比传统的卷积神经网络呢,在准确率小幅降低的前提下,大大 减少我们模型的参数以及运算量。例如相比如VGG16,它的分类准确率下降了 0.9%,但是模型仅仅是VGG16的1/32到1/33之间。
2.2、Depthwise Convolution
这是一种全新的卷积方式,一般称为DW卷积(Depthwise Convolution),它能够 大大减少模型的参数以及运算量。
下图是经典的卷积,即卷积核的channel = 输入特征矩阵的channel,输出特征矩阵 的channel = 卷积核个数。在下图中,输入是一个有着3个channel的矩阵,经过4个 channel为3的3 x 3的卷积核进行卷积后,得到了拥有4个channel输出矩阵。
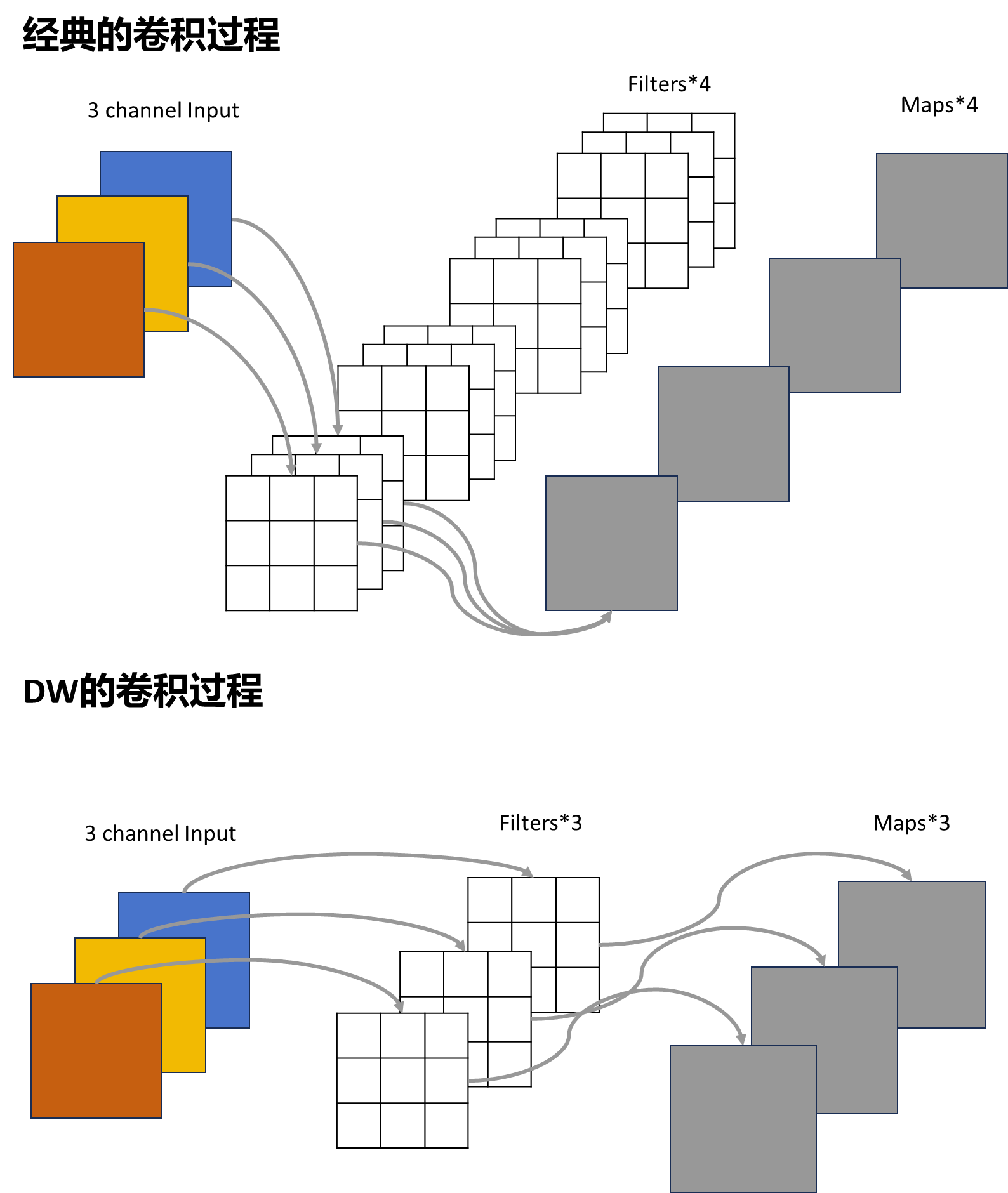
