






简介
正则表达式(Regular Expression,简称regex或regexp) 是一种强大的文本处理工具,主要用于字符串的模式匹配(包括查找、替换等操作)以及从字符串中提取信息。正则表达式使用一种特殊的语法,可以用来检查一个字符串是否含有某种子串、将匹配的子串替换或者从某个字符串中取出符合某个条件的子串等。
正则表达式的常见应用场景包括:
- 数据验证:验证用户输入的数据是否符合预期的格式,例如检查电子邮件地址、电话号码、密码等是否有效。
- 文本搜索:在大量文本中查找符合特定模式的字符串,例如搜索网页中的特定链接或代码。
- 文本替换:将文本中符合特定模式的字符串替换为其他字符串,例如将文本中的日期格式统一化。
- 数据提取:从文本中提取符合特定模式的数据,例如从网页中抓取数据或解析日志文件。
正则表达式的语法非常丰富,包括字符类、预定义字符类、数量词、边界匹配符、选择/分组和反向引用等。通过组合这些元素,可以构建出各种复杂的匹配模式。
正则表达式练习网站:RegExr: Learn, Build, & Test RegEx
打开后的网站如下:
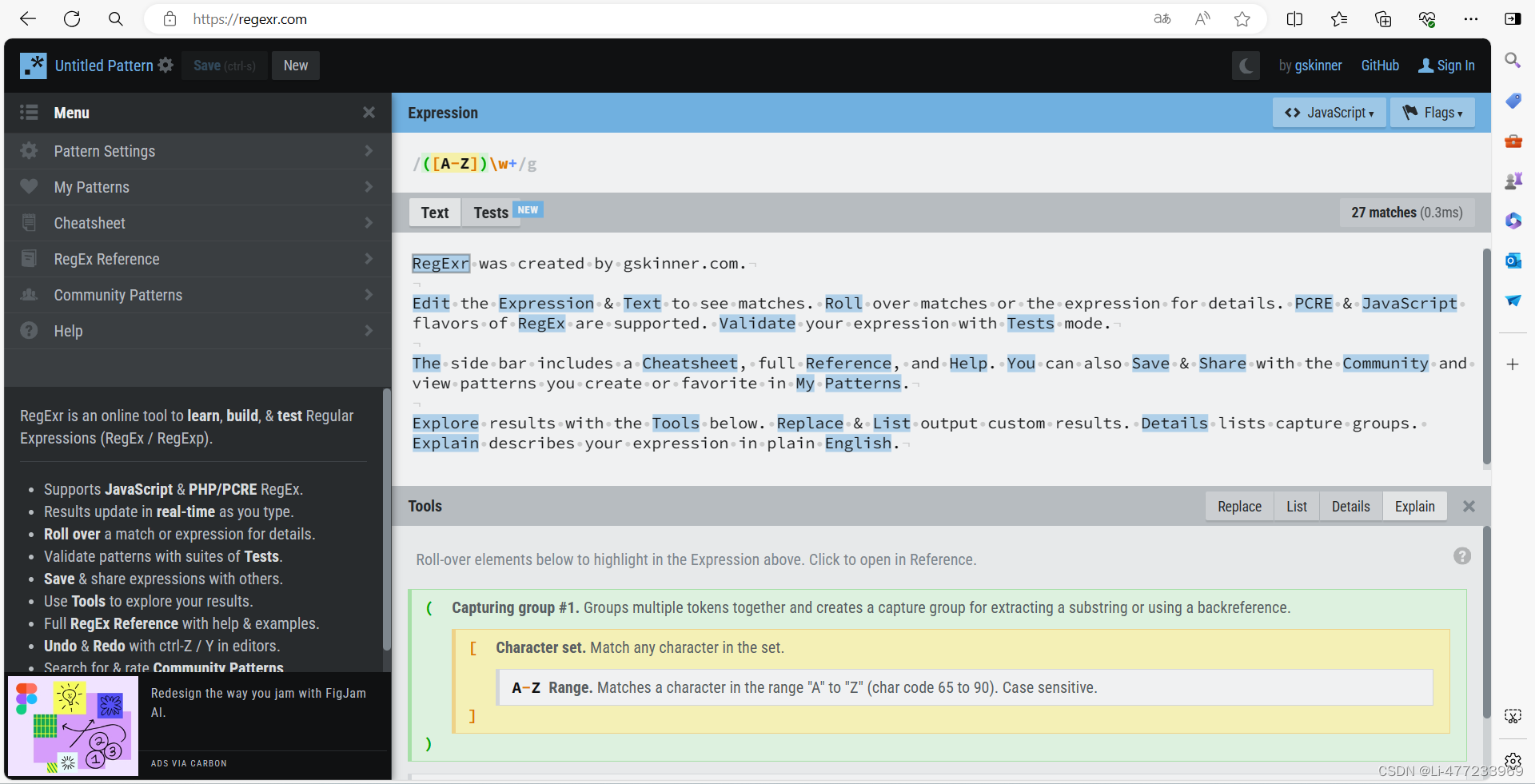
/th/g基础匹配
-
/:正则表达式的开始和结束界定符。它标志着一个正则表达式的起始和结束。 -
th:这是正则表达式中的一个模式,表示匹配字符串"th"。换句话说,它会查找文本中所有"t"后面跟着"h"的实例。 -
g:这是一个修饰符(flag),代表"global",意为全局搜索。这意味着正则表达式会尝试在目标字符串中找到所有匹配"th"的位置,而不仅仅停止在第一个匹配处。
/th./g.:点符号代表匹配任意单个字符(除了换行符)
匹配以"th"跟随任意一个字符的模式,且进行全局搜索。例如,它会匹配"the"、"tho"、"th1"等字符串。
/.th/g表示寻找任何字符后紧跟着"th"的模式,并进行全局搜索。例如,这将匹配"a.th"、"1th"、";th"等,只要是任意字符后紧跟"th"的情况都会被匹配到。
/t.h/g表示匹配以 "t" 开头,紧跟任何单个字符,然后是 "h" 的字符串。例如,它会匹配 "th", "tah", "t6h"。
/t[th]/g[]: 定义一个字符集,即匹配方括号中列出的任何一个字符
匹配的是以 "t" 开始,后面紧跟着要么是 "t" 要么是 "h" 的字符串。因此,它能匹配 "tt" 和 "th"。
/t[a-z]/g[a-z]: 一个字符集,表示小写字母 a 到 z 中的任意一个字符。这意味着它会匹配从 'a' 到 'z' 范围内的任何小写字母。
全局地查找所有以字母 "t" 开头,后面紧接着任何一个小写字母的子串。例如,它会匹配 "ta", "tb", ..., "tz" 等字符串。
/t[a-zA-Z]/g[a-zA-Z]: 一个字符集,它匹配任何大小写字母。范围从 'a' 到 'z' 包含所有小写字母,从 'A' 到 'Z' 包含所有大写字母。这意味着这个部分可以匹配任何英文字母。
全局查找所有以字母 "t" 开头,后面紧接着任何英文字母(不分大小写)的子串。例如,它会匹配 "ta", "tb", ..., "tz", "TA", "TB", ..., "TZ" 等字符串。
