






 本文介绍如何使用HDFS命令进行文件管理,包括创建时间戳文件、复制文件或目录、上传及下载文件等操作,并提供了一个定时采集数据到HDFS的Shell脚本示例。
本文介绍如何使用HDFS命令进行文件管理,包括创建时间戳文件、复制文件或目录、上传及下载文件等操作,并提供了一个定时采集数据到HDFS的Shell脚本示例。
接上节
创建时间戳文件
在/ied01目录里创建一个文件sunshine.txt,执行命令:hdfs dfs -touchz /ied01/sunshine.txt
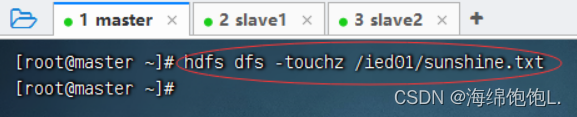
创建的是一个空文件,大小为0字节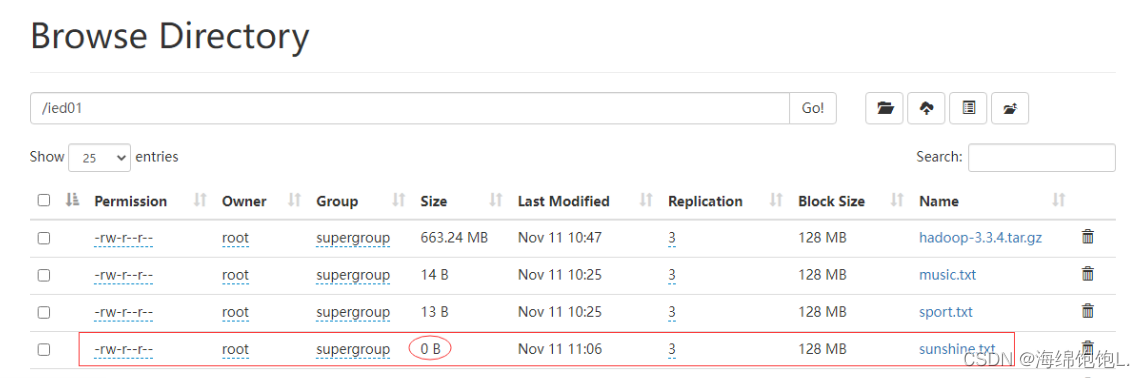
这种空文件,一般用作标识文件,也可叫做时间戳文件,再次在/ied01目录下创建sunshine.txt同名文件
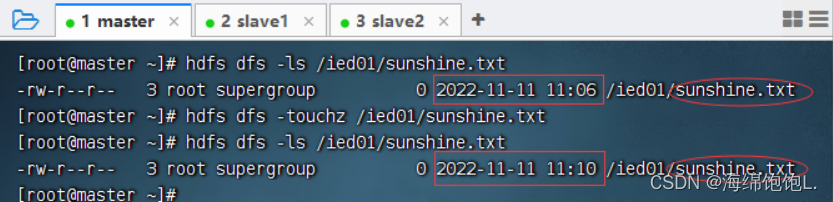
说明:如果touchz命令的路径指定的文件不存在,那就创建一个空文件;如果指定的文件存在,那就改变该文件的时间戳。
复制文件或目录
准备工作:创建/ied02目录

同名复制文件
将/ied01/music.txt复制到/ied02里,执行命令:hdfs dfs -cp /ied01/music.txt /ied02

查看拷贝生成的文件

改名复制文件
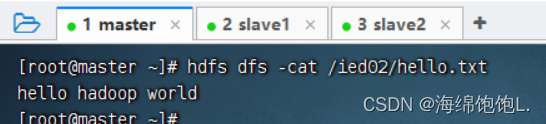
将/ied01/test.txt复制到/ied02目录,改名为hello.txt,执行命令:hdfs dfs -cp /ied01/exam.txt /ied02/hello.txt

