







- 《C程序设计语言》学习课程:《跟着星仔学C》课程链接:02_0300 2.7类型转换_哔哩哔哩_bilibili
- xingzaicpp的cnblogs:《跟着星仔学C语言》简介 - xingzaicpp - 博客园
- xingzaicpp的个人空间-xingzaicpp个人主页-哔哩哔哩视频 b站上面备注为:北邮
- 下一个课程学习:《C++ primer》按着学习 bilibili有课程。 课程链接:C++第二阶段教程:C++ Primer第五版视频教程_哔哩哔哩_bilibili

chap1 导言
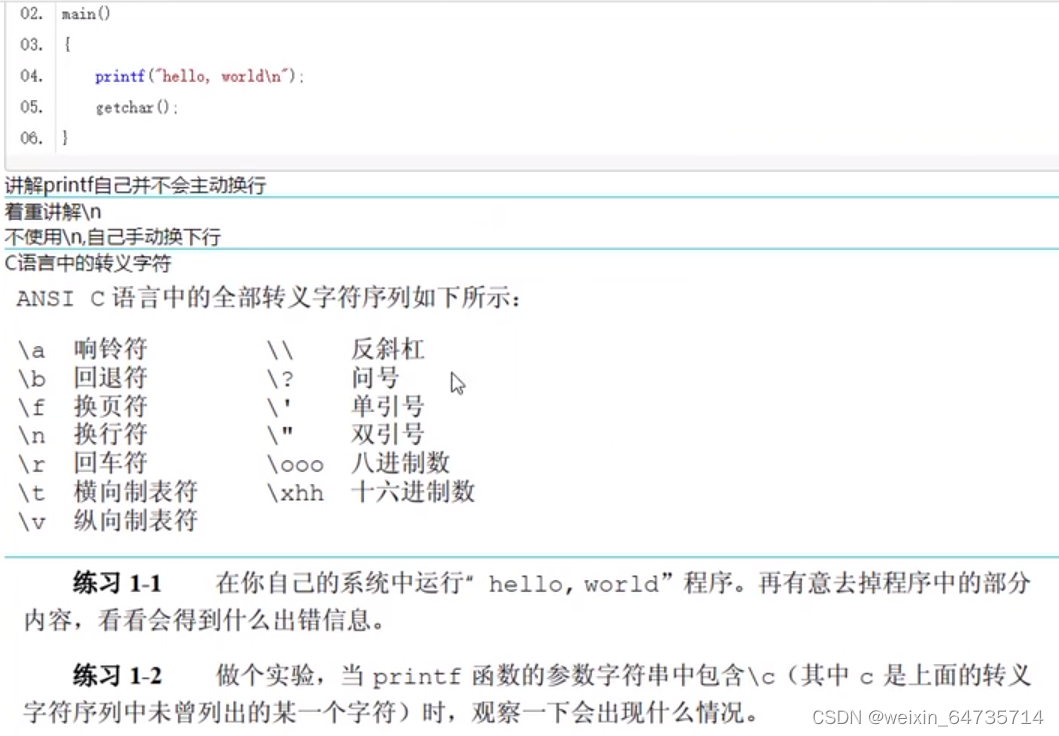
- linux: cc main.c; make main.c; gcc main.c 生成a.out;-o 可以指定生成的文件名称。
- windows vs2015文本格式为:『带BOM的utf8』 ;uft8是linux可以识别的格式。
- windows vs2015文本格式为:『ANSI』

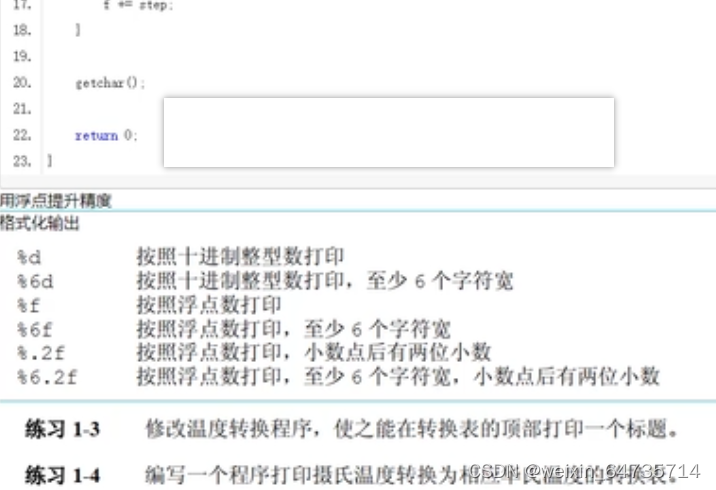
符号常量的使用

- windows下EOF:Ctrl+Z;
- linux下EOF:Ctrl+D

- 后面自己都忘了,是啥写法。简洁、易懂,易维护为主。
- getchar只有看到回车,才下发。行缓冲。只遇到回车时,才一次getchar.
- OutputDebugStringA是可以在控制台输出一些信息,不需要使用QDebug就可以在控制台输出信息的。
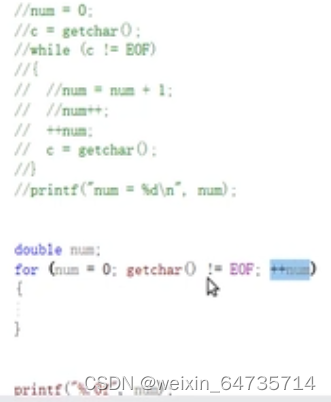
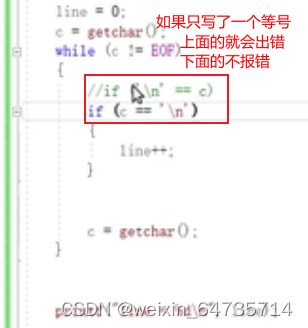
看见一个/n就认为是换行。
这样在编译阶段就会报错。写成:'\n' = c,写错了,就会报错;判断语句



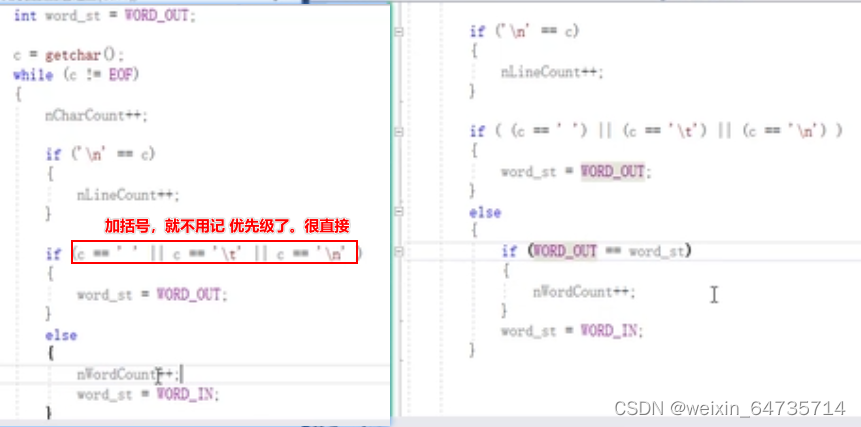
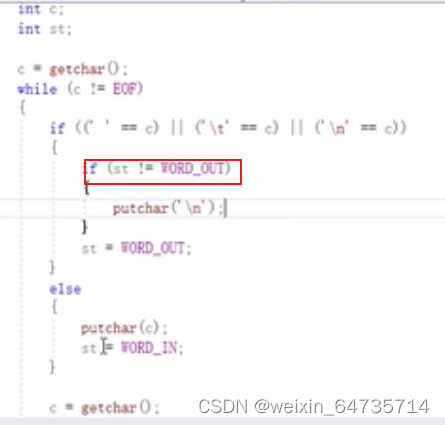
这个wrod_out和word_in的使用,很神奇。
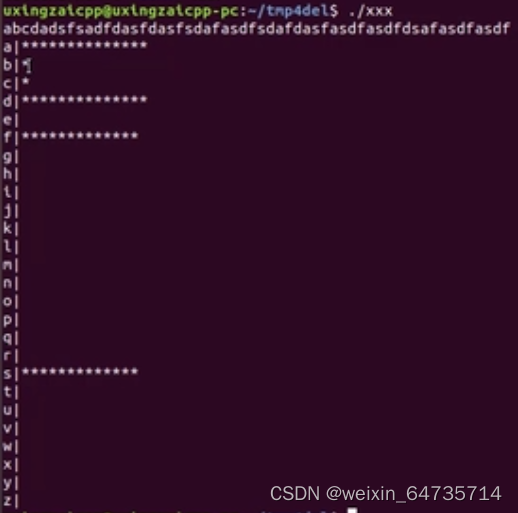
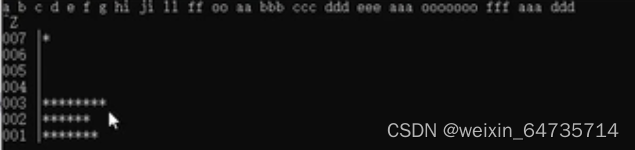
- exe执行,然后echo %ERRORLEVEL% 就能获得main函数的这个返回值。

-
Linux下main的返回值为:-1;255;所以其值就是一个8bit的数。-1 == 255
-
写批处理程序的时候,有一个值。
-

-
C语言只有传值调用。
-
函数里面,无法改变参数的值的。
-
s的值(指针地址)没有发生变化,只是s指向的内容发生了变化。
-
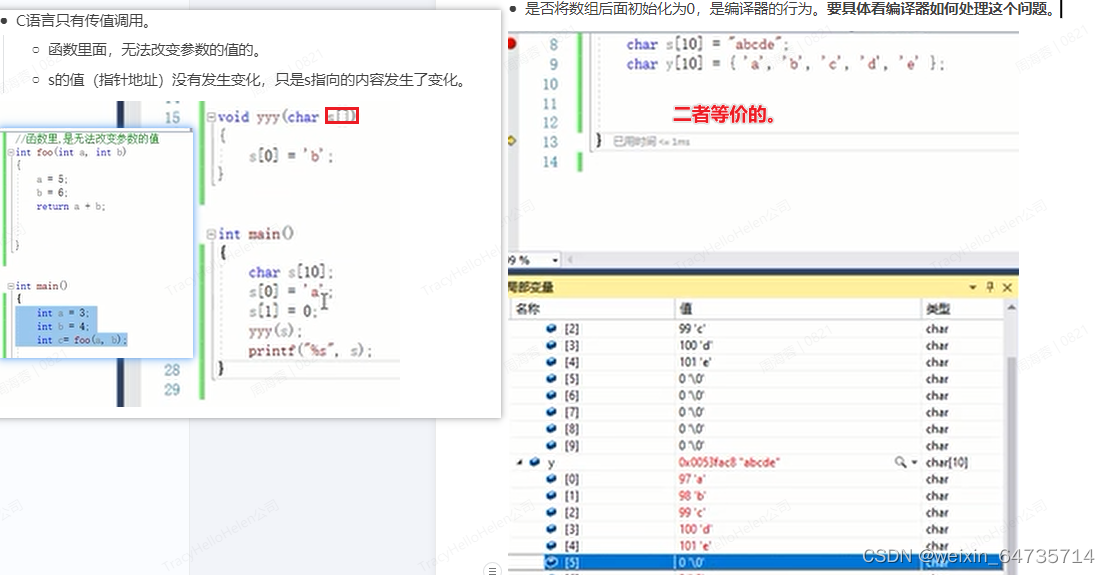
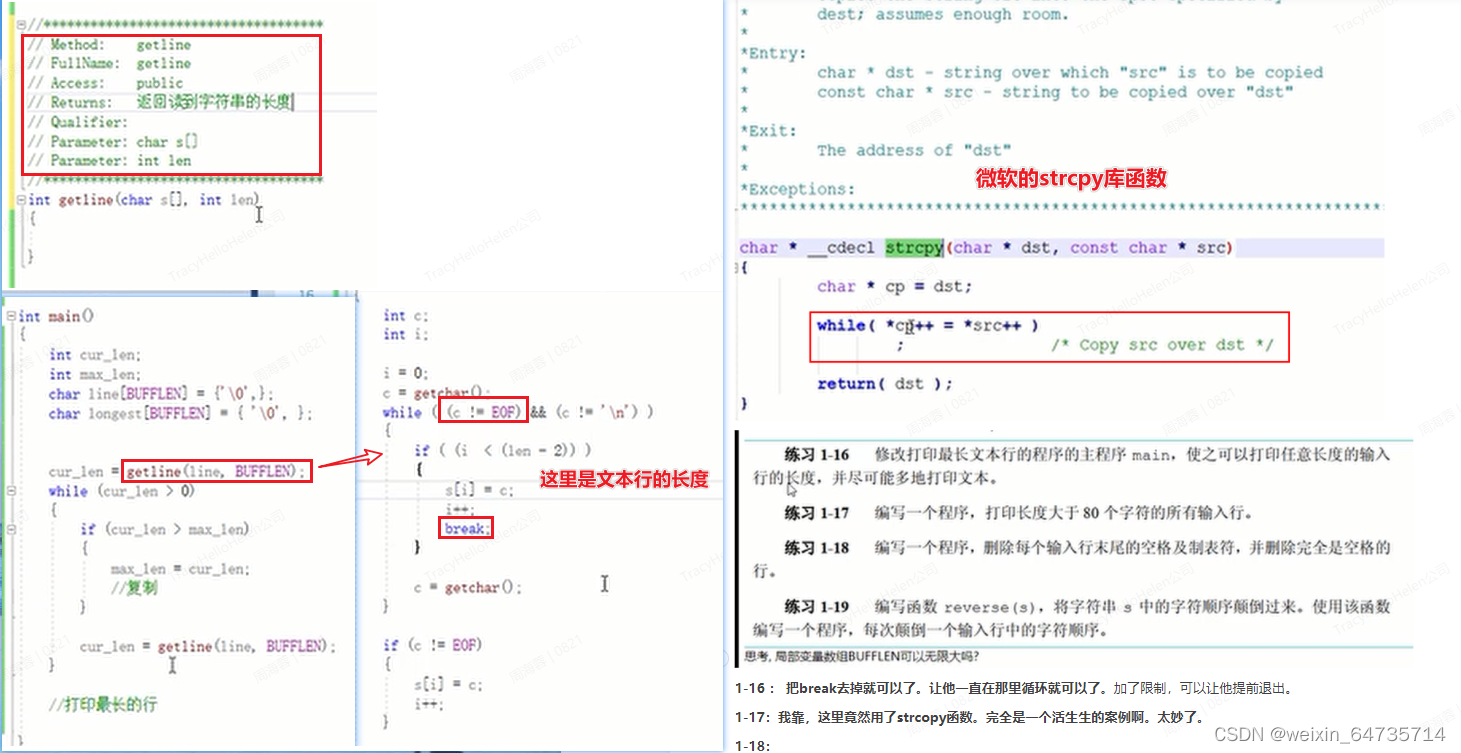
是否将数组后面初始化为0,是编译器的行为。要具体看编译器如何处理这个问题。
1-16 : 把break去掉就可以了。让他一直在那里循环就可以了。加了限制,可以让他提前退出。
1-17:我靠,这里竟然用了strcopy函数。完全是一个活生生的案例啊。太妙了。
1-18:
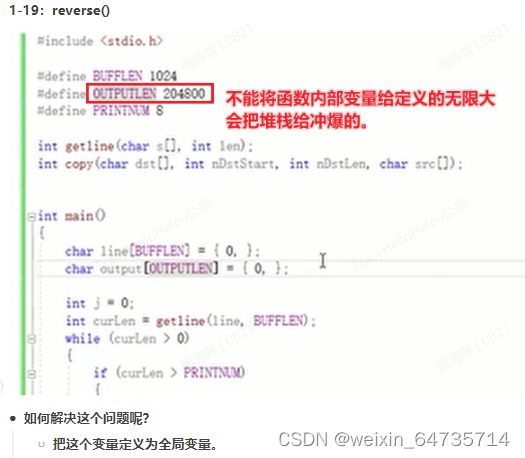
1-19:reverse()
- 如何解决这个问题呢?
- 把这个变量定义为全局变量。
chap2 数据类型及长度
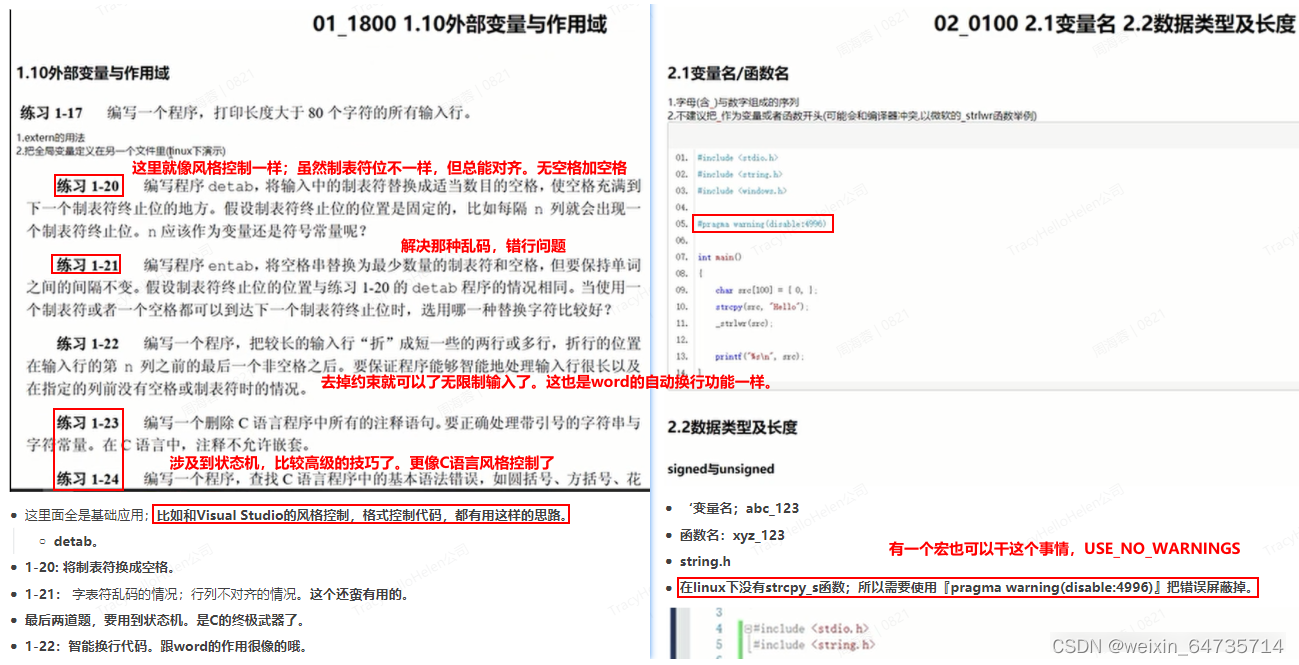

