






1.为什么用SpringBoot,它的自动装配原理
Spring Boot是一个用于快速构建基于Spring框架的应用程序的工具,简化Spring应用程序的初始化和开发过程,提供一种快速开发、无需繁琐配置的方式来构建Java应用;
自动装配原理是基于Spring框架的@ComponentScan,自动装配原理是通过类路径扫描、条件装配和外部化配置来实现的;
11.看你都是用SpringBoot,那SpringBoot的核心注解是哪个?
Spring Boot的核心注解是 @SpringBootApplication。这个注解通常用于标记Spring Boot应用的主类,以及启用自动配置和组件扫描。@SpringBootApplication包含了以下几个核心注解:
@Configuration: 表示这是一个Java配置类,用于定义Bean。@EnableAutoConfiguration: 启用Spring Boot的自动配置机制,它会根据项目的依赖自动配置Spring应用程序上下文。@ComponentScan: 启用组件扫描,Spring会自动扫描并注册Bean。
这个核心注解的使用可以让你很方便地创建一个Spring Boot应用,而不需要手动进行复杂的配置。在Spring Boot应用中,通常只需要一个主类标记@SpringBootApplication,然后通过注解和配置文件来进行项目的定制和配置
3.了解AOP吗,说一下SpringBoot中AOP的实现,JDK动态代理和CGLib动态代理的区别
AOP(面向切面编程)是一种编程范式,它允许在应用中横切关注点(cross-cutting concerns)与核心业务逻辑进行分离,通常用于处理日志、事务管理、安全等方面的功能。Spring Boot提供了AOP的支持,使得开发者能够更容易地实现横切关注点。
Spring Boot中的AOP实现通常基于两种主要的动态代理方式:JDK动态代理和CGLib动态代理。
-
JDK动态代理:
- 基于接口:JDK动态代理要求目标对象实现接口,它创建一个实现了目标接口的代理对象。
- 通过
java.lang.reflect.Proxy类和java.lang.reflect.InvocationHandler接口实现代理。 - JDK代理在运行时动态生成代理类,将代理对象方法调用委托给InvocationHandler实现类的
invoke方法。 - JDK代理对于接口代理非常有效,但不能代理没有实现接口的类。
-
CGLib动态代理:
- 基于继承:CGLib动态代理不要求目标对象实现接口,它创建一个目标类的子类作为代理对象。
- 通过
CGLib库实现代理。 - CGLib代理通过继承方式实现,创建目标类的子类,并重写其中的方法来实现代理。
- CGLib代理对于没有实现接口的类和类中的final方法也有效。
区别:
- JDK动态代理只能代理实现了接口的类,而CGLib动态代理可以代理没有实现接口的类。
- JDK动态代理是基于接口的代理,它创建代理对象时需要目标类实现接口,而CGLib动态代理是基于继承的代理,它创建目标类的子类来实现代理。
- JDK动态代理使用
java.lang.reflect.Proxy和java.lang.reflect.InvocationHandler,而CGLib动态代理使用CGLib库。 - JDK动态代理的性能相对较好,因为它生成的代理类是轻量级的,但只支持接口代理。CGLib代理性能相对较差,因为它生成的代理类相对庞大,但可以代理没有接口的类
4.SpringBoot中事务基于什么实现的
Spring Boot的事务管理基于Spring框架的事务管理机制实现。Spring提供了一种声明式的事务管理方式,其中事务的边界由特定的注解或XML配置定义。Spring Boot继承并扩展了Spring框架的事务管理能力,使得在Spring Boot应用中更容易配置和使用事务。
Spring Boot支持以下几种事务管理方式:
-
编程式事务管理:通过编写代码来控制事务的开始、提交、回滚和保存点设置。虽然它提供了最大的控制,但通常不建议在Spring Boot中使用,因为它较为繁琐。
-
基于XML的声明式事务管理:通过XML配置文件声明事务的属性和切入点。这种方式可以使事务管理的规则更加可配置,但需要编写和维护大量XML配置。
-
基于注解的声明式事务管理:使用注解配置事务属性,例如
@Transactional注解。这是Spring Boot中最常见的事务管理方式,它允许在方法上使用注解来声明事务,使得事务配置更加简单和易于维护。
5.SpringBoot中事务的隔离级别
Spring Boot中支持的事务隔离级别与标准的数据库事务隔离级别相同,包括:
-
DEFAULT(默认隔离级别):这是数据库默认的事务隔离级别。在MySQL中通常是
REPEATABLE READ,在Oracle中通常是READ COMMITTED。不设置具体隔离级别时,使用数据库默认级别。 -
