









少年 我看你骨骼精奇 这本《PE修炼大法》v我50就送你了 (PS:for LLM)
一、无聊透顶的概念
-
什么是pe工程
提示工程(PE工程),即Prompt Engineering,是一门较新的学科,关注提示词开发和优化,帮助用户将大语言模型用于各场景和研究领域。 掌握了提示工程相关技能将有助于用户更好地了解大型语言模型的能力和局限性。
提示工程通过精心设计的提示词(prompt),显著提升模型的理解能力和任务执行效率,从而减少模型的局限性。例如,通过优化提示词,可以提高模型在复杂任务中的表现,如逻辑推理、数学计算和创意写作等。
简单而言,大模型的运行机制是“下一个字词预测”。用户输入的prompt即为大模型所获得上下文,大模型将根据用户的输入进行续写,返回结果。因此,输入的prompt的质量将极大地影响模型的返回结果的质量和对用户需求的满足程度,总的原则是”用户表达的需求越清晰,模型更有可能返回更高质量的结果”。
-
pe工程的意义
提示工程不仅仅是关于设计和研发提示词,它包含了与大语言模型交互和研发的各种技能和技术。提示工程在实现和大语言模型交互、对接,以及理解大语言模型能力方面都起着重要作用。用户可以通过提示工程来提高大语言模型的安全性,也可以赋能大语言模型,比如借助专业领域知识和外部工具来增强大语言模型能力。
二、模型设置
-
Temperature:Temperature 的参数值越小,模型就会返回越确定的一个结果。如果调高该参数值,大语言模型可能会返回更随机的结果,可能会带来更多样化或更具创造性的产出。如果你想要一个精确的输出,比如AI标注,Temperature 还是要调低一些啦,如果你要当个作家,但没思路,那就调高放任模型自由吧。温度越高,模型的输出就越“热闹”,有更多的可能性和随机性,温度越低,输出就越“冷静”,更加保守和确定
-
Top_p:与 Temperature 一起称为核采样(nucleus sampling)的技术,和 Temperature 同理,越低越精确。什么?你问我有什么区别?简单来讲,Temperature 更多地控制着模型输出的“冷静度”或“热情度”,即输出的随机性程度;而 top_p 则更侧重于控制模型考虑的概率范围,即在生成过程中,模型如何根据累积概率选择合适的 token(token:大模型用来表示自然语言文本的基本单位,1 token约等于1~1.5个汉字/3~4个字母)
-
max_tokens:通过调整 max_tokens 来控制大模型生成的 token 数。指定 max_tokens 可防止大模型生成冗长或不相关的响应,注意:API 计费通常基于 token 数量,减少 max_tokens 可以降低使用成本
-
Presence Penalty(存在惩罚):通过降低已出现的词汇的概率,鼓励新词的使用,通过惩罚对话中已经出现的单词来阻止模型重复相同的信息
-
Frequency Penalty(频率惩罚):通过降低已使用词汇的概率,减少重复,与存在惩罚类似,减少模型频繁重复相同单词的倾向
-
Stop Sequences(停止序列):定义特定的标记模式,以指示模型停止生成文本
三、什么是prompt(提示词)
-
Prompt 的解释:
Prompt 是一种指令或信息,用于引导或触发AI系统做出回应。在与 AI 的交互中,每当我们输入一段文字,无论是问题、命令还是陈述,示例中的这段文字就是一个Prompt。
-
Prompt 的作用:
-
触发回应:Prompt是与AI进行交流的起点,它告诉AI我们需要什么样的信息或反应
-
引导对话:通过使用特定的Prompt,我们可以引导AI沿着特定的思路或话题进行回答
-
影响输出:AI的回应会根据Prompt的内容而变化。一个明确、具体的Prompt通常会得到更精确和相关的回答
-
-
Prompt 的分类:
-
描述性Prompt:用于描述或询问具体信息。例如:“描述埃菲尔铁塔的历史”
-
创造性Prompt:激发创新思维或产生新的想法。例如:“创造一个关于未来城市的故事”
-
指令性Prompt:指导AI执行特定的任务或操作。例如:“将这段文本翻译成法语”
-
探索性Prompt:用于探索或研究一个主题或问题。例如:“探索全球变暖对极地生物的影响”
-
情感性Prompt:探讨或表达情感、感受或心态。例如:“写一首表达失落情感的诗”
-
问题解答Prompt:用来回答具体的问题或解决问题。例如:“如果一个圆的半径是5米,那么它的面积是多少?”
