






目录
1.AlexNet网络结构
1.1.什么是AlexNet
AlexNet是由Alex Krizhevsky、Ilya Sutskever和Geoffrey Hinton在2012年ImageNet图像分类竞赛中提出来的一种经典的卷积神经网络(CNN),它在ImageNet大规模视觉竞赛中取得了优异的成绩,在当时把深度学习模型的正确率提高到了一个前所未有的高度。
AlexNet的出现对深度学习(Deep Learning)发展具有里程碑的意义,在计算机视觉领域具有极高的影响力,刺激了后续更多使用卷积神经网络和GPU来加速深度学习模型论文的出现,截至2020年,AlexNet论文已经被引用超过了54000次。
1.2.AlexNet结构详细解读
AlexNet的网络结构如下图所示
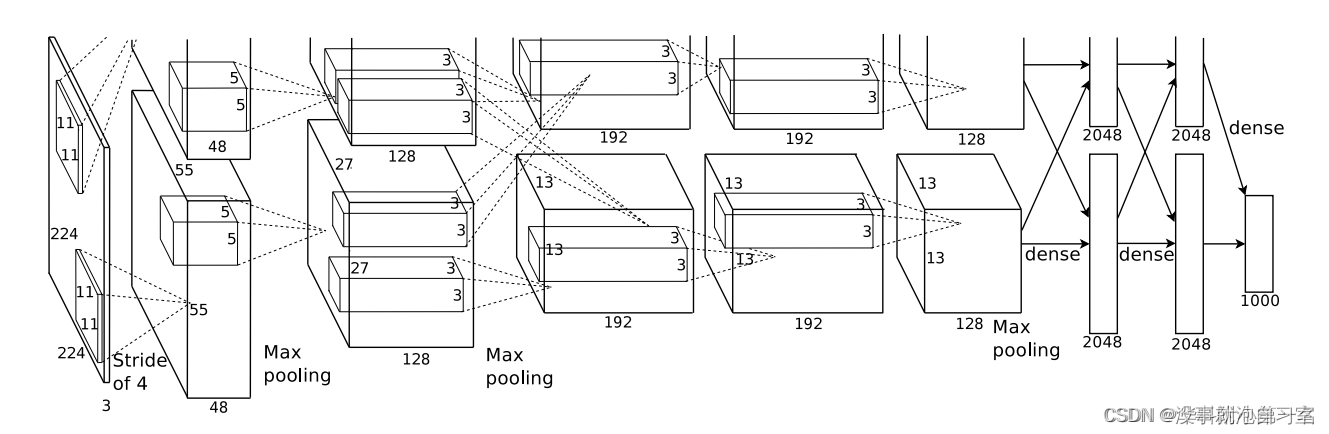
AlexNet的基本结构包含5个卷积层(Conv2d),3个池化层(MaxPool2d),3个全连接层(Linear),详细结构如下:
注解:由于原论文采用两块GPU同时进行训练,而我只有一块GPU,为了适应我的硬件设备,所以在网络结构上有所调整,后续将会解释调整的原理。 (详细见1.3)
关于卷积层和池化层的输出输出尺寸计算公式:
求图像的高度H时,idx=0;宽度W时,idx取1.无论是卷积层还是池化层,都可以这样计算,dilation默认值为1。
- 卷积层(输入通道数:3,输出通道数:96,卷积核大小:11×11,步长:4,填充:0)
- 最大池化层(池化核大小:3×3,步长:2)
- 卷积层(输入通道数:96,输出通道数:256,卷积核大小:5×5,步长:1,填充:2)
- 最大池化层(池化核大小:3×3,步长:2)
- 卷积层(输入通道数:256,输出通道数:358,卷积核大小:3×3,步长:1,填充:1)
- 卷积层(输入通道数:358,输出通道数:358,卷积核大小:3×3,步长:1,填充:1)
- 卷积层(输入通道数:358,输出通道数:256,卷积核大小:3×3,步长:1,填充:1)
- 最大池化层(池化核大小:3×3,步长:2)
- 展平,将数据转化为1×n维向量,方便后续连接全连接层
- 全连接层(输入通道数:9216,输出通道数:4096)
- 全连接层(输入通道数:4096,输出通道数:4096)
- 全连接层(输入通道数:9216,输出通道数:classes_num)
tips:
- nn.ReLU()是激活函数,适当地放在卷积层和全连接层后
- F.dropout()函数在正向传播的全连接层直接传播过程中使部分结点失效,防止过拟合
- nn.Flatten()函数是对向量进行展平的,输出为1×n维的向量,方便全连接层之间的传播
- classes_num(最终的分类结果数量)根据自己的需求进行修改,原论文实现的1000种分类,在后续的实例化中,由于我们是对肺部是否感染进行分类,只有两种情况:“正常”和“感染”,因此后续实例化中的classes_num=2。
1.3.AlexNet网络实现
双GPU到单GPU模型实现网络参数修改解释:
以第一层为例,原论文是(图为224,原始图片,未经过填充,经过填充后为227)
双GPU:(227,227,3) -> gpu1(55,55,48),gpu2(55,55,48)
单GPU:(227,227,3) -> gpu0(55,55,96)
由此可见,双GPU和单GPU最大的不同就是通道数不同,图像的尺寸是相同地,单GPU的通道数是双GPU单个GPU的通道数的两倍,可以理解为两个GPU共同完成了网络的计算,各负责一半的运算。
以此类推,后续几层的网络结构也是这样一个数量关系,在这里就不再继续展开推理
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
# 激活函数
self.ReLU = nn.ReLU()
# 1.227,227,3
# 2.227,227,3 -> 55,55,96
self.c1 = nn.Conv2d(in_channels=3, out_channels=96, kernel_size=(11, 11), stride=4)
# 3.55,55,96 -> 27,27,96
self.s2 = nn.MaxPool2d(kernel_size=(3, 3), stride=2)
# 4.27,27,96 -> 27,27,256
self.c3 = nn.Conv2d(in_channels=96, out_channels=256, kernel_size=(5, 5), stride=1, padding=2)
# 5.27,27,256 -> 13,13,256
self.s4 = nn.MaxPool2d(kernel_size=(3, 3), stride=2)
# 6.13,13,256 -> 13,13,384
self.c5 = nn.Conv2d(in_channels=256, out_channels=384, kernel_size=(3, 3), stride=1, padding=1)