/t[a-zA-Z0-9]/g[a-zA-Z0-9]: 一个字符集,它匹配任何英文大小写字母(a-z 和 A-Z)或数字(0-9)。这意味着这部分可以匹配任何英文字母或数字。
全局查找所有以字母 "t" 开头,后面紧接着任何英文字母(大写或小写)或数字的子串。例如,它会匹配 "t1", "ta", "tZ", "t9" 等字符串。
/t[^a-z]/g[^a-z]: 负向字符集,匹配不在指定范围内的任何字符。这里表示匹配任何非小写字母 a 到 z 的字符。换句话说,这会匹配任何非小写字母的字符,包括大写字母、数字、符号、空格等。
全局查找所有以 "t" 开头,后面跟着不是小写字母的任何字符的子串。例如,它会匹配 "t1", "tA", "t!", "t "(空格)等字符串,但不会匹配 "ta", "tb", "tz" 等包含小写字母的序列。
/th\d/g\d: 是一个特殊字符,表示匹配任何数字(等同于 [0-9]),这里的数字可以是 0 到 9 中的任意一个。
全局查找所有以 "th" 开头,后面紧跟一个数字的子串。例如,它会匹配 "th1", "th2", ..., "th9" 等字符串。
/th\D/g\D: 是一个特殊字符,与 \d 相对,表示匹配任何非数字字符。这意味着它会匹配除数字(0-9)之外的任何字符,包括字母、符号、空格等。
全局查找所有以 "th" 开头,后面跟着非数字字符的子串。例如,它会匹配 "thA", "th#", "th ", "th-" 等字符串,但不会匹配像 "th1", "th2" 这样后面跟着数字的序列。
/th\w/g\w 是一个特殊字符,代表匹配任何单词字符,包括字母(a-z,A-Z)、数字(0-9)以及下划线(_)。
全局查找所有以 "th" 开头,后面跟着任何单词字符(字母、数字或下划线)的子串。例如,它会匹配 "th1", "thA", "th_", "thword" 等字符串。
/th\W/g\W(大写的 W)是 \w 的反向匹配,表示匹配任何非单词字符,即除字母、数字和下划线以外的任何字符,包括空格、标点符号等。
全局查找所有以 "th" 开头,后面跟着任何非单词字符的子串。例如,它会匹配 "th ", "th.", "th#" 等字符串。
/th\s/g\s: 特殊字符,匹配任何空白字符,比如空格、制表符、换页符等。
全局查找所有以 "th" 开头,后面跟着任何空白字符的子串。例如,在文本中,它会匹配 "the cat" 中的 "th "("th"后的空格),"therefore" 前的空格(如果之前有"th"的话),以及其他所有符合该模式的实例。
/th\S/g\S: 特殊字符,与 \s 相对,匹配任何非空白字符。这意味着它会匹配除了空格、制表符、换页符等空白字符之外的任何字符,包括字母、数字、符号等。
全局查找所有以 "th" 开头,后面跟着任何非空白字符的子串。例如,它会匹配 "th1", "th!", "thWord" 等字符串中的 "th" 后紧跟的非空白字符部分。
边界匹配
在正则表达式中,边界匹配通常指的是确定一个字符串或字符模式的开始或结束位置。在正则表达式中,\b 是一个常用的元字符,用于匹配单词边界。例如,\bcat\b 只会匹配单词 "cat",而不会匹配到 "concatenate" 中的 "cat"。