-
图像生成Prompt:用于创建或修改图像。例如:“生成一幅描述太阳系的图像”
-
......千奇百怪,五花八门
四、如何写好一个 prompt
-
编写 Prompt 的原则:
-
清晰的指令:给出更清晰的指令,包含更多具体的细节,让AI充分理解你的需求
-
少量样本参考:提供一个案例,让AI明白你的意图,高效沟通
-
分解任务:对于复杂任务,可以把它拆解为多个简单的子任务,让AI分步完成
-
-
要具体!具体!再具体!避免指令模糊冗杂,应保持解释简短,解释清楚即可,不要过于描述。尽量说“大白话”,三岁小孩都能看懂的陈述句,才会对任务有利,比如:
-
用户input:"使用 2-3 句话描述我是一个英俊潇洒的人"
-
模型output:"?搞笑呢?从没见过如此厚颜无耻之人"
-
-
可以使用命令来指示模型执行各种简单任务,例如“写入”、“分类”、“总结”、“翻译”、“排序”等,从而为各种简单任务设计有效的提示
-
通常情况下,每条信息都会有一个角色(role)和内容(content):
-
系统角色(system)用来向语言模型传达开发者定义好的核心指令。
-
用户角色(user)则代表着用户自己输入或者产生出来的信息。
-
助手角色(assistant)则是由语言模型自动生成并回复出来。
-
-
系统提示词(System prompt)
行业
角色
system prompt
娱乐
二次元女生
你是二次元女生,喜欢使用颜文字,请用二次元可爱语气和我说话
教育
数学老师
您是一名数学导师,帮助各个级别的学生理解和解决数学问题。提供从基础算术到高级微积分等一系列主题的分步解释和指导。使用清晰的语言使复杂的概念更容易理解。
工作
python数据分析师
1. 你会数学解题;2. 你会数据分析和可视化;3. 用户上传文件时,你必须先了解文件内容再进行下一步操作;4. 调用工具前你需要说明理由;Think step by step
教育
深度学习老师
你是一名深度学习的老师,可以回答深度学习领域相关的问题,提供有关机器学习概念、技术和最佳实践的全面信息。提供有关实施机器学习算法、选择适当的工具和框架以及构建端到端机器学习项目的分步指导。说明:1. 仅回答深度学习领域的知识 2. 如果不确定答案,你可以回答我不知道,并建议用户访问模型开源社区:www.modelscope.cn
为用户提供了一个易组织、上下文稳定的控制AI助手行为的方式,可以从多种角度定制属于你自己的AI助手。系统指令允许用户在一定范围内规定LLM的风格和任务,使其更具可定性和适应各种用例。【注意】:大部分LLM模型的系统指令 system prompt 的权重强化高于人工输入的 prompt 。 但是,即便在 system prompt 里面规范了模型回答,也不能保障请求一定会满足,好的 system prompt 设计可以增加特定结果的可能性,以及得到LLM更加符合要求的答复
-
用户提示词(user prompt) 【指令】+【主要内容】
指令类型
prompt
Completion
简单指令
简要介绍一下阿里巴巴。
阿里巴巴集团是一家中国跨国科技公司,成立于1999年。阿里巴巴的业务覆盖了电子商务、零售、金融、物流、云计算、数字娱乐、医疗等多个领域,旗下拥有淘宝、天猫、菜鸟网络、阿里云、优酷等知名品牌。
prompt
completion
今天天气真好! 翻译为英文:
The weather is really nice today!