READ_UNCOMMITTED(读未提交数据):事务可以读取未提交的数据。这是最低的隔离级别,通常不建议使用,因为可能会导致脏读、不可重复读和幻影读问题。
-
READ_COMMITTED(读已提交数据):事务只能读取已提交的数据。这是大多数数据库的默认隔离级别,可以避免脏读问题,但仍可能存在不可重复读和幻影读问题。
-
REPEATABLE_READ(可重复读):在事务执行期间,同一数据行的读取结果保持不变。这可以避免脏读和不可重复读,但仍可能存在幻影读问题。
-
SERIALIZABLE(串行化):最高的隔离级别,可以避免脏读、不可重复读和幻影读问题。在这个级别下,事务顺序执行,可能会导致性能下降。
-
在Spring Boot中,你可以使用
@Transactional注解的isolation属性来指定事务的隔离级别
6.SpringBoot中事务的失效情况
-
事务方法未被正确调用:确保事务注解被正确添加到要开启事务的方法上,并且这些方法被其他类中的另一个方法调用。如果在同一个类中调用带有事务注解的方法,事务可能不会生效,因为Spring使用代理来处理事务。确保Spring的AOP代理被正确配置。
-
RuntimeException未被抛出:Spring的声明式事务是通过抛出
RuntimeException(或其子类)来触发事务回滚的。如果在事务方法中抛出了非RuntimeException异常,事务可能不会回滚。确保你的异常处理遵循这一规则。 -
Propagation属性设置不当:
@Transactional注解的propagation属性用于指定事务的传播行为。如果不正确地设置了传播行为,可能会导致事务失效。例如,如果一个嵌套事务没有使用Propagation.NESTED,则可能会导致外部事务的回滚不起作用。 -
不支持的数据源或驱动程序:确保你的数据源和驱动程序支持事务。某些非关系型数据库或特定的数据库驱动程序可能不支持事务,这会导致事务失效。
-
事务配置错误:Spring Boot的事务管理通常会自动配置,但如果你手动配置了事务管理器(
PlatformTransactionManager)并且配置有误,也会导致事务失效。确保你的事务管理器配置正确。 -
数据访问层不被Spring管理:如果你的数据访问层(DAO)不被Spring容器管理,事务也不会生效。确保DAO组件被Spring管理,或者通过
@Repository注解来标记。 -
数据库引擎不支持事务:某些轻量级数据库引擎或特定的配置可能不支持事务。确保你在使用支持事务的数据库引擎
12.Spring事务用过吧,原理是什么 静态代理原理是什么?
Spring 框架的事务管理是基于 AOP(面向切面编程)和代理模式实现的。下面是 Spring 事务的基本原理:
-
AOP 拦截器: Spring 使用 AOP 拦截器来在方法调用前后添加事务管理的逻辑。这是通过 Spring 的 AOP 模块实现的。
-
代理模式: Spring 创建事务代理,通常是 JDK 动态代理或 CGLIB 代理,用于包装带有
@Transactional注解的方法。这些代理对象会在方法调用前后执行事务管理逻辑。 -
声明式事务配置: 在 Spring 配置文件或 Java 注解中,通过声明式事务配置,开发人员可以定义事务的行为和属性,如传播行为、隔离级别、超时、回滚规则等。
-
Transaction Manager: Spring 配置文件中定义了一个事务管理器(如
PlatformTransactionManager的实现),该事务管理器负责底层事务的管理,如 JDBC 事务或 JTA 事务。 -
事务传播机制: Spring 事务管理允许多个方法按照一定的事务传播机制进行嵌套调用,如 REQUIRED、REQUIRES_NEW、NESTED 等。这使得事务能够嵌套运行,确保了事务的一致性。
-
隐式回滚: 如果在事务方法中抛出受检查异常(Checked Exception)或运行时异常(Unchecked Exception),Spring 会自动回滚事务,保证数据一致性。
-
提交或回滚事务: 当方法执行完毕后,根据事务的状态,事务管理器决定是提交事务还是回滚事务
静态代理是一种代理设计模式,它通过代理类(也称为代理对象)来控制对真实对象的访问。在静态代理中,代理类在编译时就已经创建,它与真实对象实现了相同的接口或继承了相同的类,从而可以代理真实对象的行为。静态代理的原理包括以下几个关键要点:
-
接口或继承: 代理类需要实现与真实对象相同的接口或继承相同的类,以确保代理类和真实对象拥有相同的行为接口。
-
封装真实对象: 代理类包含一个真实对象的引用,它用来调用真实对象的方法。代理类的主要任务是在调用真实对象的方法前后添加额外的逻辑。
-
代理方法: 代理类中的方法实际上是对真实对象方法的包装。在代理方法中,可以在调用真实对象方法前后执行其他操作,如记录日志、性能分析、权限验证等。
-
控制真实对象: 代理类可以控制真实对象的访问,它可以选择性地调用真实对象的方法。这使得代理类可以实现不同的代理逻辑,如延迟加载、事务管理、权限控制等。
-