# 7.13,13,384 -> 13,13,384
self.c6 = nn.Conv2d(in_channels=384, out_channels=384, kernel_size=(3, 3), stride=1, padding=1)
# 7.13,13,384 -> 13,13,256
self.c7 = nn.Conv2d(in_channels=384, out_channels=256, kernel_size=(3, 3), stride=1, padding=1)
# 8.13,13,384 -> 6,6,256
self.s8 = nn.MaxPool2d(kernel_size=(3, 3), stride=2)
# 9.6,6,256 -> 9216
self.flatten = nn.Flatten()
# 10.9216 -> 4096
self.f1 = nn.Linear(9216, 4096)
# 11.4096 -> 4096
self.f2 = nn.Linear(4096, 4096)
# 12.4096 -> 2
self.f3 = nn.Linear(4096, 2)
def forward(self, x):
x = self.ReLU(self.c1(x))
x = self.s2(x)
x = self.ReLU(self.c3(x))
x = self.s4(x)
x = self.ReLU(self.c5(x))
x = self.ReLU(self.c6(x))
x = self.ReLU(self.c7(x))
x = self.s8(x)
# -----------------------
x = self.flatten(x)
x = self.ReLU(self.f1(x))
x = F.dropout(input=x, p=0.5)
x = self.ReLU(self.f2(x))
x = F.dropout(input=x, p=0.5)
x = self.f3(x)
return x1.4.AlexNet的创新点
-
更深的神经网络结构:AlexNet是首个真正意义上的深度卷积神经网络,它的深度达到了当时先前神经网络的数倍。
-
ReLU激活函数的使用:AlexNet首次使用了修正线性单元(ReLU)这一非线性激活函数。
-
局部响应归一化(LRN)的使用:LRN是在卷积层和池化层之间添加的一种归一化操作,在实例化中即为ReLU()激活函数地使用。
-
数据增强和Dropout:为了防止过拟合,AlexNet引入了数据增强和Dropout技术。
-
大规模分布式训练:AlexNet在使用GPU进行训练时,可将卷积层和全连接层分别放到不同的GPU上进行并行计算,从而大大加快了训练速度。
2.AlexNet实例化
实例化以解决二分类问题进行,使用AlexNet网络对肺部X-Ray医学影像进行识别,并且能够分类,得到正常(NORMAL)和感染(PNEUMONIA)两种结果,因此后续网络中的classes_num=2。
模型结果如下:
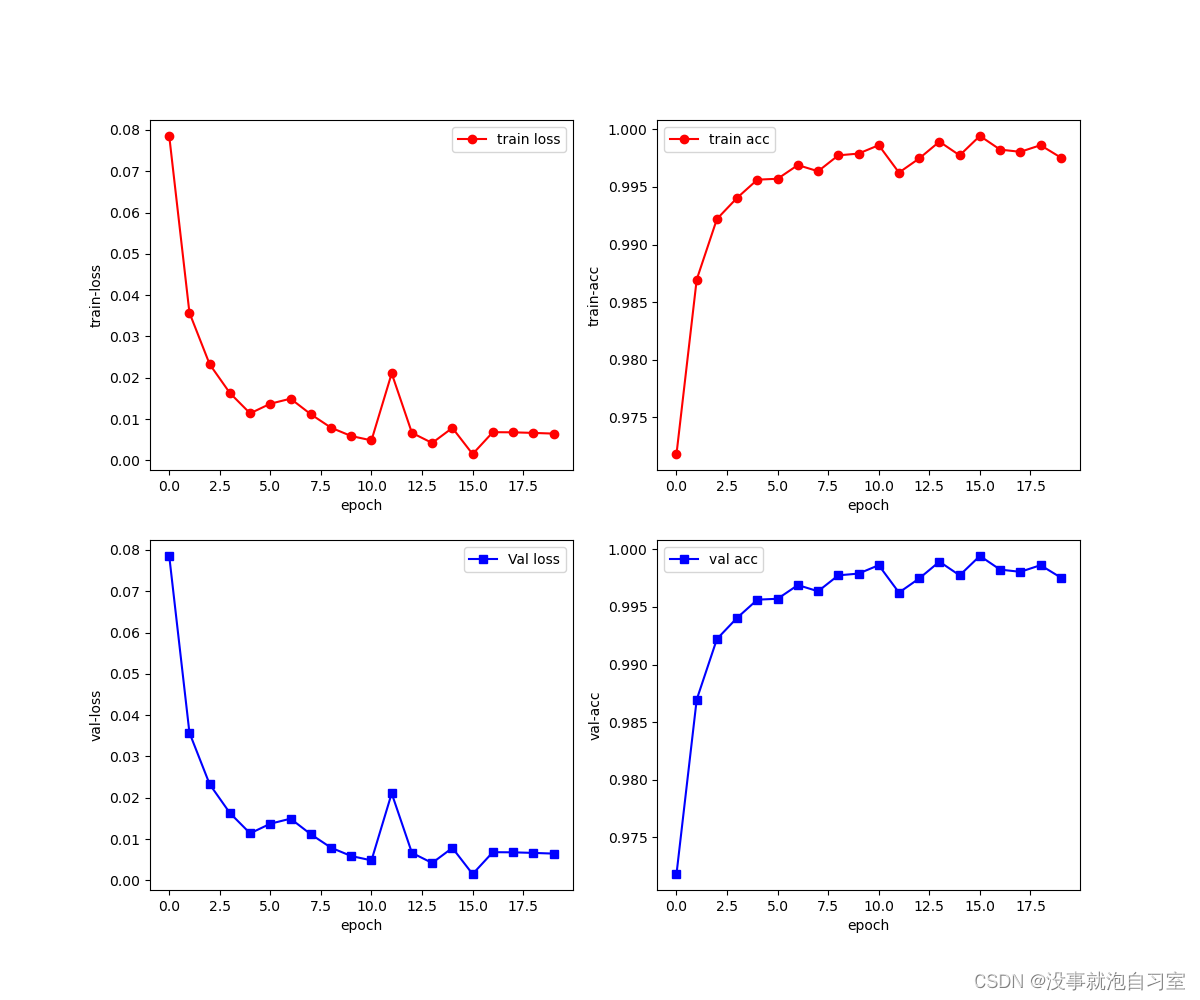
2.1.数据准备
原始数据为Chest-XRay文件夹,其目录结构如下:

其中包含了训练集(train)、验证集(val)、测试集(test)
由于原始数据过于庞大(约1.5GB,记不清了),作者将其存放到了百度网盘上(链接如下,设置为了永久有效,如果感兴趣可以自行下载),大家也可以到Kaggle上下载数据
链接:https://pan.baidu.com/s/1Pm3A2IrISJaDHUHGjUOafA
提取码:Alex
--来自百度网盘超级会员V4的分享
注解:网盘中有两个数据文件,一个是原始数据(Chest_XRay),另一个是经过Data_enhance.py随机增强过的训练数据(data_enhance)
2.2.net.py
该文件下是对AlexNet网络结构的实现,将继承了torch.nn.Module类来实现AlexNet类,net.py文件如下:
# net.py
import torch
import torch.nn as nn
from torchsummary import summary
import torch.nn.functional as F
class AlexNet(nn.Module):
def __init__(self):
super(AlexNet, self).__init__()
# 激活函数
self.ReLU = nn.ReLU()
# 1.227,227,3
# 2.227,227,3 -> 55,55,96
self.c1 = nn.Conv2d(in_channels=3, out_channels=96, kernel_size=(11, 11), stride=4)
# 3.55,55,96 -> 27,27,96
self.s2 = nn.MaxPool2d(kernel_size=(3, 3), stride=2)