可以很直观的看出,DW卷积的卷积核深度,即channel和传统的卷积不同,它的 channel不等于输入特征矩阵的channel,而是等于1,它的每一个卷积核都与输入特 征矩阵的每一个channel进行卷积计算,从而得到输出特征矩阵的每一个channel, 也就说,DW卷积的每一个卷积核负责一个输入特征矩阵的channel,那么总结下 来:输入特征矩阵的channel = 卷积核个数 = 输出特征矩阵的channel。
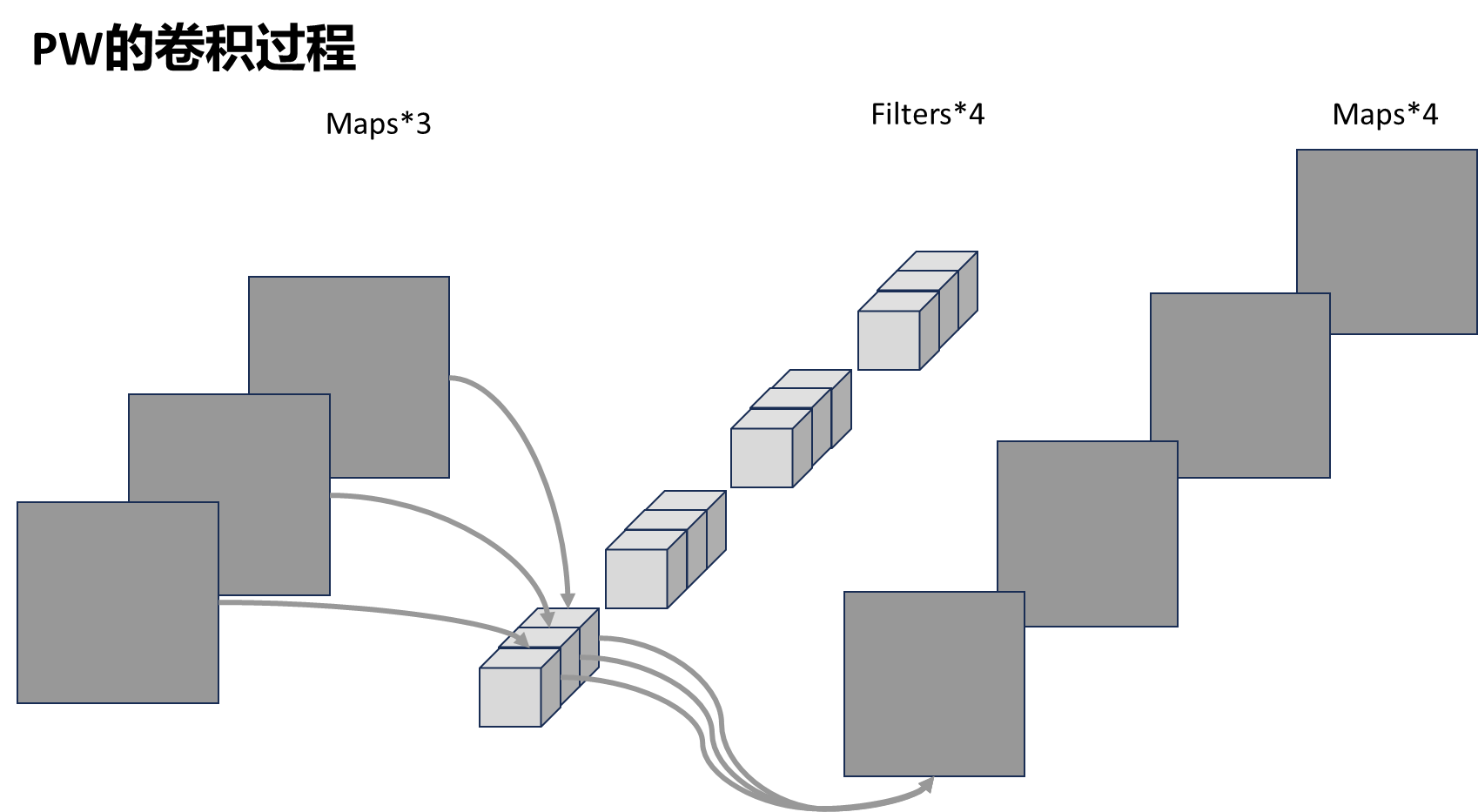
卷积核的channel与输入特征矩阵的channel相同,输出特征矩 阵的深度与卷积核的个数是相同的。可以看出,PW卷积和普通卷积是一样的,只是 卷积核的大小为1.