编译时创建: 静态代理的代理类在编译时就已经创建,并且与真实对象的类型关联,因此无法动态地添加新的代理行为,必须为每个不同的代理逻辑创建一个新的代理类。
9.Spring事务实现原理以及如何获取mysql连接
Spring的事务实现原理主要涉及Spring的事务管理框架和底层的事务管理器,通常与数据库连接相关的事务管理采用Spring的事务管理来进行处理。获取MySQL连接一般使用Spring的DataSource数据源。
Spring事务实现原理:
Spring的事务管理基于AOP(面向切面编程)和标准的Java数据库连接(JDBC)。主要包括以下步骤:
-
标注式事务:Spring允许使用
@Transactional注解在方法上标记事务的边界。在方法开始时,Spring会开启一个事务;在方法结束时,Spring会根据方法的执行情况来提交或回滚事务。 -
事务切面:Spring的AOP模块拦截带有
@Transactional注解的方法,然后在方法执行前后进行事务的管理。 -
事务管理器:Spring的事务管理器(如
PlatformTransactionManager的实现类,如DataSourceTransactionManager)负责实际的事务管理,包括事务的开始、提交、回滚等操作。 -
数据库连接:Spring通过数据源(
DataSource)来获取数据库连接,然后将连接绑定到当前线程,以便在事务中使用。Spring可以配置多种数据源,如C3P0、HikariCP、Tomcat JDBC等。 -
事务同步:Spring使用线程本地变量来保存事务信息,以确保在一个事务中使用同一个数据库连接。
-
事务传播:Spring事务管理允许嵌套事务、事务传播等高级特性。
如何获取MySQL连接:
通常,获取MySQL连接需要进行以下步骤:
- 配置数据源:在Spring的配置文件中配置
DataSource,你可以使用Spring内置的BasicDataSource或其他第三方的数据源,如HikariCP、Apache DBCP、C3P0等。
<bean id="dataSource" class="org.apache.commons.dbcp.BasicDataSource"> <property name="driverClassName" value="com.mysql.jdbc.Driver" /> <property name="url" value="jdbc:mysql://localhost:3306/yourdb" /> <property name="username" value="yourusername" /> <property name="password" value="yourpassword" /> </bean>
- 配置JdbcTemplate:为了更方便地操作数据库,可以使用Spring的
JdbcTemplate来执行SQL语句。配置JdbcTemplate时需要注入DataSource。
<bean id="jdbcTemplate" class="org.springframework.jdbc.core.JdbcTemplate"> <property name="dataSource" ref="dataSource" /> </bean>
- 使用JdbcTemplate:在需要获取数据库连接的地方,注入
JdbcTemplate,然后通过它来执行SQL语句。
@Autowired
private JdbcTemplate jdbcTemplate;
public void performDatabaseOperations() {
jdbcTemplate.update("INSERT INTO your_table (column1, column2) VALUES (?, ?)", value1, value2);
}
Spring会自动管理数据库连接的获取和释放,包括异常处理和事务管理。你只需要关注SQL语句的执行。
7.Springboot如何获得IOC容器
使用注解@Autowired或@Resource:可以在需要访问容器中的Bean的类中使用@Autowired或@Resource注解,将需要的Bean注入到该类中。

实现ApplicationContextAware接口:你可以编写一个类,实现ApplicationContextAware接口,该接口有一个setApplicationContext方法,容器初始化时会自动调用该方法,将容器的ApplicationContext传递给你的类
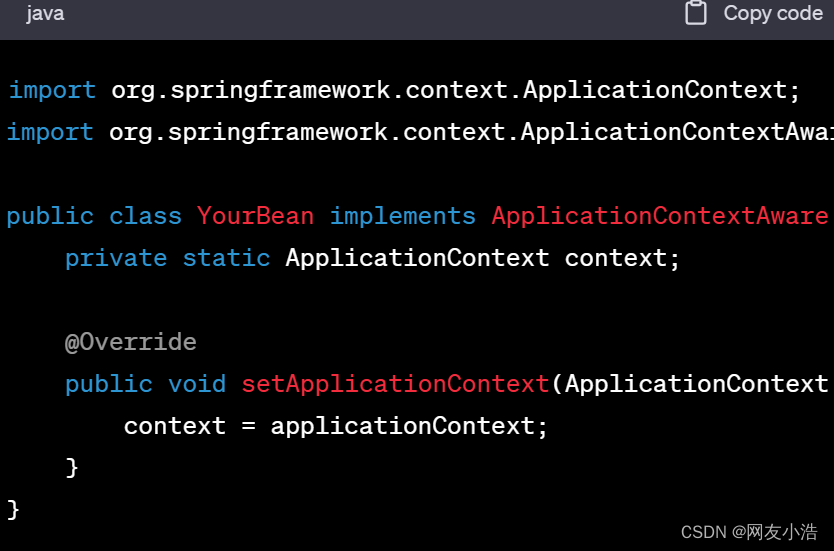
通过静态方法获得ApplicationContext:如果你不想实现ApplicationContextAware接口,也可以通过一个静态方法获得ApplicationContext
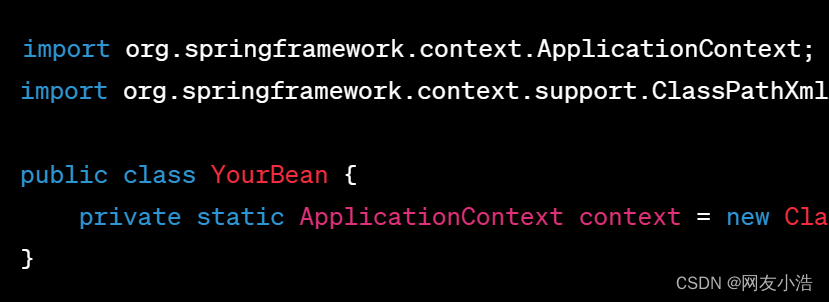
8.Springboot加载文件顺序,不在同个目录下呢?