查看拷贝后的文件内容
复制目录
将/ied01目录复制到/ied03目录,执行命令:hdfs dfs -cp /ied01 /ied03

查看拷贝后的目录
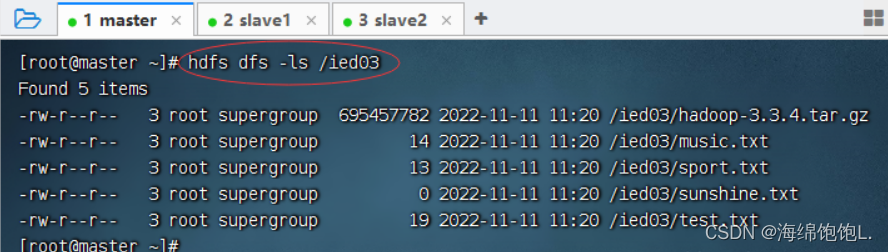
查看文件大小
执行命令:hdfs dfs -du /ied01/test.txt
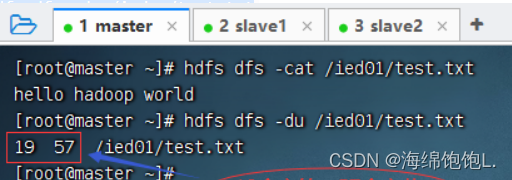
可以看到文件/ied01/test.txt大小是19个字符,包含一个看不见的结束符
上传文件
-copyFromLocal类似于-put,执行命令:hdfs dfs -copyFromLocal merger.txt /ied02

查看是否上传成功
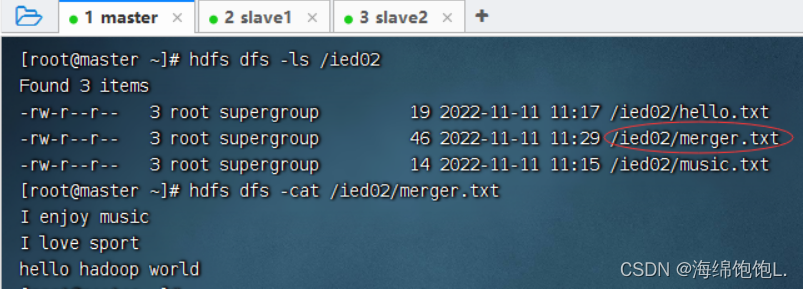
下载文件
-copyToLocal类似于-get,执行命令:hdfs dfs -copyToLocal /ied01/sunshine.txt sunlight.txt

查看是否下载成功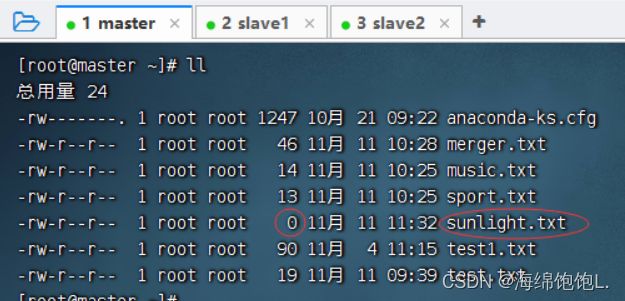
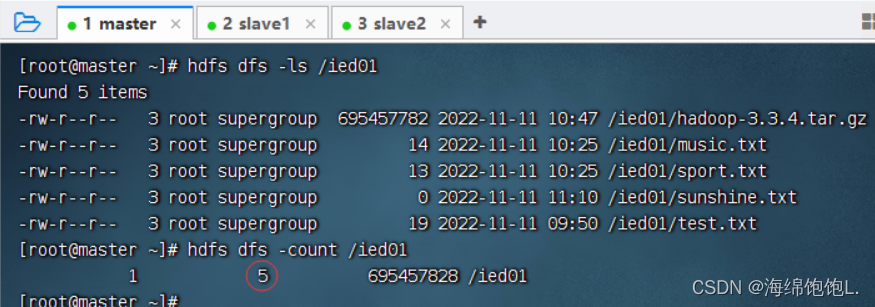
查看某目录下文件个数
执行命令:hdfs dfs -count /ied01
检查hadoop本地库
执行命令:hdfs checknative -a
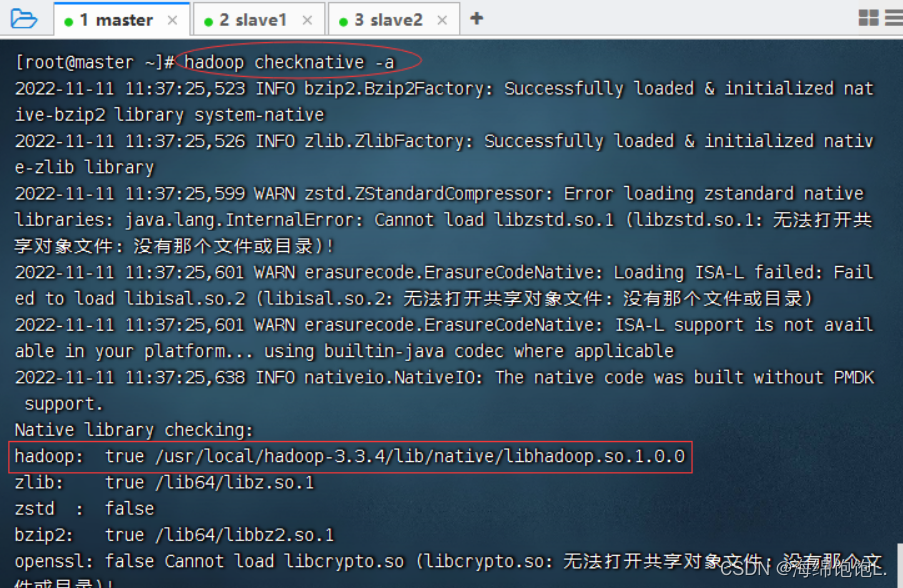
查看hadoop本地库文件

