







提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
一、为什么会存在单链表?
前文我们介绍了顺序表,可以知道顺序表并不是完美的,也是有有一些缺陷
比如:
1、顺序表的头插、头删、中间插入、删除元素的操作所花费的时间开销很大,时间复杂度都是O(N^2);
2、动态顺序表尽管已经尽可能的减少空间开销了,但是还是存在一定的空间开销,并不能保证所开辟的空间能够完全被利用;
3、空间增容是有时间消耗的,拷贝数据,释放旧空间。会有不小的消耗;
二、什么是单链表?
单链表逻辑图:

单链表同顺序表一样,都是线性表,除了首尾节点之外,任何一个节点都有自己的前驱和后继;但是单链表每个节点在物理上的地址是不连续的或者说是随机的,也就是说单链表的节点是要一个就开一个,不会过多的开辟空间;这一点正是弥补了顺序表的不足;
三、单链表结构定义
从上面的逻辑图我们就可以看出,每个节点的类型应该是一样的,节点主要分为数据域和指针域,同时对于一串链表来所,最后一个节点的指针域一定是NULL,以此来标记这是链表的结尾;同时我们只需要知道单链表的头节点,就可以很好的管理整个链表;
同时我们给出结点类型: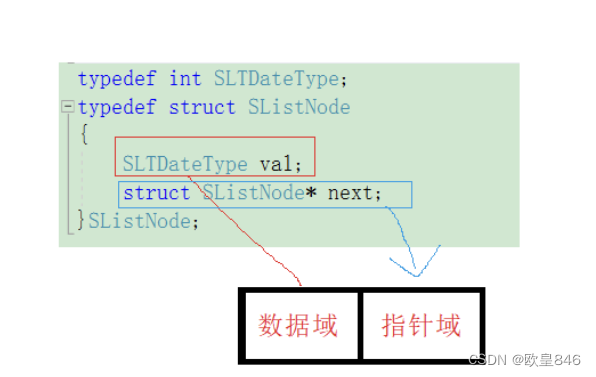
与顺序表一样具备增删查改的基本功能: 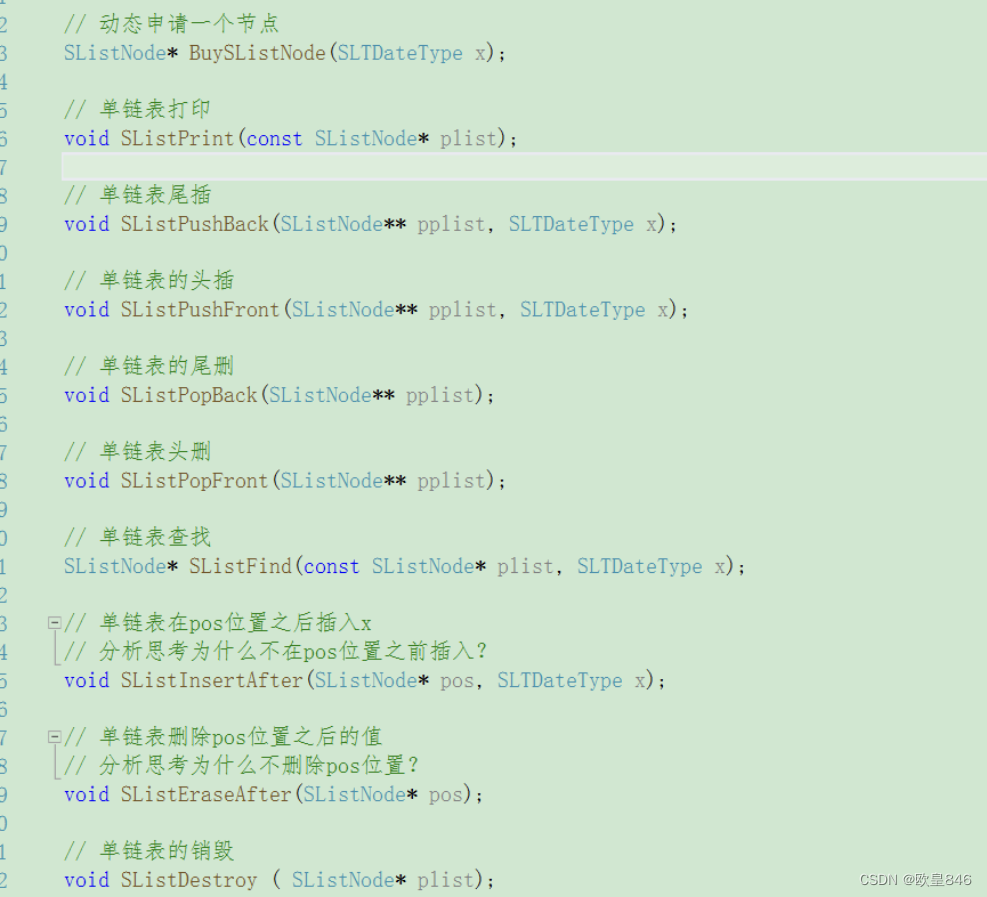
我们先实现一些简单的操作:
1、 创建结点