# 4.27,27,96 -> 27,27,256
self.c3 = nn.Conv2d(in_channels=96, out_channels=256, kernel_size=(5, 5), stride=1, padding=2)
# 5.27,27,256 -> 13,13,256
self.s4 = nn.MaxPool2d(kernel_size=(3, 3), stride=2)
# 6.13,13,256 -> 13,13,384
self.c5 = nn.Conv2d(in_channels=256, out_channels=384, kernel_size=(3, 3), stride=1, padding=1)
# 7.13,13,384 -> 13,13,384
self.c6 = nn.Conv2d(in_channels=384, out_channels=384, kernel_size=(3, 3), stride=1, padding=1)
# 7.13,13,384 -> 13,13,256
self.c7 = nn.Conv2d(in_channels=384, out_channels=256, kernel_size=(3, 3), stride=1, padding=1)
# 8.13,13,384 -> 6,6,256
self.s8 = nn.MaxPool2d(kernel_size=(3, 3), stride=2)
# 9.6,6,256 -> 9216
self.flatten = nn.Flatten()
# 10.9216 -> 4096
self.f1 = nn.Linear(9216, 4096)
# 11.4096 -> 4096
self.f2 = nn.Linear(4096, 4096)
# 12.4096 -> 2
self.f3 = nn.Linear(4096, 2)
def forward(self, x):
x = self.ReLU(self.c1(x))
x = self.s2(x)
x = self.ReLU(self.c3(x))
x = self.s4(x)
x = self.ReLU(self.c5(x))
x = self.ReLU(self.c6(x))
x = self.ReLU(self.c7(x))
x = self.s8(x)
# -----------------------
x = self.flatten(x)
x = self.ReLU(self.f1(x))
x = F.dropout(input=x, p=0.5)
x = self.ReLU(self.f2(x))
x = F.dropout(input=x, p=0.5)
x = self.f3(x)
return x2.3.Data_Enhance.py
Data_Enhance.py对Chest_XRay文件下的train训练集进行随机数据增强,通过一些随机的图像处理来增强训练过程中的准确度,怎强后的训练数据单独生成一个目录data_enhance,该新目录下只存放怎强后的训练集数据,如果做验证和测试实验,还需要用原始数据文件夹(Chest_CRay)下的val文件夹和test文件夹
# Data_Enhance.py
import os
from PIL import Image, ImageEnhance
import random
import cv2
def Random_Enhance(img):
"""
随机数据增强,包含对数据的镜像翻转、旋转、随即尺度变换、亮度变化、锐度变化、对比度变化、色彩平衡
:param img:
:return:
"""
# transpose-翻转,rotate-旋转,
methods = [Image.Image.transpose,
Image.Image.rotate,
Image.Image.resize,
ImageEnhance.Brightness,
ImageEnhance.Sharpness,
ImageEnhance.Contrast,
ImageEnhance.Color]
method = random.choice(methods)
if method == Image.Image.transpose:
# 左右镜像翻转、上下镜像翻转、逆时针旋转90、逆时针旋转180、逆时针旋转270
methods = [Image.FLIP_LEFT_RIGHT, Image.FLIP_TOP_BOTTOM, Image.ROTATE_90, Image.ROTATE_180, Image.ROTATE_270]
return img.transpose(random.choice(methods))
elif method == Image.Image.rotate:
# 逆时针旋转随机度数(0-360)
return img.rotate(random.randint(0, 360))
elif method == Image.Image.resize:
# 宽高随机缩放原来图像的0.5-1.5倍大小
width, height = img.size
return img.resize(
