






首先引入我们需要的库requests和BeautifulSoup,自行安装。
练习网站:Python爬虫案例 | Scrape Center
request
requests库是Python中非常流行且强大的用于处理HTTP请求的库,它可以轻松实现GET、POST等各种HTTP请求方式,以及处理响应内容、cookies、headers等多种网络交互需求。通过requests库,开发者可以便捷地与Web服务器进行数据交互,因此在爬虫开发、API接口调用等场景中极为常用。
BeautifulSoup
BeautifulSoup库主要用于解析HTML和XML文档,它能够将复杂的HTML结构转换成树形结构,方便开发者通过Python代码遍历、查找、修改网页元素。在网页抓取(Web Scraping)任务中,BeautifulSoup常被用来解析requests获取的HTML内容,从中抽取所需的数据信息。
发起请求
以古诗文网为例:推荐名句_古诗文网
import requests
url = 'https://so.gushiwen.cn/mingjus/default.aspx'
ag = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'}
response = requests.get(url,headers = ag)
if response.ok:
# print(response)
# <Response [200]>
print(response.text)
else:
print('请求失败')这里通过响应状态描述来判断是否成功,也可以使用响应状态码判断。
使用requests.get()方法发送GET请求到构建的URL,从服务器接收到的原始HTTP响应体(通常是二进制格式的content),可以通过.text属性转化为Unicode字符串形式(将从服务器接收到的原始HTTP响应体按照HTTP头部中的Content-Type字段所指示的字符编码进行解码,返回解码后的文本字符串,这个字符串通常代表了响应体中的HTML内容)这对于HTML内容来说尤为方便,在爬虫程序中,一旦得到了网页的HTML文本内容,就可以使用像BeautifulSoup这样的库对HTML进行解析,提取需要的数据,如文章内容、图片链接、表格数据等。
打印部分结果如下:
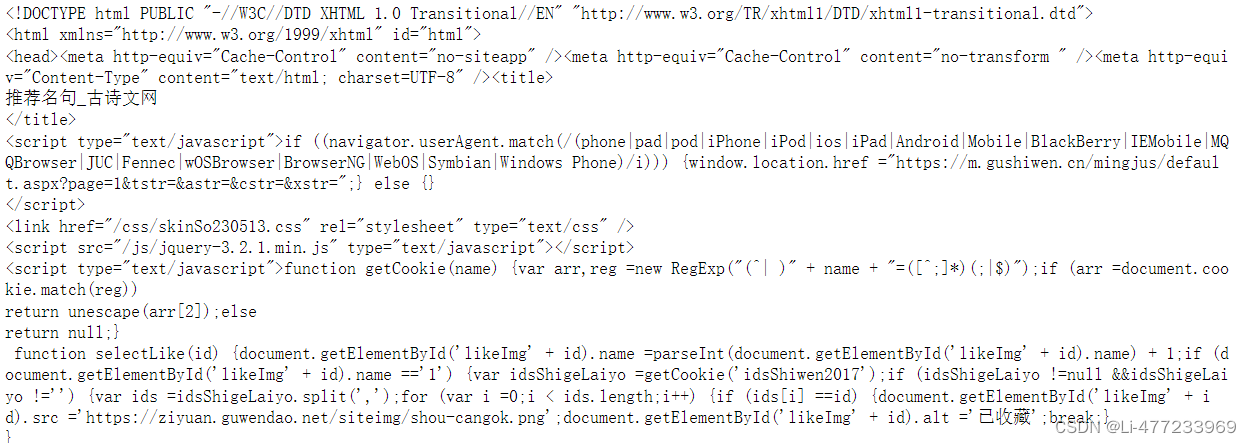
Headers
设置HTTP请求的User-Agent头信息
-
模拟浏览器访问:
许多网站会对来自非浏览器客户端的请求进行检测或限制,特别是对于爬虫活动,它们可能会通过检查请求头中的User-Agent字段来判断请求是否来自于真实的浏览器。如果不提供或者提供的User-Agent不符合常规浏览器的格式,网站有可能会拒绝服务、返回错误信息,或者甚至是封禁IP地址。 -
遵循网络礼仪:
合理地模拟浏览器发送请求,有助于遵守网站的服务条款和robots.txt文件规定,减少对服务器不必要的负担,同时也是尊重网站管理员和服务器资源的一种体现。 -
兼容性与信息完整性:
不同的User-Agent表示不同的浏览器或应用,某些网站可能会根据访问者的User-Agent提供不同的内容或功能。通过模拟主流浏览器的User-Agent,爬虫可以获取与普通用户浏览网页时相同的信息。
解析
import requests
from bs4 import BeautifulSoup
url = 'https://so.gushiwen.cn/mingjus/default.aspx'
ag = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'}
response = requests.get(url,headers = ag).text
"""if response.ok:
# print(response)
# <Response [200]>
print(response.text)