通常情况下,DW卷积核PW卷积是放在一起使用的,这种卷积比普通的卷积能节省 大量的计算量,由上图普通卷积、DW卷积、PW卷积三个图可知,普通卷积的输入 是3通道,输出是4通道,深度可分卷机由DW和PW一起构成(先DW后PW),所以 输入是3通道,输出是4通道,论文中有相关公式求解计算量,分子为深度可分卷积 的计算量,分母为普通卷积的计算量,对两者的计算量进行比对(黑色是paper的公 式,红色是我写的标注,paper里步距默认为1):

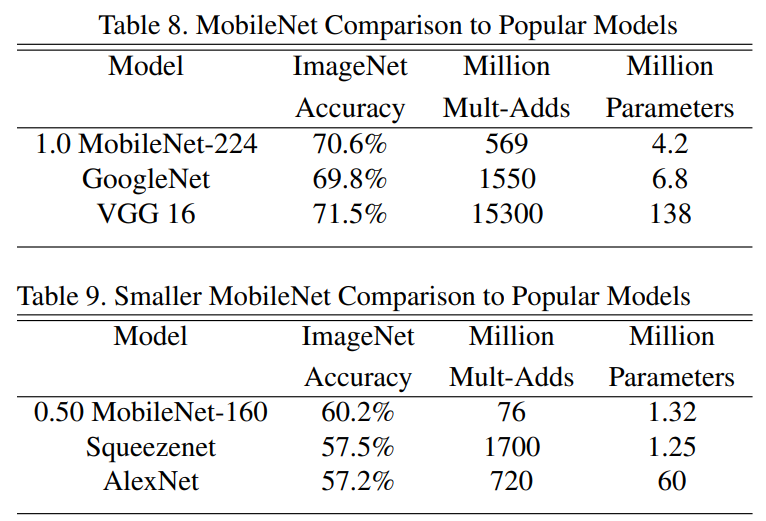
在paper中的Table 8中,展现了MobileNetV1网络和比较流行的网络的对比,如下图:
2.3、alpha ,beta的引入
alpha是卷积核个数的倍率,用来控制卷积过程中卷积核的个数,当取不同的alpha的时候, 准确率、计算量和参数量是不一样的,在paper中的Table 6中给出了不同 的对比。
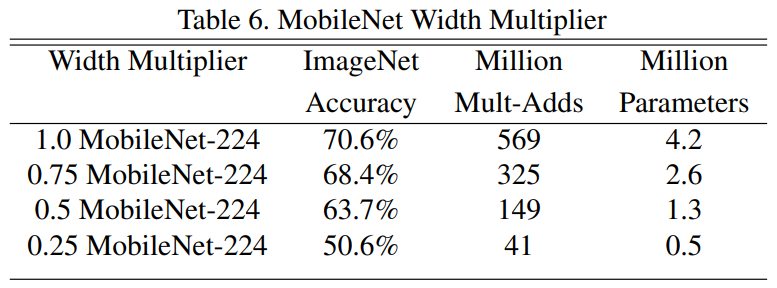
beta是分辨率参数,即输入图像尺寸的参数,在paper中的Table 7中给出了不同 的 对比,
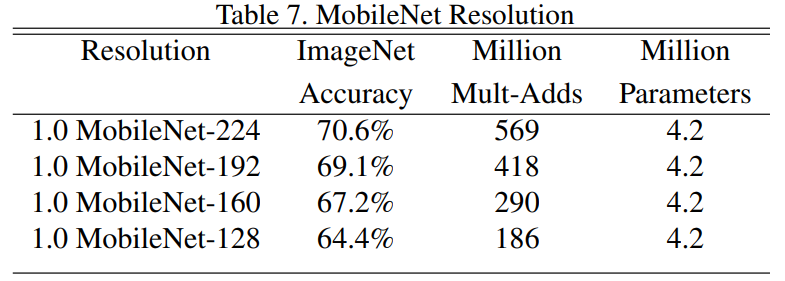
2.4、网络的问题
在使用过程中,发现了部分DW卷积核会废掉的情况,即卷积核的参数为0,这是因为
卷积核、通道数量以及权重数量太少,感受野太单薄;
. Relu激活函数;
精度低时,例如float18,int8这种低精度浮点数表示时很有限
2.5、网络的结构
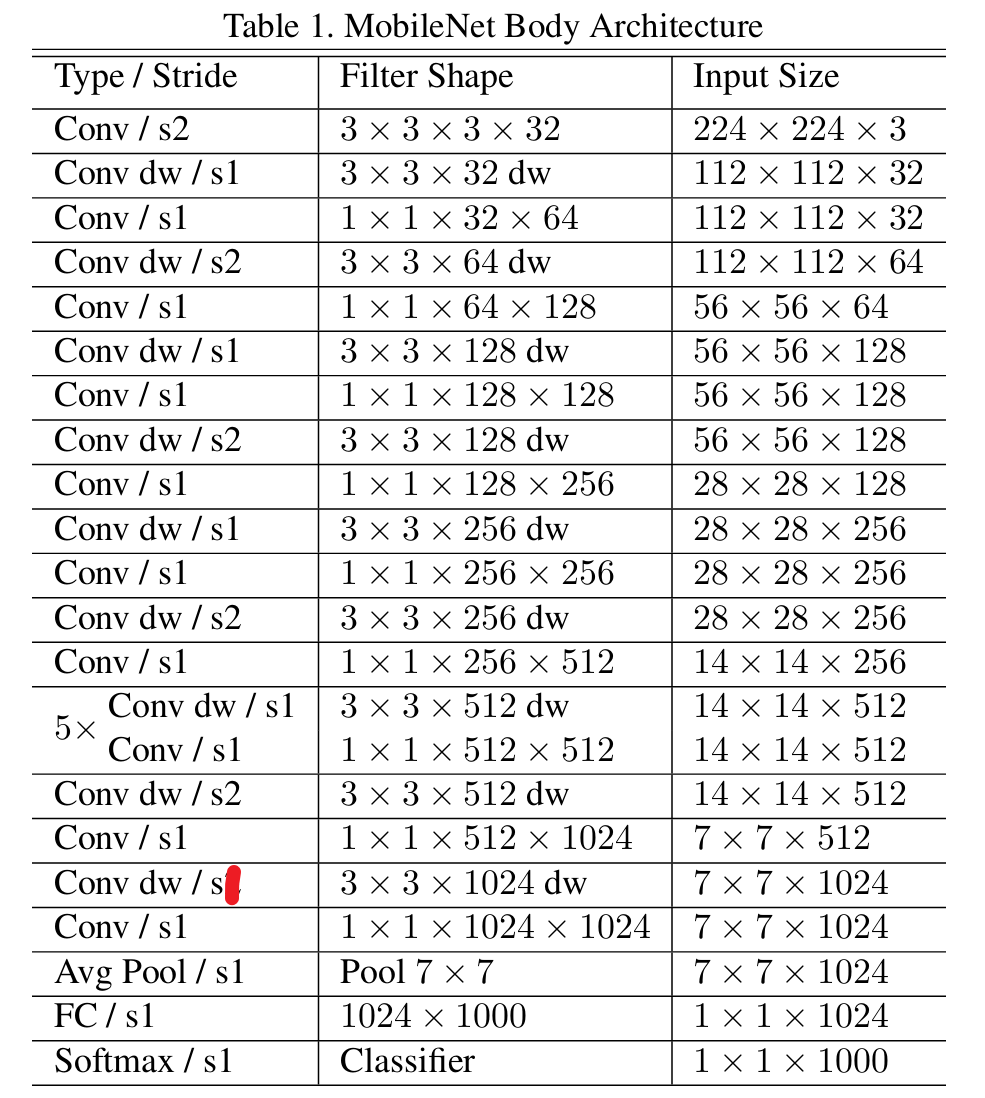

import torch
import torch.nn as nn
from torchsummary import summary
class DepthwiseConv(nn.Module):
"""
DepthwiseConv (深度可分离卷积) 模块。
它将一个标准的卷积层分解为深度卷积层 (depthwise convolution layer) 和逐点卷积层 (pointwise convolution layer),以减少计算量。
"""
def __init__(self, in_channels, out_channels, stride=1):
super(DepthwiseConv, self).__init__()
# depthwise (深度方向): 对每个输入通道分别进行卷积
self.depthwise = nn.Conv2d(in_channels, in_channels, kernel_size=3, stride=stride, padding=1, groups=in_channels, bias=False)
# bn1 (批归一化层1): 对深度卷积的输出进行批归一化
self.bn1 = nn.BatchNorm2d(in_channels)
# relu1 (ReLU激活函数1): 对批归一化的输出应用ReLU激活函数
self.relu1 = nn.ReLU(inplace=True)
# pointwise (逐点方向): 使用1x1卷积核进行通道间的线性组合
self.pointwise = nn.Conv2d(in_channels, out_channels, kernel_size=1, stride=1, padding=0, bias=False)