(random.randint(int(width * 0.5), int(width * 1.5)), random.randint(int(height * 0.5), int(height * 1.5))))
elif method == ImageEnhance.Brightness:
# 亮度变化
factor = random.uniform(a=0.3, b=1.1)
return ImageEnhance.Brightness(image=img).enhance(factor=factor)
elif method == ImageEnhance.Sharpness:
#
factor = random.uniform(a=0.5, b=1.5)
return ImageEnhance.Sharpness(image=img).enhance(factor=factor)
elif method == ImageEnhance.Contrast:
# 对比度变化
factor = random.uniform(a=0.3, b=1.7)
return ImageEnhance.Sharpness(image=img).enhance(factor=factor)
elif method == ImageEnhance.Color:
factor = random.uniform(a=0.0, b=1.0)
return ImageEnhance.Color(image=img).enhance(factor=factor)
def batch_enhance_image(class_input_dir, class_output_dir, suffix):
"""
:param class_input_dir: 原始数据文件夹(INPUT)
:param class_output_dir: 增强文件夹(OUTPUT)
:param suffix: 新数据编号(如果需要多轮增强就需要保证文件名不相同,故此处创建一个编号加在原始文件名后来区分)
:return: None
"""
# 检查输出目录是否存在,如果不存在,则创建它
if not os.path.exists(class_output_dir):
os.makedirs(class_output_dir)
# 遍历输入目录中的所有文件-class 1
for filename in os.listdir(class_input_dir):
# 检查文件是否为图像
if filename.endswith('.jpeg'):
# 获取输入图像的完整路径
input_path = os.path.join(class_input_dir, filename)
# cv2-打开原图并保存到新的路径下
img = cv2.imread(filename=input_path)
cv2.imwrite(
filename=os.path.join(class_output_dir, filename),
img=img)
# 数据增强
# PIL-打开图像
img = Image.open(fp=input_path)
img_enhanced = Random_Enhance(img=img)
# 获取输出图像的完整路径
output_path = os.path.join(class_output_dir, f'{filename[:-5]}-{suffix}.jpeg')
# 保存增强后的图像
img_enhanced.save(output_path)
# 使用示例
if __name__ == "__main__":
# 获取根目录
root_path = os.getcwd()
# 原始数据大小
num = 5126
normal_num = 1341
pneumonia_num = 3875
# 进行多轮增强
a = 1
b = 5
print(f'总共进行{b - 1}轮数据增强')
for i in range(a, b):
print(f'Data enhance turn:', i)
# 对 train\\NORMAL 里的数据进行增强
batch_enhance_image(
class_input_dir=os.path.join(root_path, 'Chest_XRay\\train\\NORMAL'),
class_output_dir=os.path.join(root_path, 'data_enhance\\train\\NORMAL'),
suffix=i)
# 对 train\\PNEUMONIA 里的数据进行增强
batch_enhance_image(
class_input_dir=os.path.join(root_path, 'Chest_XRay\\train\\PNEUMONIA'),
class_output_dir=os.path.join(root_path, 'data_enhance\\train\\PNEUMONIA'),
suffix=i)
print('train NORMAL:', normal_num * (i + 1))