else:
print('请求失败')"""
soup = BeautifulSoup(response,'html.parser')find()
find()方法用于在HTML或XML文档中查找第一个匹配给定条件的标签元素。语法如下:
tag = soup.find(name, attrs, string=None, **kwargs)- name:必需参数,可以是一个字符串,表示要查找的标签名称,比如
'a'表示查找所有<a>标签。也可以是正则表达式,用来匹配标签名。 - attrs:可选参数,是一个字典,用于筛选具有特定属性的标签。例如:
{'class': 'myClass'},这样会查找所有class属性为'myClass'的标签。 - string:可选参数,当需要查找包含特定文本内容的标签时使用,可以是字符串或正则表达式。如果设置了字符串,则查找包含该文本的标签;如果是正则表达式,则查找文本内容匹配该正则表达式的标签。
first_link = soup.find('a')
first_div = soup.find('div', attrs={'class':'maintop'})find_all()
find_all()方法用于查找文档中所有匹配给定条件的标签元素,并以列表形式返回。基本语法类似find():
tags = soup.find_all(name, attrs, string=None, limit=None, **kwargs)- 参数含义同
find()方法,只不过find_all()会返回所有符合条件的标签集合。 - limit:额外的参数,允许指定找到的最大匹配项数量。
all_links = soup.find_all('a')
all_headers = soup.find_all(re.compile("^h[1-3]$")) # 查找所有级别的标题
all_divs_with_class_content = soup.find_all('div', class_='maintop')select()
select()方法是BeautifulSoup结合了CSS选择器的功能,让你能够像在CSS中那样灵活地定位HTML元素。如果你安装了支持CSS选择器的解析器,如lxml。
elements = soup.select(selector)all_paragraphs = soup.select('p') # 找到所有 `<p>` 标签
header_links = soup.select('div a') # 找到所有位于 `<div>` 标签内的 `<a>` 标签
class_b = soup.select('.maintop') # 找到所有 class 包含 'maintop' 的元素
first_items = soup.select('.sright > div') # 找到class为'sright'的元素下的直接子元素'div'实战案例
百度翻译
分析

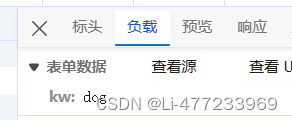
查看响应体
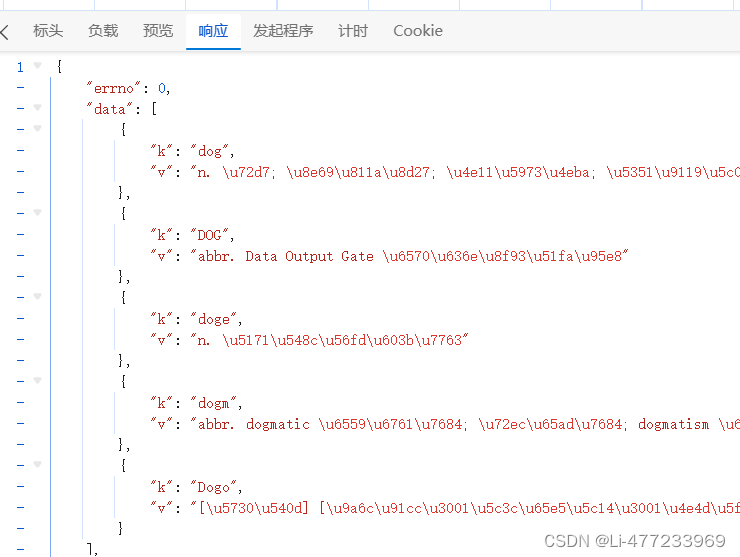
post请求,并且携带参数,返回JSON格式数据。
import requests
import json
url = 'https://fanyi.baidu.com/sug'
word = input('输入一个英语单词:')
data = {
'kw':word
}
ua = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0'}
response = requests.post(url=url,data=data,headers=ua)
# 已经知道是json格式数据
# 获取响应数据 json()方法返回obj
r_obj = response.json()
r_obj此时随着输入单词的不同,会自动给出翻译的相关信息:

古诗文