进入和退出安全模式
进入安全模式
执行命令:hdfs dfsadmin -safemode enter, 注意:进入安全模式之后,只能读不能写
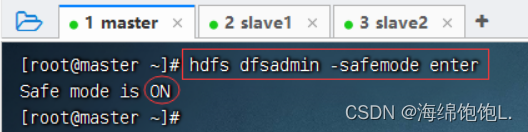
此时,如果要创建目录,就会报错

退出安全模式
执行命令:hdfs dfsadmin -safemode leave
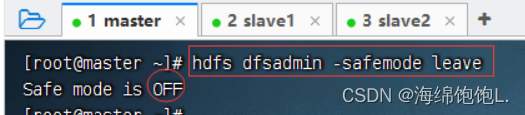
此时,创建目录/ied04就没有任何问题
案例- Shell定时采集数据到HDFS
服务器每天会产生大量日志数据,并且日志文件可能存在于每个应用程序指定的data目录中,在不使用其它工具的情况下,将服务器中的日志文件规范地存放在HDFS中。通过编写简单的Shell脚本,用于每天自动采集服务器上的日志文件,并将海量的日志上传至HDFS中。
创建日志文件存放的目录/export/data/logs/log,执行命令:mkdir -p /export/data/logs/log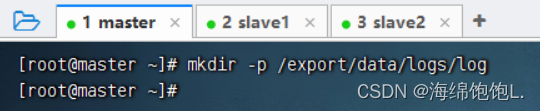
创建待上传文件存放的目录/export/data/logs/toupload,执行命令:mkdir -p /export/data/logs/toupload
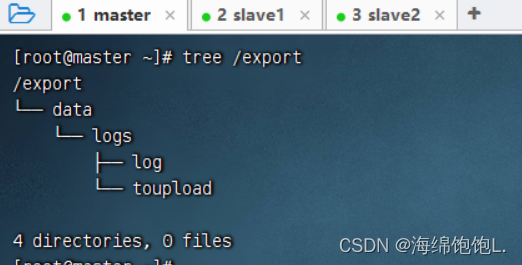
查看创建的目录树结构
编写脚本,实现功能
进入/export/data/logs目录
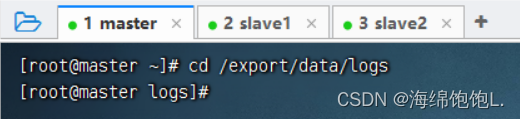
执行命令:vim upload2HDFS.sh
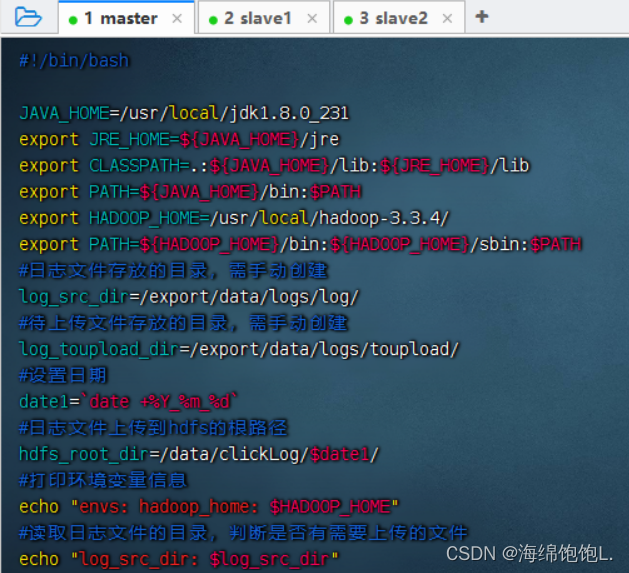
#!/bin/bash
