






实验内容:把隐马尔可夫模型和结构化感知机用于中文分词和词性标注。
基于序列标注的中文分词:输入的是字符序列,输出的是字符的构词位置标签
{B,M,E,S}
基于序列标注的词性标注:输入的是单词序列,输出的是词性标签{名词,动词,
形容词,…}。
首先导入 pyhanlp:
from pyhanlp import *
1. 基于隐马尔可夫模型的中文分词
代码参见:《自然语言处理入门》随书代码
\hanlp-python\pyhanlp\tests\book\ch04\hmm_cws.py。
要求:
- 将 hmm_cws.py 改为对下面句子进行分词测试,并输出分词结果:
结婚的和尚未结婚的确实在干扰分词啊
随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这
块也不能完全忽略掉。
歼-10 飞机拉出七道绚丽的彩烟,庆祝新中国成立 70 周年
这样的人才能经受住考验
将信息技术应用于教学实践
人要是行,干一行行一行一行行行行行要是不行干一行不行一行一行不行行行不
行
四川人用普通话与川普通电话
他说的确实在理
实验代码:
# -*- coding:utf-8 -*-
# Author:hankcs
# Date: 2018-06-19 14:33
# 《自然语言处理入门》4.6 隐马尔可夫模型应用于中文分词
# 配套书籍:http://nlp.hankcs.com/book.php
# 讨论答疑:https://bbs.hankcs.com/
from pyhanlp import *
from eval_bigram_cws import CWSEvaluator
from msr import msr_dict, msr_train, msr_model, msr_test, msr_output, msr_gold
FirstOrderHiddenMarkovModel = JClass('com.hankcs.hanlp.model.hmm.FirstOrderHiddenMarkovModel')
SecondOrderHiddenMarkovModel = JClass('com.hankcs.hanlp.model.hmm.SecondOrderHiddenMarkovModel')
HMMSegmenter = JClass('com.hankcs.hanlp.model.hmm.HMMSegmenter')
def train(corpus, model):
segmenter = HMMSegmenter(model)
segmenter.train(corpus)
print(segmenter.segment('商品和服务'))
print(segmenter.segment('结婚的和尚未结婚的确实在干扰分词啊 '))
print(segmenter.segment('随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这块也不能完全忽略掉。'))
print(segmenter.segment('歼-10 飞机拉出七道绚丽的彩烟,庆祝新中国成立 70 周年'))
print(segmenter.segment('这样的人才能经受住考验 '))
print(segmenter.segment('将信息技术应用于教学实践 '))
print(segmenter.segment('人要是行,干一行行一行一行行行行行要是不行干一行不行一行一行不行行行不行 '))
print(segmenter.segment('四川人用普通话与川普通电话'))
print(segmenter.segment('他说的确实在理 '))
return segmenter.toSegment()
def evaluate(segment):
result = CWSEvaluator.evaluate(segment, msr_test, msr_output, msr_gold, msr_dict)
print(result)
if __name__ == '__main__':
segment = train(msr_train, FirstOrderHiddenMarkovModel())
evaluate(segment)
segment = train(msr_train, SecondOrderHiddenMarkovModel())
evaluate(segment)
实验结果截图:
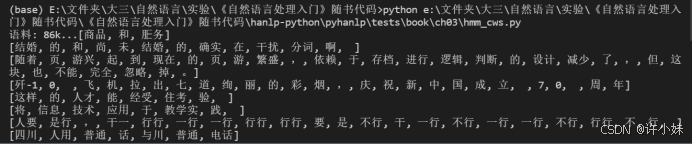

实验结果分析:
通过一阶、二阶隐马尔夫模型对于测试语句的分词结果,两个的分词结果不一样。
- 指出上述句子中分错词的地方,并分析出错原因(选其中两个出错句子分析)。
- 结婚的和尚未结婚的确实在干扰分词啊,对于一阶隐马尔可夫模型来说分词结果是可以接受的,但二阶隐马尔可夫模型的分词结果就存在有误的地方,分词结果跟预期的结果有很大的不同,一阶隐马尔可夫模型(First Order Hidden Markov Model)是一种基本的隐马尔可夫模型,在分词任务中主要考虑当前字的上下文。它假设每个字的状态只依赖于前一个字的状态,与更早之前的状态无关。二阶隐马尔可夫模型(Second Order Hidden Markov Model)在分词任务中考虑了更长的上下文信息。它假设每个字的状态不仅依赖于前一个字的状态,还依赖于前两个字的状态。