我们前文说了管理一个链表需要一个头节点的指针就可以了;
为此我们可以专门设置一个SListNode*head=NULL;
来维护我们的单链表,该指针就保存头节点的指针就行了;
当然我们能进行这些操作,我们得先写一个函数来进行创建节点的操作,只有有了节点,我们才能开展后续操作:
// 动态申请一个节点
SListNode* BuySListNode(SLTDateType x)//我们可以将数据在创建节点的时候就存入结点
{
SListNode* tmp = (SListNode*)malloc(sizeof(SListNode));
if (!tmp)//节点开辟失败,程序直接结束
exit(-1);
tmp->val = x;
tmp->next = NULL;
return tmp;
}
2、 销毁链表
我们的节点都是从堆区开辟的,当我们不在使用单链表时,我们应该将单链表销毁(也就是将所开辟的每个节点进行释放,否则容易找出内存泄漏);
思路: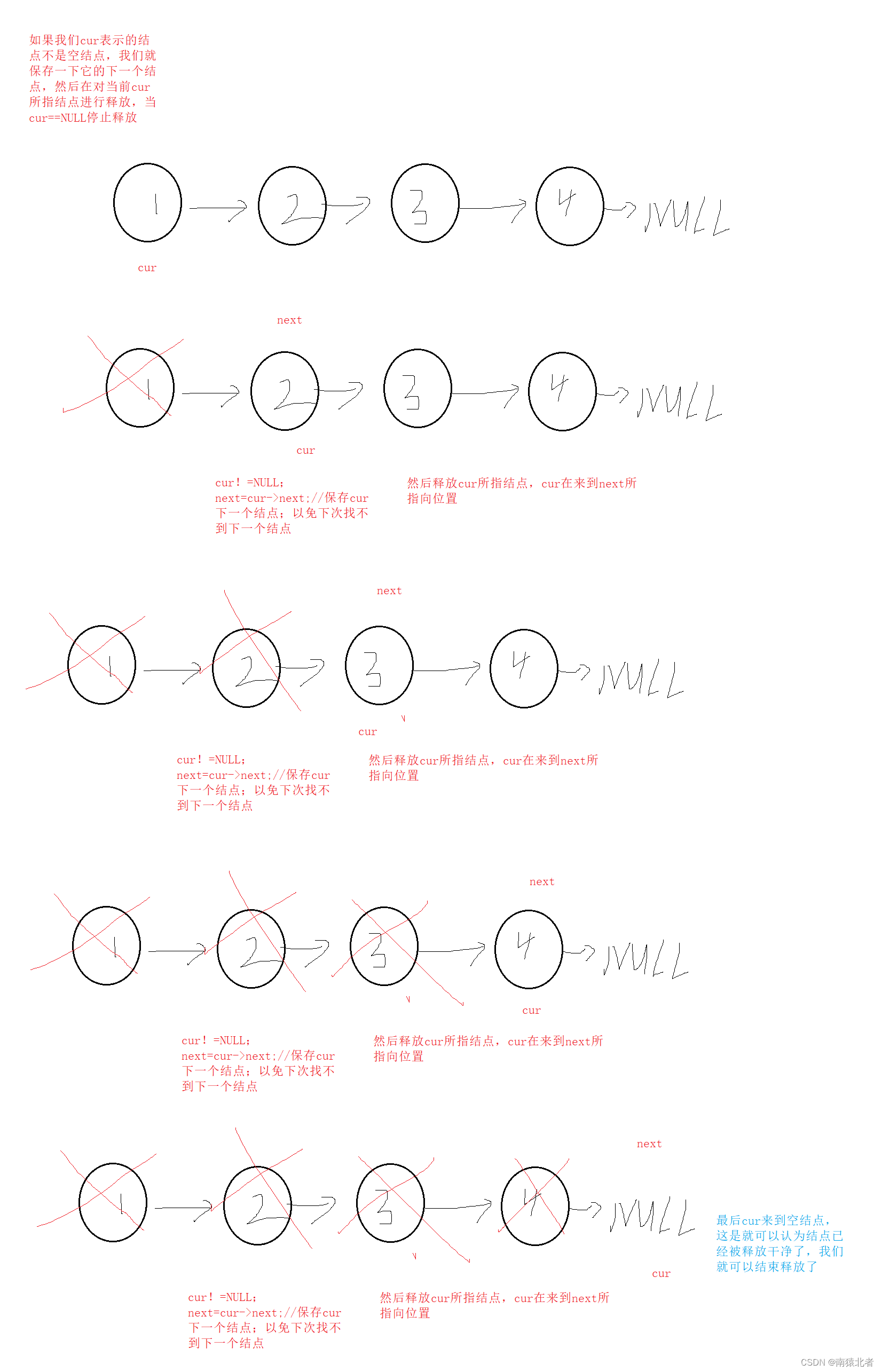
当然我们要考虑一下特殊情况,看看我们的思路能不能解决特殊情况,假设我是个空表,我的逻辑能不呢处理?
表为NULL,按照刚才逻辑,cur==NULL,cur都为NULL不会进入循环,也就是说代码什么也不会左,不会造成对NULL指针释放(对NULL释放也没事),也就是说,我们刚才的逻辑适合,无需对空表特殊处理;
代码实现:
// 单链表的销毁