/^a/g^: 表示字符串的开始位置。
全局查找所有以 "a" 开头的字符串或字符串中的行(但因为没有多行模式,所以实际上只会在字符串的最开始处匹配)。
/^a/gm^: 在多行模式 (m) 下,这个符号不仅匹配字符串的开始,还匹配每一行的开始(即每个换行符 \n 之后)。
/m: 多行模式修改符,改变了 ^ 和 $ 的行为,使其能够分别匹配每行的开始和结束。
全局范围内查找每一行以 "a" 开头的情况。也就是说,如果文本由多行组成,且每行都是以 "a" 开始,这个正则表达式就会在每一行的开头匹配到 "a"。
/.$/gm.:这是一个特殊字符,通常情况下匹配除了换行符之外的任何单个字符。
$:在多行模式(m)下,这个符号匹配每一行的结束位置,即行尾。如果没有多行模式,它仅匹配整个字符串的结束。
全局范围内,对于每一行,匹配每行的最后一个字符(除了换行符本身,因为换行符不被.匹配)。这在处理文本文件或多行字符串时特别有用,如果想要找出每行的最后一个字符是什么,这个正则表达式就能派上用场。
/\.$/gm\.:这里.被反斜杠\转义了,因此它不再是特殊字符,而是字面上的点(.)字符。
$: 在多行模式(m)下,这个符号匹配每一行的结束位置。
全局查找并匹配每一行中以字面意义上的点(.)字符结尾的情况。这意味着,如果文本中有行以句点结束(不包括行尾可能有的空格或其他字符),这个正则表达式就会匹配到那些行的句点。
/^th$/gm^: 表示行的开始位置。由于启用了多行模式(m),这个符号会在每一行的开头进行匹配。
th: 匹配字符串 "th"。
$: 表示行的结束位置。同样因为在多行模式下,它会在每一行的结束处匹配。
全局查找所有单独由 "th" 组成的行,即每一行只有 "th" 而无其他任何字符。如果一行中除了 "th" 还有空格或其它字符,哪怕是一个空格,这条正则表达式都不会匹配该行。
/\bth/gm\b: 单词边界,这个特殊字符匹配一个单词的边界位置,即它前面和后面分别是非单词字符和单词
全局查找并匹配所有位于单词边界之后的 "th",不论这些单词边界出现在单行内还是多行文本中。这意味着,它会匹配像 "the"、"thy"、"thematics" 中的 "th",但不会匹配 "bath" 或 "author" 中的 "th",因为后者不在单词的边界上。
/th\b/gm全局查找所有以 "th" 结尾且 "th" 后紧接单词边界的实例,这适用于多行文本。例如,它会匹配 "math" 中的 "th" 但不会匹配 "uthor" 中的 "th",因为后者不是单词的结束。在多行上下文中,如果某行以 "th" 结束(后面跟着换行符或文本结束),这个正则表达式也会匹配。
/\bth\b/gm全局查找并匹配所有作为完整单词出现的 "th",即前后都不连接其他字母、数字或下划线。在多行文本中,这将匹配像单独的 "th" 或位于行首或行尾、前后无其他单词字符的 "th"。例如,它会匹配 "a th b" 中的 "th",但不会匹配 "math" 或 "author" 中的 "th",因为这些情况下的 "th" 不是作为一个独立的单词存在。
/\Bth\B/gm\B: 非单词边界,这个特殊字符匹配不在单词边界的位置,即它的两边都是单词字符(如字母、数字或下划线)或两边都不是单词字符。