print('train PNEUMONIA', pneumonia_num * (i + 1))
print('train Total:', num * (i + 1))
print('-' * 50)
2.4.train.py
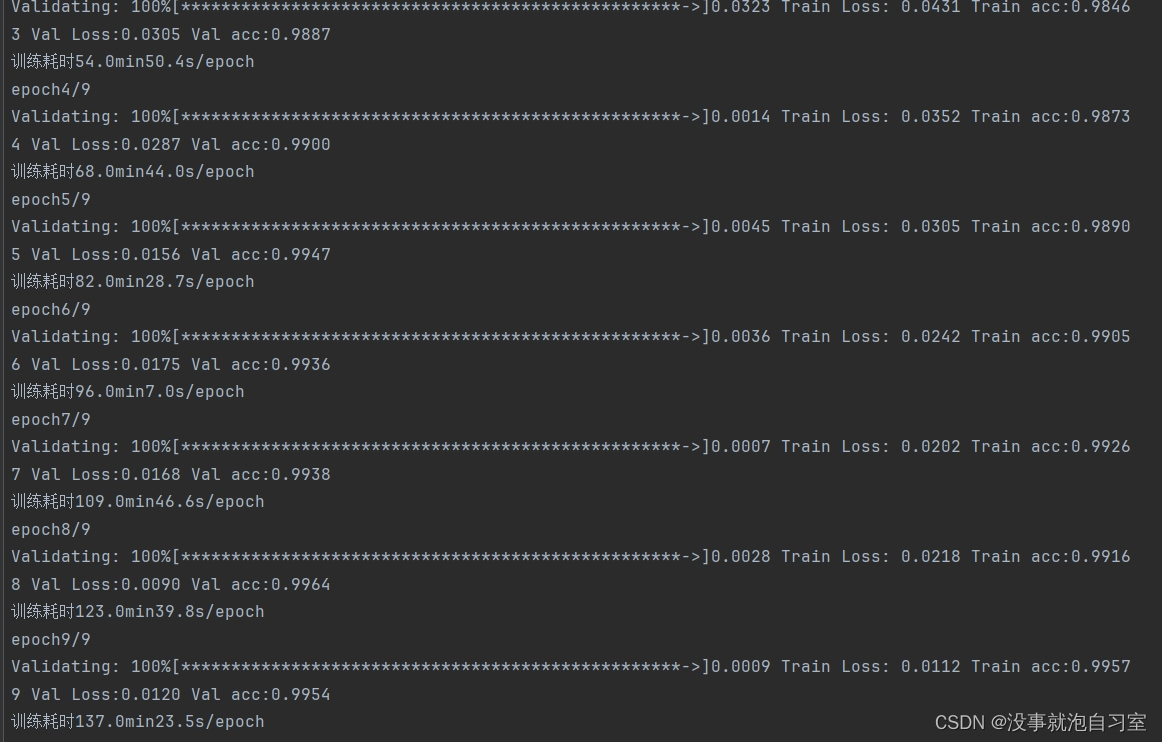
train.py对net.py文件的模型进行训练,训练好的模型以xxx.pth的形式保存,经过多次实验,lr=0.0001,epoch=10,batch=32的时候就已经能得到不错的效果,验证准确率95%以上
# train.py
import copy
import time
import torch
import torch.nn as nn
from torchvision import transforms, datasets
from torch.utils.data import DataLoader
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import os
from net import AlexNet
def Get_Image_Size(in_size):
# get Input-Imagee size
width, high = 224, 224
if isinstance(in_size, int):
width = in_size
high = in_size
elif isinstance(in_size, tuple):
width = in_size[0]
high = in_size[1]
return width, high
def Get_Batch_Size_For_TrainVal(batch):
# get batch size
train_batch, val_batch = 32, 16
if isinstance(batch, int):
train_batch = batch
val_batch = batch
elif isinstance(batch, tuple):
train_batch = batch[0]
val_batch = batch[1]
return train_batch, val_batch
# 加载数据集
def Data_Loading(root, in_size, batch):
width, high = Get_Image_Size(in_size)
train_batch, val_batch = Get_Batch_Size_For_TrainVal(batch)
# transform configuration
data_transform = {
"train": transforms.Compose([transforms.Resize((width, high)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))]),
"val": transforms.Compose([transforms.Resize((width, high)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
}
# Image File
train_path = os.path.join(root, "val")
val_path = os.path.join(root, "val")
# Dataset
train_dataset = datasets.ImageFolder(root=train_path, transform=data_transform['train'])
val_dataset = datasets.ImageFolder(root=val_path, transform=data_transform['val'])
# Loader
train_loader = DataLoader(dataset=train_dataset, batch_size=train_batch, shuffle=True, num_workers=0,
drop_last=True)
val_loader = DataLoader(dataset=train_dataset, batch_size=val_batch, shuffle=False, num_workers=0, drop_last=True)
# return variable
return train_loader, val_loader, len(train_dataset), len(val_dataset)
def Train_Process(model, Train_DataLoader, Val_DataLoader, Learning_Rate, epoch_num, pth_name):
# gpu/cpu
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cup')
# Optimizer
optimizer = torch.optim.Adam(params=model.parameters(), lr=Learning_Rate)