void SListDestroy(SListNode* plist)
{
SListNode* cur = plist;
SListNode* next = NULL;
while (cur)//空表不会进入循环
{
next = cur->next;
free(cur);
cur = next;
}
}4、 尾插节点
尾插结点故名思意就是在链表的尾部加入一个结点,然后再把链表的结点串起来,得到一个新链表;
当然我们要在尾部插入,就得找到最后一个结点对吧,最后一个结点有什么特点?
是不是最后一个结点的指针域为NULL啊,我们只要找到某个结点的指针域为NULL的就是最后一个结点,按照此思路,我们画图理解:
画图演示: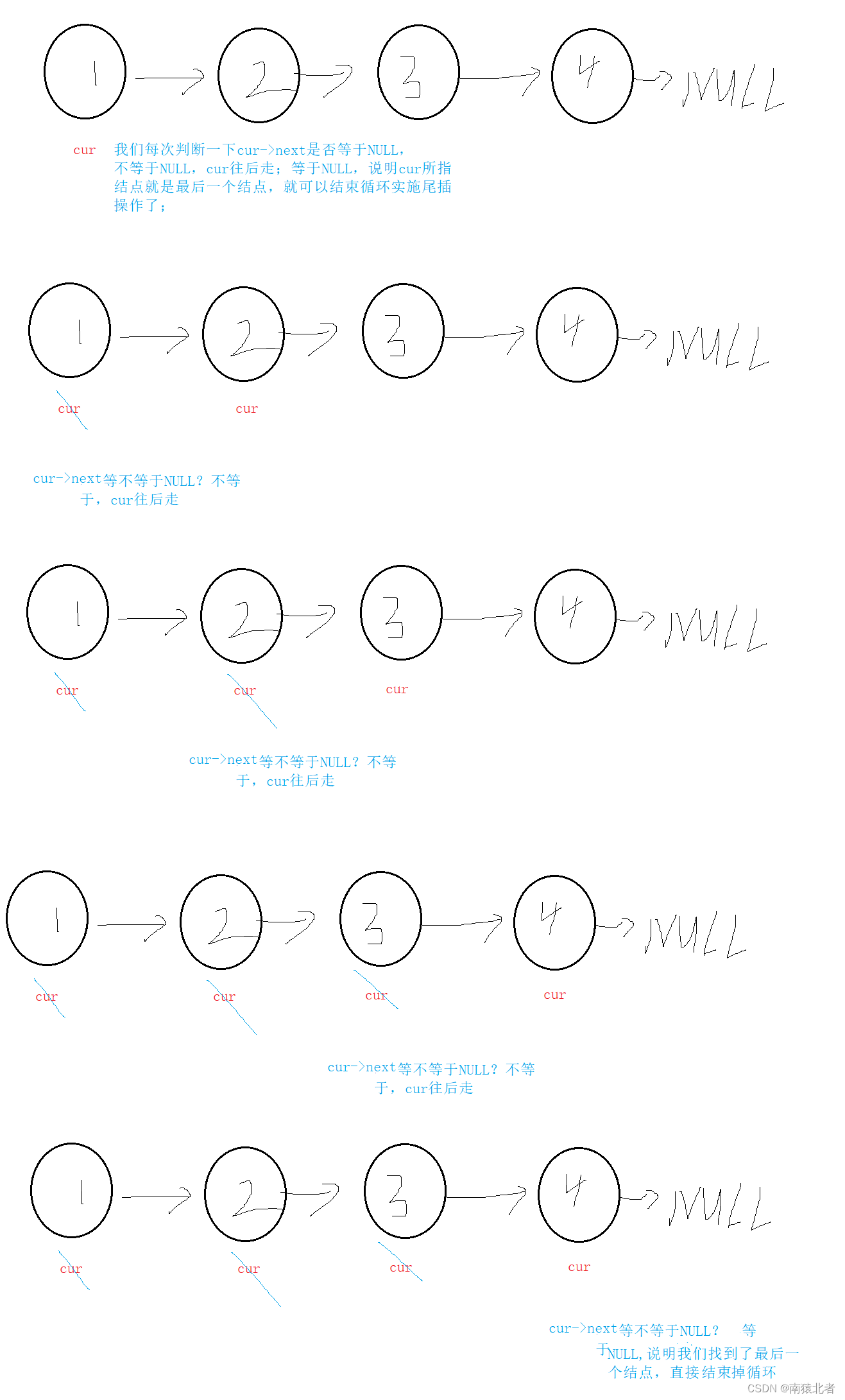
最后我们将开辟好的以初始化好的新节点直接连在最后一个结点末尾即可;
至此我们需要考虑一下特殊情况,假设传过来的是空表?
cur=NULL;
我们在判断cur->next等不等于NULL时会对NULL解引用,会报错,
这是编译器不能容忍的;
因此我们需要对空表这种情况需要单独处理;
为什么参数要设计成二级指针?
当然这两种情况混合在一起的话,我的链表的头指针就会发生变化;我们上面不是说了嘛,我们利用一个SListNode*head=NULL;head变量来维护整个链表,既然我们会该表head变量里面的值,我们是不是就需要传其地址才可以(才可以在另一个作用域,操作head变量里面的内容,可以这么理解head也是一个变量,也是在栈