全局查找所有嵌入在其他单词内部的 "th",即"th"两边都是单词字符的情况。例如,它会匹配 "mathematics" 中的 "th" 和 "author" 中的 "th",但不会匹配 "a th b" 中的独立 "th",因为那是一个单词边界上的 "th"。在多行文本中,这个规则同样适用于每一行。
量词
/th+/gm+: 量词,表示前面的字符或子模式(在这里是 "th")可以出现一次或多次连续重复。因此,th+ 匹配一个或多个连续的 "th"。
全局查找并匹配文本中所有连续出现的一个或多个 "th" 的序列,无论这些序列出现在同一行还是不同行。例如,它会匹配 "th", "thth", "ththth" 等序列,而且在多行文本中也能正确识别这些模式。
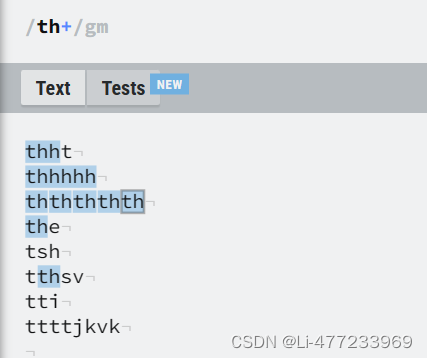
/th*/gm*: 量词,表示前面的字符或子模式(这里是 "th")可以重复零次或多次。因此,th* 匹配任何数量的连续 "th",包括零个(即空字符串)
匹配包括没有任何 "th" 的情况,单个 "th",或者连续多个 "th",如 "th", "thth", "ththth",在多行文本中亦然。
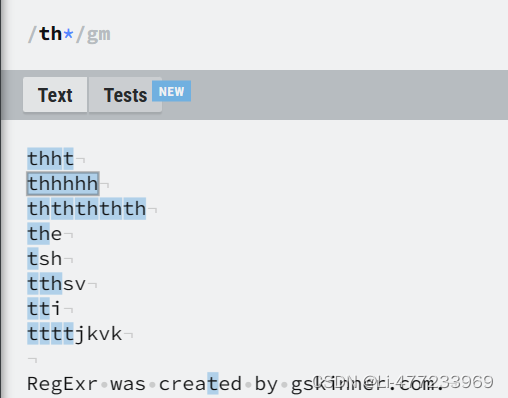
/th?/gm?: 量词,表示前面的字符或子模式可以出现零次或一次。因此,th? 匹配 "th" 或者不匹配任何东西(相当于 "th" 是可选的)。
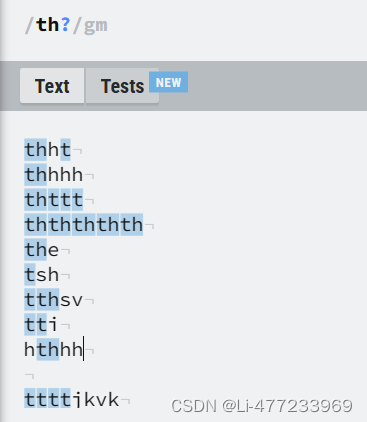
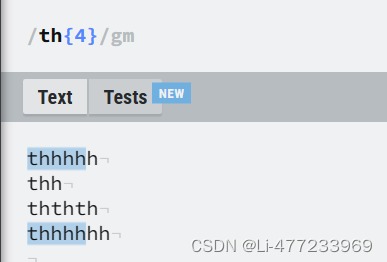
/th{4}/gm{4}: 量词,表示前面的字符 "h" 必须精确重复 4 次。
全局查找并匹配文本中所有连续出现四次的 "h",无论这些序列出现在同一行还是不同行的文本中。例如,它会匹配 "hhhhh" 中的前四个 "h",或者匹配多行文本中任何地方出现的 "hhhh"。
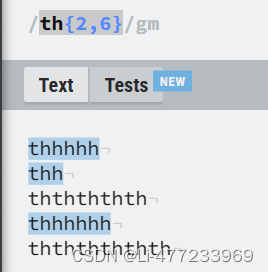
/th{2,6}/gm{2,6}: 量词,表示前面的字符 "h" 重复 2~6 次。
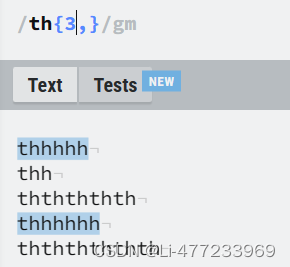
/th{2,}/gm{2,}:表示前面的字符或组合(这里为"th")必须至少连续出现2次,没有上限
分组与引用
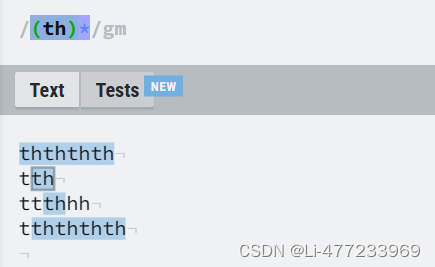
/ (th)*/gm(th):这是一个捕获组,匹配字符串"th"。括号用于捕获匹配的内容,以便后续可以通过特定功能(如替换或提取)引用。
*:紧跟在捕获组后面,表示前面的整个捕获组(即"th")可以出现任意次,包括0次。这意味着它可以匹配没有"th"的情况,或者一个"th",或者连续多个"th"序列。
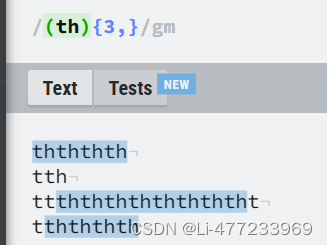
/ (th){3,}/gm(th):定义了一个捕获组,匹配字符串"th"。括号用于捕获这一匹配部分,便于后续操作使用。
{3,}:紧跟在捕获组后面,表示前面的整个捕获组"th"至少需要连续出现3次,没有上限。这意味着它不会匹配"th"或"thth",但会匹配"ththth"及更多连续的"th"序列。