# Loss-交叉熵损失
Loss = nn.CrossEntropyLoss()
# 模型指认到设备中
model.to(device)
# Copy current model param
best_model_wts = copy.deepcopy(model.state_dict())
# 初始化参数
# 最高准确度
best_acc = 0.0
# 训练集损失列表
train_loss_all = []
# 验证集损失列表
val_loss_all = []
# 训练集准确度列表
train_acc_all = []
# 验证集准确度列表
val_acc_all = []
# 保存当前时间
Time_Start = time.time()
for epoch in range(epoch_num):
print("epoch{}/{}".format(epoch, epoch_num - 1))
# initialize parameter
train_loss = 0.0
train_corrects = 0
val_loss = 0.0
val_corrects = 0
train_num = 0
val_num = 0
for step, (feature, label) in enumerate(Train_DataLoader):
feature = feature.to(device)
label = label.to(device)
# set train model
model.train()
# 前向传播过程中输出一个batch输入一个batch中对应的预测
output = model(feature)
# 查找每一行中概率最大的结果
predict = torch.argmax(input=output, dim=1)
# 通过预测和标签计算损失函数值,每个batch的损失
loss = Loss(output, label)
# 将梯度初始化为0
optimizer.zero_grad()
# 反向传播
loss.backward()
# 更新网络参数
optimizer.step()
train_loss += loss.item() * feature.size(0)
train_corrects += torch.sum(predict == label.data)
train_num += feature.size(0)
# print train process
rate = (step + 1) / len(Train_DataLoader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
# print("Training:\n")
print("\rTraining {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
for step, (feature, label) in enumerate(Val_DataLoader):
# evaluate
model.eval()
feature = feature.to(device)
label = label.to(device)
output = model(feature)
predict = torch.argmax(input=output, dim=1)
loss = Loss(output, label)
val_loss += loss.item() * feature.size(0)
val_corrects += torch.sum(predict == label)
val_num += feature.size(0)
# print train process
rate = (step + 1) / len(Val_DataLoader)
a = "*" * int(rate * 50)
b = "." * int((1 - rate) * 50)
# print('Validate:\n')
print("\rValidating: {:^3.0f}%[{}->{}]{:.3f}".format(int(rate * 100), a, b, loss), end="")
train_loss_all.append(train_loss / train_num)
val_loss_all.append(val_loss / val_num)
train_acc_all.append(train_corrects.double().item() / train_num)
val_acc_all.append(val_corrects.double().item() / val_num)
print('{} Train Loss: {:.4f} Train acc:{:.4f}'.format(epoch, train_loss_all[-1], train_acc_all[-1]))