这里面全是基础应用;比如和Visual Studio的风格控制,格式控制代码,都有用这样的思路。
-
string.h
-
在linux下没有strcpy_s函数;所以需要使用『pragma warning(disable:4996)』把错误屏蔽掉。
- limits中有各个数据类型的最大最小的表示范围。
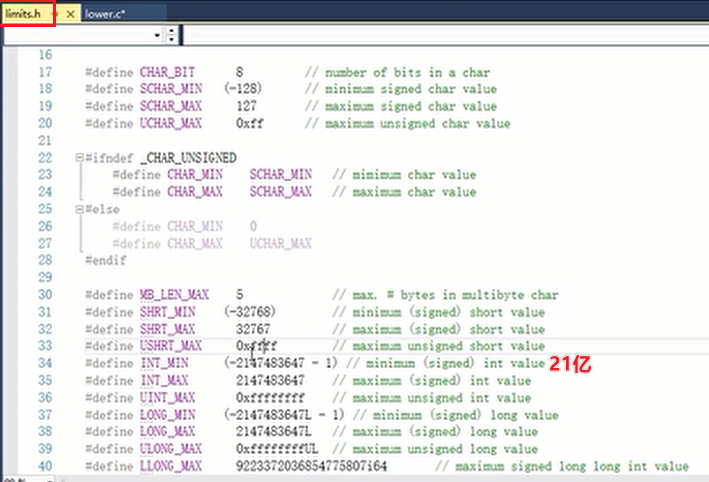

| char | short | int | long | long long | float | double | long double |
| 1 | 2 | 4 | 4 | 8 | 4 | 8 | 8 |

数据类型和编译器有关。linux下long long是8个bit的。
-
linux下面 long double占16个字节。
-
double和float的limits在 float.h 头文件中。

找FLT_MAX在哪个文件里面?正则表达式。

gcc编译器里面的float.h
2.3 常量
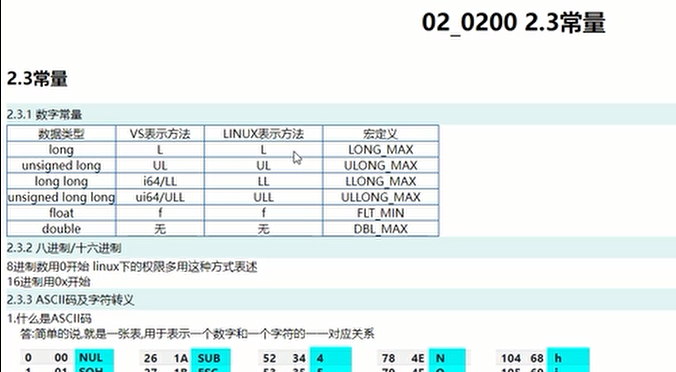

常量表达式,在编译时计算。
宏定义;
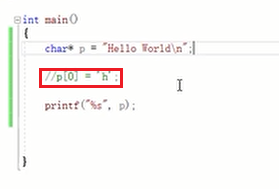
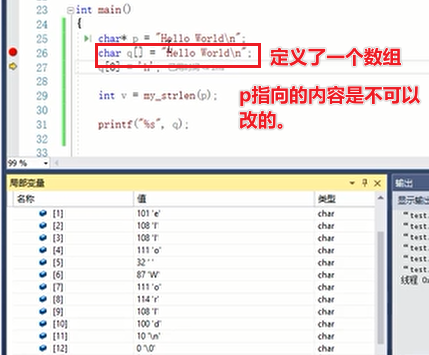
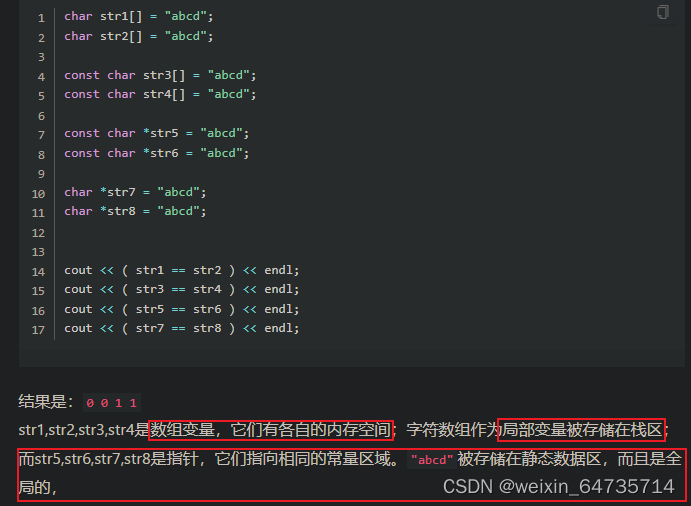
字符串常量不可以修改。修改是失败的。字符串常量,是放在一个只读区域的!!!存在exe文件中。

enum常量;最大值就是Unsigned INT,占4个字节。
都不做重复性检查的。
2.4 声明

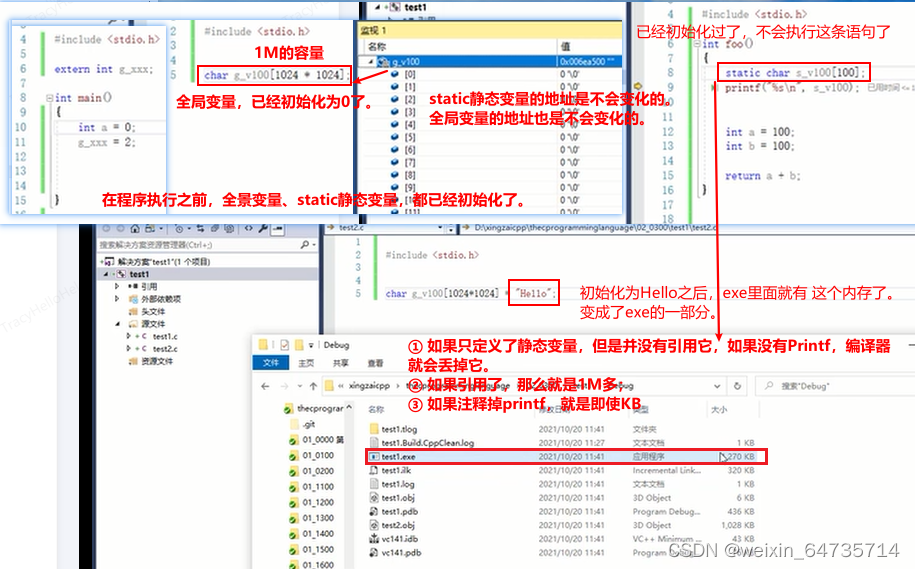
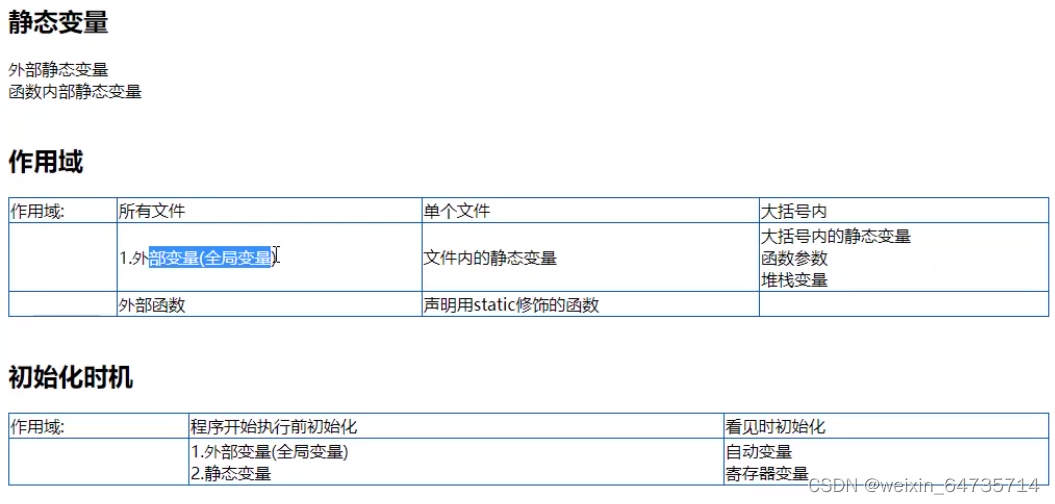
- 默认情况下,外部变量、静态变量,初始化为0。但全局变量、静态变量,只进行一次初始化。
- 自动变量 == 局部变量;每次都执行一次初始化。
- 2.4.1 全局变量 静态变量的初始化
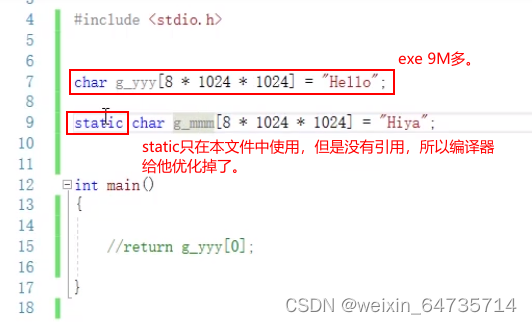
- ① 如果初始化为0, 编译后的大小不会增加;证明,初始化为0, 编译器采用了简单的方法标志为初始化为0.
- ② 如果初始化为其他值,编译后的大小会增加,exe。初始化的内容直接放在exe里面。
- ③ 不使用/引用/调用的静态变量,可能会被编译器优化掉,具体看编译器的实现。
- 总结:C语言中,全局变量/静态比那里在程序执行前已经初始化。

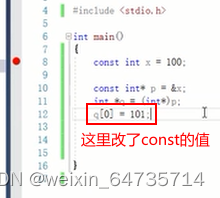


- 关于优先级:直接加括号,不用记忆这些。不要为难自己。就算写出来了,但是别人看也看不懂,看起来会很老火。所以易读易用,容易理解比较好。
- 不建议写在一起。代码的需求:①自己能看明白;②别人能看明白。



2.7 类型转换

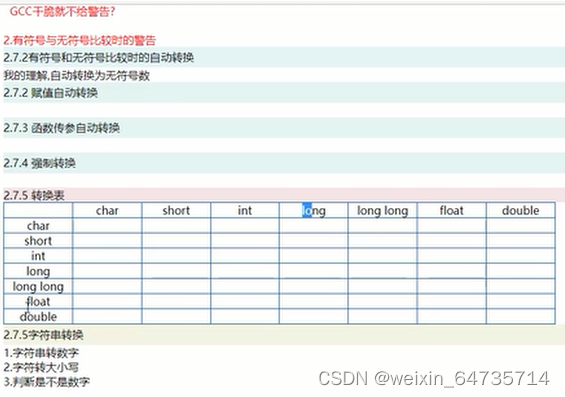
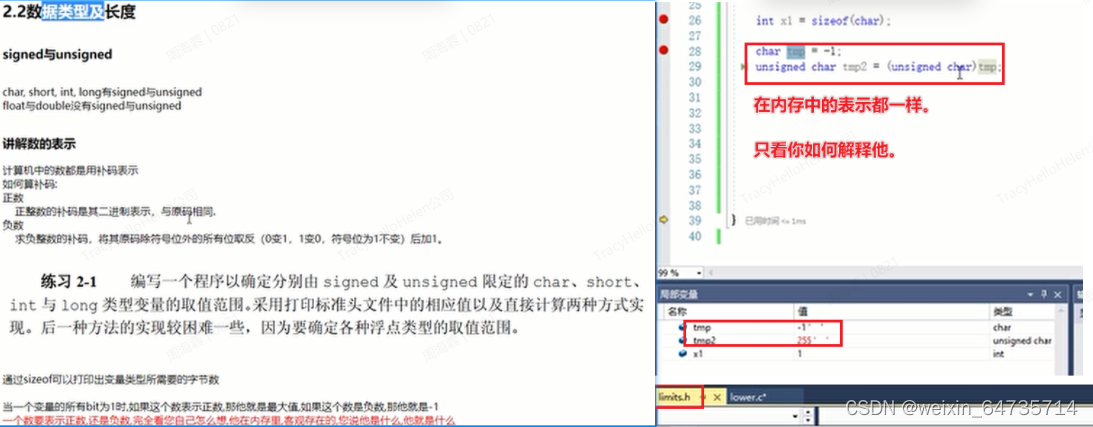
- 有符号 无符号的转换,在内存中不会有什么变化,其16进制的值不会有什么变化。只是解释器发生了变化。
- 低级到高级: char转为short,高位填0;-1, 高位填1;
- 高级到低级:扔掉高级部分。
- visual studio中,int向下转到Char/short,并不会出现编译告警;
- 有符号、无符号,作比较时,自动转为无符号数。这种地方容易出bug;一个有符号的 signed -1 > unsigned 0;
- 浮点数的转化:int转float可能会丢失信息。
- 自己做四舍五入:float x1= 5.9f; int v1 = (int)(x1 + 0.5); 加个0.5可以自动四舍五入。


这里int转为Float后,后面的小数点会丢失。精度丢失;所以一个很大的int数,转为float的时候,整数部分会丢失。
int转float的坑_qq_45740393的博客-CSDN博客_int转float
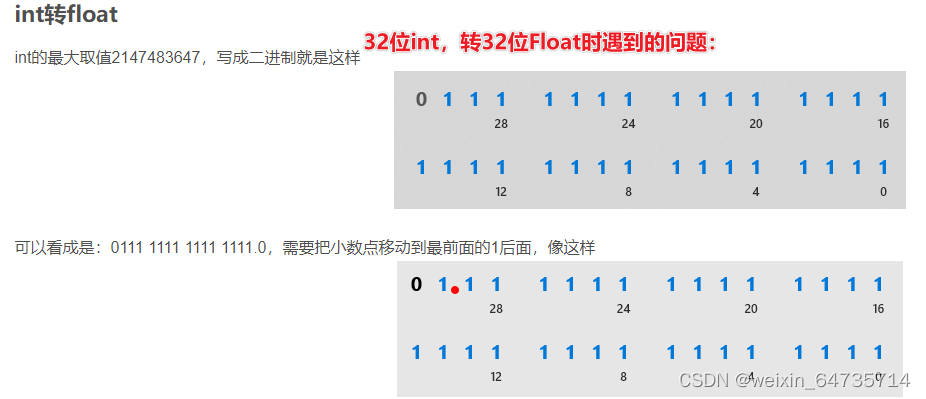
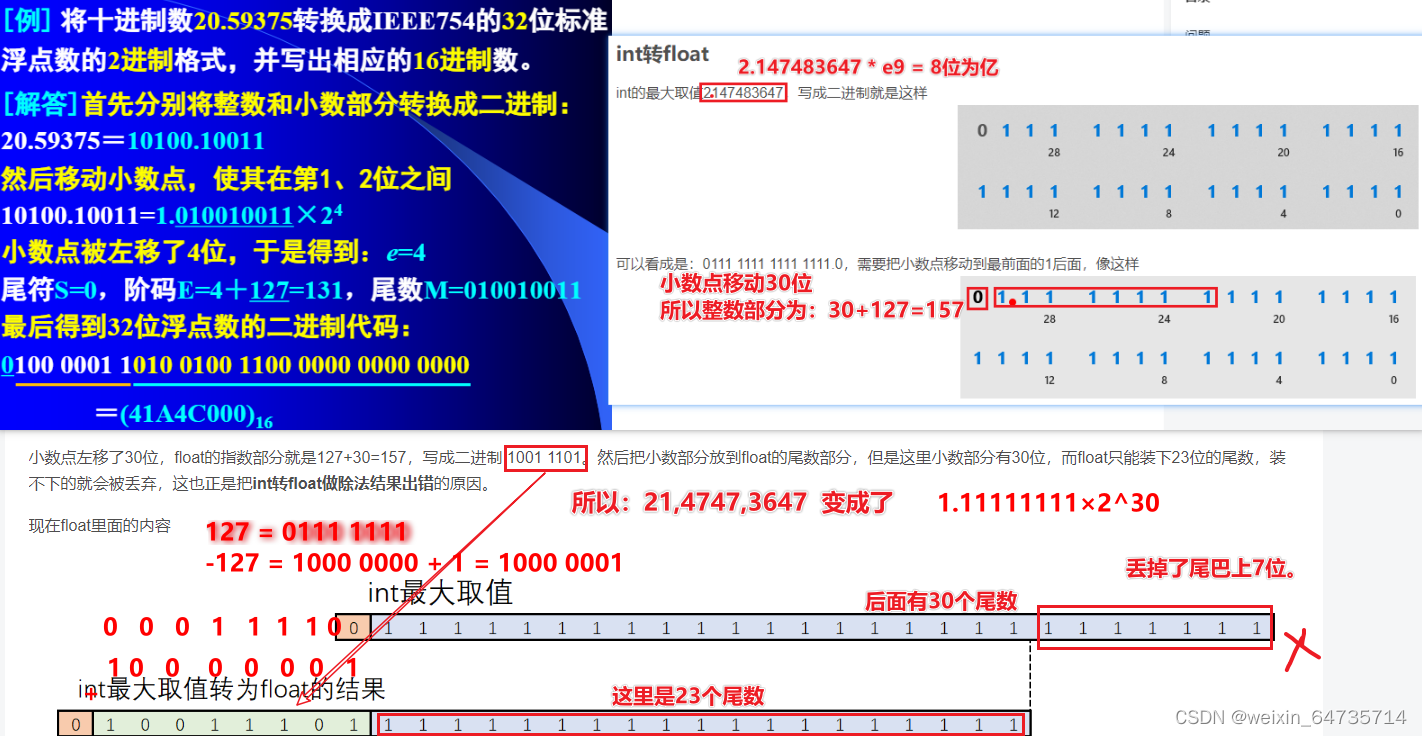
也就是丢掉了末尾的7位,对于一个连续数字而言:每隔127个数字,都会是一个精度阶梯;float丢掉了最后的7位。导致了精度误差。所以对于很大的整型数据,转换为Float会有精度损失,造成意想不到的bug。


