






一、概述
图像分割是许多视觉理解系统的重要组成部分。它包括将图像(或视频帧)分割成多个片段或对象。
分割在医学图像分析(例如,肿瘤边界提取和组织体积测量),自主载体(例如,可导航表面和行人检测),视频监控,和增强现实起到了非常重要的作用。
图像分割可以表述为带有语义标签的像素分类问题(语义分割)或单个对象分割问题(实例分割)。语义分割对所有图像像素使用一组对象类别(如人、车、树、天空)进行像素级标记,因此通常比预测整个图像的单个标签的图像分类困难。实例分割通过检测和描绘图像中的每个感兴趣对象(例如,个体的分割),进一步扩展了语义分割的范围。
二、什么是图像分割
图像分割:预测目标的轮廓。将不同的像素划分到不同的类别,非常细粒度的分类,特性可以是灰度、颜色、纹理等;目标可以对应单个区域,也可以对应多个区域。
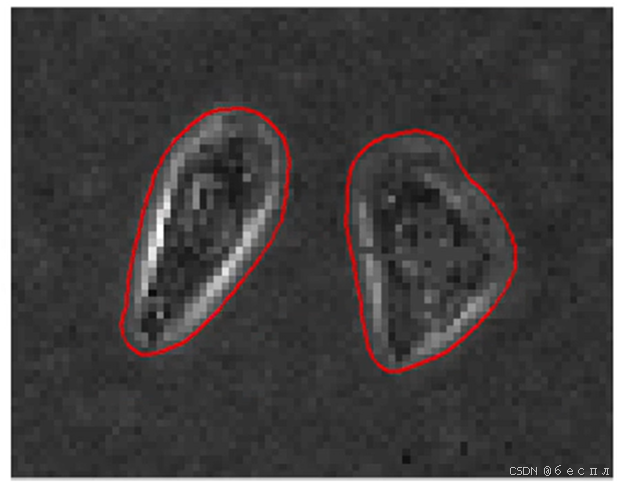

三、图像分割的应用场景
1.人像抠图,医学组织提取,遥感图像分析,自动驾驶,材料图像等。
2.物体Things:可数前景目标(行人等)。
3.事物Stuff:不可数背景(天空,草地,路面)。


四、图像分割的三层境界

1.语义分割(semantic segmentation)
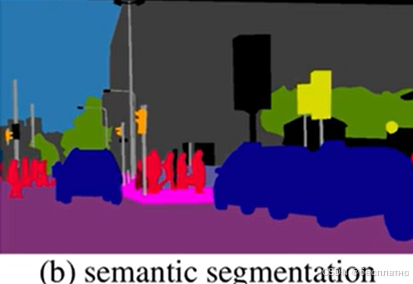