print('{} Val Loss:{:.4f} Val acc:{:.4f}'.format(epoch, val_loss_all[-1], val_acc_all[-1]))
if val_acc_all[-1] > best_acc:
best_acc = val_acc_all[-1]
# 保持当前参数
best_model_wts = copy.deepcopy(model.state_dict())
time_use = time.time() - Time_Start
print('训练耗时{:.1f}min{:.1f}s/epoch'.format(time_use // 60, time_use % 60))
# 选择最优模型保存-加载最高准确率下的参数
model.load_state_dict(best_model_wts)
root_path = os.getcwd()
torch.save(obj=best_model_wts,
f=os.path.join(root_path, 'pth_save', pth_name))
train_process = pd.DataFrame(data={'epoch': range(epoch_num),
'train_loss_all': train_loss_all,
'val_loss_all': val_loss_all,
'train_acc_all': train_acc_all,
'val_acc_all': val_loss_all, })
return train_process
def plot(train_process, Title, Save_Path):
plt.figure(figsize=(12, 10))
plt.subplot(2, 2, 1)
plt.plot(train_process['epoch'], train_process.train_loss_all, 'ro-', label='train loss')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('train-loss')
plt.subplot(2, 2, 3)
plt.plot(train_process['epoch'], train_process.train_loss_all, 'bs-', label='Val loss')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('val-loss')
plt.subplot(2, 2, 2)
plt.plot(train_process['epoch'], train_process.train_acc_all, 'ro-', label='train acc')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('train-acc')
plt.subplot(2, 2, 4)
plt.plot(train_process['epoch'], train_process.train_acc_all, 'bs-', label='val acc')
plt.legend()
plt.xlabel('epoch')
plt.ylabel('val-acc')
# plt.title(Title)
# plt.show()
plt.savefig(Save_Path)
if __name__ == "__main__":
# 0.获取项目文件路径
root_path = os.getcwd()
# 1.模型实例化
net = AlexNet()
# 2.加载数据集
train_dataloader, val_dataloader, train_num, val_num = Data_Loading(
root=os.path.join(root_path, 'data_enhance'),
in_size=(227, 227), batch=(32, 32))
train_process = Train_Process(model=net, Train_DataLoader=train_dataloader, Val_DataLoader=val_dataloader,
Learning_Rate=0.0001, epoch_num=1, pth_name='AlexModel_test.pth')
plot(train_process=train_process, Title='lr=0.0001 epoch=10',
Save_Path='plt/VTest.png')训练结果需下图所示:
2.5.test.py
train.py训练完成后得到训练好的模型:xxx.pth
建议:lr=0.0001,epoch=10,batch=32
test.py则是利用测试集数据(Chest_XRay/test)进行训练,test.py代码如下:
# test.py
import torch
from torch.utils.data import DataLoader
from torchvision import datasets, transforms