参考如下代码:(进行了一些修改)
C语言打印数据的二进制格式-原理解析与编程实现_码农爱学习的博客-CSDN博客_c语言打印二进制
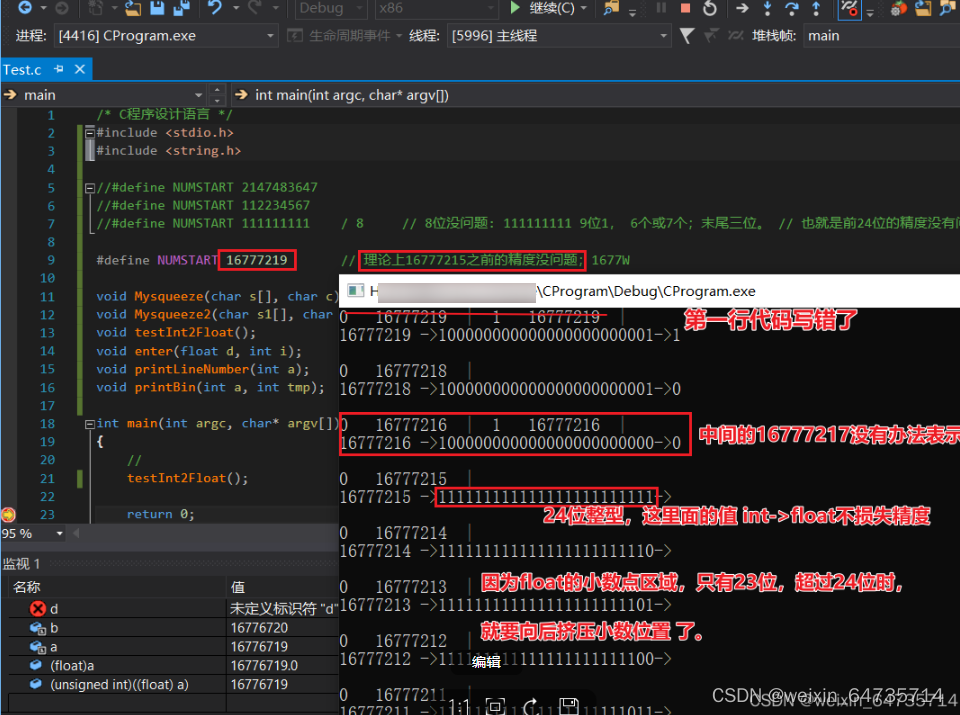
/* C程序设计语言 */
#include <stdio.h>
#include <string.h>
//#define NUMSTART 2147483647
//#define NUMSTART 112234567
//#define NUMSTART 111111111 / 8 // 8位没问题: 111111111 9位1, 6个或7个;末尾三位。 // 也就是前24位的精度没有问题。
#define NUMSTART 16777219 // 理论上16777215之前的精度没问题;1677W
void Mysqueeze(char s[], char c); // 从字符串s中删除所有的字母c
void Mysqueeze2(char s1[], char s2[]);
void testInt2Float();
void enter(float d, int i);
void printLineNumber(int a);
void printBin(int a, int tmp);
int main(int argc, char* argv[])
{
//
testInt2Float();
return 0;
}
// 从字符串s中删除所有的字母c
void Mysqueeze(char s[], char c)
{
int i, j;
for (i = 0, j = 0; s[i] != '\0'; i++)
{
if (s[i] != c)
s[j++] = s[i];
}
s[j] = '\0';
}
// 字符串拼接:t接到s的末尾,假设s中有足够的空间保存 s + t
void Mystrcat(char s[], char t[])
{
int i = 0, j = 0;
while (s[i] != '\0')
i++;
while ((s[i++] = t[j++]) != '\0')
;
}
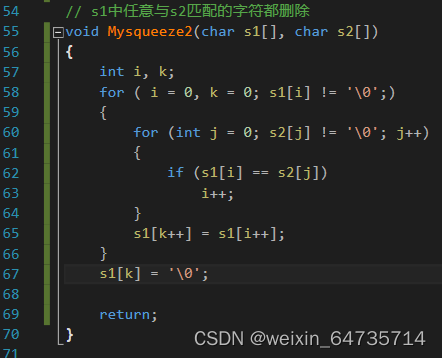
// s1中任意与s2匹配的字符都删除
void Mysqueeze2(char s1[], char s2[])
{
return;
}
/* 反转字符串 */
void reverse(char s[])
{
// 几次遍历?
/* 1. 生成一个同等长度的,t,然后遍历赋值;2. 两次遍历;2N---->N+N/2=1.5N;
*/
// 卧槽,想都没想到,还能折半查找写这个代码!!! 直接进行原地交换。我晕。
// 无论奇偶,只用交换两边即可。
int i = 0, len = 0;
while (s[i])
{
i++;
}
len = i;
for (int j = 0; j < len / 2; j++)
{
char tmp = s[j];
s[j] = s[len - 1 - j];
s[len -1 - j] = tmp;
}
}
static int a = NUMSTART; // int_max
static int b = NUMSTART;
static int print = 1; // 换行控制变量
static linenumber = 0; // 行号
static int tmp = 1;
/* 测试int2float的精度变化问题 */
void testInt2Float()
{
for (int i = 0; i < 500; i++)
{
float fb = (float)a; // a是int类型,每次-1;但强制转换为float类型
a = a - 1;
enter(fb, i);
}
}
void enter(float d, int i)
{
// 判断浮点数是否更新,更新就换行
if (d != b) {
printLineNumber(linenumber); // 输出行号
printf("%d | \n", b); // d是float表示的数, a是int实际的数; 隔多少个数,b == a?
printBin(b, tmp);
printf("\n");
// 变量重置
print = 0;
linenumber = 0;
tmp++;
b = (int)d; // float转int精度不够 int->float->int, 左边int-1,右边int还是同一个值
// a-1 -> d=float(a-1) -> b = int(d) float表示的int值;int实际在-1, 但float没发现。
}
else{
printLineNumber(linenumber);
printf("%d | ", b); // 打印每次的浮点数
linenumber++;
}
if (print % 16 == 0)
{
print++;
printf("\n");
}
else {
print++;
}
}
void printLineNumber(int a)
{
if (a < 10)
{
printf("%d ", a);
}
else if (a > 100)
{
printf("%d ", a);
}
else {
printf("%d ", a);
}
}
void printBin(int a, int tmp)
{
char s[32];
_itoa(a, s, 2);
printf("%d ->", a);
// 在字符串倒数第7个位置,加入别的字符;
for (int i = 0, j = 0; i < 34; i++)
{
if (i == 24)
{
printf("-");
}
else if (i == 25)
{
printf(">");
}
else if(s[j] != '\0')
printf("%c", s[j++]);
}
}
- float 不会自动转换为double;float主要是为了在使用较大的数组时节省存储空间,有时也为了计生机器执行时间。
- double双精度算术运算特别费时。
- linux下查找函数在哪里:man isdigit ; man atoi

2.8 自增自减运算符

- 从汇编语言:调试——>窗口->反汇编,看看汇编代码是怎么进行的。
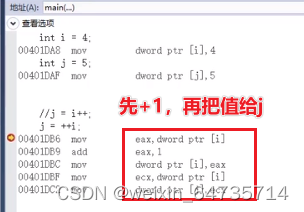
- 数组越界了:数组访问了不该访问的东西。这个程序的运行完全看人品。
- 如何解决这个问题?——增大空间。


可以认真去阅读《微软的标准库代码》:里面有很多思想,都可以借鉴。
UCRT下载地址:https://github.com/huangqinjin/ucrt

2.9 按位运算符

按位运算符,是最简单的加密算法?
- 6个按位运算符只能用于整型操作数:short,int,long,long long类型。
- 与、或、非、异或、左移、右移; 异或XOR ^
- 用异或用于加密和解密:
- 同一个数异或两次,会等于原来的值。(X^F)^F=X, (X|F)&F=F
- 取非的时候, 与类型有关的。x = x & ~077, 与操作数的数值类型有关系!
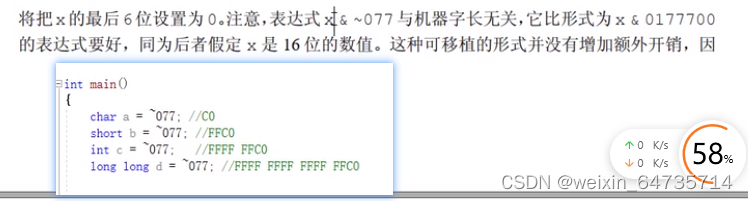

- unsigned x = -1;默认的是Int; static x = 0; 也都默认的是int类型的。什么都不写的时候,都是int类型,int的简写。
- getbits函数有什么用途?
- 所以用~0的用途,就在与此,希望~0可以自动分配长度;不能用一个统一的长度来计算。


- 有点像Ctrl+F的那个替换功能?
- 2-6思路:先清零,再相加(加法,就是求或就可以了;不进位的加法,或就可以了)?


习题2-7:


习题2-8:循环右移
先取出来x1,把x1放到最左边;x右移,因为是无符号的,所以只会补0;然后x1|y = x1+y

移位的速度是很快的; m>>1 == m/2; 移位用得好的话,代码的速度会大大提升。
2.10 赋值运算符与表达式 条件表达式 预算符优先级与求值次序
- x是传值,是局部变量,所以是赋值。可以直接对x进行操作,而不会改变原来的值。


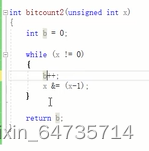
- 对bitcount加速:删除最后一个二进制位的做法如下:
- 加速分析:原来是需要移位n位;现在4只有1个1,只需要一次计算。有多少个1,就执行多少次!而之前是,有多少位,就得移动多少次;4的话,得移动2次。所以加速了。
- 都是111的情况下,都要执行3次计算;但是 1100的情况下,移位需要计算4次;而2-9只需要执行2次即可,减少了计算量。
- 主要原因是:100 & 011 x=x&(x-1)的作用太好了,直接消除了1个1的位置,减少了很多计算。直接把1的那个位置全部清零了。所以快了。
- 据说与比移位快。
- 看循环次数,就明显占优。所以优化的地方,有可能是:减少冗余的循环次数。

- 大厂的代码规则是很严格的;if后面必须加括号;否则后面加代码的话,没有括号,直接把整个代码干废了。
- 条件表达式的返回值的类型:是跟f,n的类型有关系,所以返回值是float类型,不希望这个表达式结束之后丢失精度。



求值顺序对结果会产生副作用,因此尽量少写这种依赖项强的代码!——————不知道典型的哪些场景会发生此类事情?


3. 控制流

C语言的缩进是给自己看的;编译器只看括号的。这个虽然缩进了,看起来是一串的,但是编译器是看不见的。
- 高级环境的代码提示功能,可以让你尽量减少错误。高手用记事本的说法,已经过去了。还是高效便捷、少出错为主。


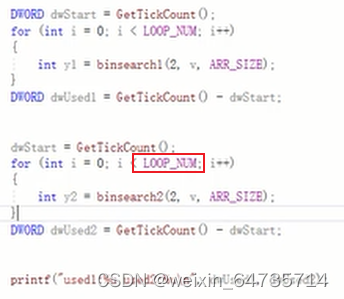
二分查找法:要求数组是排序过的。

- 现在的计算机太快了,没时间。就让他多执行一些次数,1000次,还是0。 100W次,代码1 32ms;代码2:46ms。
- 1000W次,代码1:422 ms;代码2:453ms
- array size:编译器对代码也会进行优化。肯定不是这里的问题,这都不算优化。关键的优化地方还是在循环次数那里的。
按着alt键进行编辑,就是列编辑模式,一下子就可以写上这么多。
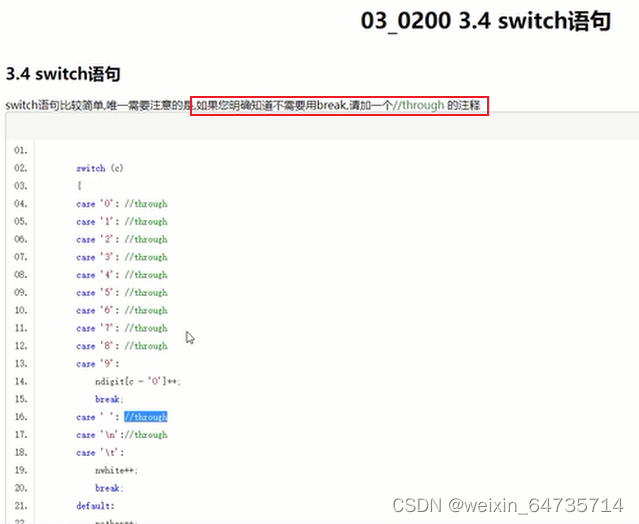

- 这个版本可以跳过空白符;做一些基础的异常处理。

linux下查文件:man isspace


- 代码虽然不多,但是讲清楚,还是很难的。

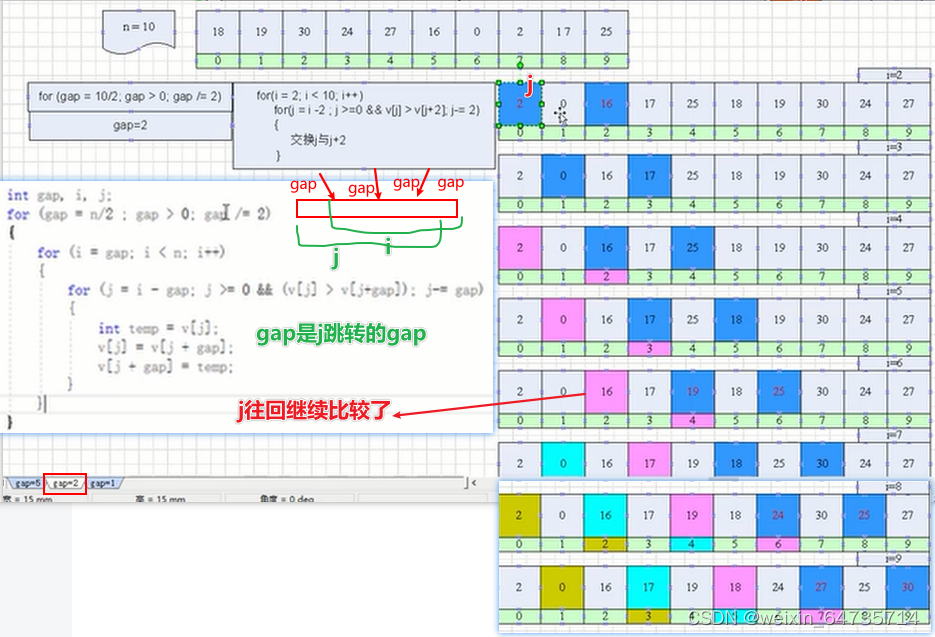
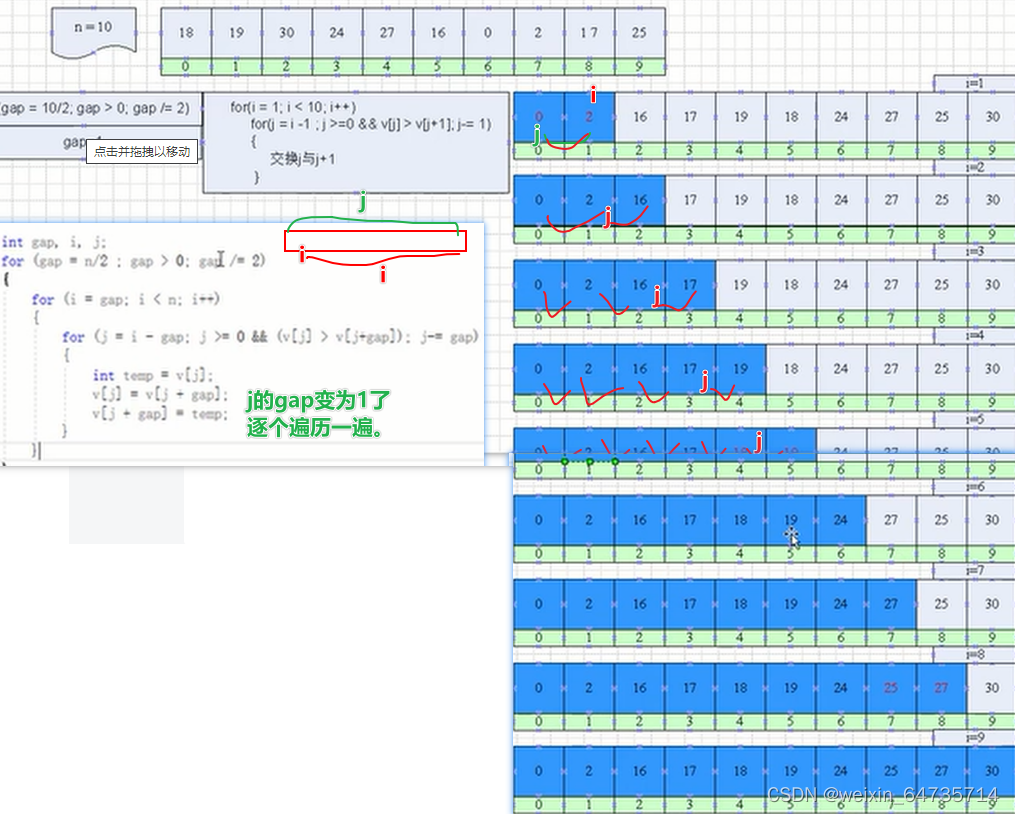
只做最后一遍排序,也可以实现排序的功能:
gap=1,就能确保能排序好。