语义分割(semantic segmentation)从字面意思上理解就是让计算机根据图像的语义来进行分割,例如让计算机在输入下面左图的情况下,能够输出右图。语义在语音识别中指的是语音的意思,在图像领域,语义指的是图像的内容,对图片意思的理解,比如左图的语义就是三个人骑着三辆自行车;分割的意思是从像素的角度分割出图片中的不同对象,对原图中的每个像素都进行标注。
目前语义分割的应用领域主要有:
- 地理信息系统
- 无人车驾驶
- 医疗影像分析
- 机器人等领域
对图像中的每个像素打上类别标签,如下图,把图像分为人(红色)、树木(深绿)、地面(深紫色)、天空(浅蓝色)、车辆(深蓝色)等标签。
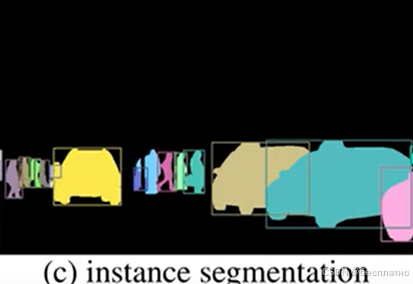
2.实例分割(instance segmentation)
目标检测和语义分割的结合,在图像中将目标检测出来(目标检测),然后对每个像素打上标签(语义分割)。对比上图、下图,如以人(person)和车辆(car)为目标,语义分割不区分属于相同类别的不同实例,实例分割区分同类的不同实例。(使用不同颜色区分不同的人和车辆)
3.全景分割(panoptic segmentation)