/[Tt]he/gm
/The | the/gm正则表达式都用于匹配英文单词"the",不区分大小写
/[Tt]he/gm使用了字符类[Tt]来匹配大写"T"或小写"t"。
紧接着是"he",这样整体匹配"The"或"the"。
/The | the/gm使用了逻辑或(|)操作符,匹配左边的"The"或右边的"the"。
直接写出两种大小写形式,没有使用字符类。
虽然两者都能达到相同的目的——匹配不区分大小写的"the",但第一种方法/[Tt]he/gm通过字符类简化了表达式,使其更为紧凑;第二种方法/The | the/gm则通过显式列出所有可能的大小写组合来实现,可能在可读性上对某些用户来说更加直观。性能上,现代正则表达式引擎通常会对这两种写法进行优化,因此实际执行效率差异不大。
/\d{4}-\d{2}-\d{2}/gm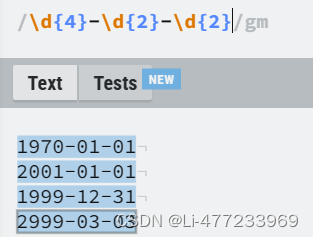
鼠标点击日期会出现分组
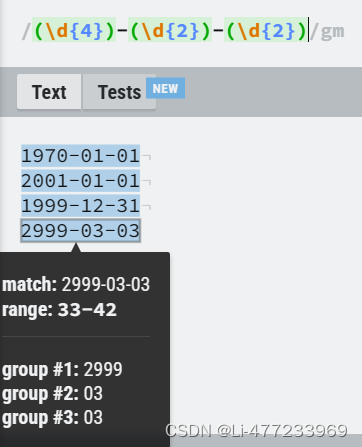
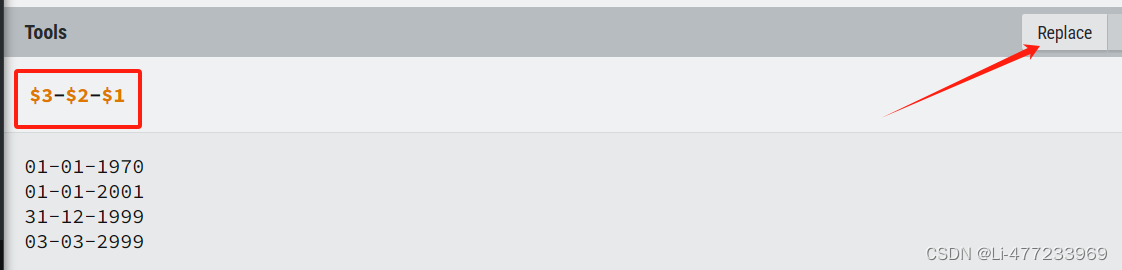
/(\d{4})[-./]?(\d{2})[-./]?(\d{2})/gm
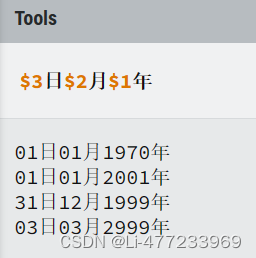
/(\d{4})[-./]?(?:\d{2})[-./]?(\d{2})/gm不捕获月份
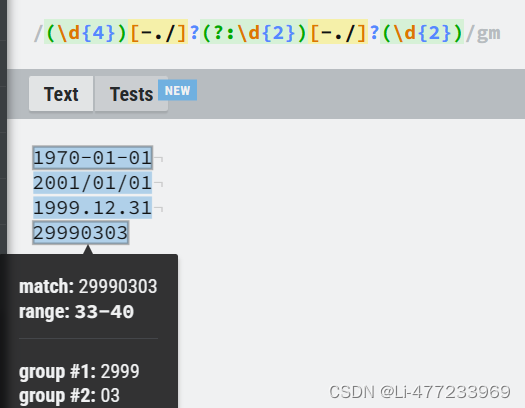
/\b([a-z])[a-z]*\1\b/gm匹配前后相同
前瞻后顾
正则表达式中的前瞻(Lookahead)和后顾(Lookbehind)是高级特性,用于检查某个模式前后的内容,但这些内容并不包括在最终匹配结果中。它们是非捕获型的,主要用于条件匹配,提高匹配的精确度。
前瞻(Lookahead)
前瞻分为正向前瞻(Positive Lookahead)和负向前瞻(Negative Lookahead)。
-
正向前瞻:
(?=...),表示接下来的模式必须匹配,但匹配的内容不包含在结果中。例如,\d+(?=\s*USD)匹配后面跟着零或多个空白字符和"USD"的数字序列,但"USD"不会被包含在匹配结果里。 -
负向前瞻:
(?!...),表示接下来的模式不应该匹配,如果匹配则整个表达式不匹配。例如,foo(?!bar)匹配"foo",但其后不能紧跟着"bar"。
后顾(Lookbehind)
后顾也分为正向后顾(Positive Lookbehind)和负向后顾(Negative Lookbehind)。
-
正向后顾:
(?<=...),检查之前的模式是否匹配,但该模式同样不包含在匹配结果中。需要注意的是,并非所有正则表达式引擎都支持固定宽度的后顾,如.NET、Java的java.util.regex等支持,而JavaScript的正则表达式就不支持这种后顾。例如,
(?<=\s)hello匹配前面有空白字符的"hello",空白字符不包括在匹配中。 -
负向后顾:
(?<!...),确保之前的模式不匹配。同样,不是所有环境都支持,且要求后顾表达式的长度是固定的。例如,
(?<![a-zA-Z])apple匹配不在字母后面的"apple"。