以古诗网推荐名句_古诗文网 (gushiwen.cn)为例,现在通过爬虫获取诗句,出处,链接。

通过对古诗句网页的分析,可以得出每一页的诗句都位于一个类名为sons的div下,且每一句诗句及其相关信息又分别位于一个个类名为cont的子div标签内。
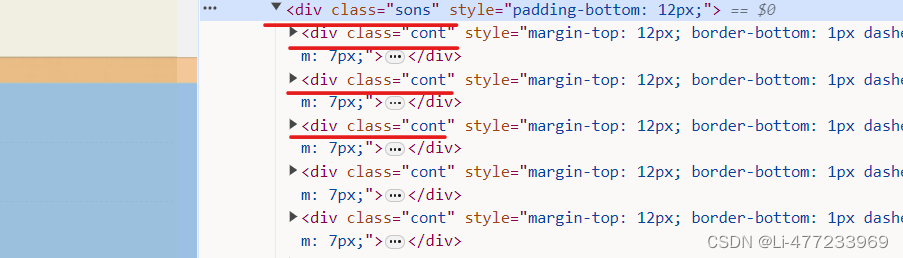
通过页面的转换我们可以得到控制页面的信息为page=页数。

利用一个for循环遍历出每一页,构建古诗网的url,代码如下:
# 循环遍历页码,从1到4
for i in range(1,5):
# 构建古诗网的URL,其中i是页码。
url = "https://so.gushiwen.cn/mingjus/default.aspx?page={0}".format(i)
print(url)得到如下结果:

创建一个poem_list 变量
包含所有匹配到的 <div class="cont"> 元素的对象列表。<div class="cont"> 包含了古诗词的相关信息,爬虫会进一步处理这个列表中的每个元素,以提取具体的诗词内容和其他相关信息。
完整代码如下:
# 用于发起网络请求
import requests
# 用于解析HTML内容
from bs4 import BeautifulSoup as BS
print('------------古诗网-----------')
# 创建一个空列表poems,用于存储抓取到的古诗词信息
poems = []
# 循环遍历页码,从1到4
for i in range(1,5):
# 构建古诗网的URL,其中i是页码。
url = "https://so.gushiwen.cn/mingjus/default.aspx?page={0}".format(i)
# print(url)
# 建一个字典ag,用于设置HTTP请求的User-Agent头信息,以模拟浏览器访问
ag = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'}
# 使用requests.get()方法发送GET请求到构建的URL,并设置headers参数为ag字典
response = requests.get(url,headers=ag)
# print(response)
# 获取请求的响应内容,并将其存储在变量html中
html = response.text
# BeautifulSoup解析html内容
soup = BS(html,'lxml')
poem_list = soup.select('body > div.main3 > div.left > div.sons > div.cont')
# print(poem_list)
# 遍历poem_list中的每个古诗词信息
for i in range(len(poem_list)):
# 获取当前的古诗词信息
PoemObj = poem_list[i]
if len(PoemObj.select("a"))>=2:
sentence = PoemObj.select('a')[0].get_text()
poem = PoemObj.select('a')[1].get_text()
href = PoemObj.select('a')[1].get("href")
poems.append("{0}--出自{1}(https://so.gushiwen.cn{2})".format(sentence,poem,href))
else:
sentence = PoemObj.select('a')[0].get_text() # 文本
poems.append("{0}--没有出处".format(sentence))
for k in poems:
with open(r'poem.txt','a',encoding='utf-8') as f:
f.write(k+'\n')r在此处并不是读取模式的标志,而是表示字符串为原始字符串(raw string literal),在字符串中 \n 被原样保留,不会转义为换行符。由于在Windows系统下,路径中可能会出现反斜杠\,使用原始字符串可以避免转义问题,让\被视为普通字符而非特殊转义字符。这里的文件打开模式是 'a',表示追加模式,即在文件末尾追加内容,而不是覆盖原有的内容。
poem.txt文件内容如下:

写入数据库
古诗网
两种方式创建数据库,可以提前在MySQL中创建好数据库,也可以在Python中创建数据库。
MySQL命令行界面创建数据库代码如下:
CREATE TABLE IF NOT EXISTS poems (
id INT AUTO_INCREMENT PRIMARY KEY,
sentence VARCHAR(255) NOT NULL,
source VARCHAR(255),
url VARCHAR(255)
);Python中创建数据库:
from pymysql import Connection
con = Connection(
host = 'localhost', # 主机名(ip)
port = 3306, # 端口
user = 'root', # 账户
password = '123456' # 密码
)
# 创建一个游标对象
cursor = con.cursor()
# 选择数据库
con.select_db('mq')
# 建表
set_Table = """
CREATE TABLE IF NOT EXISTS poems (
id INT AUTO_INCREMENT PRIMARY KEY,
sentence VARCHAR(255) NOT NULL,
source VARCHAR(255),
url VARCHAR(255)
);
"""
cursor.execute(set_Table)
# 关闭连接
con.close()直接上最终代码:
import requests
from bs4 import BeautifulSoup as BS
from pymysql import Connection
# 数据库连接配置
db_config = {
'host': 'localhost', # 数据库地址
'user': 'root', # 据库用户名
'password': '123456', # 数据库密码
'database': 'mq', # 数据库名
'charset': 'utf8mb4', # 字符集,确保可以存储中文
'cursorclass': pymysql.cursors.DictCursor
}
# 创建数据库连接(此处传参不懂就看看函数传参)
con = Connection(**db_config)
try:
# 管理数据库游标
with con.cursor() as cursor:
poems = []
# 循环遍历页码,从1到4
for i in range(1,5):
# 构建古诗网的URL,其中i是页码。
url = "https://so.gushiwen.cn/mingjus/default.aspx?page={0}".format(i)
# print(url)
# 建一个字典ag,用于设置HTTP请求的User-Agent头信息,以模拟浏览器访问
ag = {'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/106.0.0.0 Safari/537.36'}
# 使用requests.get()方法发送GET请求到构建的URL,并设置headers参数为ag字典
response = requests.get(url,headers=ag)
# print(response)
# 获取请求的响应内容,并将其存储在变量html中
html = response.text
# BeautifulSoup解析html内容
soup = BS(html,'lxml')
poem_list = soup.select('body > div.main3 > div.left > div.sons > div.cont')
