






一.误删除相关的数据rm -rf /etc/kubernetes/*,导致集群看不到,好在只是刚部署单节点,在网上查了很多。只能重置

1.重置之前kubeadm reset 要删除相关k8s的数据 记得删除/root/.kube 提示找不到相关的sock文件 因为我部署的里面有docker和contained
Found multiple CRI endpoints on the host. Please define which one do you wish to use by setting the 'criSocket' field in the kubeadm configuration file: unix:///var/run/containerd/containerd.sock, unix:///var/run/cri-dockerd.sock
kubeadm reset --force --cri-socket unix:///var/run/containerd/containerd.sock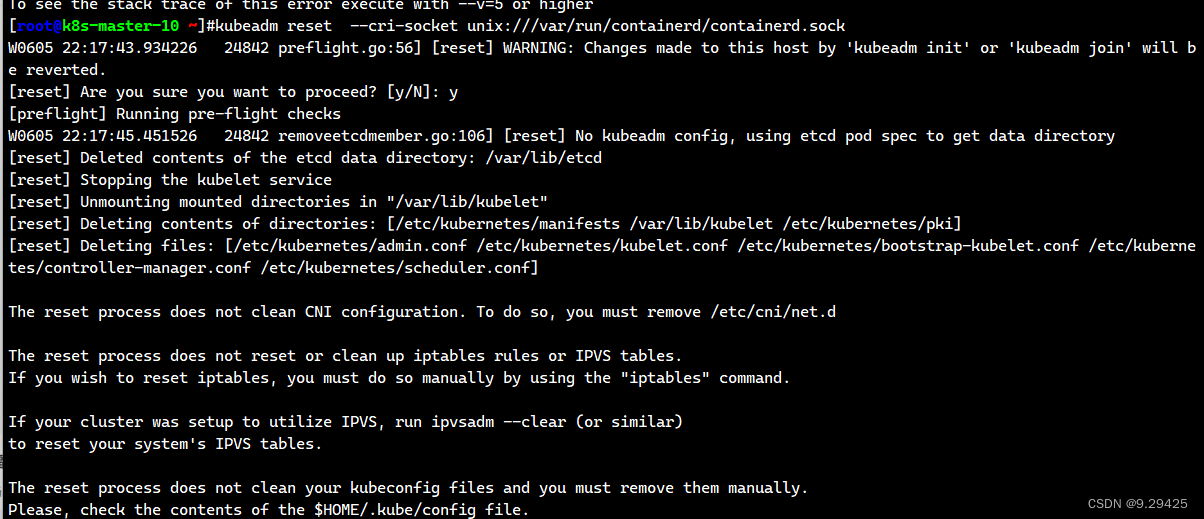
接着重新部署即可
#kubeadm init --config=kubeadm.yaml --ignore-preflight-errors=SystemVerificatio2.node节点加入master一直显示
Found multiple CRI endpoints on the host. Please define which one do you wish to use by setting the 'criSocket' field in the kubeadm configuration file: unix:///var/run/containerd/containerd.sock, unix:///var/run/cri-dockerd.sock
 跟上面一样 是要指定sockert文件
跟上面一样 是要指定sockert文件
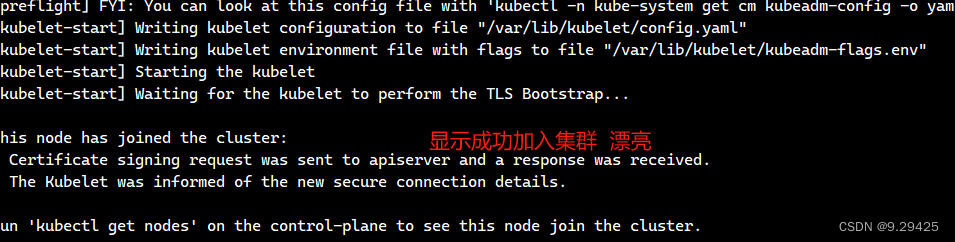
kubeadm join 10.0.0.10:6443 --token dqnemc.cxuwjh6ktssfjnvj --discovery-token-ca-cert-hash sha256:68d5561673eb8c100733afe25fd33b15b29c0470e55494949b9d28c8996c53d5 --ignore-preflight-errors=SystemVerification kubeadm reset --cri-socket unix:///var/run/containerd/containerd.sock3.发现一直 accepts at most 1 arg(s), received 4
To see the stack trace of this error execute with --v=5 or higher 显示报错
有很多可能 比如注意,拷贝命令的时候需要删除换行符 \,否则会报错: 或者中间掺杂了其他的参数 我这个后面才发现是多加了kubeadm reset 还是太粗心了 















 9万+
9万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