JAVA_HOME=/usr/local/jdk1.8.0_231
export JRE_HOME=${JAVA_HOME}/jre
export CLASSPATH=.:${JAVA_HOME}/lib:${JRE_HOME}/lib
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop-3.3.4/
export PATH=${HADOOP_HOME}/bin:${HADOOP_HOME}/sbin:$PATH
#日志文件存放的目录,需手动创建
log_src_dir=/export/data/logs/log/
#待上传文件存放的目录,需手动创建
log_toupload_dir=/export/data/logs/toupload/
#设置日期
date1=`date +%Y_%m_%d`
#日志文件上传到hdfs的根路径
hdfs_root_dir=/data/clickLog/$date1/
#打印环境变量信息
echo "envs: hadoop_home: $HADOOP_HOME"
#读取日志文件的目录,判断是否有需要上传的文件
echo "log_src_dir: $log_src_dir"
ls $log_src_dir | while read fileName
do
if [[ "$fileName" == access.log.* ]]; then
date=`date +%Y_%m_%d_%H_%M_%S`
#将文件移动到待上传目录并重命名
echo "moving $log_src_dir$fileName to $log_toupload_dir"lzy_click_log_$fileName"$date"
mv $log_src_dir$fileName $log_toupload_dir"lzy_click_log_$fileName"$date
#将待上传的文件path写入一个列表文件willDoing,
echo $log_toupload_dir"lzy_click_log_$fileName"$date >> $log_toupload_dir"willDoing."$date
fi
done
#找到列表文件willDoing
ls $log_toupload_dir | grep will | grep -v "_COPY_" | grep -v "_DONE_" | while read line
do
#打印信息
echo "toupload is in file: $line"
#将待上传文件列表willDoing改名为willDoing_COPY_
mv $log_toupload_dir$line $log_toupload_dir$line"_COPY_"
#读列表文件willDoing_COPY_的内容(一个一个的待上传文件名)
#此处的line 就是列表中的一个待上传文件的path
cat $log_toupload_dir$line"_COPY_" | while read line
do
#打印信息
echo "puting...$line to hdfs path...$hdfs_root_dir"
hdfs dfs -mkdir -p $hdfs_root_dir
hdfs dfs -put $line $hdfs_root_dir
done
mv $log_toupload_dir$line"_COPY_" $log_toupload_dir$line"_DONE_"
done
编辑权限,执行命令:chmod u+x upload2HDFS.sh