# 遍历poem_list中的每个古诗词信息
for i in range(len(poem_list)):
PoemObj = poem_list[i]
if len(PoemObj.select("a")) >= 2:
sentence = PoemObj.select('a')[0].get_text() # 文本
poem = PoemObj.select('a')[1].get_text() # 出处
href = PoemObj.select('a')[1].get("href") # 链接
source = poem
url = "https://so.gushiwen.cn" + href
# 插入数据库
sql = "INSERT INTO poems (sentence, source, url) VALUES (%s, %s, %s)"
cursor.execute(sql, (sentence, source, url))
else:
sentence = PoemObj.select('a')[0].get_text() # 文本
source = None
url = None
# 插入数据库
sql = "INSERT INTO poems (sentence, source) VALUES (%s, %s)"
cursor.execute(sql, (sentence, source))
# 提交事务
con.commit()
finally:
con.close()数据库内容如下
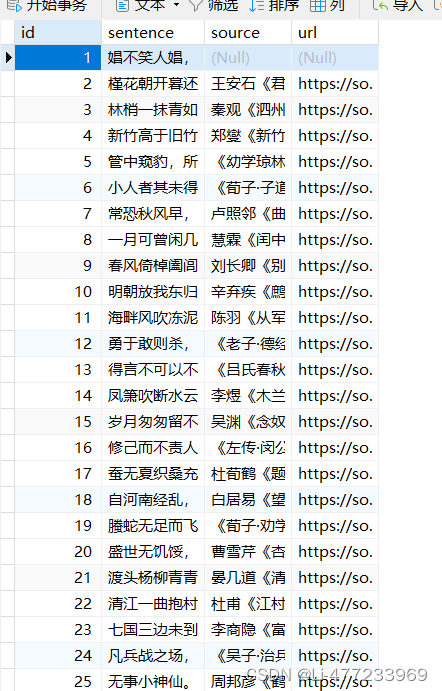
电影top250
import requests
from bs4 import BeautifulSoup
from pymysql import connect
con = connect(host='localhost', # 主机名(ip)
port=3306, # 端口
user='root', # 账户
password='123456', # 密码
autocommit=True,
database='mq')
try:
# 管理数据库游标
with con.cursor() as cursor:
# 初始化一个列表来存储电影信息
movies = []
# 遍历电影排名页面
for i in range(0, 10):
url = "https://movie.douban.com/top250?start={0}".format(i * 25)
# print(url) # 对应页面的url
# continue;
# 谷歌浏览器
ag = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/122.0.0.0 Safari/537.36'}
# 返回响应体
resopnse = requests.get(url, headers=ag)
# print(resopnse)
# continue
# 页面html
html = resopnse.text
# print(html)
# continue
# 将复杂的HTML文档转换成一个复杂的树形结构
soup = BeautifulSoup(html, 'lxml')
# print(soup)
# continue
# 中名片名 排名 评分 链接 ------列表
movie_list = soup.select('#content > div > div.article > ol > li')
# print(movie_list)
# continue
for movie in range(len(movie_list)):
# 电影对象
FilmObj = movie_list[movie]
# 获取电影排名
rank = FilmObj.find('em').text
# 获取电影标题
title = FilmObj.find('span', class_='title').text