- 这样的人才能经受住考验的分析结果预期与结婚的和尚未结婚的确实在干扰分词啊的结果分析一样。
注:
1. HMM 的训练依旧在 msr 库进行,但不在 msr 库上测试,故不需执行
hmm_cws.py 中的 evaluate(segment)。
如果只需要进行HMM的训练而不需要在msr库上进行测试,可以不执行hmm_cws.py中的evaluate(segment)函数。通常情况下,模型的训练和测试是分离的步骤,你可以根据需要选择执行相应的代码。在HMM的训练过程中,主要会使用训练数据对模型的参数进行估计,例如计算转移概率、发射概率和初始概率等。你可以确保在训练代码中只包含与训练相关的逻辑,并且忽略掉与测试相关的代码,这样就可以只进行模型的训练而不需要进行测试。
2. 一阶、二阶隐马尔可夫模型均要运行(即调用 FirstOrderHiddenMarkovModel()
和 SecondOrderHiddenMarkovModel()),对比两者的分词结果的异同。
一阶隐马尔可夫模型(First Order Hidden Markov Model)是一种基本的隐马尔可夫模型,在分词任务中主要考虑当前字的上下文。它假设每个字的状态只依赖于前一个字的状态,与更早之前的状态无关。在进行分词时,一阶隐马尔可夫模型只考虑当前字与其前一个字之间的转移概率,不考虑更远的上下文。因此,它可能无法捕捉到更复杂的语义信息,会出现分词效果不佳的情况。
二阶隐马尔可夫模型(Second Order Hidden Markov Model)在分词任务中考虑了更长的上下文信息。它假设每个字的状态不仅依赖于前一个字的状态,还依赖于前两个字的状态。在进行分词时,二阶隐马尔可夫模型会考虑当前字与其前两个字之间的转移概率,以及前两个字与当前字之间的发射概率。相比于一阶模型,二阶模型能够更好地捕捉到字与字之间的语义关系,因此在一些复杂的语言环境下,它可能有更好的分词效果。
2. 基于结构化感知机的中文分词
代码参见:《自然语言处理入门》随书代码
\hanlp-python\pyhanlp\tests\book\ch05\perceptron_cws.py。
实验代码:
# -*- coding:utf-8 -*-
# Author:hankcs
# Date: 2018-06-22 15:18
# 《自然语言处理入门》5.6 基于结构化感知机的中文分词
# 配套书籍:http://nlp.hankcs.com/book.php
# 讨论答疑:https://bbs.hankcs.com/
from pyhanlp import *
from eval_bigram_cws import CWSEvaluator
from msr import msr_train, msr_model, msr_dict, msr_gold, msr_output, msr_test
CWSTrainer = JClass('com.hankcs.hanlp.model.perceptron.CWSTrainer')
def train_uncompressed_model():
model = CWSTrainer().train(msr_train, msr_train, msr_model, 0., 10, 8).getModel() # 训练模型
model.save(msr_train, model.featureMap.entrySet(), 0, True) # 最后一个参数指定导出txt
def train():
model = CWSTrainer().train(msr_train, msr_model).getModel() # 训练模型
segment = PerceptronLexicalAnalyzer(model).enableCustomDictionary(False) # 创建分词器
return segment
# print(CWSEvaluator.evaluate(segment, msr_test, msr_output, msr_gold, msr_dict)) # 标准化评测
if __name__ == '__main__':
segment = train()
sents = [
"王思斌,男,1949年10月生。",
"山东桓台县起凤镇穆寨村妇女穆玲英",
"现为中国艺术研究院中国文化研究所研究员。",
"我们的父母重男轻女",
"北京输气管道工程",
]
for sent in sents:
print(segment.seg(sent))
# train_uncompressed_model()
- 比较与基于隐马尔可夫模型的分词结果的异同。
(1)模型结构不同:结构化感知机是一种判别模型,它直接学习了输入序列和目标序列之间的条件概率分布,将分词过程作为一个序列标注的问题。而HMM是一个生成模型,它对于给定的输入序列,通过学习转移概率和发射概率来描述序列的生成过程。
(2)上下文建模不同:结构化感知机可以灵活地考虑更多的局部和全局上下文信息,通过特征函数来建模。相比之下,HMM在分词过程中通常只考虑当前字与其前一个字之间的转移概率,以及字与标签之间的发射概率。