语义分割和实例分割的结合,即要对所有目标都检测出来,又要区分出同个类别中的不同实例。对比上图、下图,实例分割对图像中的目标(如上图中的人)进行检测和按像素分割,区分不同实例(使用不同颜色),而全景分割是对图中的所有物体包括背景都要进行检测和分割,区分不同实例。(使用不同颜色)

五、图像分割的数据集
1.VOC数据集
PASCAL VOC挑战赛 (The PASCAL Visual Object Classes )是一个世界级的计算机视觉挑战赛,PASCAL全称:Pattern Analysis, Statical Modeling and Computational Learning,是一个由欧盟资助的网络组织。PASCAL VOC挑战赛主要包括以下几类:图像分类(Object Classification),目标检测(Object Detection),目标分割(Object Segmentation),行为识别(Action Classification) 等。
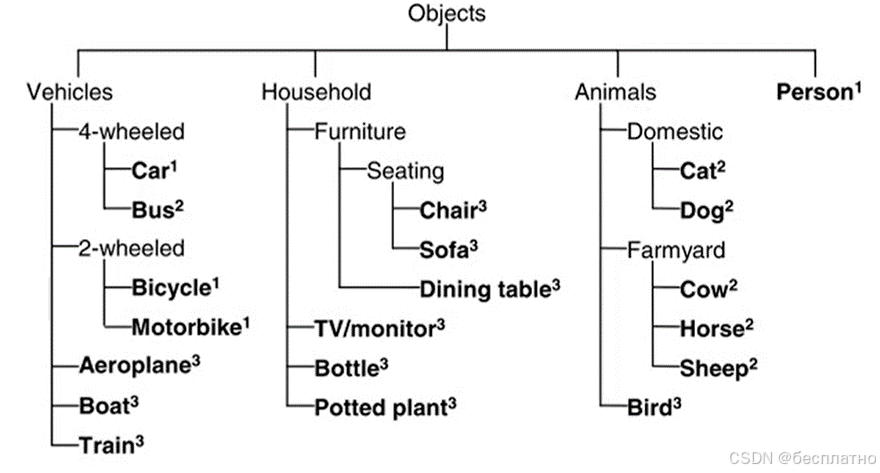
在Pascal VOC数据集中主要包含20个目标类别,下图展示了所有类别的名称以及所属超类。其中包括了4大类,20小类、VOC 2007:9963图片/24640目标;VOC 2012:23080图片/54900目标。
2.Cityscape数据集