# 获取电影链接
link = FilmObj.find('a')['href']
# 获取电影评分
rating = FilmObj.find('span', class_='rating_num').text
# 插入数据库
sql = "INSERT INTO films (title, rating, url) VALUES (%s, %s, %s)"
cursor.execute(sql, (title, rating, link))
finally:
con.close()
建表
CREATE TABLE IF NOT EXISTS films ( `rank` INT AUTO_INCREMENT PRIMARY KEY, `title` VARCHAR(255) NOT NULL, `rating` FLOAT, `url` VARCHAR(255) );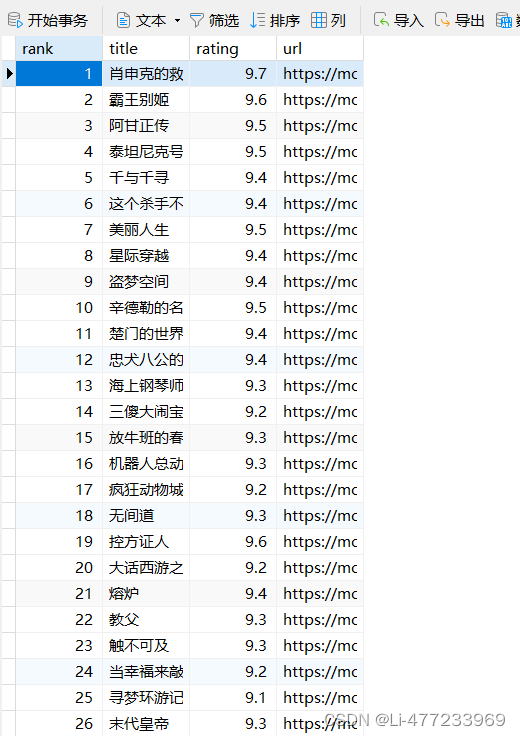
Xpath
XPath 是一种专门用于查询和定位 XML (eXtensible Markup Language) 文档中元素、属性及其他节点的语言。它提供了一种简洁且强大的路径表达式语法,使得用户能够准确地描述并访问XML数据结构中的特定部分。
解析原理
实例化一个etree对象,将需要被解析的页面源码数据加载到etree对象,调用该对象中的xpath()方法结合xpath表达式实现标签的定位和内容捕获。(将 XML 或 HTML 文档转化为节点树,通过编写和执行 XPath 表达式在节点树中进行路径导航和条件筛选,最终返回符合要求的节点集合,以便从中提取所需数据)
安装lxml
pip install lxmlfrom lxml import etree实例化etree对象
(一)本地html源码数据加载到xtree对象中
etree.parse(filepath)(二)网页源码数据加载到etree对象中
etree.HTML('html_text')案例实操
读书网世界名著书名
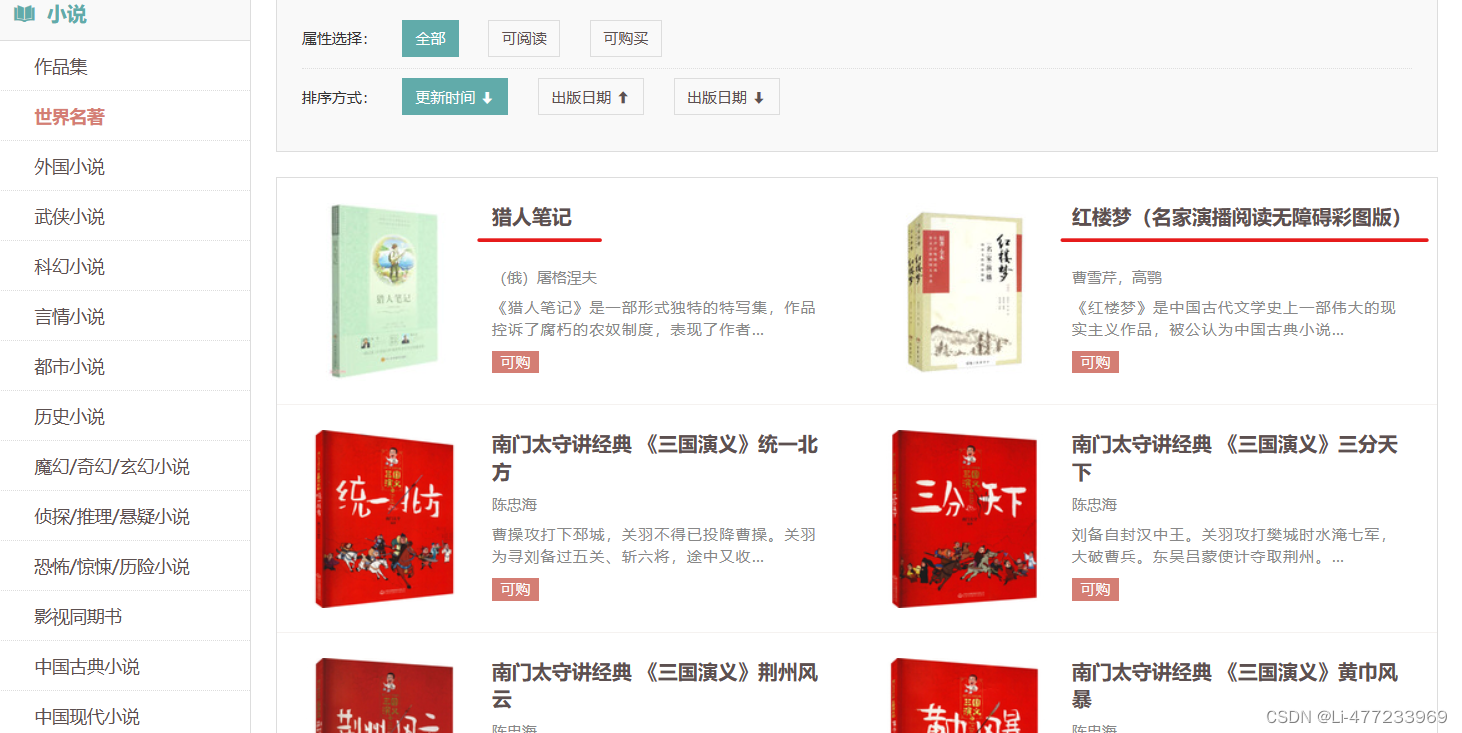
可以发现每本书为于一个li标签内:
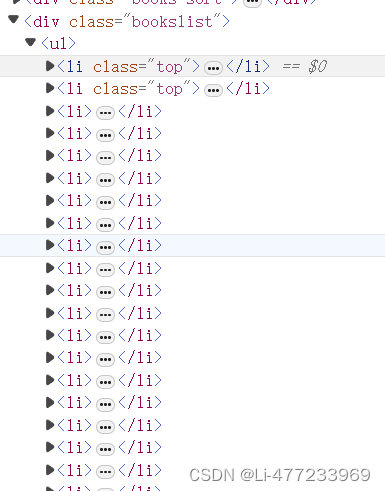
书名位于h3下的a标签内

import requests
from lxml import etree
for i in range(1,101):
url = 'https://www.dushu.com/book/1175_{0}.html'.format(i)
ua = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0'}
response = requests.get(url=url, headers=ua).text
tree = etree.HTML(response)
# 得到每本书
book_list = tree.xpath('//div[@class="bookslist"]/ul/li')
for li in book_list:
title = li.xpath('./div/h3/a/text()')[0]
print(title)结果如下:

彼岸图网
4K动漫壁纸_高清4K动漫图片大全_彼岸图网 (netbian.com)
import requests
from lxml import etree
url = 'https://pic.netbian.com/4kdongman/'
ua = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0'}
response = requests.get(url=url, headers=ua).text
# 乱码 .encoding = ('utf-8')
tree = etree.HTML(response)