上开辟的,因此也是一块空间,只不过这块空间的名字叫做head,我们现在想在另一个作用域对该作用域下的head进行更改内容的操作,只能传这个空间的地址,只有这样,我们在另一个作用域的改变才能影响到head的取值,这也是为什么函数参数要设计成二级指针的原因),又由于head本身就是一个一级指针变量,我们对一级指针变量取地址,就再次得到一个地址,这个地址叫做二级指针,因此我们在参数设计时,应当串以二级指针;
代码实v
// 单链表尾插
void SListPushBack(SListNode** pplist, SLTDateType x)
{
assert(pplist);//为了避免使用者乱传,先断言一下
SListNode* cur = *pplist;
SListNode* NewNode = BuySListNode(x);
if (cur)//表不为NULL
{
while (cur->next)
{
cur = cur->next;
}
cur->next = NewNode;
}
else//空表
{
*pplist = NewNode;
}
}
5、 头插结点
顾名思义,就是在头部插入结点,因此我们的头指针也会发生改表,为了便于管理,我们参数也应该设计成二级指针;
思路分析:cur表示没插入之前的头节点,NewNode表示新结点,那么只需把新节点的指针域,保存一下上一次的头节点cur,就完成了链表的头部插入,最后在更新一下头节点就完成了;
同时考虑一下NULL表能不能实现?