前瞻和后顾使得正则表达式能够进行更复杂的条件匹配,特别是在需要基于上下文进行匹配时非常有用。但使用时也应注意到它们可能增加正则表达式的复杂性和理解难度,以及在某些环境下的兼容性问题。
实操
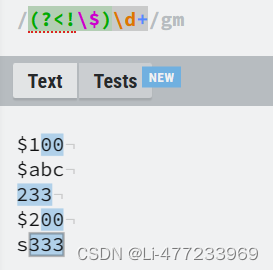
/\$(?=\d+)/gm匹配数字前面的$

/\$(?!\d+)/gm不是数字
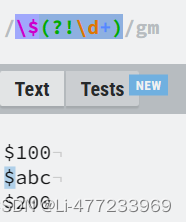
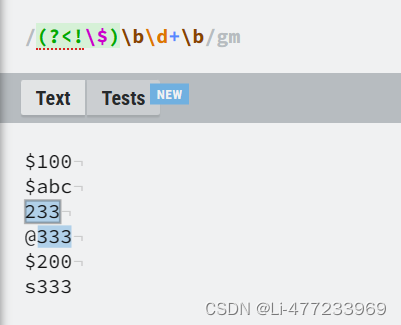
/(?<=\$)\d+/gn$后面的数字

/(?<!\$)\d+/gm前面不是$,才匹配数字
Python中的正则表达式
Python中使用re模块来处理正则表达式:
导入模块
首先,需要导入正则表达式模块:
import re编译正则表达式
可以先编译一个正则表达式模式,然后使用这个模式进行匹配。这在多次使用同一模式时可以提高效率。
pattern = re.compile(r'\d+')搜索匹配
- search() 方法:在字符串中搜索第一个匹配项。
result = pattern.search('There are 123 apples')
if result:
print("Found:", result.group()) # 输出匹配到的子串"123"
else:
print("No match")- match() 方法:从字符串的开始位置尝试匹配。
result = pattern.match('123 apples')
if result:
print("Matched:", result.group())
# Matched: 123
else:
print("No match at the beginning of the string")全局搜索
- findall() 方法:返回所有非重叠匹配的列表。
text = '123 apples and 456 oranges'
matches = pattern.findall(text)
print(matches) # 输出:['123', '456']- finditer() 方法:返回一个迭代器,每次迭代返回一个匹配对象。
for match in pattern.finditer(text):
print(match.group()) # 分别输出:'123', '456'替换字符串
- sub() 方法:替换匹配到的子串。
new_text = re.sub(r'\d+', '520', text)
print(new_text)
# 520 apples and 520 oranges分割字符串
- split() 方法:根据匹配的模式分割字符串。
words = re.split(r'\s+', 'one two three')
print(words) # 输出:['one', 'two', 'three']练习1: 提取URL
题目: 给定一段文本,从中提取所有的HTTP或HTTPS网址。
文本:
访问我们的网站 https://www.example.com 获取更多信息,或者查看 http://www.example.org 的教程。import re