(3)训练方法不同:结构化感知机使用结构化的感知机算法进行训练,通过迭代优化模型参数使得模型的预测结果尽可能接近于真实结果。HMM则是通过训练数据的统计信息来估计模型的参数。
3. 基于隐马尔可夫模型的词性标注
代码参见:《自然语言处理入门》随书代码\hanlp-python\pyhanlp\tests\book\ch07\demo_hmm_pos.py。
要求:
1. 将 demo_hmm_pos.py 改为对下面句子的分词结果进行词性标注,并输出标注结果:
结婚的和尚未结婚的确实在干扰分词啊
随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这
块也不能完全忽略掉。
歼-10 飞机拉出七道绚丽的彩烟,庆祝新中国成立 70 周年
这样的人才能经受住考验
将信息技术应用于教学实践
人要是行,干一行行一行一行行行行行要是不行干一行不行一行一行不行行行不
行
四川人用普通话与川普通电话
他说的确实在理
实验代码:
# -*- coding:utf-8 -*-
# Author:hankcs
# Date: 2018-07-04 17:34
# 《自然语言处理入门》7.3.1 基于隐马尔可夫模型的词性标注
# 配套书籍:http://nlp.hankcs.com/book.php
# 讨论答疑:https://bbs.hankcs.com/
from pyhanlp import *
from pku import PKU199801_TRAIN
HMMPOSTagger = JClass('com.hankcs.hanlp.model.hmm.HMMPOSTagger')
AbstractLexicalAnalyzer = JClass('com.hankcs.hanlp.tokenizer.lexical.AbstractLexicalAnalyzer')
PerceptronSegmenter = JClass('com.hankcs.hanlp.model.perceptron.PerceptronSegmenter')
FirstOrderHiddenMarkovModel = JClass('com.hankcs.hanlp.model.hmm.FirstOrderHiddenMarkovModel')
SecondOrderHiddenMarkovModel = JClass('com.hankcs.hanlp.model.hmm.SecondOrderHiddenMarkovModel')
def train_hmm_pos(corpus, model):
tagger = HMMPOSTagger(model) # 创建词性标注器
tagger.train(corpus) # 训练
print(', '.join(tagger.tag("他", "的", "希望", "是", "希望", "上学"))) # 预测
analyzer = AbstractLexicalAnalyzer(PerceptronSegmenter(), tagger) # 构造词法分析器
print(analyzer.analyze("结婚的和尚未结婚的确实在干扰分词啊 ")) # 分词+词性标注
print(analyzer.analyze("随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这块也不能完全忽略掉。"))
print(analyzer.analyze("歼-10 飞机拉出七道绚丽的彩烟,庆祝新中国成立 70周年"))
print(analyzer.analyze("这样的人才能经受住考验 "))
print(analyzer.analyze("将信息技术应用于教学实践 "))
print(analyzer.analyze("人要是行,干一行行一行一行行行行行要是不行干一行不行一行一行不行行行不行 "))
print(analyzer.analyze("四川人用普通话与川普通电话 "))
print(analyzer.analyze("他说的确实在理 "))
return tagger
if __name__ == '__main__':
tagger = train_hmm_pos(PKU199801_TRAIN, FirstOrderHiddenMarkovModel())
tagger = train_hmm_pos(PKU199801_TRAIN, SecondOrderHiddenMarkovModel()) # 或二阶隐马
4. 基于结构化感知机的词性标注
代码参见:《自然语言处理入门》随书代码
\hanlp-python\pyhanlp\tests\book\ch07\demo_perceptron_pos.py。
要求:
1. 将 demo_perceptron_pos.py 改为对下面句子的分词结果进行词性标注,并输出标注结果:
结婚的和尚未结婚的确实在干扰分词啊
随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这
块也不能完全忽略掉。歼-10 飞机拉出七道绚丽的彩烟,庆祝新中国成立 70 周年
这样的人才能经受住考验
将信息技术应用于教学实践
人要是行,干一行行一行一行行行行行要是不行干一行不行一行一行不行行行不
行
四川人用普通话与川普通电话
他说的确实在理
实验代码:
# -*- coding:utf-8 -*-
# Author:hankcs
# Date: 2018-07-05 10:19
# 《自然语言处理入门》7.3.2 基于感知机的词性标注
# 配套书籍:http://nlp.hankcs.com/book.php
# 讨论答疑:https://bbs.hankcs.com/
from pyhanlp import *
from demo_hmm_pos import AbstractLexicalAnalyzer, PerceptronSegmenter
from pku import PKU199801_TRAIN, POS_MODEL
POSTrainer = JClass('com.hankcs.hanlp.model.perceptron.POSTrainer')
PerceptronPOSTagger = JClass('com.hankcs.hanlp.model.perceptron.PerceptronPOSTagger')
def train_perceptron_pos(corpus):
trainer = POSTrainer()
trainer.train(corpus, POS_MODEL) # 训练
tagger = PerceptronPOSTagger(POS_MODEL) # 加载
print(', '.join(tagger.tag("他", "的", "希望", "是", "希望", "上学"))) # 预测
analyzer = AbstractLexicalAnalyzer(PerceptronSegmenter(), tagger) # 构造词法分析器
print(analyzer.analyze("李狗蛋的希望是希望上学")) # 分词+词性标注
print(analyzer.analyze("结婚的和尚未结婚的确实在干扰分词啊 ")) # 分词+词性标注
print(analyzer.analyze("随着页游兴起到现在的页游繁盛,依赖于存档进行逻辑判断的设计减少了,但这块也不能完全忽略掉。"))
print(analyzer.analyze("歼-10 飞机拉出七道绚丽的彩烟,庆祝新中国成立 70周年"))
print(analyzer.analyze("这样的人才能经受住考验 "))
print(analyzer.analyze("将信息技术应用于教学实践 "))
print(analyzer.analyze("人要是行,干一行行一行一行行行行行要是不行干一行不行一行一行不行行行不行 "))
print(analyzer.analyze("四川人用普通话与川普通电话 "))
print(analyzer.analyze("他说的确实在理 "))
return tagger
if __name__ == '__main__':
train_perceptron_pos(PKU199801_TRAIN)
实验结果截图:
2. 指出上述句子中词性标注有错的地方,并分析出错原因(选其中两个出错句
子分析)。
“人要是行,干一行行一行一行行行行行要是不行干一行不行一行一行不行行行不行 、四川人用普通话与川普通电话 ”特征选择不当:结构化感知机依赖于定义的特征来进行预测,如果选取的特征无法充分反映词性的信息,或者存在冗余的特征,都会影响模型的性能。上下文信息不足:类似于隐马尔可夫模型,结构化感知机也只考虑了有限长度的上下文信息,对于复杂的语境可能无法准确判断词性。
3.比较与基于隐马尔可夫模型的词性标注结果的异同。
- 算法原理不同:结构化感知机是基于条件随机场(CRF)算法的一种变种,其目标是最大化标注序列的分数,而隐马尔可夫模型则是一种基于统计的序列建模方法,旨在寻找最可能的隐含状态序列和可见状态序列之间的关系。
- 模型复杂度不同:基于结构化感知机的词性标注模型通常需要更多的训练数据和计算资源,以获得更高的准确度;而基于隐马尔可夫模型的标注模型相对简单,在小规模数据集上也能取得较好的效果。
- 特征抽取方式不同:结构化感知机通常采用更加丰富的特征来描述词性标注问题,例如词形、上下文等,而隐马尔可夫模型通常使用离散化的观测特征、转移特征、状态特征等。
代码阅读心得
对基于结构化感知机的词性标注代码理解,在代码实现中,特征提取是一个非常重要的环节。通过合理的特征选择和提取,可以有效提高模型的准确性。常见的特征包括基于上下文的特征(如前一词、后一词的词性)、基于词本身的特征(如词长、词首字母、是否含有数字等)以及基于词性转移的特征。结构化感知机的损失函数通常采用了与感知机算法类似的形式,即使用最大间隔来区分正确标注和错误标注之间的边界。这种损失函数可以有效避免过拟合,提高模型的泛化能力。结构化感知机需要使用解码算法来预测整个序列的标注结果。常见的解码算法包括维特比算法和基于动态规划的算法。这些算法的复杂度通常较高,需要在考虑准确性和效率之间做出权衡。在实际应用中,往往需要对训练数据进行预处理,包括分词、词性标注等操作。
问题并解决:
1. 在实验中遇到预想之外的问题(比如得到的 NLP 处理效果与预期不同,或者
程序运行时出现了错误提示),自己找到原因,并想到办法加以解决。 
对于这类问题解决是路径的指定问题,只要将程序放在同一个文件夹内便可以很好的运行该实验。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