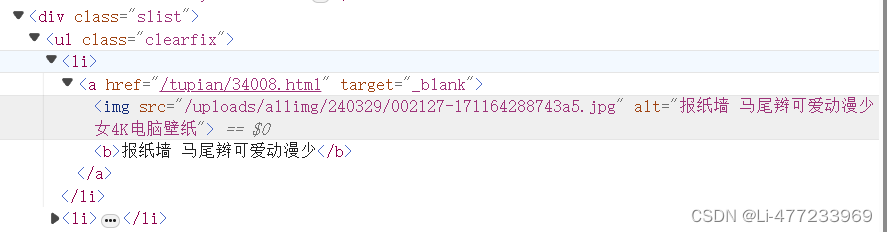
picture_list = tree.xpath('//div[@class="slist"]/ul/li')
for li in picture_list:
img_src = 'https://pic.netbian.com'+li.xpath('./a/img/@src')[0]
img_name = li.xpath('./a/img/@alt')[0]+'.jpg'
# 处理乱码
img_name = img_name.encode('iso-8859-1').decode('gbk')
print(img_src,img_name)全国城市名
PM2.5历史数据_空气质量指数历史数据_中国空气质量在线监测分析平台历史数据 (aqistudy.cn)
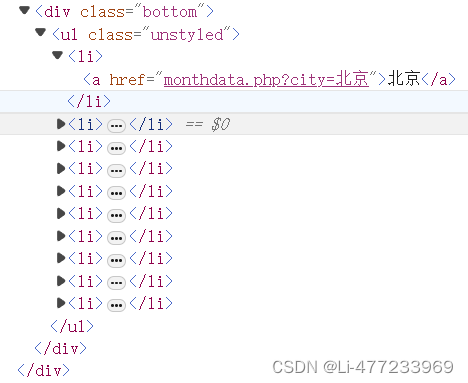
热门城市
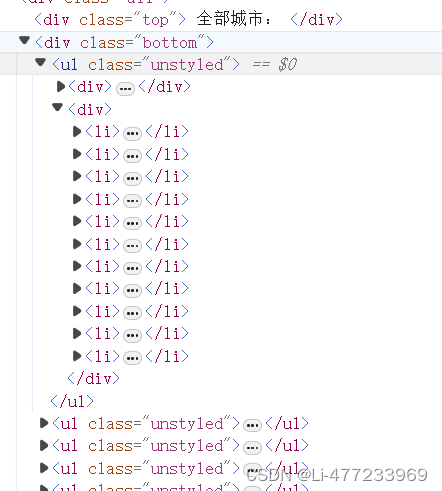
全部城市
分开爬热门和全部
import requests
from lxml import etree
# 存放城市
citys = []
url = 'https://www.aqistudy.cn/historydata/'
ua = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0'}
response = requests.get(url=url, headers=ua).text
tree = etree.HTML(response)
# 热门城市
hot_city_list = tree.xpath('//div[@class="bottom"]/ul/li')
for li in hot_city_list:
hot_city = li.xpath('./a/text()')[0]
citys.append(hot_city)
# 全部城市
all_city = tree.xpath('//div[@class="bottom"]/ul/div[2]/li')
for li in all_city:
city = li.xpath('./a/text()')[0]
citys.append(city)
print(citys)合并
import requests
from lxml import etree
citys = []
url = 'https://www.aqistudy.cn/historydata/'
ua = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/123.0.0.0 Safari/537.36 Edg/123.0.0.0'}
response = requests.get(url=url, headers=ua).text
tree = etree.HTML(response)
a_list = tree.xpath('//div[@class="bottom"]/ul/li/a | //div[@class="bottom"]/ul/div[2]/li/a')
for a in a_list:
city = a.xpath('./text()')[0]
citys.append(city)
# 打印城市
print(citys)如果想获得全国所有城市,且不要重复,直接将下面代码删即可。
# 热门城市
hot_city_list = tree.xpath('//div[@class="bottom"]/ul/li')
for li in hot_city_list:
hot_city = li.xpath('./a/text()')[0]
citys.append(hot_city)















 395
395











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