# bn2 (批归一化层2): 对逐点卷积的输出进行批归一化
self.bn2 = nn.BatchNorm2d(out_channels)
# relu2 (ReLU激活函数2): 对批归一化的输出应用ReLU激活函数
self.relu2 = nn.ReLU(inplace=True)
def forward(self, x):
# out (输出): 深度卷积的输出
out = self.depthwise(x)
# out (输出): 经过批归一化
out = self.bn1(out)
# out (输出): 经过ReLU激活
out = self.relu1(out)
# out (输出): 逐点卷积的输出
out = self.pointwise(out)
# out (输出): 经过批归一化
out = self.bn2(out)
# out (输出): 经过ReLU激活
out = self.relu2(out)
return out
class MobileNetV1(nn.Module):
"""
MobileNetV1 (MobileNetV1模型) 主体结构。
它由一系列的深度可分离卷积层 (DepthwiseConv layer) 和标准的卷积层 (Conv2d layer) 组成。
"""
def __init__(self, num_classes=1000):
super(MobileNetV1, self).__init__()
def conv_bn(inp, oup, stride):
"""
conv_bn (卷积-批归一化) 组合层。
包含一个卷积层 (Conv2d)、一个批归一化层 (BatchNorm2d) 和一个ReLU激活函数 (ReLU)。
inp (input channels): 输入通道数
oup (output channels): 输出通道数
stride (步长): 卷积步长
"""
return nn.Sequential(
nn.Conv2d(inp, oup, kernel_size=3, stride=stride, padding=1, bias=False),
nn.BatchNorm2d(oup),
nn.ReLU(inplace=True)
)
# model (模型): MobileNetV1 的Sequential模型容器
self.model = nn.Sequential(
# 初始卷积层: 将3通道的输入转换为32通道的特征图,步长为2
conv_bn(3, 32, 2),
# DepthwiseConv层: 输入32通道,输出64通道,步长为1
DepthwiseConv(32, 64, 1),
# DepthwiseConv层: 输入64通道,输出128通道,步长为2 (进行下采样)
DepthwiseConv(64, 128, 2),
# DepthwiseConv层: 输入128通道,输出128通道,步长为1
DepthwiseConv(128, 128, 1),
# DepthwiseConv层: 输入128通道,输出256通道,步长为2 (进行下采样)
DepthwiseConv(128, 256, 2),
# DepthwiseConv层: 输入256通道,输出256通道,步长为1
DepthwiseConv(256, 256, 1),
# DepthwiseConv层: 输入256通道,输出512通道,步长为2 (进行下采样)
DepthwiseConv(256, 512, 2),
