






1. MongoDB简介
1.1. 吐槽和评论数据特点分析
吐槽和评论两项功能存在以下特点:
-
数据量大
-
写入操作频繁
-
价值较低
对于这样的数据,我们更适合使用MongoDB来实现数据的存储
1.2. 什么是MongoDB
MongoDB 是一个跨平台的,面向文档的数据库,是当前 NoSQL 数据库产品中最热门的一种。它介于关系数据库和非关系数据库之间,是非关系数据库当中功能最丰富,最像关系数据库的产品。它支持的数据结构非常松散,是类似 JSON 的 BSON 格式,因此可以存 储比较复杂的数据类型。MongoDB 的官方网站地址是:MongoDB: The Developer Data Platform | MongoDB
1.3. MongoDB特点
MongoDB 最大的特点是他支持的查询语言非常强大,其语法有点类似于面向对象的查询语言,几乎可以实现类似关系数据库单表查询的绝大部分功能,而且还支持对数据建立索引。它是一个面向集合的,模式自由的文档型数据库。
具体特点总结如下:
-
面向集合存储,易于存储对象类型的数据
-
模式自由
-
支持动态查询
-
支持完全索引,包含内部对象
-
支持复制和故障恢复
-
使用高效的二进制数据存储,包括大型对象(如视频等)
-
自动处理碎片,以支持云计算层次的扩展性
-
支持 Python,PHP,Ruby,Java,C,C#,Javascript,Perl 及 C++语言的驱动程序,社区中也提供了对 Erlang 及.NET 等平台的驱动程序
-
文件存储格式为 BSON(一种 JSON 的扩展)
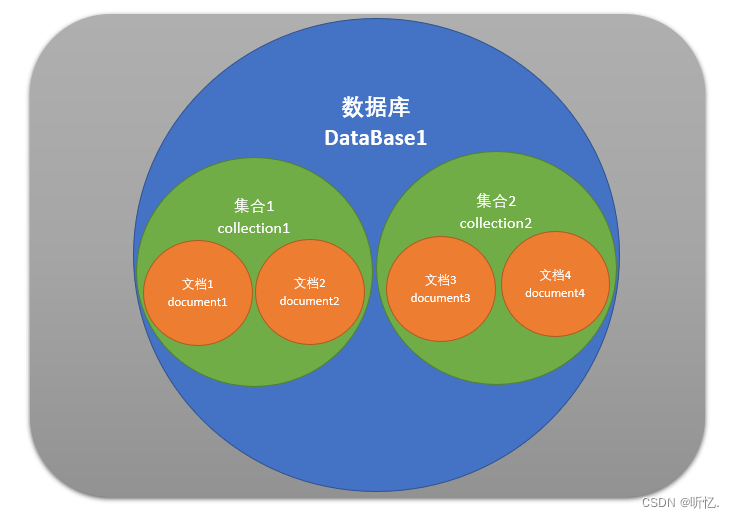
1.4. MongoDB体系结构
MongoDB 的逻辑结构是一种层次结构。主要由:文档(document)、集合(collection)、数据库(database)这三部分组成的。逻辑结构是面向用户的,用户使用 MongoDB 开发应用程序使用的就是逻辑结构。
-
MongoDB 的文档(document),相当于关系数据库中的一行记录。
-
多个文档组成一个集合(collection),相当于关系数据库的表。
-
多个集合(collection),逻辑上组织在一起,就是数据库(database)。
-
一个 MongoDB 实例支持多个数据库(database)。
文档(document)、集合(collection)、数据库(database)的层次结构如下图:
下表是MongoDB与MySQL数据库逻辑结构概念的对比
| MongoDb | 关系型数据库Mysql |
|---|---|
| 数据库(databases) | 数据库(databases) |
| 集合(collections) | 表(table) |
| 文档(document) | 行(row) |
1.5. 数据类型
基本数据类型:null:用于表示空值或者不存在的字段,{“x”:null}
布尔型:布尔类型有两个值true和false,{“x”:true}
数值:shell默认使用64为浮点型数值。{“x”:3.14}或{“x”:3}。对于整型值,可以使用NumberInt(4字节符号整数)或NumberLong(8字节符号整数),{“x”:NumberInt(“3”)}{“x”:NumberLong(“3”)}
字符串:UTF-8字符串都可以表示为字符串类型的数据,{“x”:“呵呵”}
日期:日期被存储为自新纪元依赖经过的毫秒数,不存储时区,{“x”:new Date()}
正则表达式:查询时,使用正则表达式作为限定条件,语法与JavaScript的正则表达式相同,{“x”:/[abc]/}
数组:数据列表或数据集可以表示为数组,{“x”: [“a“,“b”,”c”]}
内嵌文档:文档可以嵌套其他文档,被嵌套的文档作为值来处理,{“x”:{“y”:3 }}
对象Id:对象id是一个12字节的字符串,是文档的唯一标识,{“x”: objectId() }
二进制数据:二进制数据是一个任意字节的字符串。它不能直接在shell中使用。如果要将非utf-字符保存到数据库中,二进制数据是唯一的方式。
代码:查询和文档中可以包括任何JavaScript代码,{“x”:function(){/…/}}
2. MongoDB
2.1. Docker安装MongoDB
在宿主机创建mongo容器 :
docker run -id --name mongo -v /docker_volume/mongodb/data:/data/db -p 27017:27017 mongo:4.4
远程登陆 :
mongo 地址
在命令提示符输入以下命令即可完成登陆 :
mongo
退出mongodb :
exit
以吐槽表为例讲解MongoDB常用命令 :
| 吐槽表 | spit | |
|---|---|---|
| 字段名称 | 字段含义 | 字段类型 |
| _id | ID | 文本 |
| content | 吐槽内容 | 文本 |
| publishtime | 发布日期 | 日期 |
| userid | 发布人ID | 文本 |
| nickname | 发布人昵称 | 文本 |
| visits | 浏览量 | 整型 |
| thumbup | 点赞数 | 整型 |
| share | 分享数 | 整型 |
| comment | 回复数 | 整型 |
| state | 是否可见 | 文本 |
| parentid | 上级ID | 文本 |
2.2. 常用命令
2.2.1. 选择和创建数据库
选择和创建数据库的语法格式:
==use 数据库名称==
如果数据库不存在则自动创建以下语句创建spit数据库
use spit
2.2.2. 插入与查询文档
插入文档的语法格式:
==db.集合名称.insert(数据);==
我们这里可以插入以下测试数据:
db.spit.insert({content:"哇哦哦哦哦哦哦!",userid:"1011",nickname:"听忆",visits:NumberInt(902)})
查询集合的语法格式:
==db.集合名称.find()==
如果我们要查询spit集合的所有文档,我们输入以下命令