- 为什么需要 gap/2;跟交换顺序有关系,shell前面的步骤可以减少交换的步骤。所以,排序算法前面是进行粗排,减少了交换的次数。
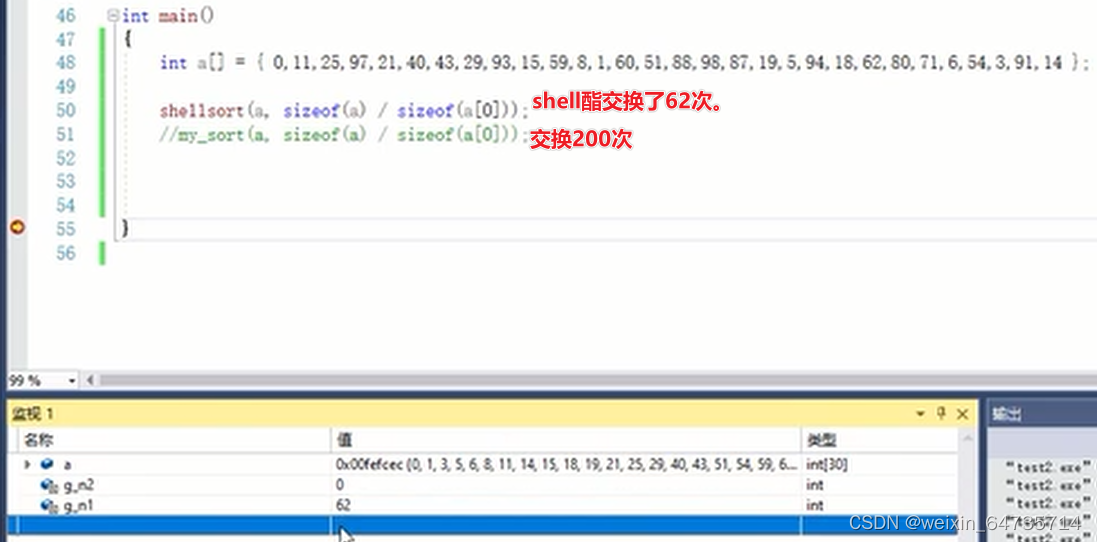
- 可以用一个变量来统计交换的次数。所以算法加速的很多关键点,都是减少其中的一些循环、访问等。
- 都是减少其中时间消耗过多的模块。


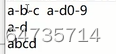
a-d 替换为abcd


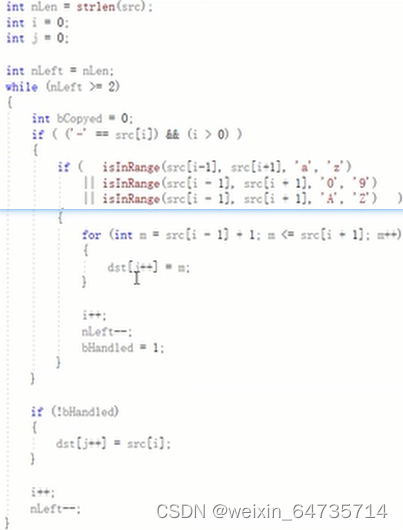

3.6 do-while循环
- 实际中用的很少。

3-4:不能处理INT_MIN, 超出其表示范围了。
微软如何处理这个函数的呢?crt->itoa。 radix是转换的进制。
- 标准的库函数:
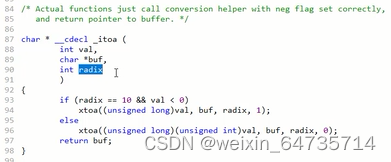
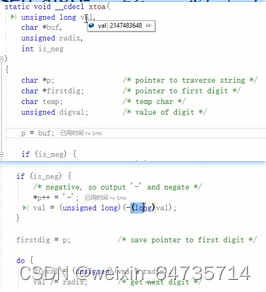
- 有兴趣去看看星仔的源码怎么写的,这里。

itob看xtoa的代码,照着改,就可以了。
- 多度微软源代码,大师级别的代码,对自己会有很大的帮助的。
3.10
trim这个函数平时用的还是比较多的。



- goto只能向后跳。
- 靠一个goto和标号,程序很稳定。
- 严格的使用规则,只能向后跳,不能向前跳。
- goto也有它有用的时候。
可以直接生产的函数:①最前面进行参数有效性的检查;
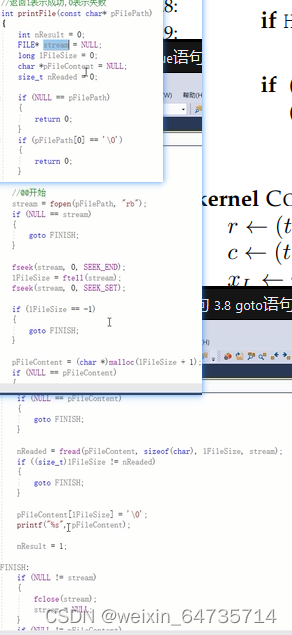
// 可生产的函数示例:函数头有return; 函数主题中没有return;函数末尾有return
/*
返回:1-成功; 0-失败
*/
int printFile(const char* pFilePath)
{
int nResult = 0;
FILE* stream = NULL; // 读取文件内容
long lFileSize = 0;
char *pFileContent = NULL;
size_t nReaded = 0;
if (NULL == pFilePath) // 路径为空 参数有效性检查
{
return 0;
}
if (pFilePath[0] == '\0')
{
return 0;
}
stream = fopen(pFilePath, 'rb');// 打开文件
if (NULL == stream) // 打开文件失败
{
goto FINISH;
}
fseek(stream, 0, SEEK_END);
lFileSize = ftell(stream); // 获取文件长度,判断文件大小是否有效
fseek(stream, 0, SEEK_SET);
if (lFileSize == -1) // 如果文件长度有问题,ftell返回-1
{
goto FINISH;
}
pFileContent = (char *)malloc(lFileSize + 1);
if (NULL == pFileContent) // 内存分配失败
{
goto FINISH;
}
nReaded = fread(pFileContent, sizeof(char), lFileSize, stream); // fread的返回值为size_t
if ((size_t)lFileSize != nReaded)
{
goto FINISH;
}
pFileContent[lFileSize] = '\0';
printf("%s", pFileContent);
nResult = 1;
FINISH: // 统一做所有的释放资源:这是一串复用的代码;做返回值的检查
if (NULL != stream)
{
fclose(stream);
stream = NULL;
}
if (NULL != pFileContent)
{
free(pFileContent);
pFileContent = NULL;
}
return nResult ;
}chap4 函数

- 不是所有的路径都有返回值。
- grep函数的特例


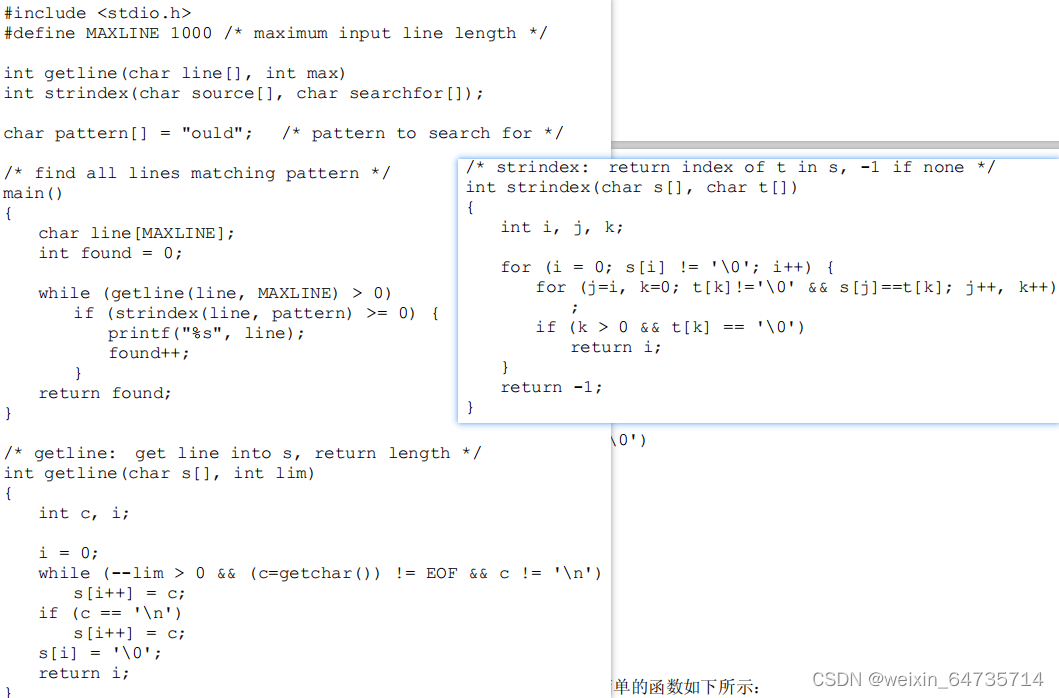

- 从右到左去找。
4.2 返回非整型的函数

- 0.0是double类型;0.0f是double类型。


编译器从上往下看函数,需要先声明,再使用。
- 这就是编译器看到不一样的;所以就会warning和error

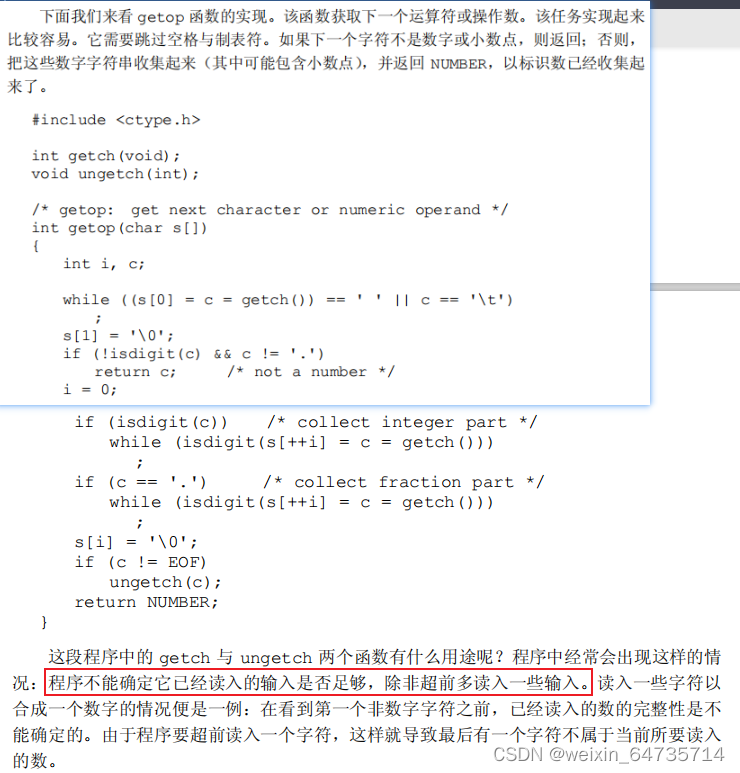
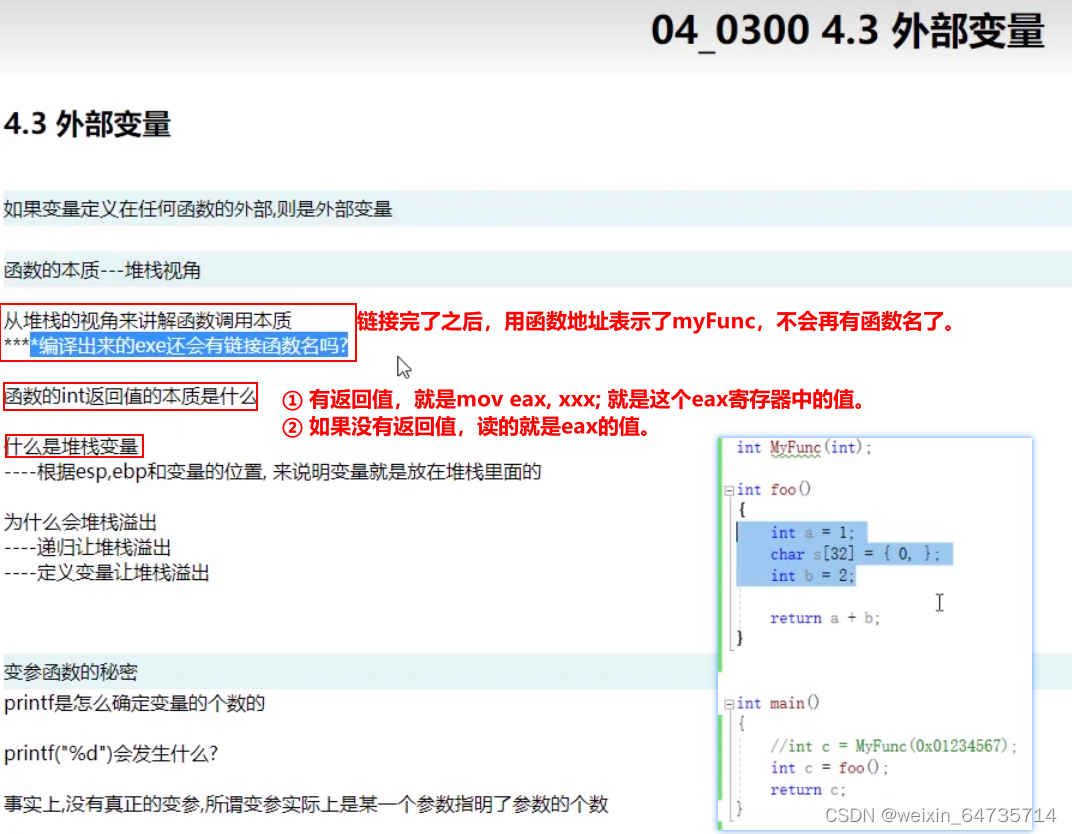
4.2 外部变量

