






1.阿里云的DataV无法实时展示:
在这个时候我的sql里的数据都是在实时变化的,但是Datav数据不能实时变化,有以下两点原因:
在数据库设置中,需要设置数据每秒自动请求:
除此之外,不能使用全局变量去获取数据:
2.在idea中,无法连接到外部的kafka:
无论是直接使用ip还是使用localhost都无法找到外部的idea:
 在后来在host文件中配置了kafka1:172.0.0.1后,发现连接成功:
在后来在host文件中配置了kafka1:172.0.0.1后,发现连接成功:
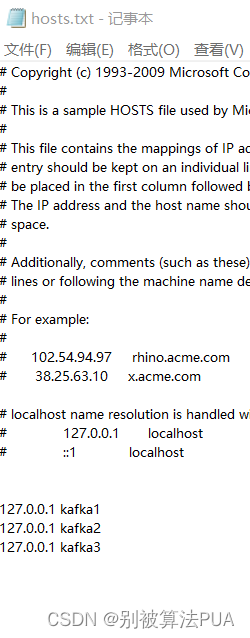
配置后发现,无论是使用localhost还是使用kafka1,2,3都可以连接到了。这很奇怪,因为直接使用localhost本质上就是使用172.0.0.1,使用kafka1,2,3也是使用172.0.0.1.但为什么配置以上的内容之后就可以?
3.storm集群搭建问题
使用docker-compose.yaml文件之后,strom无法连接到zookeeper集群:

这时需要去storm.yaml文件中更改配置文件,手动的将storm与zookeeper连接上

4.storm集群的搭建出现问题,具体参考:docker-compose搭建storm、zookeeper集群,解决Could not find leader nimbus from seed hosts [localhost]问题-CSDN博客
5.重复读取消息队列中的内容,在将新生产的消息消费完成之后,offset(偏移量)又会到一个之前已经消费过的地方开始继续消费,导致一直能有消息在进行消费:

在配置中,配置以上的内容都发现没有用,仍然有这个问题,之后,借鉴了相关的代码:
package orderdetail;
// -*- codeing: utf-8 -*-
// @Time :2021/12/12 19:28
// @Author :李壮壮
//@File :KfakaStormTopology.java
//@Software : IntelliJ IDEA
import kafka.api.OffsetRequest;
import org.apache.storm.Config;
import org.apache.storm.LocalCluster;
import org.apache.storm.StormSubmitter;
import org.apache.storm.generated.StormTopology;
import org.apache.storm.kafka.BrokerHosts;
import org.apache.storm.kafka.KafkaSpout;
import org.apache.storm.kafka.SpoutConfig;
import org.apache.storm.kafka.ZkHosts;
import org.apache.storm.topology.BasicOutputCollector;
import org.apache.storm.topology.OutputFieldsDeclarer;
import org.apache.storm.topology.TopologyBuilder;
import org.apache.storm.topology.base.BaseBasicBolt;
import org.apache.storm.tuple.Tuple;
/**
* Kafka和storm的整合,用于统计实时流量对应的pv和uv
*/
public class KfakaStormTopology {
// static class MyKafkaBolt extends BaseRichBolt {
static class MyKafkaBolt extends BaseBasicBolt {
/**
* kafkaSpout发送的字段名为bytes
*/
@Override
public void execute(Tuple input, BasicOutputCollector collector) {
byte[] binary = input.getBinary(0); // 跨jvm传输数据,接收到的是字节数据
// byte[] bytes = input.getBinaryByField("bytes"); // 这种方式也行
String line = new String(binary);
System.out.println(line);
}
@Override
public void declareOutputFields(OutputFieldsDeclarer declarer) {
}
}
public static void main(String[] args) throws Exception {
TopologyBuilder builder = new TopologyBuilder();
/**
* 设置spout和bolt的dag(有向无环图)
*/
KafkaSpout kafkaSpout = createKafkaSpout();
builder.setSpout("id_kafka_spout", kafkaSpout);
builder.setBolt("id_kafka_bolt", new KfakaStormTopology.MyKafkaBolt())
.shuffleGrouping("id_kafka_spout"); // 通过不同的数据流转方式,来指定数据的上游组件
// 使用builder构建topology
StormTopology topology = builder.createTopology();
String topologyName = storm.KafkaStormTopology.class.getSimpleName(); // 拓扑的名称
Config config = new Config(); // Config()对象继承自HashMap,但本身封装了一些基本的配置
// 启动topology,本地启动使用LocalCluster,集群启动使用StormSubmitter
if (args == null || args.length < 1) { // 没有参数时使用本地模式,有参数时使用集群模式
LocalCluster localCluster = new LocalCluster(); // 本地开发模式,创建的对象为LocalCluster
localCluster.submitTopology(topologyName, config, topology);
} else {
StormSubmitter.submitTopology(topologyName, config, topology);
}
}
private static KafkaSpout createKafkaSpout() {
String brokerZkStr = "192.168.145.141:2181,192.168.145.142:2181,192.168.145.143:2181";
BrokerHosts hosts = new ZkHosts(brokerZkStr); // 通过zookeeper中的/brokers即可找到kafka的地址
String topic = "orderdetail";//要消费的topic主题
String zkRoot = "/" + topic;//kafka在zk中的目录(会在该节点目录下记录读取kafka消息的偏移量)
String id = "consumer-id";//当前操作的标识id
SpoutConfig spoutConf = new SpoutConfig(hosts, topic, zkRoot, id);
spoutConf.startOffsetTime = OffsetRequest.LatestTime(); // 设置之后,刚启动时就不会把之前的消费也进行读取,会从最新的偏移量开始读取
return new KafkaSpout(spoutConf);
}
}
如上,是使用手动计算当前的偏移量。















 3440
3440











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