-
内置默认值(Hard-coded Defaults):Spring Boot会首先加载内置的默认值,这是Spring Boot预定义的配置项。
-
application.properties或application.yml:Spring Boot会加载src/main/resources目录下的application.properties或application.yml文件,这些文件可以用于设置应用程序的全局配置。 -
application-{profile}.properties或application-{profile}.yml:如果定义了激活的profile(如dev、prod等),Spring Boot会尝试加载application-{profile}.properties或application-{profile}.yml文件,这可以用于在不同环境中设置不同的配置项。 -
外部配置文件:你可以通过
spring.config.name和spring.config.location来指定外部的配置文件。外部配置文件的加载顺序取决于它们的指定顺序。你可以使用以下方法来指定外部配置文件的位置:spring.config.name:指定要加载的配置文件名,不包括文件扩展名。例如,如果你想加载myconfig.properties,可以设置spring.config.name=myconfig。spring.config.location:指定加载配置文件的位置。你可以使用file:前缀来指定本地文件的路径,也可以使用classpath:前缀来指定类路径下的文件。多个文件可以通过逗号分隔。
-
其他位置的配置文件:Spring Boot还会加载其他位置的配置文件,例如
/config、/、$HOME/.config等。这些文件的加载顺序也取决于它们的指定顺序。 -
命令行参数:你还可以通过命令行参数来设置配置项。例如,
--server.port=8080将会设置server.port属性的值为8080。
10.Bean生命周期,问了每个流程你具体怎么用的
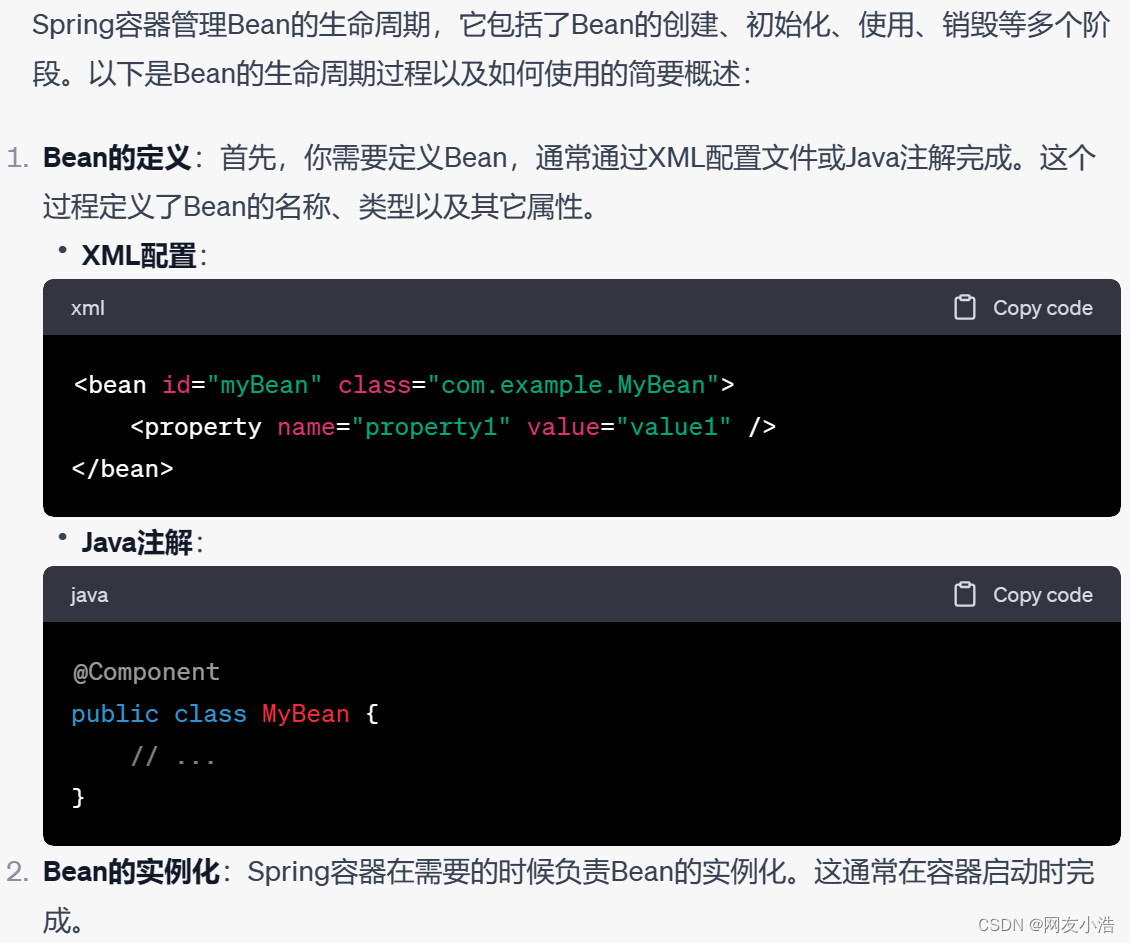
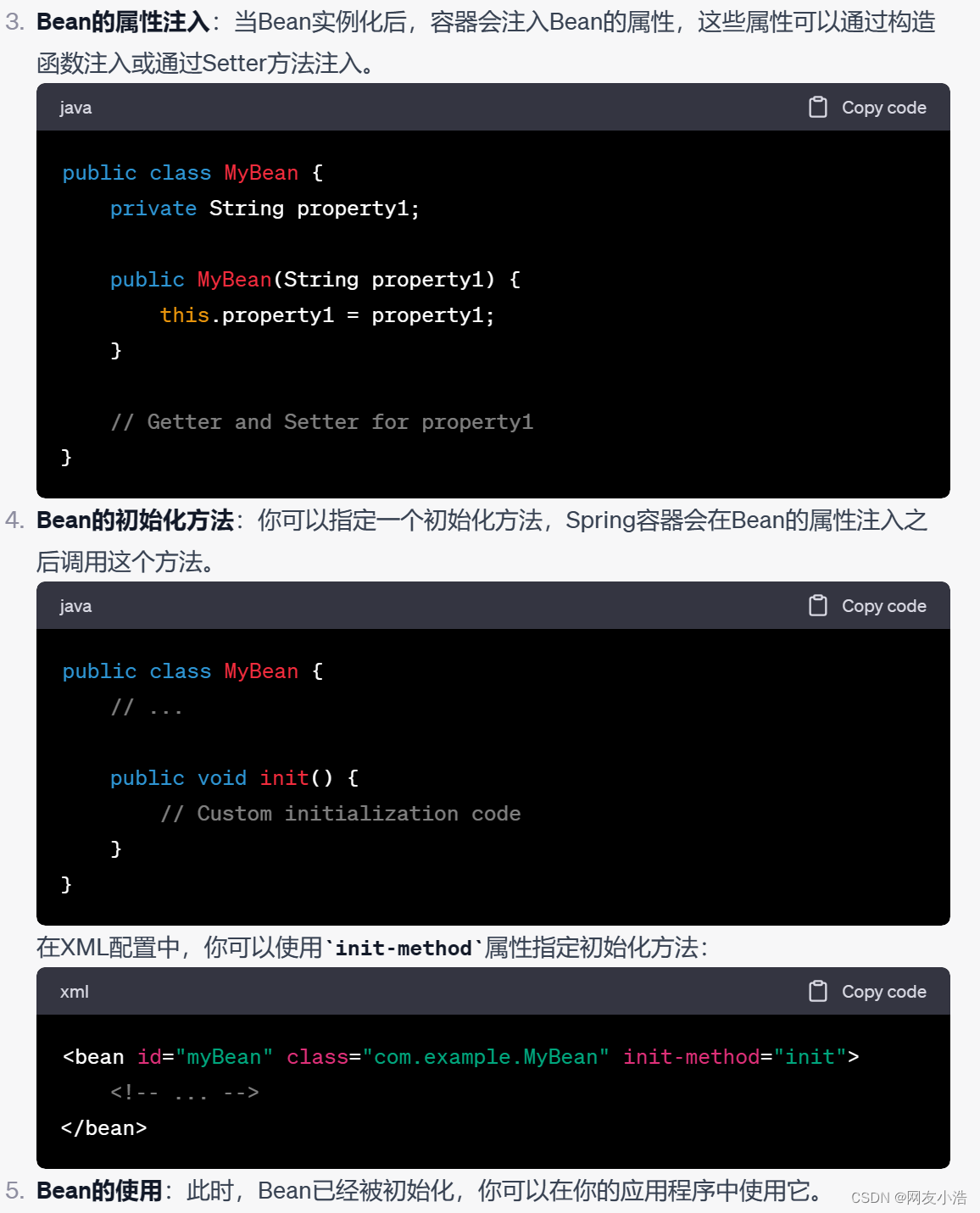
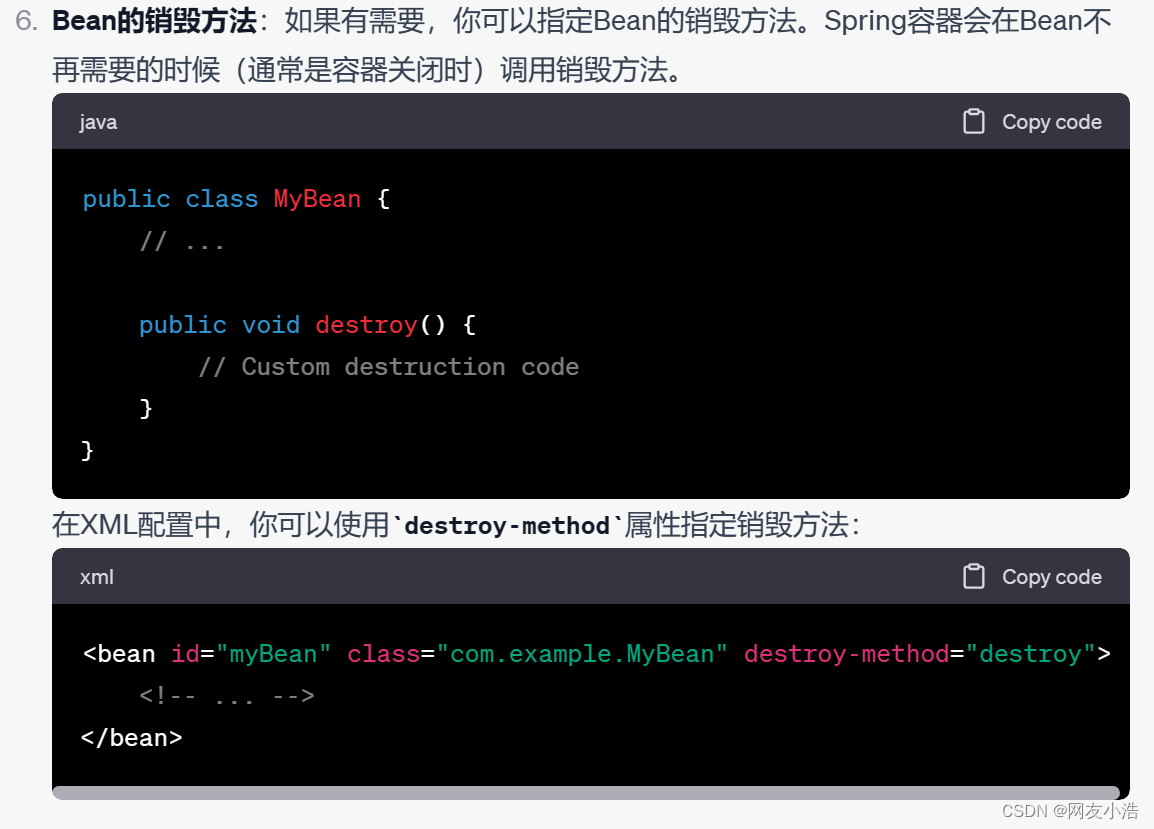
2.SpringBoot中bean的创建过程
Spring Boot基于Spring框架,因此Spring Boot中的Bean创建过程与Spring框架的Bean生命周期非常相似。以下是Spring Boot中Bean的创建过程的简要描述:
-
扫描和组件扫描(Component Scanning):Spring Boot会根据约定扫描应用程序的包以查找带有