- 技术含量较高的一门课;堆栈比较难懂。
- 逆波兰表达式。




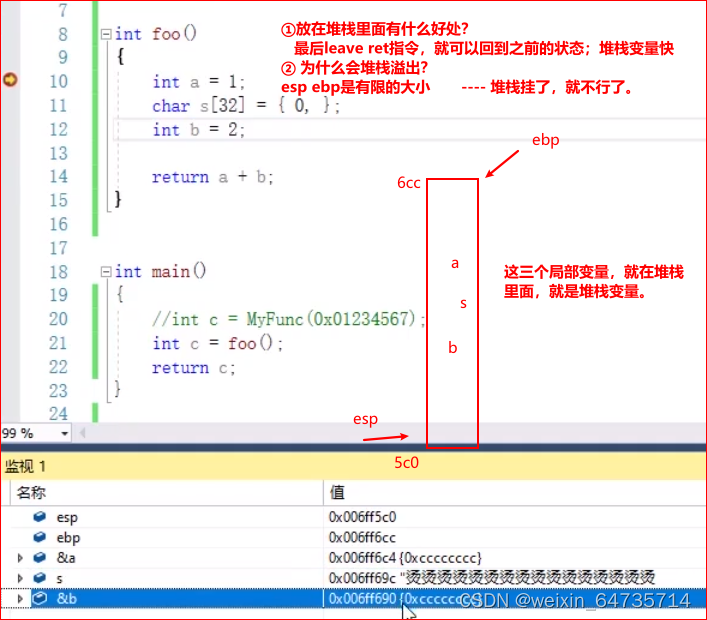
4.4 函数本质(堆栈的视角)
几个子程序插入,靠堆栈实现。
子函数的调用,就是靠堆栈来实现的。
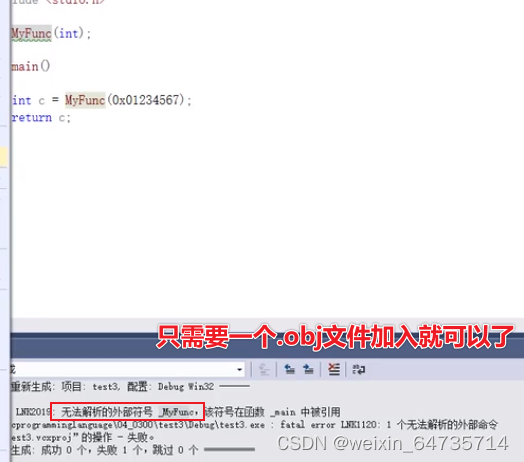
- 堆栈,是程序运行过程中就有的一块存储区域。
- ①
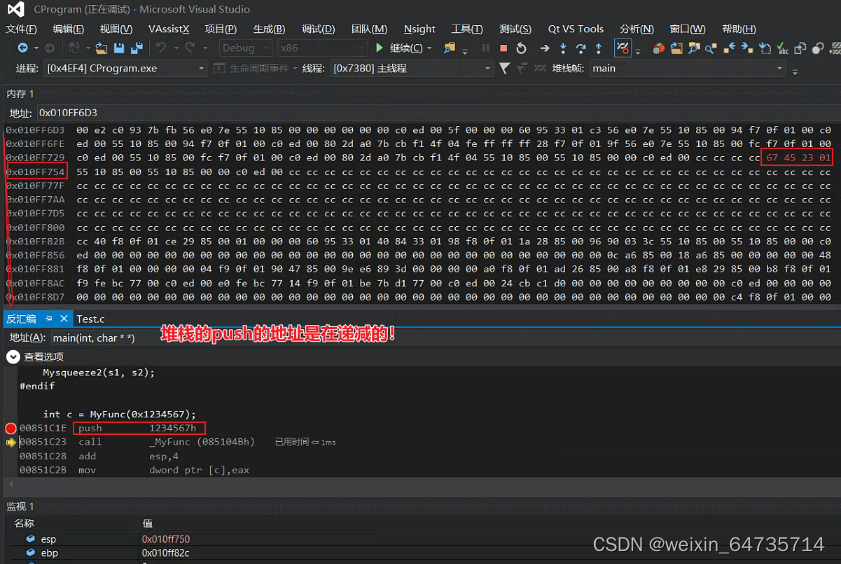
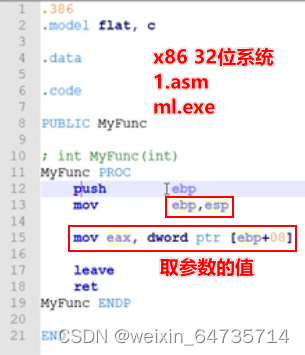
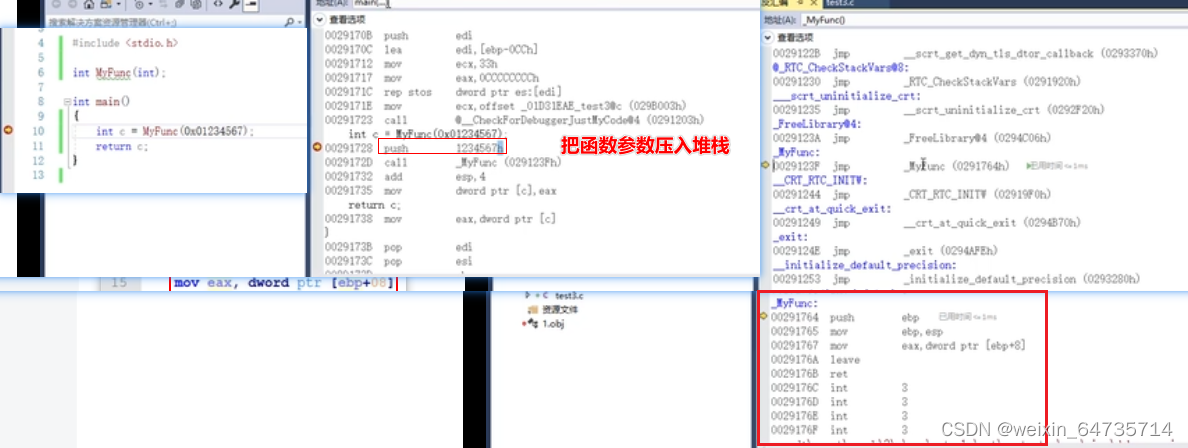
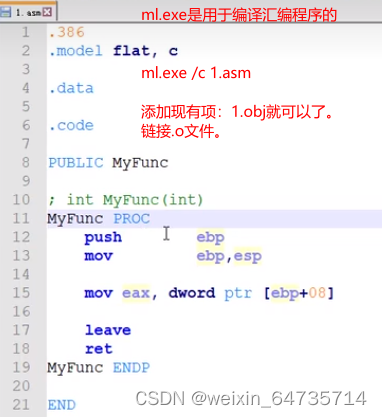
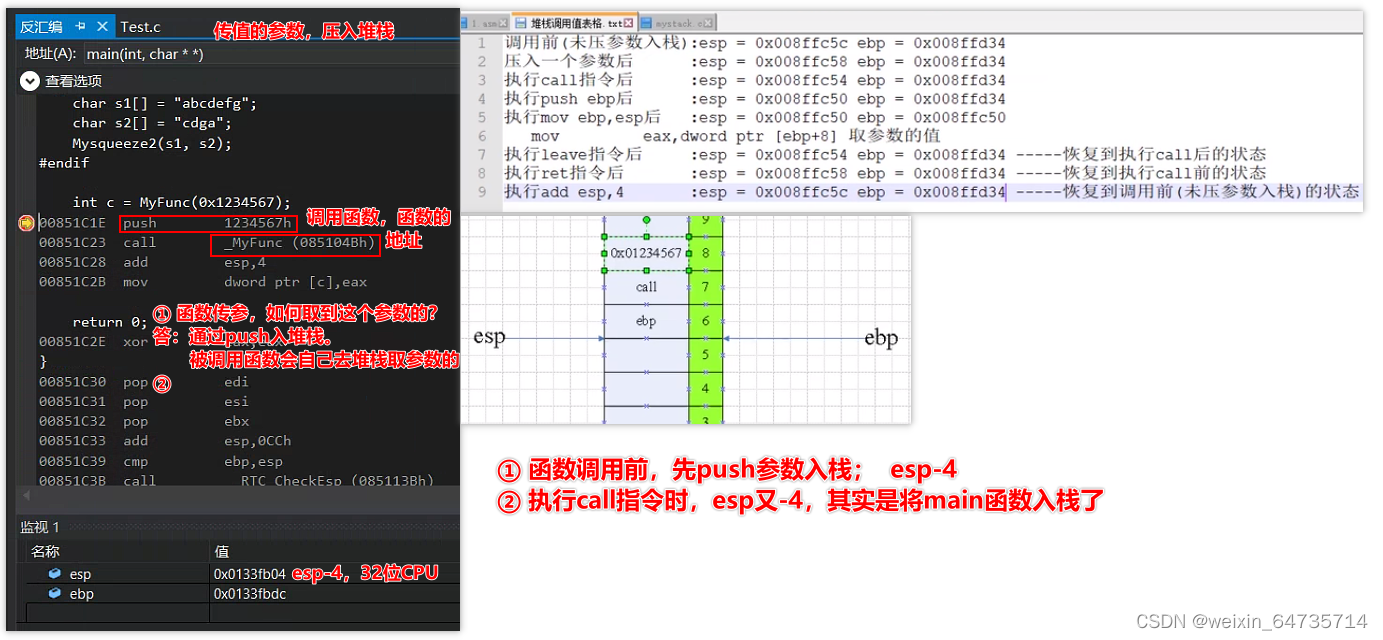
- 函数调用,传参。函数是如何取到参数的????
- 调用时,将这个参数push压入堆栈;然后被调用函数去堆栈取这个参数。
- 函数传参数,是通过堆栈实现的。
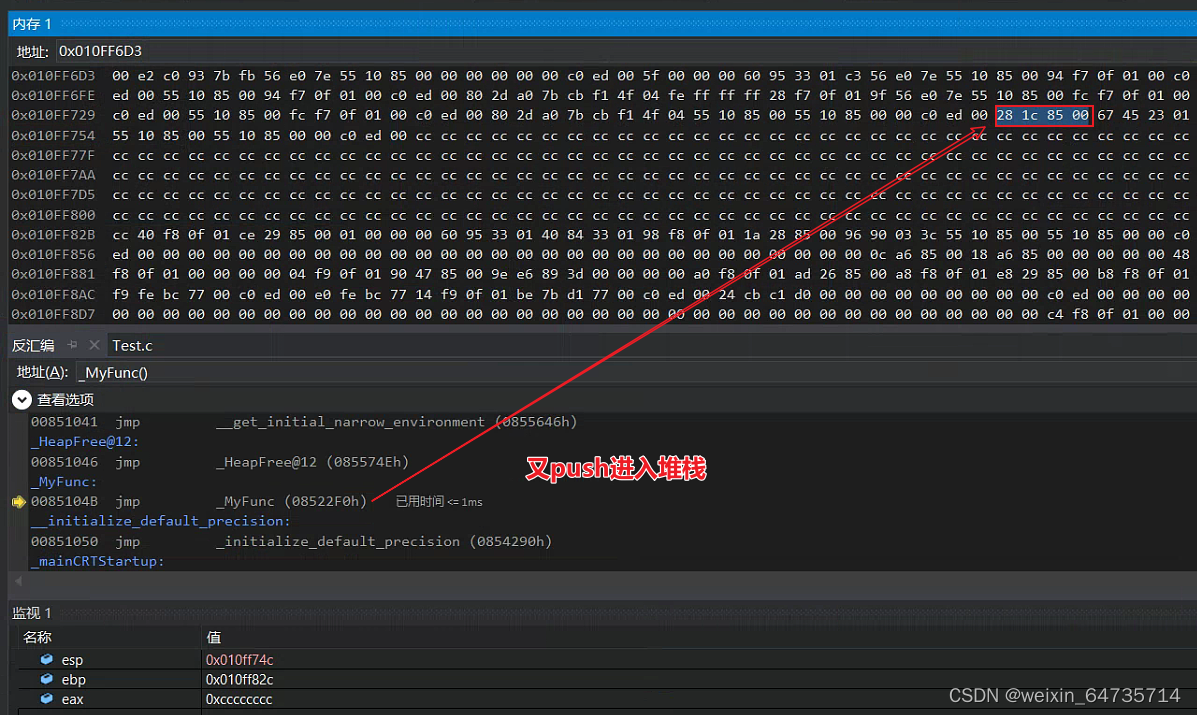
- 递归为什么会堆栈溢出呢?
- 堆栈一直在压入压入压入
- 一直调用子函数,相当于函数都在调用自己,所以一直在压入堆栈。调用一次子函数,就要使用一次堆栈。
- ① 递归的效率并不是很高;② 递归多了会让堆栈溢出
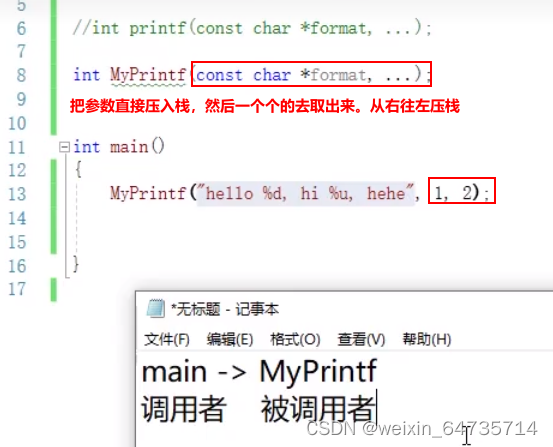
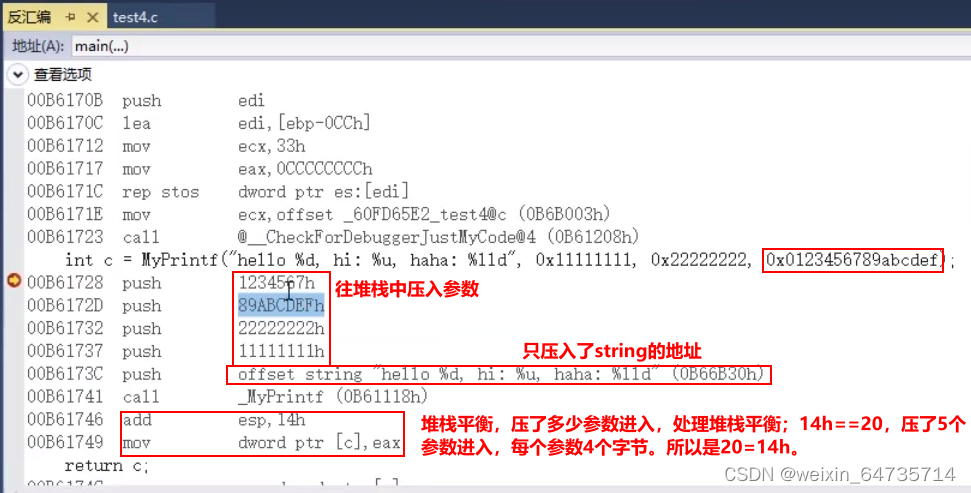
- 变参函数
- 参数个数不确定,就是变参。
- 通过前面的%来判断有几个参数。

- 32位CPU,一个堆栈的格子是4个字节;4 bytes;
- printf("%d")————执行者会从堆栈中去取一个数,所以dirty read,读了不该读的东西;eax去堆栈找了一个数。
- VS的默认堆栈大小是多大:default stack size, 默认是1M。
- 可以实际测试一下这个堆栈到底多大;char s【1024*1024],理论上是会崩溃的。确实崩溃了。
- 如果有很大的变量,不要做成堆栈变量。
- 把较大的变量放在堆栈外面。
- malloc free
- malloc申请的内存在Heap上,不在stack上。heap没有stack快。
- stack的速度很快。
4.3 外部变量


4.4 作用域规则

- 外部变量 == 全局变量 使用:extern int g_x;
- static 静态变量
- 自动变量==堆栈变量;局部变量。
- 函数的形参:寄存器变量。
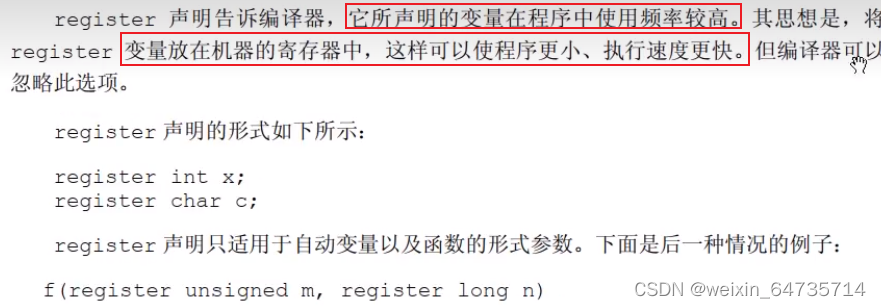
- 无论寄存器变量是否放在寄存器中,它的地址都是不可访问的。内存才是有地址的,寄存器是没有地址的。寄存器速度是比较快的。
- 不需要加寄存器变量。因为编译器可以轻松就给你优化掉,所以不用在意这个。
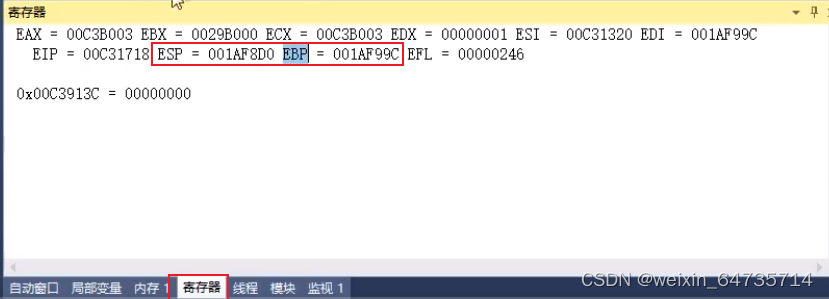
- static函数
- 定义:告诉编译器要预留多少空间。
- 声明:不可以对变量初始化;