text = "访问我们的网站 https://www.example.com 获取更多信息,或者查看 http://www.example.org 的教程。"
pattern = re.compile(r'https?://[\w.-]+(?:\.[\w\.-]+)+[\w\-\._~:/?#[\]@!\$&\'\(\)\*\+,;=.]+')
urls = pattern.findall(text)
print(urls)
# ['https://www.example.com', 'http://www.example.org']练习2: 验证邮箱格式
题目: 编写一个正则表达式,用于验证一个字符串是否符合qq电子邮件地址的格式。
import re
email_pattern = re.compile(r'^[\d\.-]+@[\w\.-]+\.\w+$')
def is_valid_email(email):
return bool(email_pattern.match(email))
test_emails = ["user@example.com", "333@qq.com", "@example.com", "333@qq"]
for email in test_emails:
print(f"{email}: {is_valid_email(email)}")
"""
user@example.com: False
333@qq.com: True
@example.com: False
333@qq: False
"""
练习3: 替换敏感词
题目: 将文本中出现的敏感词(如"badword")替换为"*"号。
文本:
这是一段含有badword的文本,badword应该被替换。import re
text = "这是一段含有badword的文本,badword应该被替换。"
censored_text = re.sub(r'badword', '*', text)
print(censored_text)
# 这是一段含有*的文本,*应该被替换。练习4: 提取HTML标签中的文本
题目: 从一段HTML文本中提取所有的<a>标签内的文本内容。
文本:
<html>
<body>
<p>欢迎访问<a href="https://www.baidu.com">baidu</a>百度网站!</p>
<a href="https://www.jd.com">买买买</a>
</body>
</html>import re
html_text = """
<html>
<body>
<p>欢迎访问<a href="https://www.baidu.com">baidu</a>百度网站!</p>
<a href="https://www.jd.com">买买买</a>
</body>
</html>
"""
pattern = re.compile(r'<a[^>]*>(.*?)</a>')
texts = pattern.findall(html_text)
print(texts)
# ['baidu', '买买买']














 8万+
8万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