@Component注解(例如@Service、@Repository、@Controller等)的类。这些类被认为是Spring Bean的候选者。 -
实例化Bean:当Spring Boot扫描到一个候选的类时,它会创建该类的一个实例,并将其注册到Spring IoC容器中。
-
依赖注入:如果一个Bean依赖于其他Bean,Spring Boot会通过自动装配或
@Autowired注解来注入这些依赖。 -
Bean初始化:如果Bean类中定义了
@PostConstruct注解的方法,该方法将在Bean实例化后立即执行。这可用于执行一些初始化逻辑。 -
使用Bean:应用程序可以使用Spring Boot创建的Bean进行业务操作。
-
Bean销毁:如果Bean类中定义了
@PreDestroy注解的方法,该方法将在Bean被销毁前执行,可用于释放资源或执行清理操作。 -
外部化配置:Spring Boot允许使用
application.properties或application.yml等配置文件来外部化配置Bean的属性。 -
条件化Bean创建:Spring Boot支持条件化Bean创建,可以根据应用的配置属性、环境等条件来决定是否创建某些Bean
2.SpringBoot的循环注入问题如何解决,如何了解到的,有读过源码吗
-
使用三级缓存:Spring使用三级缓存来解决循环依赖问题,这些缓存包括
singletonObjects、earlySingletonObjects和singletonFactories。这些缓存存储Bean的实例、提前暴露的Bean实例和Bean工厂,从而允许Spring容器在循环依赖时找到已创建的Bean实例。 -
合理设计Bean依赖关系:尽量减少Bean之间的复杂依赖关系,通过设计避免直接的循环依赖。合理的依赖注入设计可以降低循环依赖的发生概率。
-
使用构造函数注入:将Bean的依赖关系通过构造函数注入,这有助于更早地发现循环依赖问题。构造函数注入是Spring推荐的依赖注入方式。
-
懒加载和代理:可以将Bean设置为懒加载,以延迟Bean的创建,从而降低循环依赖的概率。此外,Spring AOP代理也可以用于解决一些循环依赖问题。
-
查看日志:Spring框架通常会在日志中记录循环依赖的信息。查看日志可以帮助定位和解决循环依赖问题
13.bean加载过程 如何在装配阶段进行bean的替换?
在Spring中,Bean加载的过程主要包括三个阶段:Bean的定义、Bean的装配、Bean的初始化。
-
Bean的定义:在这一阶段,Spring容器会读取应用程序的配置文件(如XML配置文件或Java配置类)或注解,并将Bean定义信息(如Bean的名称、类型、依赖关系等)加载到内存中。