Cityscapes(城市景观数据集)拥有5000张在城市环境中驾驶场景的图像(2975train,500 val,1525test)。它具有19个类别的密集像素标注(97%coverage),其中8个具有实例级分割。这是一个新的大规模数据集,其中包含一组不同的立体视频序列,记录在50个不同城市的街道场景。


城市景观数据集中于对城市街道场景的语义理解图片数据集,该大型数据集包含来自50个不同城市的街道场景中记录的多种立体视频序列,除了20000个弱注释帧以外,还包含5000帧高质量像素级注释。因此,数据集的数量级要比以前的数据集大的多。Cityscapes数据集共有fine和coarse两套评测标准,前者提供5000张精细标注的图像,后者提供5000张精细标注外加20000
张粗糙标注的图像。
3.COCO数据集
MS COCO的全称是Microsoft Common Objects in Context,起源于微软于2014年出资标注的Microsoft COCO数据集,与ImageNet竞赛一样,被视为是计算机视觉领域最受关注和最权威的比赛之一。
COCO数据集是一个大型的、丰富的物体检测,分割和字幕数据集。这个数据集以scene understanding为目标,主要从复杂的日常场景中截取,图像中的目标通过精确的segmentation进行位置的标定。图像包括91类目标,328,000影像和2,500,000个label。目前为止有语义分割的最大数据集,提供的类别有80 类,有超过33 万张图片,其中20 万张有标注,整个数据集中个体的数目超过150 万个。
COCO数据集:以场景理解为目标,特别选取比较复杂的日常场景。

六、语义分割的评估指标
Pixel Accuracy(像素准确率、PA):逐像素分类精度。
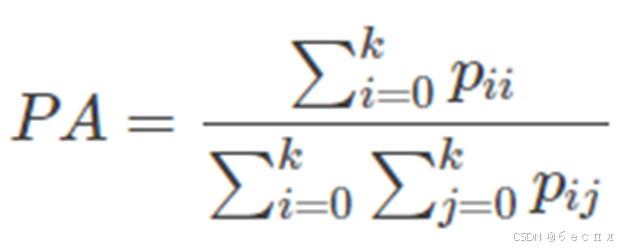
Class Pixel Accuray(类别像素准确率、CPA)
Mean Pixel Accuracy(类别平均像素准确率、MPA):每个类内被正确分类像素数的比例。
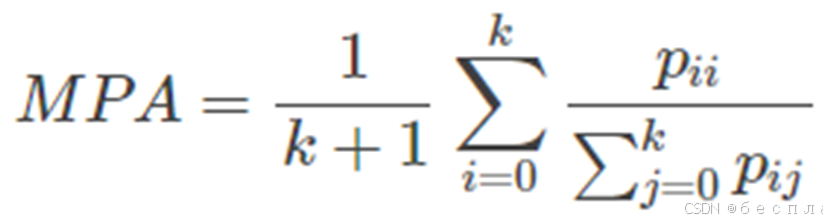
IoU(交并比、Intersection over Union):前景目标交并比。
mIoU(平均交并比、Mean Intersection over Union):每个类的IoU平均值。
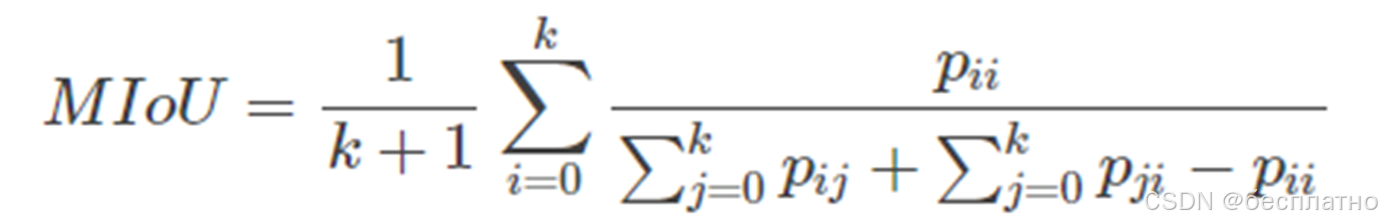
FWIoU(加权交并比、Frequency Weighted Intersection over Union):根据每个类出现的概率给mIoU计算权重。
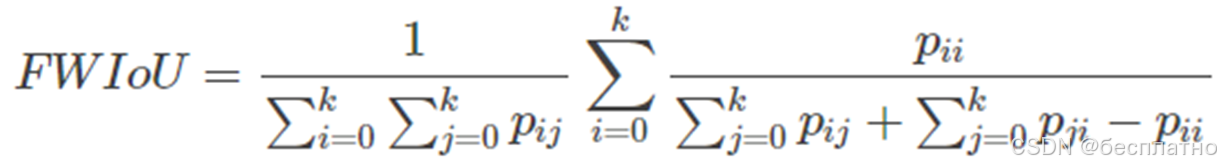