事实上空表,按照这个逻辑也是OK的(读者可以自行验证)为此我们无需对空表进行特殊处理;
代码实现:
// 单链表的头插
void SListPushFront(SListNode** pplist, SLTDateType x)
{
assert(pplist);
SListNode* cur = *pplist;
SListNode* NewNode = BuySListNode(x);
NewNode->next = cur;
*pplist = NewNode;
}
6、 尾结点的删除
上面讲了头节点的插入和尾结点的插入,接下来我们来讲讲尾结点的删除;
首先先讲解尾结点的删除:
首先想要删除尾结点,我们得首先知道尾结点,其次还得知道尾结点的下一个结点,这个好说,只要找到了尾结点,就找到了尾结点的下一个,关键是我们最后想把链表链接起来就得知道尾结点的上一个结点,为此我们得定义一个prev指针来记录尾结点的前一个结点;
同时cur找尾,cur找尾与尾插思想基本一直,只不过多了一步prev=cur
当然我们能删除结点的前提条件就是表不为NULL,如果表都为空了,那还删个屁,直接给你报错提醒;
所以我们最好断言一下链表是否为空!!!
画图理解: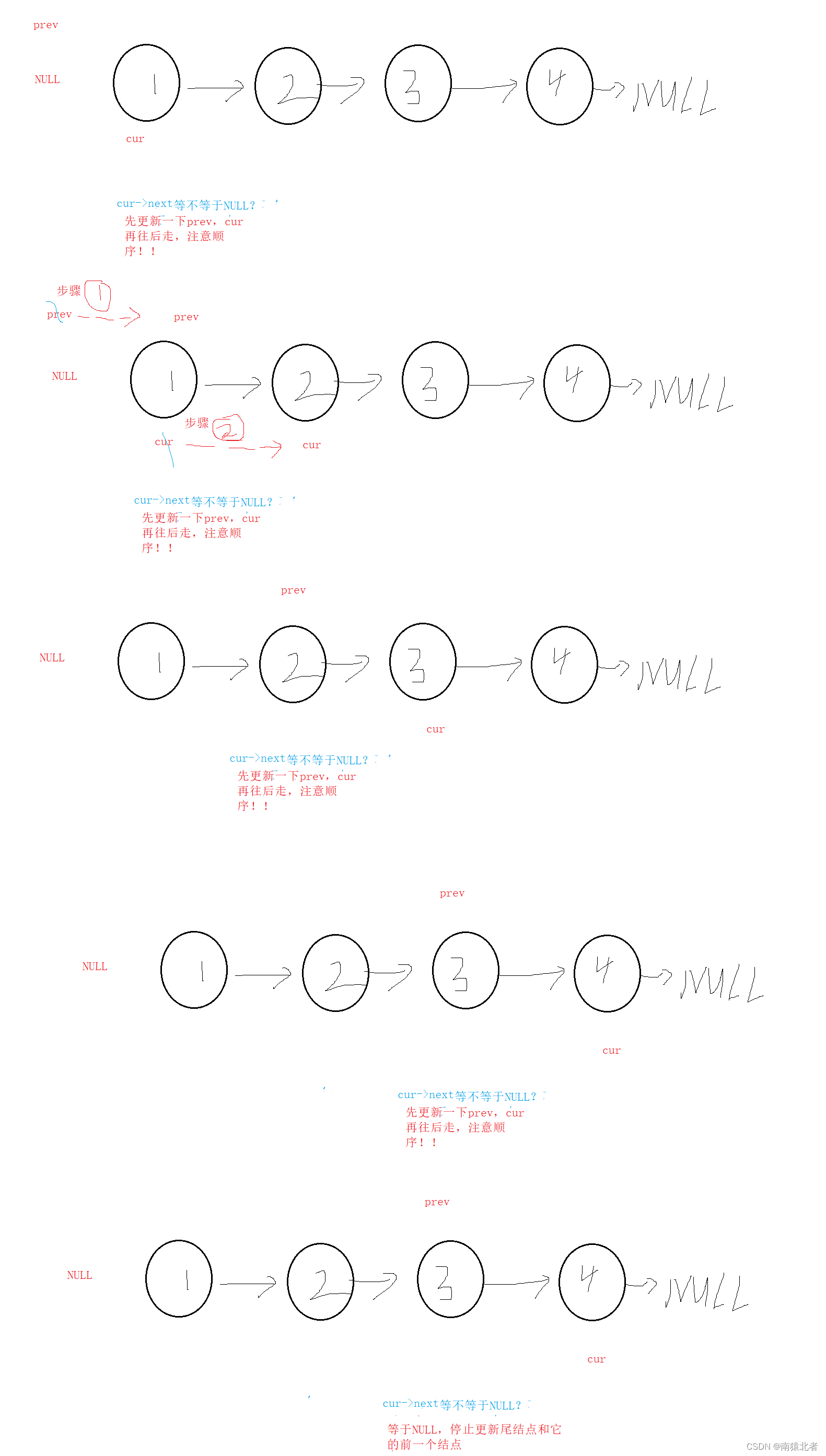
7、 头结点的删除
也就是删除第一个结点,我们的头指针肯定该表,为了便于维护该链表,我们的参数也应该使用二级指针;
当然删除操作的前提条件就是要有的删,对于空表来说,我们删个毛!!
为此我们最好断言一下;
头节点的删除比较简单,我们可以先根据现有的头结点,找到它的下一个结点next,然后再释放掉头节点,就完成了头节点的删除操作,最后再将新的头节点跟新一下,我们不就完美实现了头节点的删除操作!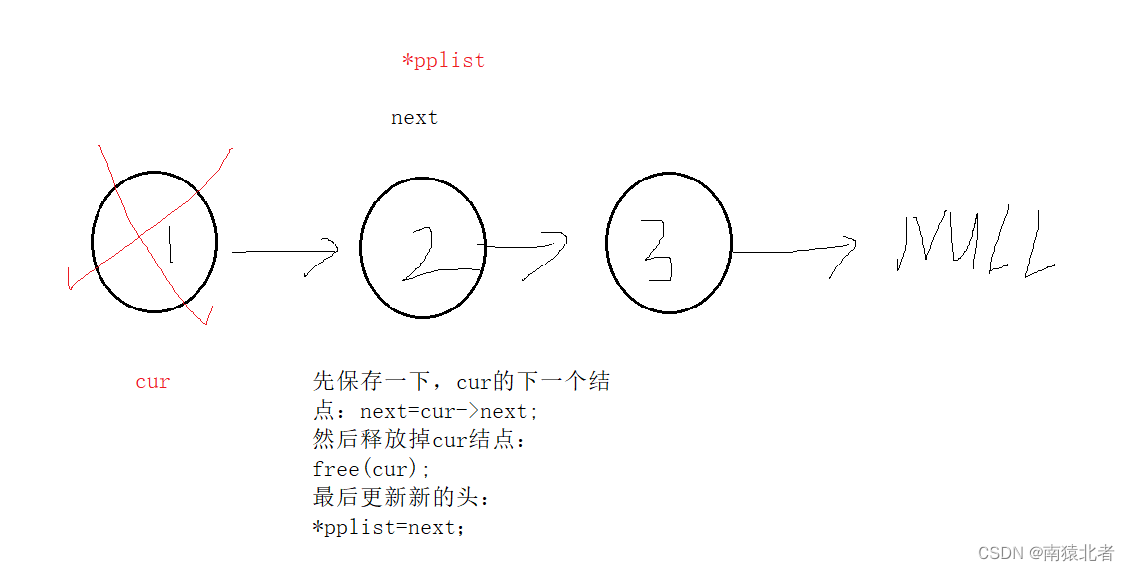















 1万+
1万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