-
Bean的装配:在这一阶段,Spring容器会根据Bean定义信息,将相应的Bean实例化,并通过依赖注入,将各个Bean之间的关系建立起来。装配包括构造函数注入、属性注入、接口注入等。
-
Bean的初始化:在这一阶段,Spring容器会调用Bean的初始化方法(如
init-method或@PostConstruct注解标记的方法),进行一些额外的设置和准备工作。
如果需要在Bean装配阶段进行Bean的替换,通常可以通过以下方式来实现:
-
BeanPostProcessor:Spring提供了
BeanPostProcessor接口,可以在Bean装配阶段进行拦截和修改Bean的操作。通过实现这个接口,你可以在Bean被实例化、依赖注入完成之后,对Bean进行修改,包括替换成另一个Bean实例。你可以编写一个自定义的BeanPostProcessor,实现postProcessBeforeInitialization方法,根据需要替换Bean的实例。 -
Profile:Spring框架支持配置多个不同的Profile,你可以在不同的Profile中定义不同的Bean,然后在装配阶段根据需要选择使用哪个Profile。通过
@Profile注解和spring.profiles.active配置来指定要激活的Profile。 -
Conditional注解:Spring提供了
@Conditional注解,允许你在装配Bean的时候根据一定条件来决定是否装配某个Bean。你可以根据需要定义一个自定义的条件,根据条件来决定是否装配原有Bean或替换成另一个Bean。
14.MyBatis中#{}和${}的区别
#{}:是预编译的占位符,它会将参数值传递给 SQL 数据库驱动,数据库驱动会将参数值进行转义并插入 SQL 语句中,从而防止 SQL 注入攻击。#{}是安全的,因为参数值不会直接插入 SQL 语句中,而是在执行时通过预编译的方式传递给数据库,因此不会影响 SQL 语句的执行计划。${}:是字符串替换,它会将参数值直接插入 SQL 语句中,如果参数值不经过正确的转义处理,可能会导致 SQL 注入攻击。${}不会进行预编译,因此存在一定的安全风险。
一般来说,推荐使用 #{},因为它能够提供更好的安全性,避免 SQL 注入问题
15.MyBatis中的动态标签
MyBatis 提供了一组动态 SQL 标签,用于在 SQL 映射文件中根据不同条件生成不同的 SQL 语句,从而实现动态 SQL。以下是一些常见的 MyBatis 动态标签:
<if>:如果条件为真,则包含标签体的内容。<choose>:类似于 switch-case,根据条件选择执行不同的分支。<when>:用于<choose>中,定义一个条件分支。<otherwise>:用于<choose>中,定义条件不满足时的默认分支。<trim>:用于去掉生成 SQL 语句的多余部分,如多余的逗号或 AND/OR 连接词。<set>:用于设置列的值,常用于 UPDATE 语句。<foreach>:用于遍历集合或数组,生成循环执行的 SQL
16.MyBatis的一级缓存和二级缓存
MyBatis 的动态标签提供了强大的灵活性,能够根据不同条件生成不同的 SQL,使 SQL 映射文件更易于维护和扩展。
一级缓存和二级缓存是 MyBatis 中的缓存机制:
- 一级缓存:也被称为本地缓存,它是默认开启的,且与 SqlSession 绑定。在同一个 SqlSession 中,执行相同的查询将从缓存中获取结果,而不需要再次查询数据库。一级缓存的作用范围仅限于单个 SqlSession。
- 二级缓存:是跨 SqlSession 的缓存,它可以存储多个 SqlSession 共享的查询结果。如果多个 SqlSession 执行相同的查询,结果可以从二级缓存中获取,而不需要重复查询数据库。二级缓存的作用范围是整个应用程序。默认情况下,二级缓存是禁用的,需要在 MyBatis 配置文件中手动启用。
17.用到gateWay是吧。gateWay如何实现url重写?
Spring Cloud Gateway 是一个基于 Spring Boot 的网关解决方案,它支持 URL 重写。你可以使用 Spring Cloud Gateway 来实现 URL 重写,通常是通过配置路由规则和 Predicates(谓词)来实现。谓词可以用来匹配请求的条件,然后根据匹配的条件重写 URL。以下是一个简单的示例:
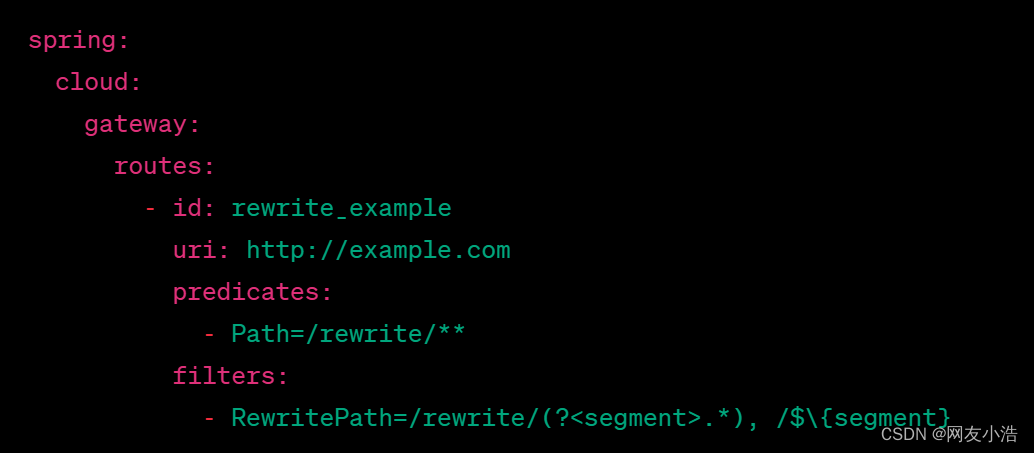
上述配置表示当请求的路径以 /rewrite/ 开头时,Gateway 会将请求转发到 http://example.com/,并且会重写 URL,去掉 /rewrite/ 前缀。这样可以实现 URL 重写
18.maven会用吧,说一下依赖传递性?
Maven 是 Java 项目的构建工具,它负责管理项目依赖、构建项目、运行测试、打包发布等任务。Maven 中的依赖传递性是指当一个项目依赖另一个项目时,它会自动获取并加载被依赖项目的依赖项。这意味着如果项目 A 依赖项目 B,而项目 B 依赖项目 C,那么项目 A 会间接依赖项目 C,Maven 会自动帮助你下载和管理项目 C 的依赖。
这种依赖传递性有助于简化项目构建和管理,因为你不需要手动管理所有依赖项,而是让 Maven 自动解析和下载它们。你只需声明你的直接依赖,Maven 就会处理其余的
过滤器和拦截器有什么区别?拦截器主要作用?两者那个范围更大?过滤器是如何实现的?