# DepthwiseConv层: 输入512通道,输出512通道,步长为1 (重复5次)
DepthwiseConv(512, 512, 1),
DepthwiseConv(512, 512, 1),
DepthwiseConv(512, 512, 1),
DepthwiseConv(512, 512, 1),
# DepthwiseConv层: 输入512通道,输出1024通道,步长为2 (进行下采样)
DepthwiseConv(512, 1024, 2),
# DepthwiseConv层: 输入1024通道,输出1024通道,步长为1
DepthwiseConv(1024, 1024, 1),
# AvgPool2d (平均池化层): 对特征图进行全局平均池化,将尺寸变为1x1
nn.AvgPool2d(7),
)
# fc (全连接层): 将展平的特征向量映射到num_classes个类别
self.fc = nn.Linear(1024, num_classes)
def forward(self, x):
# out (输出): 模型前向传播的输出
out = self.model(x)
# out (输出): 将多维特征图展平成一维向量
out = torch.flatten(out, 1)
# out (输出): 通过全连接层得到最终的分类结果
out = self.fc(out)
return out
if __name__ == '__main__':
# model (模型): 实例化一个MobileNetV1模型,分类类别数为10
model = MobileNetV1(num_classes=10)
# summary (模型概要): 打印模型结构的概要信息,包括每层的输出形状和参数数量
print(summary(model, (3, 224, 224)))----------------------------------------------------------------
Layer (type) Output Shape Param #
================================================================
Conv2d-1 [-1, 32, 112, 112] 864
BatchNorm2d-2 [-1, 32, 112, 112] 64
ReLU-3 [-1, 32, 112, 112] 0
Conv2d-4 [-1, 32, 112, 112] 288
BatchNorm2d-5 [-1, 32, 112, 112] 64
ReLU-6 [-1, 32, 112, 112] 0
Conv2d-7 [-1, 64, 112, 112] 2,048
BatchNorm2d-8 [-1, 64, 112, 112] 128
ReLU-9 [-1, 64, 112, 112] 0
DepthwiseConv-10 [-1, 64, 112, 112] 0
Conv2d-11 [-1, 64, 56, 56] 576
BatchNorm2d-12 [-1, 64, 56, 56] 128
ReLU-13 [-1, 64, 56, 56] 0
Conv2d-14 [-1, 128, 56, 56] 8,192
BatchNorm2d-15 [-1, 128, 56, 56] 256