- 编译:C全部变成obj;
- 链接:obj生成exe
- static变量,static函数,只能作用于当前的文件。
- 其他的变量都是右作用域的。
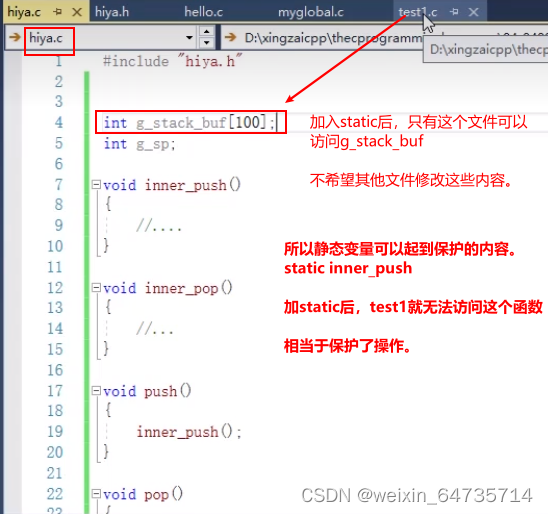
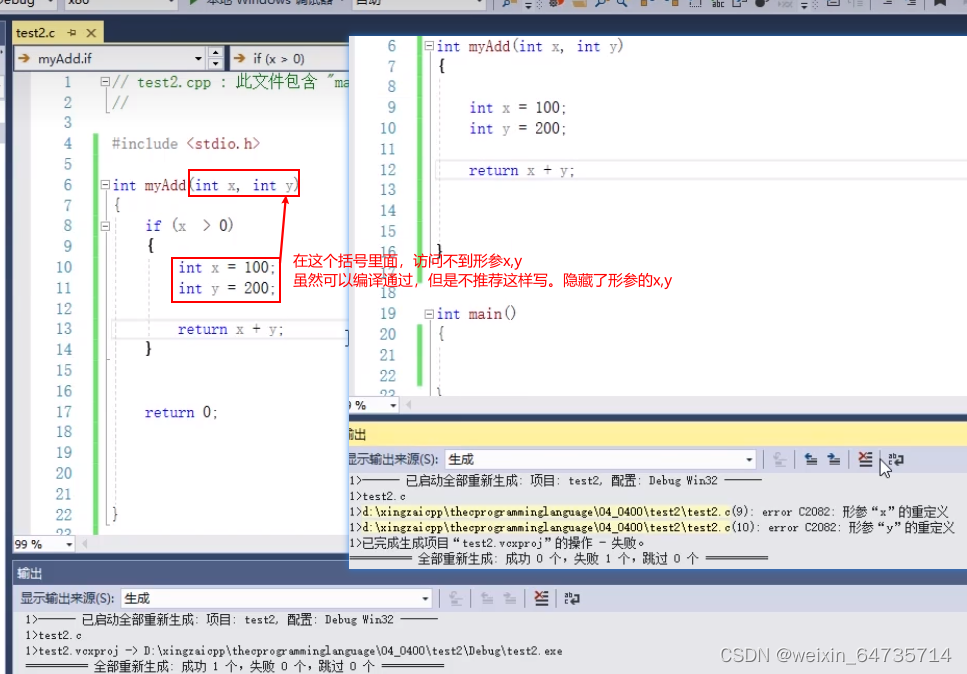
- 静态变量的内存分配问题

- 局部变量,不初始化,就是随机值。
- 全局变量,会自动初始化为0。
4.9 递归

- 求阶乘,4800次,在14的时候,堆栈就溢出了。
- 只要函数调用次数足够多,一定也会导致堆栈溢出。
qsort 去画图,一步步的理解里面的逻辑是什么!才能学得比较明白的。qsort快速排序算法
- 详细分析是怎么运行的qsort代码

4.11 C预处理器
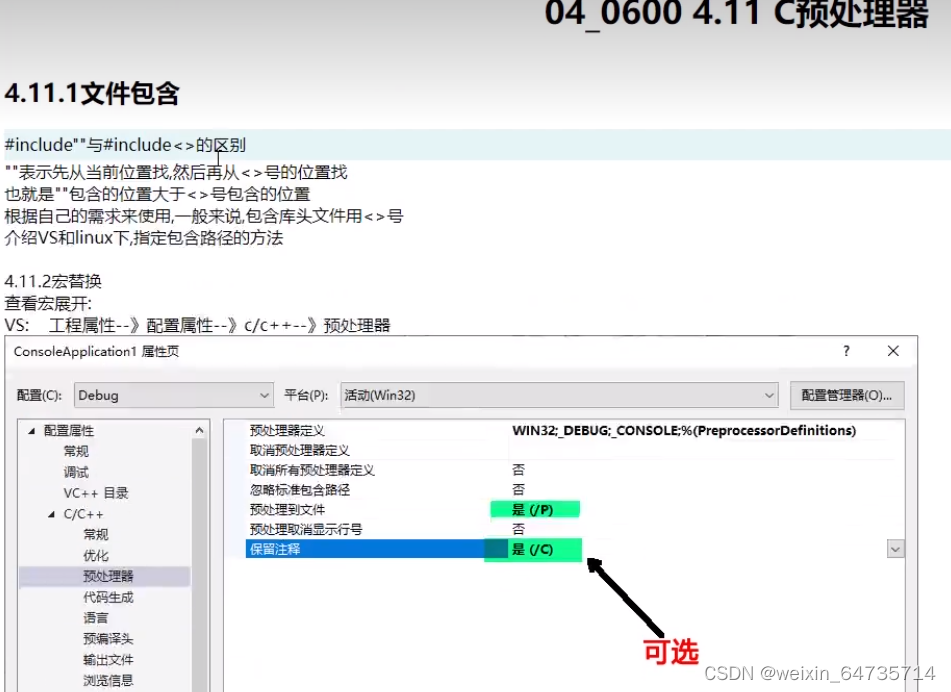
- 可以看到宏展开的样子,test2.i这个.i文件,就是展开了宏的样子。
- exe
- 预处理每一个文件
- 编译每一个文件,形成中间文件obj
- 链接所有的obj文件,形成exe文件。


宏定义的时候,必须加括号。可以看看具体的预处理之后的文件,看看宏替换的部分,是否有歧义。
- #define 进行宏定义
- #undef 可以取消宏定义
- 条件包含
- #if
- #endif

- 头文件只想包含一次
- #ifndef __TEST3H__
- #define __TEST3H__
- 可以用来只包含一次。只要两个宏是一样的就可以。
- 现在的编译体系:pragma once跟上面的define是一样的。而且不用担心宏不唯一。
- 现在的编译器都支持pragma once了。
- 附加包含目录,在目录下没找到,就去附加包含目录下去找。
- 用VC去管理文件。组织文件。新建筛选器;代码下面要加包含目录。
chap5 指针与数组
- 内存的本质是什么?
- 32位能寻址4G的内存空间。
- 32位,8个F。
- 内存就是一个线性表格;CPU可以根据地址读取该地址对应的内容,也可以写入。
- 没有识别的内存用于管理外设等需求。如网卡、声卡等内容
- 4G的内存,有保留一部分自己来用的。


- 每个程序都以为自己又一个内存在用。
- 操作系统会将虚拟地址转化为实际地址。

- 链接成exe了,就没有名字了。 int 的变量名,都变成了内存中的值了。
- 编译器预留多少个空间;
- 执行的时候,堆栈没那么大,所以一执行的时候就崩溃了。
- 8个f,来表示一个地址;4 byte;
- 一个地址是32位;4个字节;
- 指针的sizeof大小,由它能访问的内存空间大小决定。
- 指针的sizeof都是一样的。跟指针指向的类型是没有关系的,就是指向了一个地址,地址的大小都是一样的。

- 预留4个字节的空间给指针。
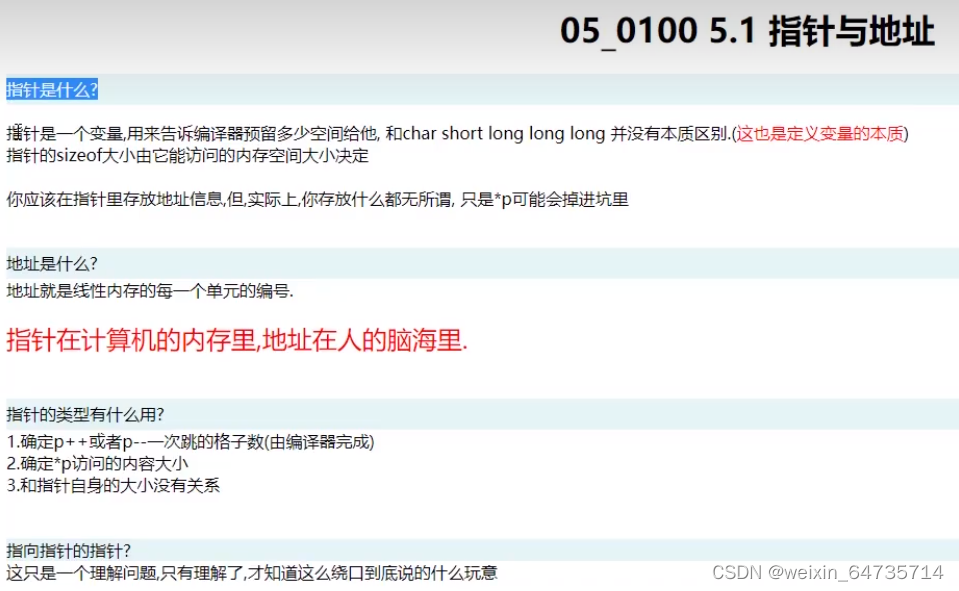
- 指针的指针,二级指针:
- p,q,m都是指针,都是一样的编译器预留一样的空间。
- p的指针的内容是a的地址;
- (void *)类型的指针;不可以进行++,--;赋值都是可以的。
5.2 指针与函数参数
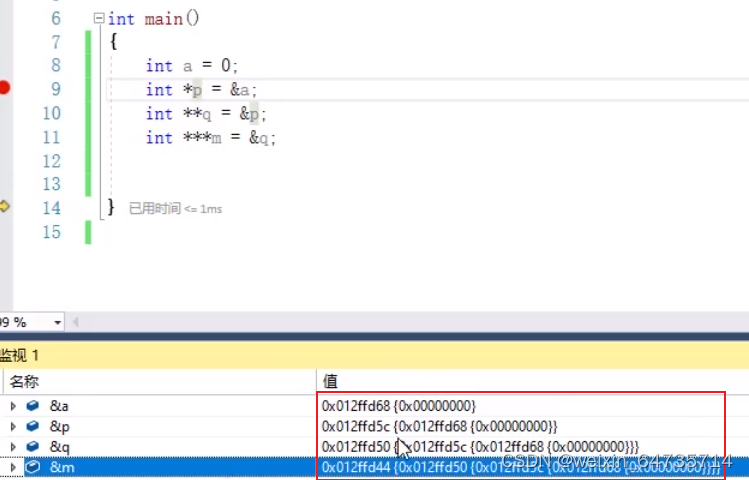
- 传值方式:传参。
- 在堆栈中,申请了参数的拷贝数据;形参,实参,都是在堆栈中申请的堆栈变量。交换了拷贝的ab的值,但是原来的ab没有变化。
- 只是交换了压入了堆栈的参数的值;
- 这就是C语言的传值调用:传值,是在堆栈中进行的。
- 为什么改为* swap就工作了呢? 因为传入了实参的地址。

- 还是传值调用,但是传递的是地址。
- 使用地址的swap,就是正确的swap了。
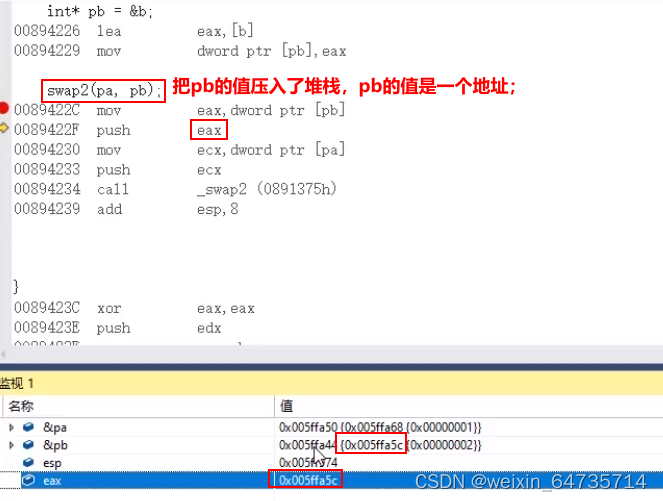
- 无论传递的啥,都是一份拷贝。在堆栈区中的一堆值。
- 只是里面有地址,可以使用这些地址。
- 操作的是:*px, *py;
- C语言是以传值的方式完成函数调用。
5.2 指针与函数参数
- 数组标号是一个常量;
-


- padding, 32位系统,4字节对齐;64位系统,8字节对齐。
- 网络传输的时候,可以不Padding;
- 指针类型,在跳指针的的时候,决定了跳多少大小。
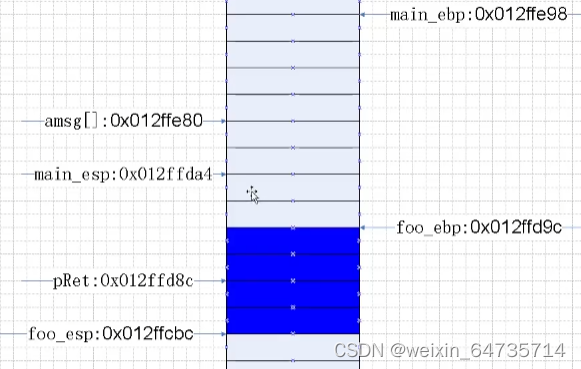
- amsg在堆栈变量中;pmsg指向的地址,不在堆栈中,虽然这个变量在堆栈中,但是其指向的是一个字符串常量,所以指向的内容不在堆栈内存中。
- 字符串常量是全局有效的。

- 堆栈的内存是在反复使用,局部变量字符串数组,就在调用函数的堆栈中。局部变量字符串数组是不可以的,是垃圾信息;从调用函数堆栈出来之后,就变化了。
- 字符串常量的地址,在程序的终身都是有效的。
- strlen计算字符串的长度
- 使用指针来计算字符串的长度;
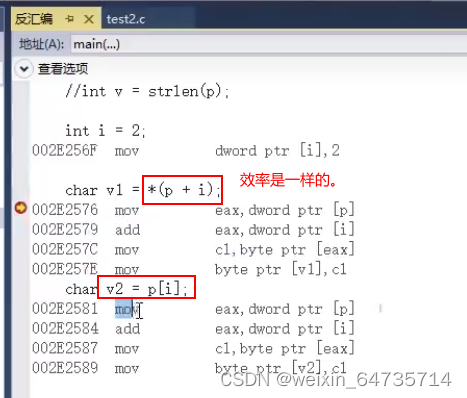
- s[i]与*(s+i)的效率,谁最高?

- strcpy 字符串拷贝
05_0500 5.5 字符指针与函数
char amsg[]与char*pmsg的区别
1.amsg指向的地址位于堆栈之内
2.pmsg指向的地址位于堆栈之外
- 它指向的字符串常量是全局有效的;
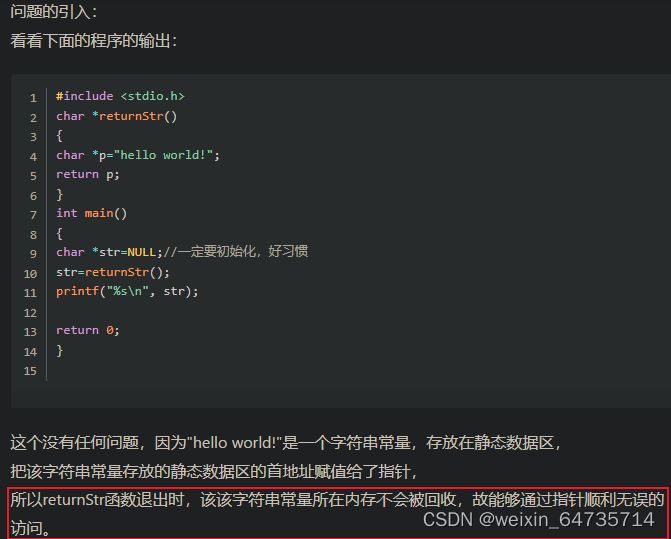
3.字符串常量可读,是否可写是未定义的
4.字符串常量可用于函数返回值,但局部变量字符串数组就不可以了(事实证明)
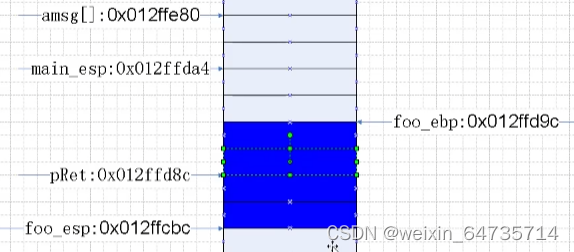
- 堆栈平衡:就是从调用函数foo返回到Main函数的堆栈;
- pRet在堆栈退出后,就变成了垃圾信息;虽然内存的数据没有被擦除,但是已经变成了垃圾信息;
- foo_ebp这个地址又变成了voo的栈;所以栈是在重复使用的;
- 由于返回的是字符串常量;虽然pRet的返回值是在foo函数堆栈中;但是
- 参考:函数返回值与栈: 函数返回值与栈_Learning_zhang的博客-CSDN博客_函数返回值在栈上吗
- ① 函数的返回值,是通过寄存器来返回的;当返回数值、指针、结构体时,有些许差异;见:https://blog.csdn.net/Learning_zhang/article/details/52389035
- ② 所以返回指针时,指针的内容必须指向一个仍然存在区域;如果指向了别的,就会发生错误!所以最好是看看,指针有没有指向了被调用函数!
- https://www.jianshu.com/p/21b5b720fb75
- 所有的字符窜常量都被放在静态内存区
因为字符串常量很少需要修改,放在静态内存区会提高效率
- 所有的字符窜常量都被放在静态内存区