在Java中,过滤器(Filter)和拦截器(Interceptor)是用于在Web应用中进行请求和响应的处理和干预的两种不同机制。它们有以下区别:
-
范围:
- 过滤器:过滤器是Servlet规范中定义的组件,通常用于处理HTTP请求和响应。它的范围更广,可以拦截和处理所有Web请求,包括Servlet、JSP、静态资源等。
- 拦截器:拦截器是Spring框架中的概念,用于拦截Spring MVC中的Controller处理器方法。拦截器主要用于对控制器层的请求进行处理,因此其范围相对较小。
-
实现方式:
- 过滤器:过滤器是Java Servlet API的一部分,它需要在
web.xml文件中进行配置,并实现javax.servlet.Filter接口,然后通过过滤器链按照顺序处理请求。 - 拦截器:拦截器是Spring框架的一部分,通常在Spring配置文件中进行配置,然后实现
HandlerInterceptor接口。它通过Spring的拦截器链来处理请求。
- 过滤器:过滤器是Java Servlet API的一部分,它需要在
-
主要作用:
- 过滤器:过滤器主要用于请求和响应的通用处理,如日志记录、字符编码转换、权限验证等。它可以修改请求和响应,但通常无法获取到具体的Controller方法的信息。
- 拦截器:拦截器主要用于处理Controller层的请求,它可以访问到具体的Controller方法和方法参数,从而进行更精细的处理,如身份验证、参数预处理、日志记录等。
-
调用顺序:
- 过滤器:多个过滤器按照在
web.xml中的配置顺序依次执行,可以有多个过滤器链。 - 拦截器:Spring中的拦截器按照配置顺序执行,每个拦截器可以对请求进行前置处理、后置处理和完成处理。
- 过滤器:多个过滤器按照在
-
框架依赖:
- 过滤器:与Servlet容器直接相关,不依赖于任何特定的框架。
- 拦截器:依赖于Spring框架,通常与Spring MVC一起使用
常见设计模式,答了工厂和单例,然后深问单例模式?
-
饿汉式单例:
- 应用场景:适用于实例创建开销较小且在应用启动时就需要使用的情况。
- 区别:在类加载时就创建实例,天然线程安全,但可能浪费资源。
-
懒汉式单例:
- 应用场景:适用于实例创建开销较大或需要延迟加载的情况。
- 区别:在首次访问时创建实例,需要进行同步处理以确保线程安全。
-
双重检查锁定:
- 应用场景:适用于需要延迟加载的情况,同时希望保持高性能。
- 区别:通过两次检查锁定来保证线程安全,兼顾了性能和延迟加载。
-
静态内部类:
- 应用场景:适用于需要延迟加载,同时要保持线程安全的情况。
- 区别:利用Java类加载的机制,保证了线程安全和延迟加载。
-
枚举单例:
- 应用场景:适用于最简单、线程安全且易于实现的单例模式。
- 区别:通过枚举类型来实现,天然线程安全,且实现简单。
-
容器管理单例:
- 应用场景:适用于大型应用框架,如Spring,提供了IoC容器管理单例的方式。
- 区别:通过容器管理,可以动态配置单例的创建和生命周期。
选择合适的单例模式应该依赖于具体的应用需求和性能要求。通常来说,饿汉式和静态内部类单例是比较常用的,它们既能确保线程安全,又能实现延迟加载,适用于多数情况。如果对性能要求比较高,双重检查锁定方式是一个不错的选择。枚举单例是最简单和安全的方式,也是一种良好的选择。容器管理单例则适用于大型框架和应用
序列化? 反序列化的理解? 什么时候需要用到? 怎么用? 为什么要指定UID 为什么我序列化后插入一个数据后反序列化有什么问题 ?为什么有这个问题?为什么你说uid不指定就会出现这个问题?
1.序列化是将对象的状态转换为字节序列的过程,通常用于将对象持久化到磁盘或通过网络传输。反之,反序列化是将字节序列恢复为对象的状态的过程。
2.在Java中,序列化和反序列化是通过java.io.Serializable接口来实现的。当一个类实现Serializable接口时,它的对象可以被序列化,将其转换为字节序列,并在需要时反序列化以还原为对象。这通常用于对象的持久化、跨系统的数据传输以及缓存等情况。
3.UID(版本号)在Java序列化中是一个用于版本控制的重要机制。每个可序列化类都有一个唯一的UID,它可以手动指定,也可以自动生成。如果不指定UID,Java会自动生成一个基于类结构的UID。当你反序列化一个对象时,Java会使用类的UID和字节流中的UID进行比较,如果不匹配,则会抛出InvalidClassException,表明类结构已经改变,无法反序列化旧的数据。
4.如果你在对象已经序列化后对类进行了修改,例如添加了新的字段,那么反序列化时可能会出现问题。这是因为新的字段在旧的序列化数据中没有对应的数值,反序列化时会导致字段丢失或赋予默认值。为了避免这个问题,可以手动指定UID,并在类变化时更新UID,或使用@SuppressWarnings("serial")来禁止编译器生成默认UID。这样,当类结构发生变化时,反序列化会忽略丢失的字段,而不会导致异常;
















 4118
4118











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