ReLU-16 [-1, 128, 56, 56] 0
DepthwiseConv-17 [-1, 128, 56, 56] 0
Conv2d-18 [-1, 128, 56, 56] 1,152
BatchNorm2d-19 [-1, 128, 56, 56] 256
ReLU-20 [-1, 128, 56, 56] 0
Conv2d-21 [-1, 128, 56, 56] 16,384
BatchNorm2d-22 [-1, 128, 56, 56] 256
ReLU-23 [-1, 128, 56, 56] 0
DepthwiseConv-24 [-1, 128, 56, 56] 0
Conv2d-25 [-1, 128, 28, 28] 1,152
BatchNorm2d-26 [-1, 128, 28, 28] 256
ReLU-27 [-1, 128, 28, 28] 0
Conv2d-28 [-1, 256, 28, 28] 32,768
BatchNorm2d-29 [-1, 256, 28, 28] 512
ReLU-30 [-1, 256, 28, 28] 0
DepthwiseConv-31 [-1, 256, 28, 28] 0
Conv2d-32 [-1, 256, 28, 28] 2,304
BatchNorm2d-33 [-1, 256, 28, 28] 512
ReLU-34 [-1, 256, 28, 28] 0
Conv2d-35 [-1, 256, 28, 28] 65,536
BatchNorm2d-36 [-1, 256, 28, 28] 512
ReLU-37 [-1, 256, 28, 28] 0
DepthwiseConv-38 [-1, 256, 28, 28] 0
Conv2d-39 [-1, 256, 14, 14] 2,304
BatchNorm2d-40 [-1, 256, 14, 14] 512
ReLU-41 [-1, 256, 14, 14] 0
Conv2d-42 [-1, 512, 14, 14] 131,072
BatchNorm2d-43 [-1, 512, 14, 14] 1,024
ReLU-44 [-1, 512, 14, 14] 0
DepthwiseConv-45 [-1, 512, 14, 14] 0
Conv2d-46 [-1, 512, 14, 14] 4,608
BatchNorm2d-47 [-1, 512, 14, 14] 1,024
ReLU-48 [-1, 512, 14, 14] 0
Conv2d-49 [-1, 512, 14, 14] 262,144
BatchNorm2d-50 [-1, 512, 14, 14] 1,024
ReLU-51 [-1, 512, 14, 14] 0
DepthwiseConv-52 [-1, 512, 14, 14] 0
Conv2d-53 [-1, 512, 14, 14] 4,608
BatchNorm2d-54 [-1, 512, 14, 14] 1,024
ReLU-55 [-1, 512, 14, 14] 0
Conv2d-56 [-1, 512, 14, 14] 262,144
BatchNorm2d-57 [-1, 512, 14, 14] 1,024
ReLU-58 [-1, 512, 14, 14] 0
DepthwiseConv-59 [-1, 512, 14, 14] 0