以下一个函数来举例说明:
int add(int x,int y)
{
int z=x+y;
return z;
}
int main()
{
int sum=add(3,4);
return 0;
}
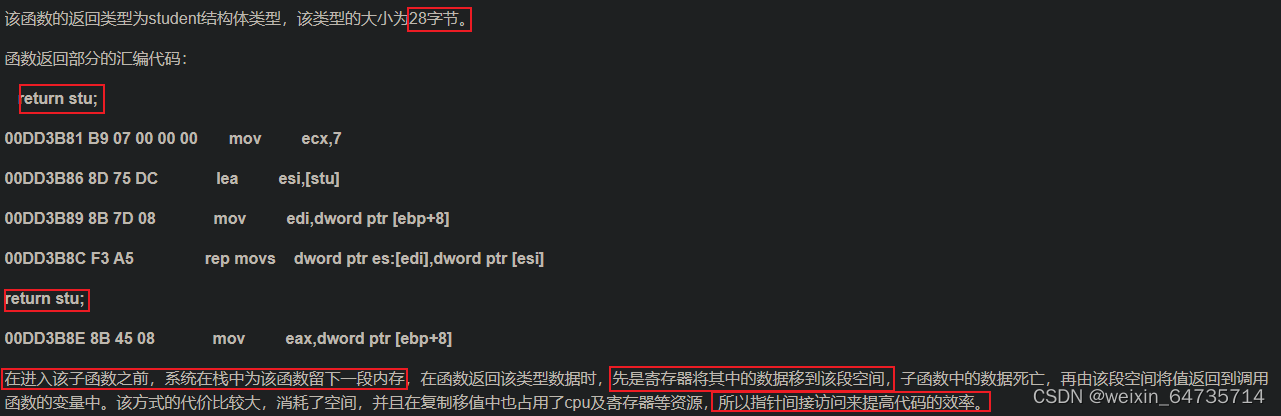
该函数返回部分的汇编代码:
return z;
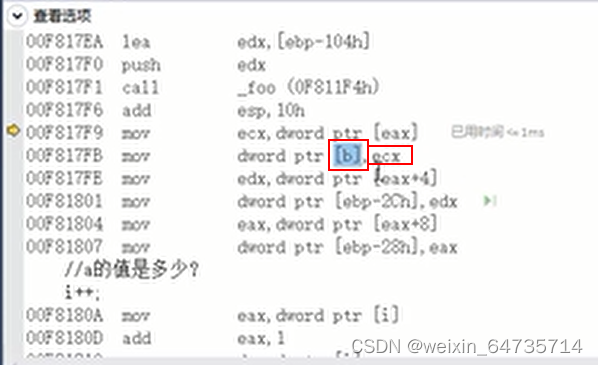
001813F7 8B 45 F8 mov eax,dword ptr [z]
return这一段中,可以看到z中计算好的数据移到eax寄存器中,由eax寄存器将值带给调用该函数的函数变量。
在返回这些类型时,系统将该函数所要返回的值移到寄存器中,栈顶指针下移,栈中的局部变量都死亡,寄存器中的数据再返回给调用该函数的函数所要接收的变量。
————————————————
版权声明:本文为CSDN博主「Learning_zhang」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接: https://blog.csdn.net/Learning_zhang/article/details/52389035

- 字符串长度
s与*(s+i)的效率之差
*s++与*--p的意思
用执行结果来查看其意思,如果考试需要,请记住
代码:http://q1024.com/p/item.php?u=krc
视频:https://www.bilibili.com/video/BV12L4y1Y76R?p=43


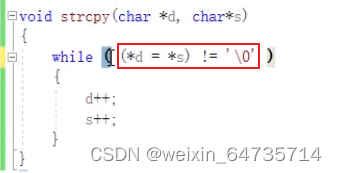
- strcpy
- // 注意:括号内有复制;
- 可以假设和思考一下,复制的整个过程是如何进行的;
- strncpy 只复制一部分;万一空间不够呢?

- strcat;
- strncat;
- strcmp; 比较两个字符串
- strncmp;之比较前几个;
- strend(s,t) t是否存在s的尾部
不建议一条写两条语句,最好容易理解,一条就写一条;
习题答案见:krx50500.c
05_0600 5.6 指针数组以及指向指针的指针
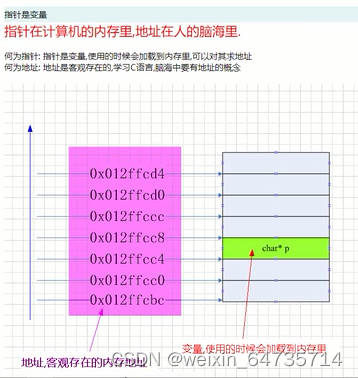
指针是变量
指针在计算机的内存里,地址在人的脑海里.
何为指针: 指针是变量,使用的时候会加载到内存里,可以对其求地址
何为地址: 地址是客观存在的,学习C语言,脑海中要有地址的概念
代码:http://q1024.com/p/item.php?u=krc
视频:https://www.bilibili.com/video/BV12L4y1Y76R?p=44
文本行;排序;输出;
#include <stdio.h>
#include <string.h>
#define MAXLINES 5000 /*进行排序的最大文本行数*/
char *lineptr[MAXLINES]; /*指向文本行的指针数组*/
#define MAXLEN 1000 /*每个输入文本行的最大长度*/
#define ALLOCSIZE 10000 /*可用空间大小*/
static char allocbuf[ALLOCSIZE]; /*alloc使用的存储区*/
static char *allocp = allocbuf; /*下一个空闲位置*/
char *alloc(int n);
int getline(char s[], int lim);
int readlines(char *lineptr[], int nlines);
void writelines(char *lineptr[], int nlines);
void swap(char *v[], int i, int j);
void qsort(char *lineptr[], int left, int right);
/*对输入的文本行进行排序*/
int main()
{
int nlines; /*读取的输入行数目*/
if ((nlines = readlines(lineptr, MAXLINES)) >= 0)
{
qsort(lineptr, 0, nlines - 1);
writelines(lineptr, nlines);
return 0;
}
else
{
printf("error: input too big to sort\n");
return 1;
}
}
/*返回指向n个字符的指针*/
char *alloc(int n)
{
/*有足够的空闲空间*/
if (allocbuf + ALLOCSIZE - allocp >= n)
{
allocp += n;
return allocp - n;/*返回分配前的指针p*/
}
else /*空闲空间不够*/
{
return 0;
}
}
/*getline函数: 将一行读入到s中并返回其长度*/
int getline(char s[], int lim)
{
int c, i;
for (i = 0; i < lim - 1 && (c = getchar()) != EOF && c != '\n'; ++i)
{
s[i] = c;
}
if (c == '\n')
{
s[i] = c;
++i;
}
s[i] = '\0';
return i;
}
/*读取输入行*/
int readlines(char *lineptr[], int maxlines)
{
int len, nlines;
char *p, line[MAXLEN];
nlines = 0;
while ((len = getline(line, MAXLEN)) > 0)
{
if (nlines >= maxlines || (p = alloc(len)) == NULL)
{
return -1;
}
else
{
line[len-1] = '\0';/*删除换行符*/
strcpy(p, line);
lineptr[nlines++] = p;
}
}
return nlines;
}
/*写输出行*/
void writelines(char *lineptr[], int nlines)
{
while (nlines-- > 0)
printf("%s\n", *lineptr++);
}
void swap(char *v[], int i, int j)
{
char *temp;
temp = v[i];
v[i] = v[j];
v[j] = temp;
}
/*按递增顺序对v[left] ... v[right]进行排序*/
void qsort(char *v[], int left, int right)
{
int i, last;
if (left >= right)
return ;
swap(v, left, (left+right)/2);
last = left;
for (i = left+1;i <= right; i++)
if (strcmp(v[i], v[left]) < 0)
swap(v, ++last, i);
swap(v, left, last);
qsort(v, left, last-1);
qsort(v, last+1, right);
}
5-7 重写函数readlines,将输入的文本行存储到由main函数提供的一个数组中,而不是存储到调用alloc分配的存储空间中。该函数的运行速度比改写前快多少?
readlines将读取的输入行保存在主函数提供的数组 `linestor` 中。字符指针 `p` 的初值指向 `linestor` 的第一个元素。
这个版本的readlines函数因为不去频繁申请新的存储空间,速度会比原始版本稍快。
- 但在现在CPU的速度,已经不比之前快多少了;
int readlines(char *lineptr[], char *linestor, int maxlines){
int len, nlines;
char line[MAXLEN];
char *p = linestor;
char *linestop = linestor + MAXSTOR;
nlines = 0;
while((len = getline(line, MAXLEN)) > 0){
if(nlines >= maxlines || p + len > linestop)
return -1;
else{
line[len - 1] = '\0'; // 删除换行符
strcpy(p, line);
lineptr[nlines++] = p;
p += len;
}
}
return nlines;
}
/*读取输入行*/
int readlines(char *lineptr[], int maxlines)
{
int len, nlines;
char *p, line[MAXLEN];
nlines = 0;
while ((len = getline(line, MAXLEN)) > 0)
{
if (nlines >= maxlines || (p = alloc(len)) == NULL)
{
return -1;
}
else
{
line[len-1] = '\0';/*删除换行符*/
strcpy(p, line);
lineptr[nlines++] = p;
}
}
return nlines;
}第二个有alloc,稍微慢一点;
05_0700 5.7 多维数组
多维数组在内存中的表现形式
定义数组的方法 变量名[行][列]
char arr[2][3] = {'a','b','c','1','2','3'}; //2表示行,3表示列
多维数组作为函数参数
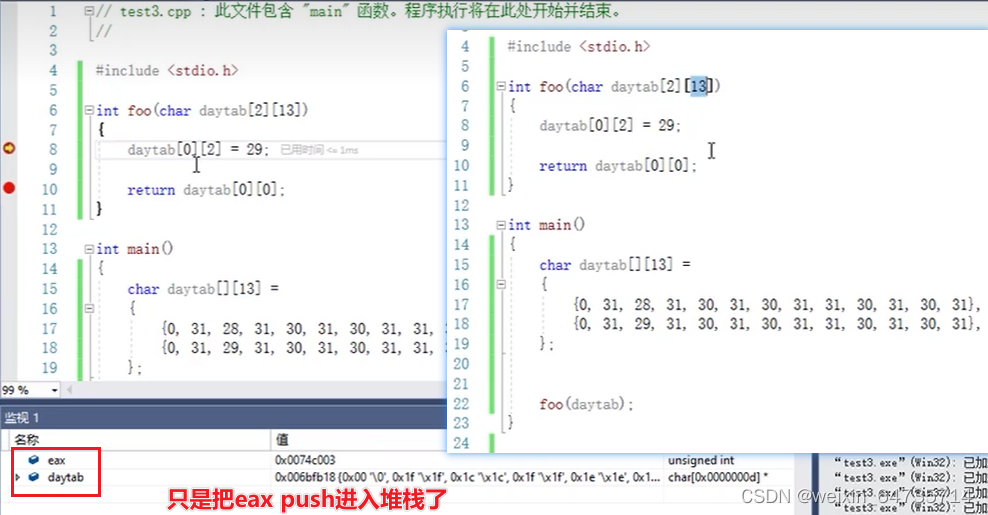
f(int daytab[2][13]) //OK 虽然参数传的是数组,但是已经退化为指针了;反汇编push的只有一个数组首地址;
f(int daytab[][13]) //OK 列的信息是不可少的;13在数组内容索引中是有帮助的;首地址为基准,列多少,来访问内容;
f(int (*daytab)[13]) //OK 用得少;
int *daytab[13] //ERROR
代码:https://q1024.com/p/item.php?u=krc
视频:http://www.bilibili.com/video/BV12L4y1Y76R?p=45
- 二维数组一定要知道列是多少个;它可以根据内存来计算行多少;这样指针跳的时候才知道跳到哪里。
- 数组不越界就可以了;一般只进行一般的检查;如果需要检查的很多的话,还不如调用者自己检查;
- 检查参数可以做的非常详细;有时候检查的参数量就非常大;
- 可以保证:基本不崩溃;是基本的要求
- 二位数组用的很少;因为可以用一维数组来替换;
- 图片,都是一个线性数组;自己控制行和列;
- 可以定义为一个结构体;二维数组可以扁平化;
- 所以二维数组用的不是特别多
05_0800 C程序内存布局
环境变量PATH举例
windows下修改环境变量: 高级系统设计->高级->环境变量
linux下修改环境变量: export PATH=/home/uxingzaicpp/tmp4del/123PATH
- 在环境变量里面的程序,可以直接打开;
- 无论在哪个路径下都可以直接打开程序;
- C语言可以获取环境变量的值:getenv
- 命令行参数:echo $PATH;第0个命令行参数,就是程序名称;
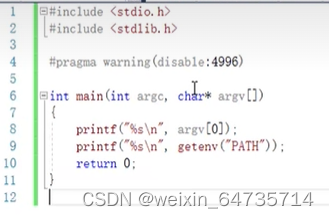
argv[0]是命令行第一个参数,就是程序自己的名字;
参数arg
C程序内存布局
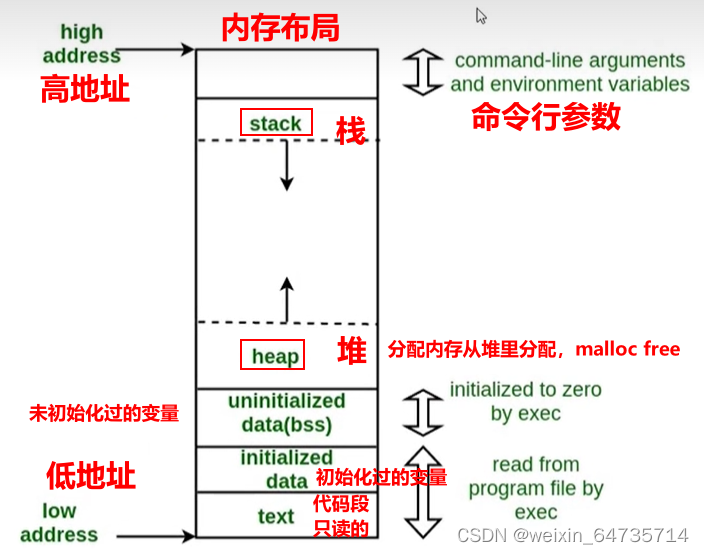