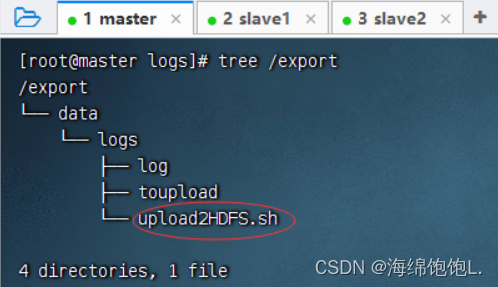
查看/export目录树结构
运行脚本,查看结果
为了模拟生产环境,在日志存放目录/export/data/logs/log/中,手动创建日志文件,access.log表示正在源源不断的产生日志的文件,access.log.1、access.log.2等表示已经滚动完毕的日志文件,即为待上传日志文件。
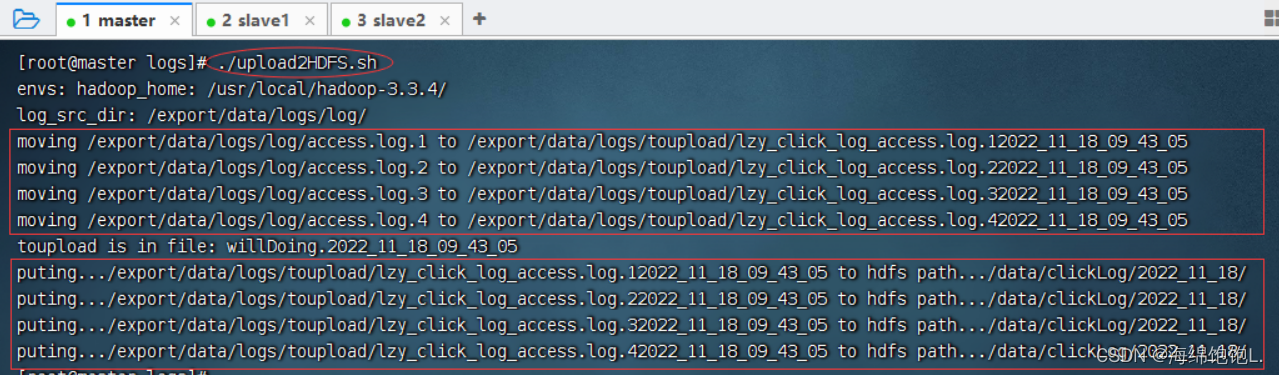
在upload2HDFS.sh文件路径下运行脚本,先将日志存放目录log中的日志文件移到待上传toupload目录下,并根据业务需求重命名;然后脚本执行“hdfs dfs -put”上传命令,将待上传目录下的所有日志文件上传至HDFS;最后通过HDFS WebUI界面可看到需要采集的日志文件已按照日期分类,上传至HDFS中。
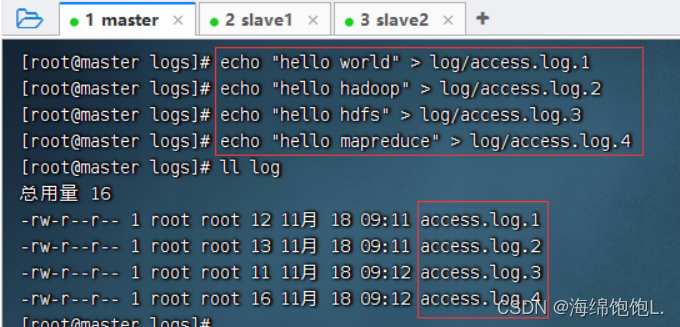
创建四个日志文件(必须以access.log.打头)
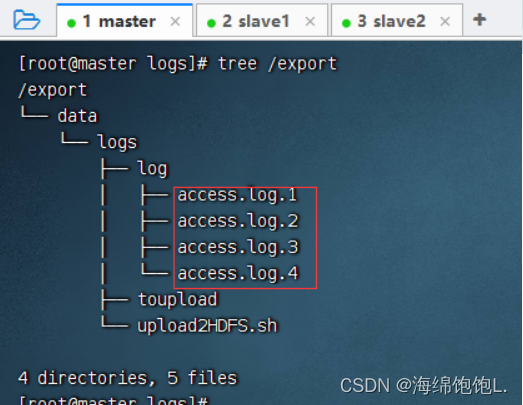
查看/export目录树结构
执行命令:./upload2HDFS.sh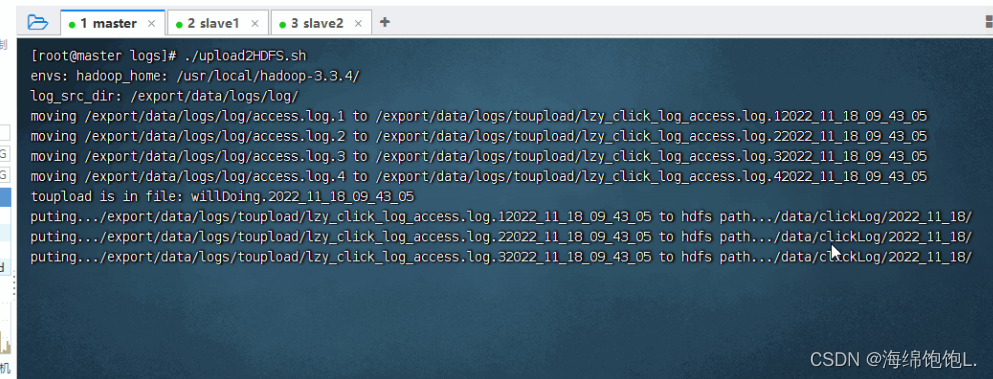
查看/export目录树结构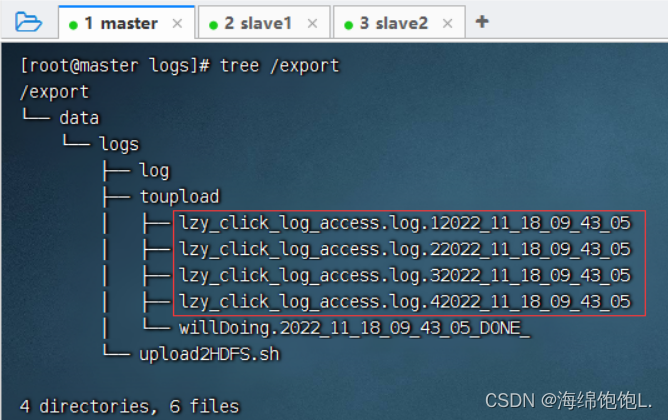
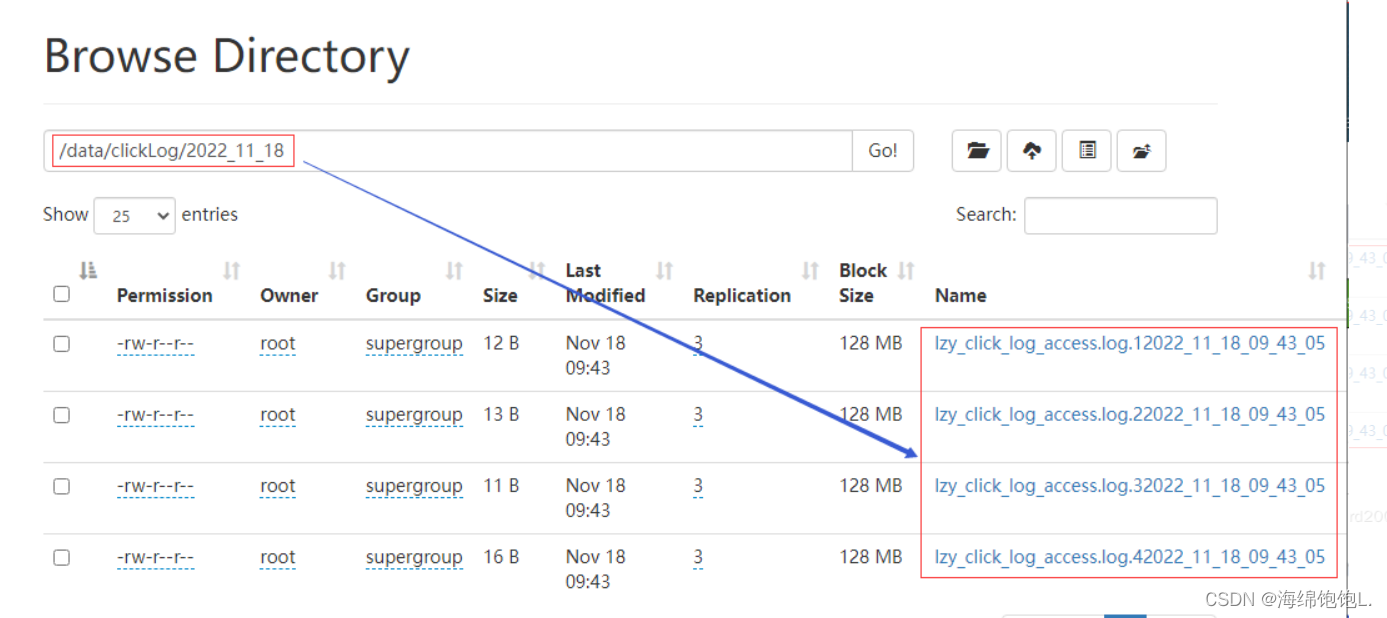

















 1233
1233

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