db.spit.find() 这里你会发现每条文档会有一个叫_id的字段,这个相当于我们原来关系数据库中表的主键,当你在插入文档记录时没有指定该字段,MongoDB会自动创建,其类型是ObjectID类型。如果我们在插入文档记录时指定该字段也可以,其类型可以是ObjectID类型,也可以是MongoDB支持的任意类型。输入以下测试语句:
db.spit.insert({_id:"1",content:"我还是没有想明白到底为啥出错",userid:"1012",nickname:"小明",visits:NumberInt(2020)});
db.spit.insert({_id:"2",content:"加班到半夜",userid:"1013",nickname:"凯撒",visits:NumberInt(1023)});
db.spit.insert({_id:"3",content:"手机流量超了咋办?",userid:"1013",nickname:"凯撒",visits:NumberInt(111)});
db.spit.insert({_id:"4",content:"坚持就是胜利",userid:"1014",nickname:"诺诺",visits:0000000000000(1223)});如果我想按一定条件来查询,比如我想查询userid为1013的记录,怎么办?很简单!只要在find()中添加参数即可,参数也是json格式,如下 :
db.spit.find({userid:'1013'})如果你只需要返回符合条件的第一条数据,我们可以使用findOne命令来实现 :
db.spit.findOne({userid:'1013'}) 如果你想返回指定条数的记录,可以在find方法后调用limit来返回结果,例如 :
db.spit.find().limit(3)2.2.3. 修改与删除文档
修改文档的语法结构:
==db.集合名称.update(条件,修改后的数据)==
如果我们想修改_id为1的记录,浏览量为1000,输入以下语句:
db.spit.update({_id:"1"},{visits:NumberInt(1000)}) 执行后,我们会发现,这条文档除了visits字段其它字段都不见了,为了解决这个问题,我们需要使用修改器$set来实现,命令如下:
db.spit.update({_id:"2"},{$set:{visits:NumberInt(2000)}}) 这样就OK啦。删除文档的语法结构:
==db.集合名称.remove(条件)==
以下语句可以将数据全部删除,请慎用:
db.spit.remove({})如果删除visits=1000的记录,输入以下语句:
db.spit.remove({visits:1000})2.2.4. 统计条数
统计记录条件使用count()方法。以下语句统计spit集合的记录数 :
db.spit.count() 如果按条件统计 ,例如:统计userid为1013的记录条数 :
db.spit.count({userid:"1013"}) 2.2.5. 模糊查询
MongoDB的模糊查询是通过正则表达式的方式实现的。格式为:
==db.集合名称.find({key:/模糊查询字符串/ )==
例如,我要查询吐槽内容包含“流量”的所有文档,代码如下:
db.spit.find({content:/流量/}) 如果要查询吐槽内容中以“加班”开头的,代码如下:
db.spit.find({content:/^加班/}) 2.2.6. 大于 小于 不等于
<, <=, >, >= 这个操作符也是很常用的,格式如下:
==db.集合名称.find({ "field" : { $gt: value }}) // 大于: field > value====db.集合名称.find({ "field" : { $lt: value }}) // 小于: field < value====db.集合名称.find({ "field" : { $gte: value }}) // 大于等于: field >= value====db.集合名称.find({ "field" : { $lte: value }}) // 小于等于: field <= value====db.集合名称.find({ "field" : { $ne: value }}) // 不等于: field != value==
示例:查询吐槽浏览量大于1000的记录:
db.spit.find({visits:{$gt:1000}}) 2.2.7. 包含与不包含
包含使用$in操作符。示例:查询吐槽集合中userid字段包含1013和1014的文档
db.spit.find({userid:{$in:["1013","1014"]}}) 不包含使用$nin操作符。示例:查询吐槽集合中userid字段不包含1013和1014的文档
db.spit.find({userid:{$nin:["1013","1014"]}})2.2.8. 条件连接
我们如果需要查询同时满足两个以上条件,需要使用$and操作符将条件进行关联。(相当于SQL的and)格式为:
==$and:[ { },{ },{ } ]==
示例:查询吐槽集合中visits大于等于1000 并且小于2000的文档
db.spit.find({$and:[ {visits:{$gte:1000}} ,{visits:{$lt:2000} }]}) 如果两个以上条件之间是或者的关系,我们使用 操作符进行关联,与前面and的使用方式相同格式为:
==$or:[ { },{ },{ } ]==
示例:查询吐槽集合中userid为1013,或者浏览量小于2000的文档记录
db.spit.find({$or:[ {userid:"1013"} ,{visits:{$lt:2000} }]}) 2.2.9. 列值增长
如果我们想实现对某列值在原有值的基础上进行增加或减少,可以使用$inc运算符来实现
db.spit.update({_id:"2"},{$inc:{visits:NumberInt(1)}} )














 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