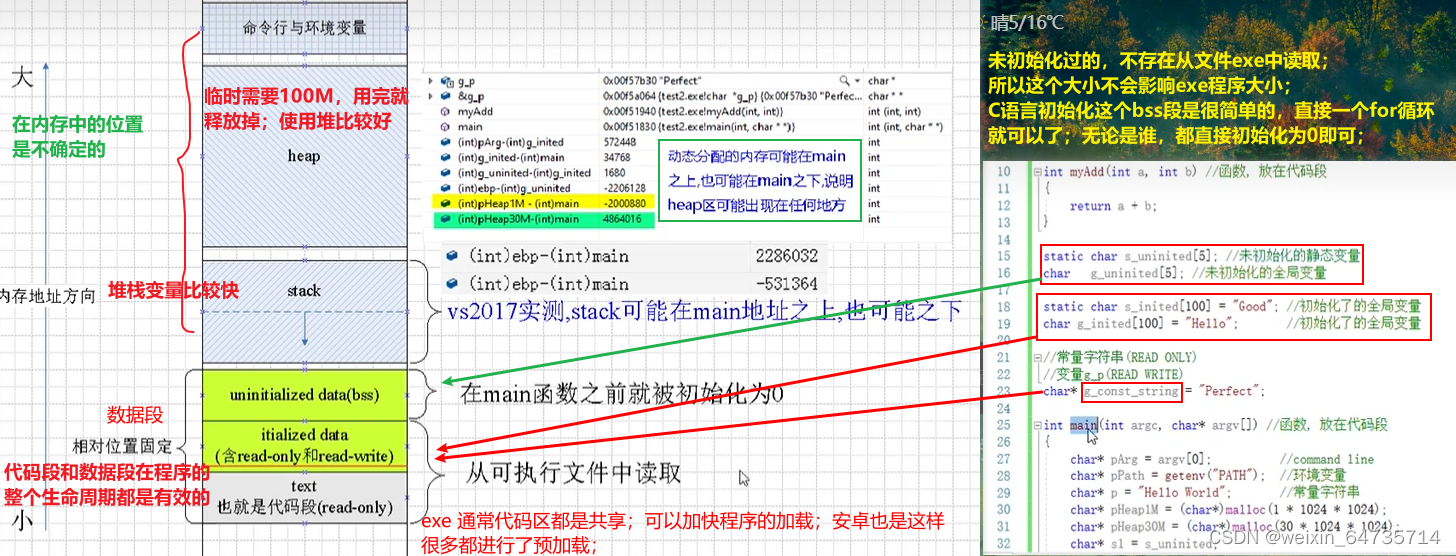
- 可能难的不是指针,而是搞不懂内存;
- 从宏观的方向去理解指针;
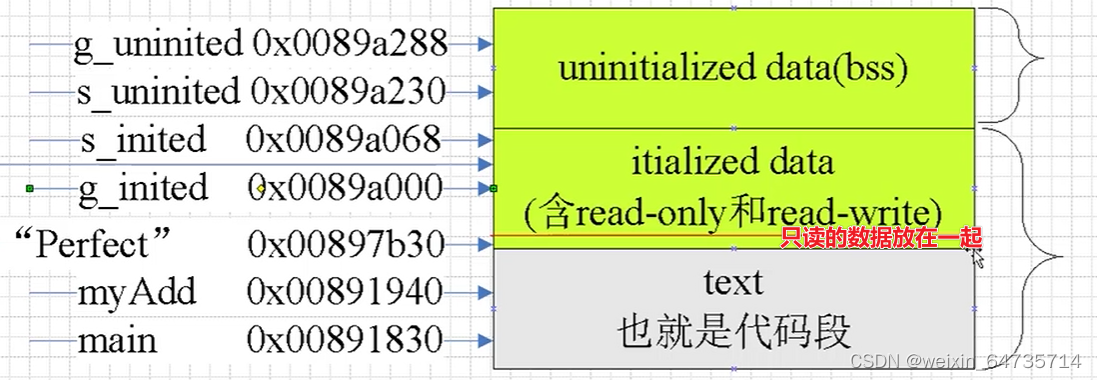
代码:http://q1024.com/p/item.php?u=krc
视频:https://www.bilibili.com/video/BV12L4y1Y76R?p=46
05_0801 5.8 指针数组的初始化 5.9 指针与多维数组
5.8 指针数组的初始化
- int a[12]
- int* a[12] 就是一个指针数组
- 指针指向哪里都可以;*p读地址的内容,就要考虑了。
5.9 指针与多维数组
矩阵下标的计算公式: 列宽*row + col
代码:http://q1024.com/p/item.php?u=krc
视频:https://www.bilibili.com/video/BV12L4y1Y76R?p=47
05_0900 5.10 命令行参数
char **argv 与 char* argv[] 作为函数参数等价,正如char* s与char s[]一样
char* argv[] char* s
char* *argv char s[]
int main(int argc, char* argv[])
{
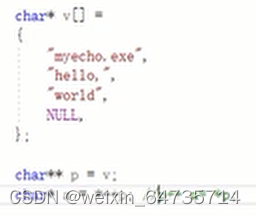
char* v[] =
{
"myecho.exe",
"hello,",
"world",
NULL,
};// 这是一个指针数组,每个元素是一个指针,所以大小应该是3或者4;每个p+1,就指向了下一个内容
char** p= v;
char* a = *(++p);
//对比q讲解argv
}
- 如何自己解析:argv[]的内容;获取输入的字符串?『可以自己写的』
- 解析字符串——必须要掌握的技能;具有的起码的能力
- *++argv是啥意思?
- *(++argv)指针先+1;
- v是一个指针数组,数组中的每一个内容是一个指针;
- p指向了v的第一个数组指针;
- char* a = *(++argv); argv本来是二级指针,*argv就变成了一级指针;
- 所以a指向了每一个字符串;
- a和p都是指向了hello,很奇怪;为什么*(++p)导致a和p都指向了下一个字符串呢?
- 解释 *++argv (*++argv)[0] *++argv[0]
- 不建议写这种复杂不容易读的东西
- []与操作数结合的优先级比*和++高
代码:http://q1024.com/p/item.php?u=krc
视频:https://www.bilibili.com/video/BV12L4y1Y76R?p=48
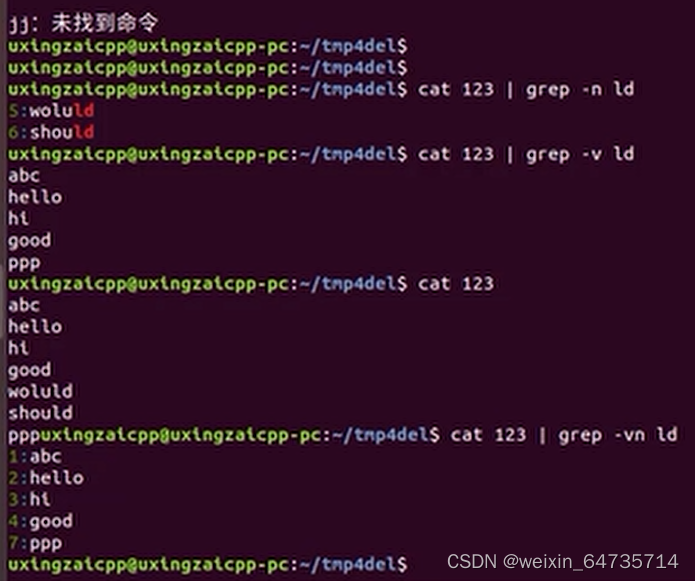
- find同linux下的grep函数作用相当;
- cat 123 | grep |的意思是将cat的输出作为grep的输入;
- grep -n ld 输出ld的行号;
- grep -v ld 反向输出不含有Ld的行;
- grep -vn ld
- 书上的find函数
#include <stdio.h>
#include <string.h>
#define MAXLINE 1000
int getline(char *line, int max);
/*find函数:打印与第一个参数指定的模式匹配的行*/
main(int argc, char *argv[])
{
char line[MAXLINE];
long lineno = 0;
int c, except = 0, number = 0, found = 0;
while (--argc > 0 && (*++argv)[0] == '-')
{
while (c == *++argv[0]) // 这里两种写法不一样,这里是挨个访问字符
{
switch (c)
{
case 'x':
except = 1;
break;
case 'n':
number = 1;
break;
default:
printf("find: illegal option %c\n", c);
argc = 0;
found = -1;
break;
}
}
}
if (argc != 1)
{
printf("Usage: find -x -n pattern\n");
}
else
{
while (getline(line, MAXLINE) > 0)
{
lineno++;
if ((strstr(line, *argv) != NULL) != except)
{
if (number)
printf("%ld: ", lineno);
printf("%s", line);
found++;
}
}
}
return found;
}
int getline(char *line, int max)
{
int c, i;
for (i = 0; i < max - 1 && (c = getchar()) != EOF && c != '\n'; ++i)
{
line[i] = c;
}
if (c == '\n')
{
line[i] = c;
++i;
}
line[i] = '\0';
return i;
}
05_0901 5.10 命令行参数 - 练习
编写程序expr
编写程序tail
代码:http://q1024.com/p/item.php?u=krc
视频:https://www.bilibili.com/video/BV12L4y1Y76R?p=49
tail 输出文本的末尾多少行;适用于读取最新的log日志;
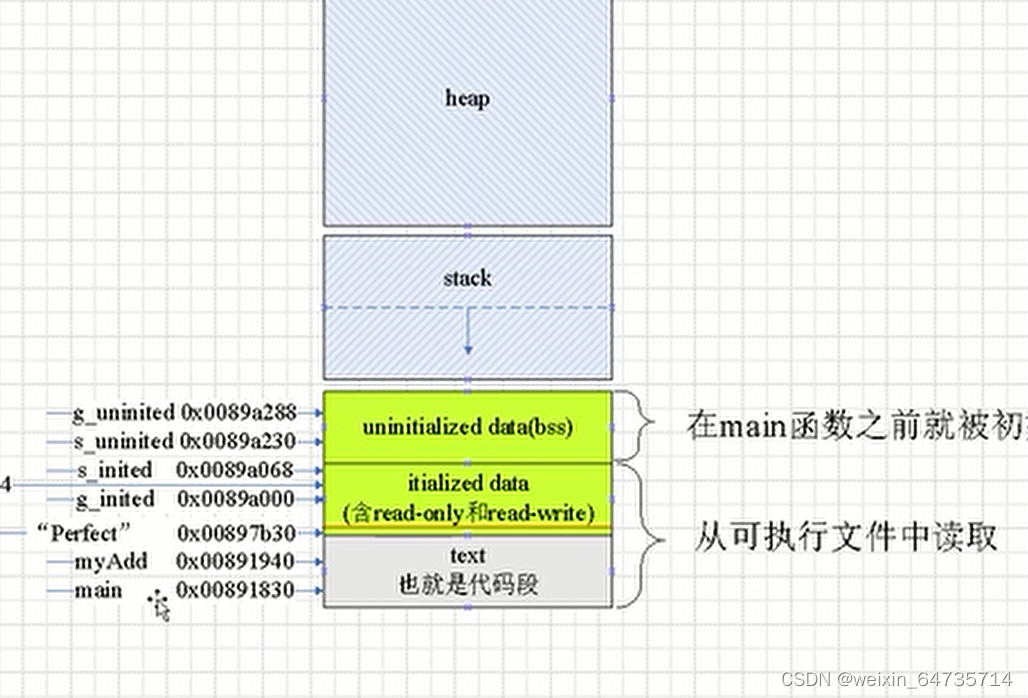
05_1000 5.11指向函数的指针
函数指针里存放的值不是函数地址,而一个跳转指令
- 一个函数是有地址的;char* p = (char *)myAdd; p的值和myAdd的值略微有点不同;前面是一个e9指令
- 这个跳转指令,最终会跳到函数地址
- E9就是jmp:相对跳转指令
- 计算公式:E9后面的地址 = 目标地址myAdd - 当前地址p - 5

从指针说起
1.定义一个指针变量,比如说int* a; 那么*a就可以改变指针a指向的地址的内容
2.定义一个函数变量,比如说func f; 那么(*f)就可以调用f指向的内容的函数, *可以省略
编写程序tail
- 如何通过指针p去执行这个函数呢?
函数指针类型和int a没什么分别
普通函数秒变函数指针类型
代码:http://q1024.com/p/item.php?u=krc
视频:https://www.bilibili.com/video/BV12L4y1Y76R?p=50


05_1001 5.11指向函数的指针 - 练习 5.12复杂声明的前5个例子
逆序排序
不区分大小写排序
指向二维数组的指针
代码:http://q1024.com/p/item.php?u=krc
视频:https://www.bilibili.com/video/BV12L4y1Y76R?p=51

复杂声明

- int (*daytab)[13] 指向维维数组的一个指针;指向了datab[13]的指针;
- 最后两个遇到的比较少;
第六章 结构
《跟着星仔学C语言》第六章 结构 - xingzaicpp - 博客园
06_0100 6.1 结构的基本知识 6.2 结构与函数
关键字struct后面的名字是可选的
结构体的sizeof与字节对齐
- C++的类是从结构体扩展出去的;
- 编译器喜欢对齐的内存;12个字节;
- 多理解,多思考;少死记硬背;少当规则处理;多应用;
- arm访问不是字节对齐的地址,就会崩溃;
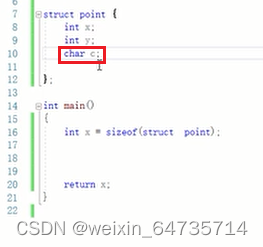
结构体的初始化可以在定义的后面使用初值表进行
struct point maxpt = {320, 200};
结构体的合法操作
1.整体的复制和赋值
2.通过&运行取地址
3.访问其成员
4.结构体无法直接进行比较是否相等(但有其他方法)
memcmp可以比较:比较内存;比较两个内存是否相等;<string.h>
- memcmp(&x, &t, sizeof(struct point)); 比较两个结构体的内存是否相等;
p->结构成员快速访问结构成员
在函数参数中, 结构体参数和普通参数一样,都是传值调用
- 拷贝了一份到堆栈里面;
如果返回值是结构体,那也是对结构体进行了拷贝
- 之前返回Int是在一个寄存器里面放堆栈的返回值;
- 但是结构体的话,寄存器不够用,寄存器只有4个字节;
- 效率就是比较低的;
- 现在的计算机比较高;有些不是极致优化的代码也不是大问题;
- 传指针;
代码:http://q1024.com/p/item.php?u=krc
视频:https://www.bilibili.com/video/BV12L4y1Y76R?p=52
06_0200 6.3 结构数组
exe的生成过程
参考:05_0300 5.3 指针与数组

- sizeof 计算数组长度;动态计算;不需要因为类型而改变;微软有 ARAYSIZE宏
代码:http://q1024.com/p/item.php?u=krc
视频:https://www.bilibili.com/video/BV12L4y1Y76R?p=53
06_0300 6.4 指向结构的指针
1字节对齐
参考:05_0400 5.4 地址算术运算
地址随便算,只要你知道你在干什么就行
个人觉得, &tab[-1]和&tab[n] 都是有效的,但你要知道指针指到哪里去了
- java没有指针;有时候需要将指针改为java;
- 结构体中还有字节对齐;注意其地址计算的问题;
代码:http://q1024.com/p/item.php?u=krc
视频:https://www.bilibili.com/video/BV12L4y1Y76R?p=54
06_0400 6.5 自引用结构
二叉树
1.任意结点的左子树比该结点小,右子树比该接点大
2.二叉树的特殊形式就是链表
- 统计单词次数
- 二叉树
- 结构体包含自身的实例是非法的;
- 定义一个结构体必须要知道自己的大小是多大?但是left和right就不知道了
- 所以只能搞一个指针;指针的大小总是固定的;所以叫做自引用结构。

代码:http://q1024.com/p/item.php?u=krc
视频:https://www.bilibili.com/video/BV12L4y1Y76R?p=55
06_0500 6.6.0 单链表
单链表的构造
单链表的查找

代码:http://q1024.com/p/item.php?u=krc
视频:https://www.bilibili.com/video/BV12L4y1Y76R?p=56
06_0510 6.6.1 删除节点与哈希
1.从单链表中删除一个结点
2.讲解计算机领域内的hash是什么意思
- 如果数据规模太大的怎么办?
- 降低数据规模;通过长度来降低数据规模
- 哈希,主要是为了让查找变得更加高效;
- 比较好的哈希算法是:散列列表比较均匀;这样啊每次的查找时间都差不多;就最好;


代码:http://q1024.com/p/item.php?u=krc
视频:https://www.bilibili.com/video/BV12L4y1Y76R?p=57
06_0520 6.6.2 插入节点与表查找
1.在单链表中插入结点
2.讲解书中6.6节的内容
代码:http://q1024.com/p/item.php?u=krc
视频:https://www.bilibili.com/video/BV12L4y1Y76R?p=58
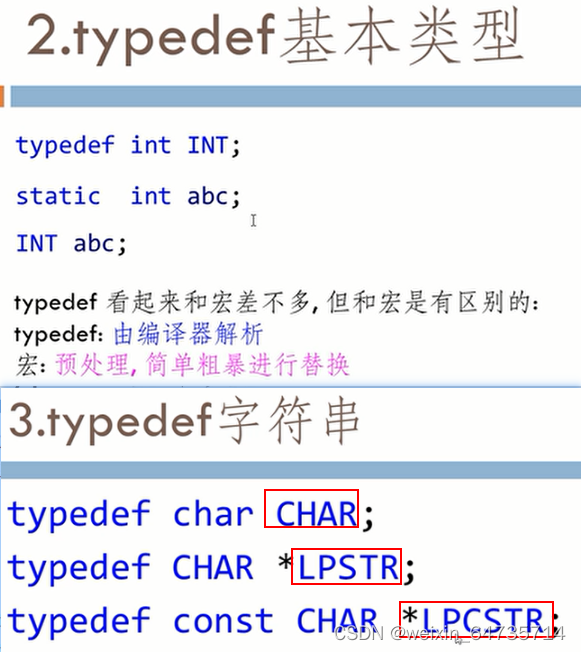
06_0600 6.7 类型定义(typedef)
1.typedef 重定义基本数据类型
2.typedef 重定义字符串
3.typedef 重定义结构体
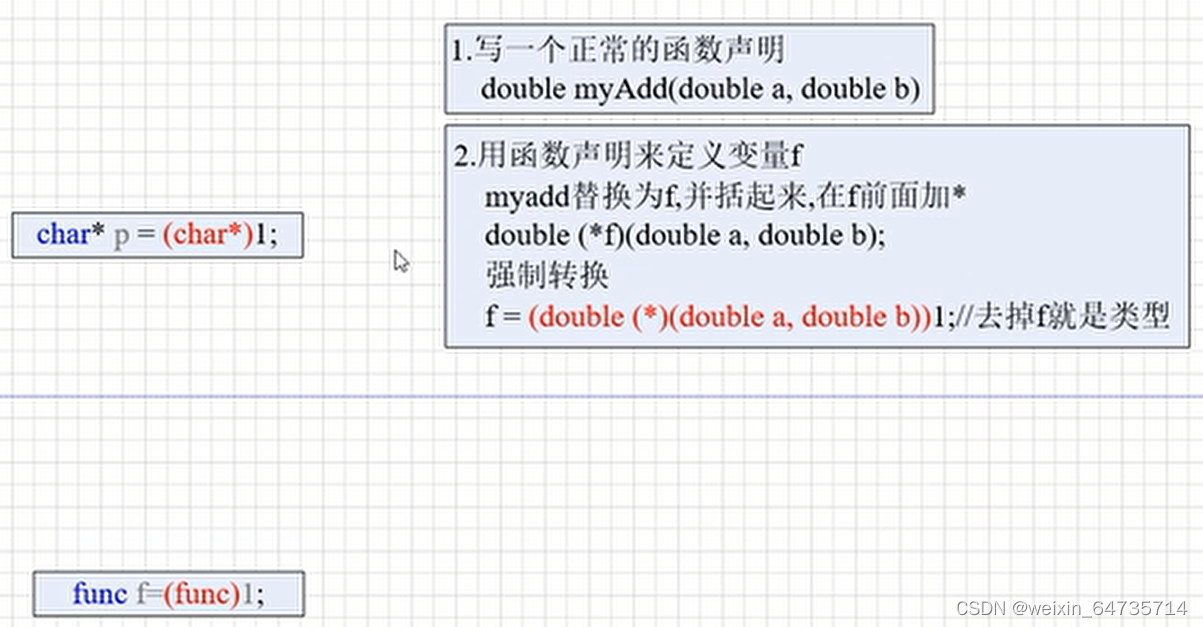
4.typedef 重定义函数指针
- 把现有类型用一个新的类型来表示


- typedef 重定义函数指针
-

代码:https://q1024.com/p/item.php?u=krc
视频:https://www.bilibili.com/video/BV12L4y1Y76R?p=59


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