七、图像分割模块
详细参考:一文看尽深度学习中的20种卷积(附源码整理和论文解读) - 知乎
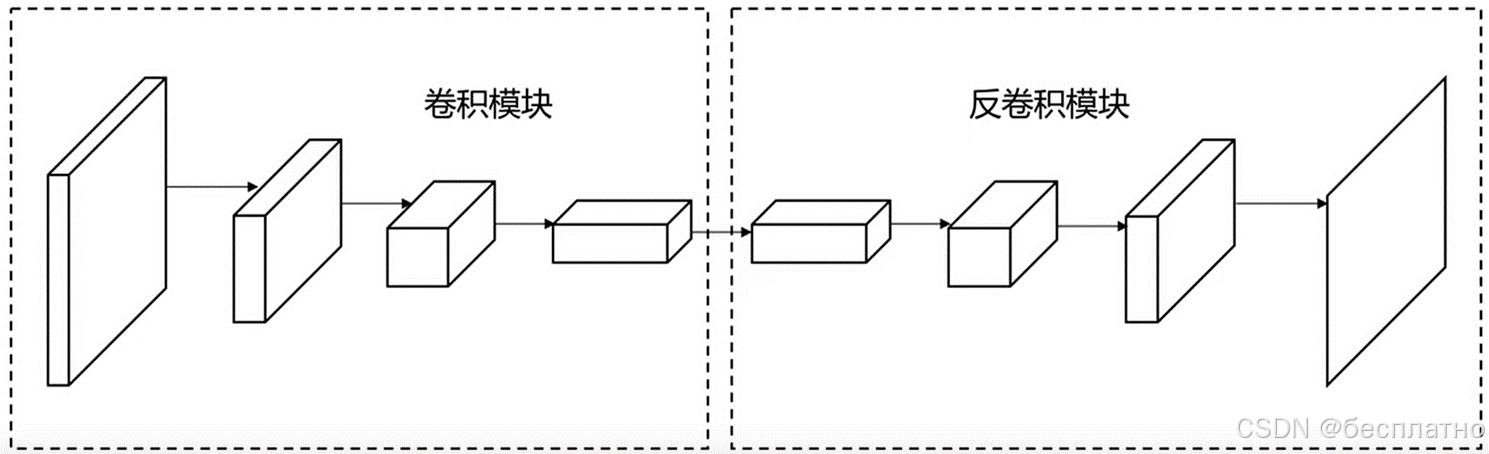
1.卷积模块:提取特征。
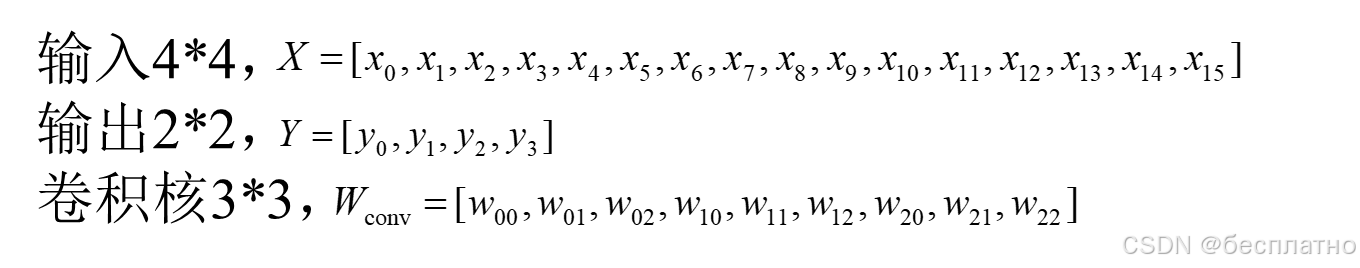
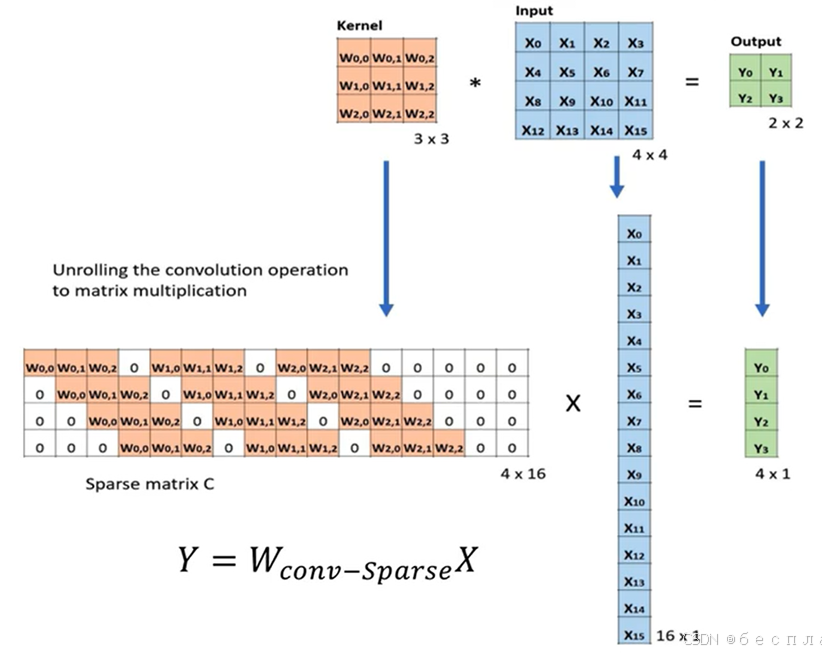
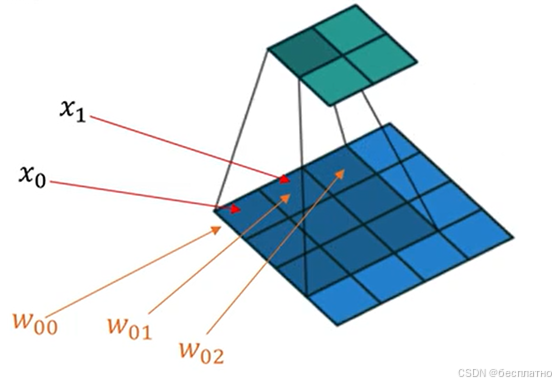
2.反卷积模块:上采样恢复到原图尺度。
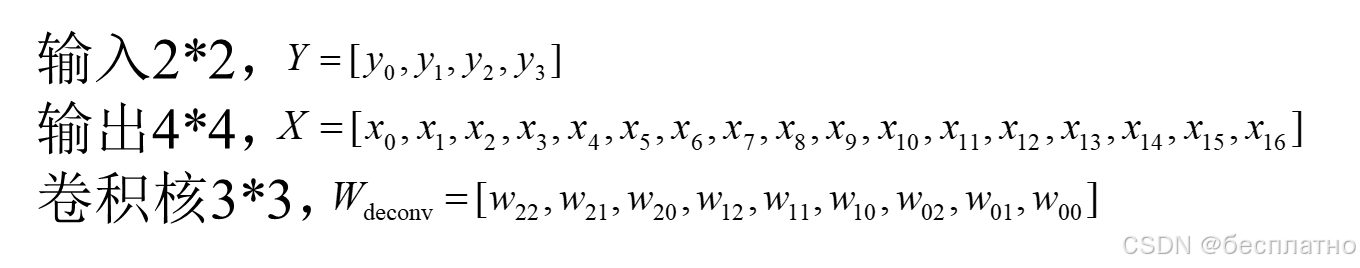
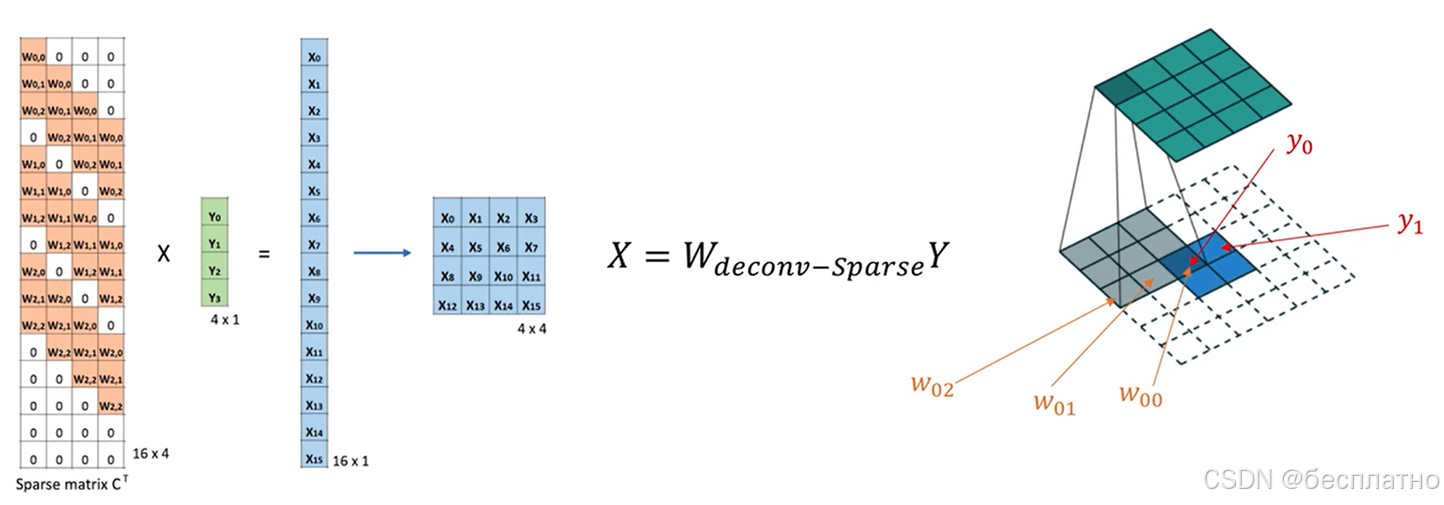
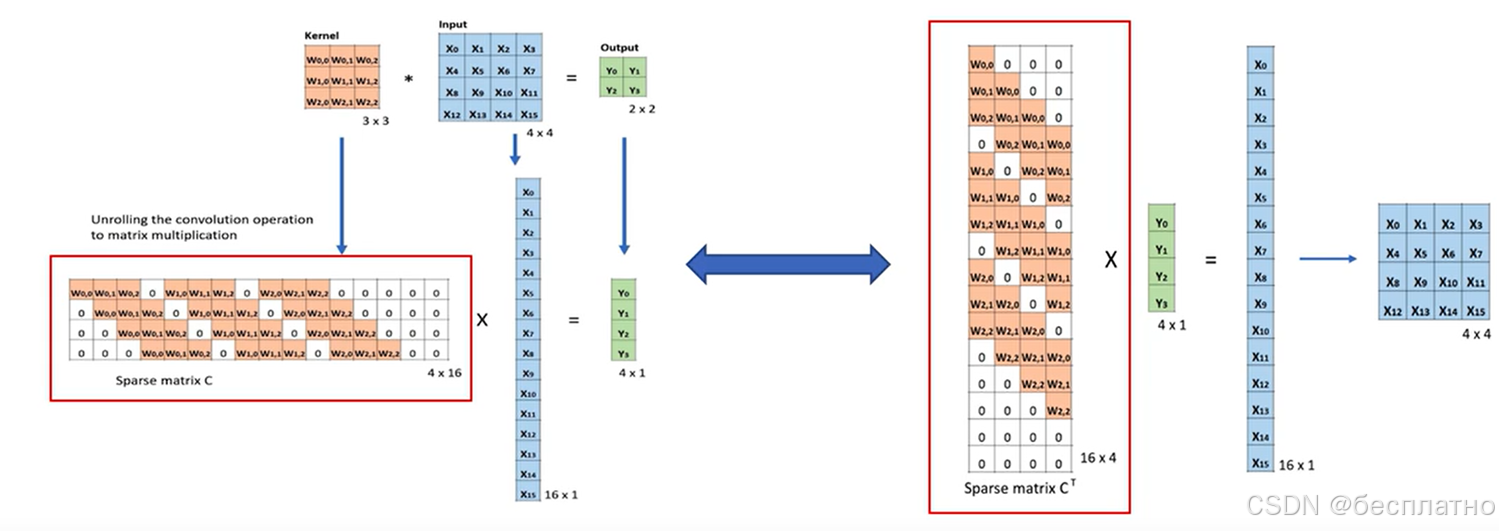
3.卷积与反卷积(转置关系,transposed)
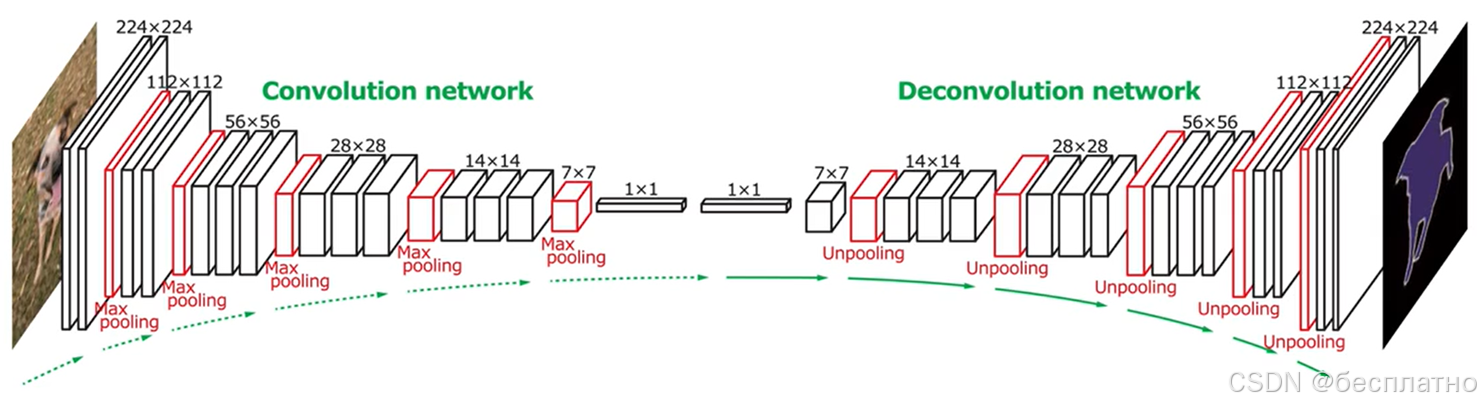
八、典型分割网络
详细参考:分割网络模型(FCN、Unet、Unet++、SegNet、RefineNet)-CSDN博客
卷积网络:编码器
反卷积网络:解码器


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