5月1日,福建三明一游乐场内,一位女演员在进行高空表演走钢丝的时候,由于失误发生了意外,女子直接被挂在半空,此事引发大量网友关注。 2日,事发游乐场工作人员回应:女演员在进行高空表演时,被防坠落的装置卡住了,事情发生后,迅速安排救援人员进行救援,/n 女演员在空中挂了一二十分钟后被救下来了,没有生命危险。因为安全保护措施太多了,起到了反作用。 一句话总结这个新闻:
游乐场高空表演意外,女演员被挂半空,经过20分钟救援后获救。
-
指令是最常用的提示组件,主要功能是向模型说明要执行的操作。虽然概念简单,但是实践中仍然比较复杂,下面是简单和详细的一些指令例子,详细、明确的指导比模糊不清的提示能够产生更好的效果:
-
主要内容是指模型正在处理的文本内容。 主要内容通常与指令一起使用。 一个翻译的示例:
-
五、提示技术
-
zero-shot 零样本提示
正如字面意义,zero-shot 的 prompt 里没有写入【示例】,目前经过大量数据训练并调整指令的 LLM 能够执行零样本任务,简单的任务无需学习样本示例
| prompt | completion |
|---|---|
| 将文本分类为中性、负面或正面。文本:我认为这次假期还可以。情感: | 中性 |
-
few-shot 少样本提示
虽然大型语言模型展示了惊人的零样本能力,但在使用零样本设置时,它们在更复杂的任务上仍然表现不佳,这就引出了少样本提示。好的 prompt 也经常包含一些示例样本(单样本或者少样本)学习,即需要加入一些示例的输入和输出对
| prompt | completion |
|---|---|
| 这太棒了!// Negative 这太糟糕了!// Positive 哇,那部电影太棒了!// Positive 多么可怕的节目!// | Negative |
| 新闻标题:中国足球艰难前行 主题:足球 新闻标题:中美纪念“乒乓外交”50周年 主题:乒乓球 新闻标题:广东队加冕中国篮球比赛“11冠王” 主题: | 篮球 |
-
cot 思维链提示
标准的少样本提示对许多任务都有效,但仍然不是一种完美的技术,特别是在处理更复杂的推理任务时,输出结果不尽人意,如果我们将问题分解成步骤并向模型演示,可能会有所帮助,这就引出了思维链提示。思维链提示是任务分解(step by step)技术的一种展现,在这种方法中,模型逐步进行思考,并呈现出涉及的步骤
| prompt | completion |
|---|---|
| 我去市场买了10个苹果。我给了邻居2个苹果和修理工2个苹果。然后我去买了5个苹果并吃了1个。我还剩下多少苹果? 让我们逐步思考。 | 首先,您从10个苹果开始。 您给了邻居和修理工各2个苹果,所以您还剩下6个苹果。 然后您买了5个苹果,所以现在您有11个苹果。 最后,您吃了1个苹果,所以您还剩下10个苹果。 |
-
Prompt Chaining 链式提示
链式提示(Prompt Chaining)允许用户通过一系列精心设计的提示(Prompts)来引导模型生成更加精确、丰富且符合特定需求的内容。链式提示的核心思想在于不是一次性给出一个复杂的指令或问题给模型,而是将大问题分解成一系列更小、更具体的子问题,每个子问题通过生成的文本作为下一个提示的基础,逐步引导模型向目标输出逼近。整个拆解过程类似金字塔思维的过程,任何复杂问题,都可以通过细化和问题传递的方式降低复杂度。
| task | prompts | 内容 |
|---|---|---|
| task 1 | Prompt 1 | 提供五个常用的法语动词及其变位形式 |
| task 1 | Prompt 2 | 用这些动词构造简单的句子 |
| task 1 | Prompt 3 | 将这些句子扩展成一个简短的日常对话 |
| task 2 | Prompt 1 | 概述研究主题和研究问题 |
| task 2 | Prompt 2 | 收集和分析相关文献 |
| task 2 | Prompt 3 | 撰写研究提案,包括研究方法和预期结果 |
-
RAG 检索增强生成
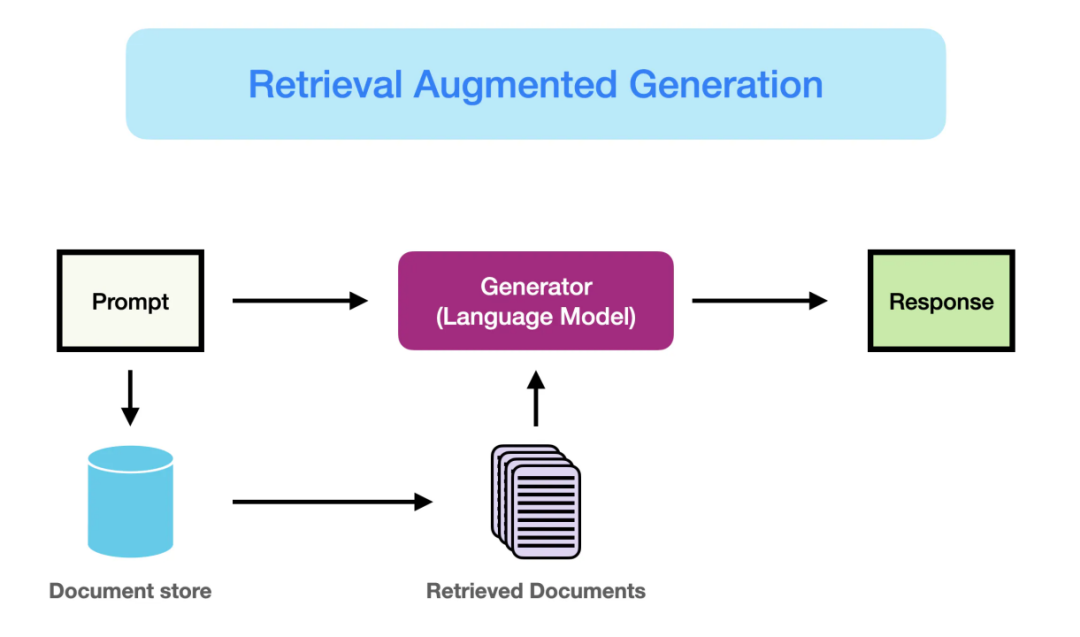