Conv2d-60 [-1, 512, 14, 14] 4,608
BatchNorm2d-61 [-1, 512, 14, 14] 1,024
ReLU-62 [-1, 512, 14, 14] 0
Conv2d-63 [-1, 512, 14, 14] 262,144
BatchNorm2d-64 [-1, 512, 14, 14] 1,024
ReLU-65 [-1, 512, 14, 14] 0
DepthwiseConv-66 [-1, 512, 14, 14] 0
Conv2d-67 [-1, 512, 14, 14] 4,608
BatchNorm2d-68 [-1, 512, 14, 14] 1,024
ReLU-69 [-1, 512, 14, 14] 0
Conv2d-70 [-1, 512, 14, 14] 262,144
BatchNorm2d-71 [-1, 512, 14, 14] 1,024
ReLU-72 [-1, 512, 14, 14] 0
DepthwiseConv-73 [-1, 512, 14, 14] 0
Conv2d-74 [-1, 512, 7, 7] 4,608
BatchNorm2d-75 [-1, 512, 7, 7] 1,024
ReLU-76 [-1, 512, 7, 7] 0
Conv2d-77 [-1, 1024, 7, 7] 524,288
BatchNorm2d-78 [-1, 1024, 7, 7] 2,048
ReLU-79 [-1, 1024, 7, 7] 0
DepthwiseConv-80 [-1, 1024, 7, 7] 0
Conv2d-81 [-1, 1024, 7, 7] 9,216
BatchNorm2d-82 [-1, 1024, 7, 7] 2,048
ReLU-83 [-1, 1024, 7, 7] 0
Conv2d-84 [-1, 1024, 7, 7] 1,048,576
BatchNorm2d-85 [-1, 1024, 7, 7] 2,048
ReLU-86 [-1, 1024, 7, 7] 0
DepthwiseConv-87 [-1, 1024, 7, 7] 0
AvgPool2d-88 [-1, 1024, 1, 1] 0
Linear-89 [-1, 10] 10,250
================================================================
Total params: 2,948,426
Trainable params: 2,948,426
Non-trainable params: 0
----------------------------------------------------------------
Input size (MB): 0.57
Forward/backward pass size (MB): 130.74
Params size (MB): 11.25
Estimated Total Size (MB): 142.56
----------------------------------------------------------------

















 1563
1563

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