from net import AlexNet
import os
def Get_Image_Size(in_size):
"""
获取图像尺寸,并且辨别是int还是tuple
:param in_size:
:return:
"""
# get Input-Imagee size
width, high = 224, 224
if isinstance(in_size, int):
width = in_size
high = in_size
elif isinstance(in_size, tuple):
width = in_size[0]
high = in_size[1]
return width, high
def Data_Loading(root, img_size, batch):
"""
加载数据
:param root:数据地址
:param img_size:需要的图像大小
:param batch: batch-number
:return:
"""
width, high = Get_Image_Size(img_size)
test_transform = transforms.Compose([transforms.Resize((width, high)),
transforms.ToTensor(),
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5))])
test_dataset = datasets.ImageFolder(root=root, transform=test_transform)
test_dataloader = DataLoader(dataset=test_dataset, batch_size=batch, shuffle=True, num_workers=0)
return test_dataloader
def Test_Model(model, test_dataloader):
# gpu/cpu
device = torch.device('cuda:0' if torch.cuda.is_available() else 'cup')
model = model.to(device)
# initialize parameter
test_acc = 0.0
test_num = 0
test_correct = 0
# 梯度值为零
with torch.no_grad():
for feature, label in test_dataloader:
feature = feature.to(device)
label = label.to(device)
model.eval()
output = model(feature)
predict = torch.argmax(input=output, dim=1)
test_correct += torch.sum(predict == label.data)
test_num += feature.size(0)
print(f"predict:{predict}---label:{label}, result:{'1' if predict == label else '0'}")
test_acc = test_correct.double().item() / test_num
print('test acc:', test_acc)
if __name__ == "__main__":
model = AlexNet()
root_path = os.getcwd()
model.load_state_dict(torch.load(f=os.path.join(root_path, 'pth_save', 'AlexModel_V11.pth')))
test_dataloader = Data_Loading(root=os.path.join(root_path, 'data_enhance', 'test'),
img_size=227,
batch=1)
Test_Model(model=model, test_dataloader=test_dataloader)
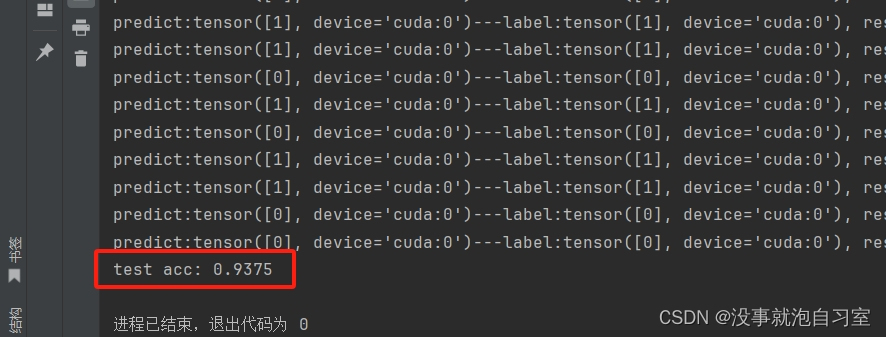
测试结果如下(AlexModel_V11.pth,即lr=0.0001,epoch=10,batch=32):
3.备注
3.1.代码运行
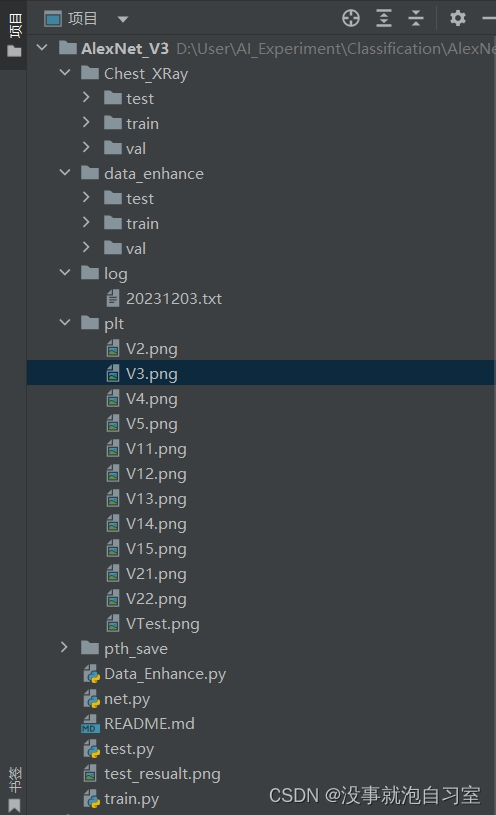
所有代码文件和文中提到的数据文件应当放在同一项目文件夹下,否则运行会因为路劲无效而中断,以下给出作者自己的目录格式:
3.2.联系方式及Github仓库地址
如果文中有问题请联系作者及时更正~
Email:y_years@126.com
Github :https://github.com/Y-nk-FE/AlexNet.git



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