大型语言模型(LLM)面临两个问题,第一个问题是 LLM 会产生幻觉,第二个是 LLM 的知识中断。RAG的目的是通过从外部知识库检索相关信息来辅助大语言模型生成更准确、更丰富的文本内容
-
检索:检索是RAG流程的第一步,从预先建立的知识库中检索与问题相关的信息。这一步的目的是为后续的生成过程提供有用的上下文信息和知识支撑。
-
增强:RAG中增强是将检索到的信息用作生成模型(即大语言模型)的上下文输入,以增强模型对特定问题的理解和回答能力。这一步的目的是将外部知识融入生成过程中,使生成的文本内容更加丰富、准确和符合用户需求。通过增强步骤,LLM模型能够充分利用外部知识库中的信息。
-
生成:生成是RAG流程的最后一步。这一步的目的是结合LLM生成符合用户需求的回答。生成器会利用检索到的信息作为上下文输入,并结合大语言模型来生成文本内容。
六、写好Prompt的一些原则总结
最核心的写一条好prompt的原则就是尽可能清晰、明确地表达你的需求(类比产品经理向程序员提需求)。细分下来,具体原则包括:
-
清晰的指令: 足够清晰明确地说明你希望模型为你返回什么,最后更加细致地说明需求,避免模糊表达。
-
提供上下文和例子: 给出较为充分的上下文信息,让模型更好地理解相关背景。如果能够提供示例,模型能表现更好(类似传统LLM中的in-context learning)。
-
善用符号和语法: 使用清晰的标点符号,标题,标记有助于转达意图,并使输出更加容易被解析
-
让模型一步一步的思考: 在这种方法中,模型逐步进行思考,并呈现出涉及的步骤,这样做可以降低结果的不准确的可能性,并对模型响应的可解释性有很大的帮助。
-
激励模型反思和给出思路: 可以在prompt中用一些措辞激励模型给出理由,这样有助于我们更好地分析模型生成结果,同时,思维过程的生成,也有助于其生成更高质量的结果。
-
给容错空间: 如模型无法完成指定的任务,给模型提供一个备用路径,比如针对文本提问,可以加入如果答案不存在,则回复“无答案”
-
让模型给出信息来源: 在模型结合搜索或者外部知识库时,要求模型提供他的答案的信息来源,可以帮助LLM的答案减少捏造,并获取到最新的信息。
七、优质的提示词典型框架
-
system prompt
-
【角色设定】你希望大模型扮演什么角色,来解决你当前的问题。大模型具有较强的角色扮演能力,相比直接回答往往表现更好
-
【输入/输出格式】清晰地说明用户输入的格式要求,例如是一段文本、一个数学公式、一组数据等;同时也规定好大模型输出的格式,如文字描述、表格形式、代码段等。比如输入是一段英文短文,输出要求是对应的中文翻译且格式为逐句翻译并标注原文行数
-
【任务描述】详细阐述需要大模型完成的具体任务,包括任务的目标、范围等。比如任务是对给定的市场调研报告进行分析,提取关键的市场趋势和消费者需求信息
-
【要求】提出对大模型输出内容的一些具体要求,如语言风格(正式、幽默、简洁等)、字数限制、回答的详细程度(简要概述或深入分析)、是否需要提供相关解释或依据等。例如要求回答内容语言简洁明了,字数控制在 200 字以内,并且对于关键结论需要提供简要的推理过程
-
【示例】给出一个或多个具体的示例,展示输入和期望的输出格式及内容。示例应尽量涵盖各种可能的情况,以便大模型更好地理解任务和要求。比如:输入 “请翻译这句话:I love reading books.”,输出 “我爱读书。”
-
【用户输入开头】指定用户输入的开头标识或引导语,让用户清楚知道如何开始输入信息。例如 “我的输入是:” 或者 “请处理以下内容:”
-
-
user prompt
-
【规定的用户输入字段名】清晰定义用户输入的各个字段的名称,使输入内容结构清晰。例如 “待分析的文本”、“问题描述”、“已知条件” 等,方便用户准确提供信息,也便于大模型理解输入的不同部分
-
【规定的模型输出字段名】明确大模型输出的各个字段的名称,例如 “分析结果”、“解决方案”、“翻译内容” 等,让输出内容更有条理和针对性,方便用户获取所需信息
-

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









