








人生就像一盒巧克力,你永远不知道下一块是什么滋味—阿甘正传
目录
1、函数的嵌套调用和链式访问
1.1嵌套调用
函数的嵌套调用,我们可以理解为函数之间的嵌套类似于循环里面的嵌套一环套一环,只不过循环是可以在循环体内定义一个循环,函数不能在函数体内定义函数。C语言中函数的定义都是相互平行、相互独立的,也就是说在函数定义时,函数体内不能包含另一个函数的定义,即函数不能嵌套定义,但可以嵌套调用。
1.1.1练习
🤼我们来看一个程序,要求是输入一个数,输出从0到这个数的和:
#include<stdio.h>
int set_num(int x)
{
return x + 1;
}
int get_num(int m)
{
int s = 0;
for (int i = 0; i < m; i++)
{
s=s+set_num(i);
}
return s;
}
int main()
{
int n = 0;
scanf("%d", &n);
printf("%d\n", get_num(n));
return 0;
}输入:4 输出:10
此程序就用到了到了嵌套调用,主函数main里面调用了get_num函数,而get_num函数里面调用set_num函数。返回时set_num函数返回get_num函数返回主函数main。也就是调用时候是顺序,返回是逆序。
1.2链式访问
函数的链式访问是把一个函数的返回值作为另一个函数的参数。
🤼举一例子,求字符串长度:
#include<stdio.h>
#include<string.h>
int main()
{
char arr[] = "abcdef";
printf("%d", strlen(arr));
}结果:6
上述程序就是一个简单的链式访问,printf函数里面调用strlen函数的返回值6,从而输出6。
1.2.1练习
🤼♀️我们来看一个程序:
#include<stdio.h>
int main()
{
printf("%d ", printf("%d ", printf("%d ",66)));
return 0;
}输出:66 3 2
为什么会这样呢,最里面的 printf输出66 ,第二个printf输出3 第一printf输出2。注意格式符%d后面有个空格。printf函数返回值类型是整形。因此每次返回的都是前一个字符个数。

2、函数的声明与定义
2.1函数的声明
- 函数的声明一般出现在函数的使用之前。要满足先声明后使用。
- 函数的声明一般要放在头文件中的
函数的声明就是我们要向编译器写出函数的返回类型是声明,函数名是什么,参数是什么。具体函数体是否存在,函数的声明解决不了,我们要看函数的定义。下图就是函数的声明,表明了函数的返回类型,函数名,参数。

2.2函数的定义
函数的定义就是函数体里面的内容,也就是函数的实现功能。下图展示了函数的声明、定义的位置。

2.3函数的声明和定义
函数在被调用前必须要声明自己的返回类型,函数名,参数。
#include<stdio.h>
int main()
{
int a = 0;
int b = 0;
scanf("%d %d", &a, &b);
printf("%d\n",Sum(a, b));
return 0;
}
int Sum(int x, int y)
{
return x + y;
}输入:1 2 输出:3
上述程序输入输出都没什么问题,但是没有在主函数上方声明。导致最后报警告,因此我们应该在主函数上方声明一下。

3、函数的递归
3.1递归是什么,为什么要有递归?
首先我们要知道递归的过程为递推与回归。递归做为一种算法,它是一个过程或函数在定义后在函数本身中自己调用自己的一种算法。它通常把一个大型复杂问题,层层化为原问题相似的小规模问题来求解这讲究递归策略。优点是只需要少量的代码解决多次的重复计算。
🤼♀️我们来看一程序:
#include<stdio.h>
int main()
{
printf("Hello World\n");
main();
return 0;
}结果:一直打印Hello World
主函数main()中调用main()。这就是一个递归的思想,自己调用自己。只不过该程序没有终止条件,导致程序最后栈溢出,只得编译器自行终止。
3.2递归的两个必要条件
首先我们要知道递归过程为递推然后回归,那么递归过程中必须满足两个条件:
- 递归中必须存在限制条件,当达到这个限制条件时,递归将不再继续。
- 每次递归调用后会越来越接近这个限制条件。
3.2.1练习1
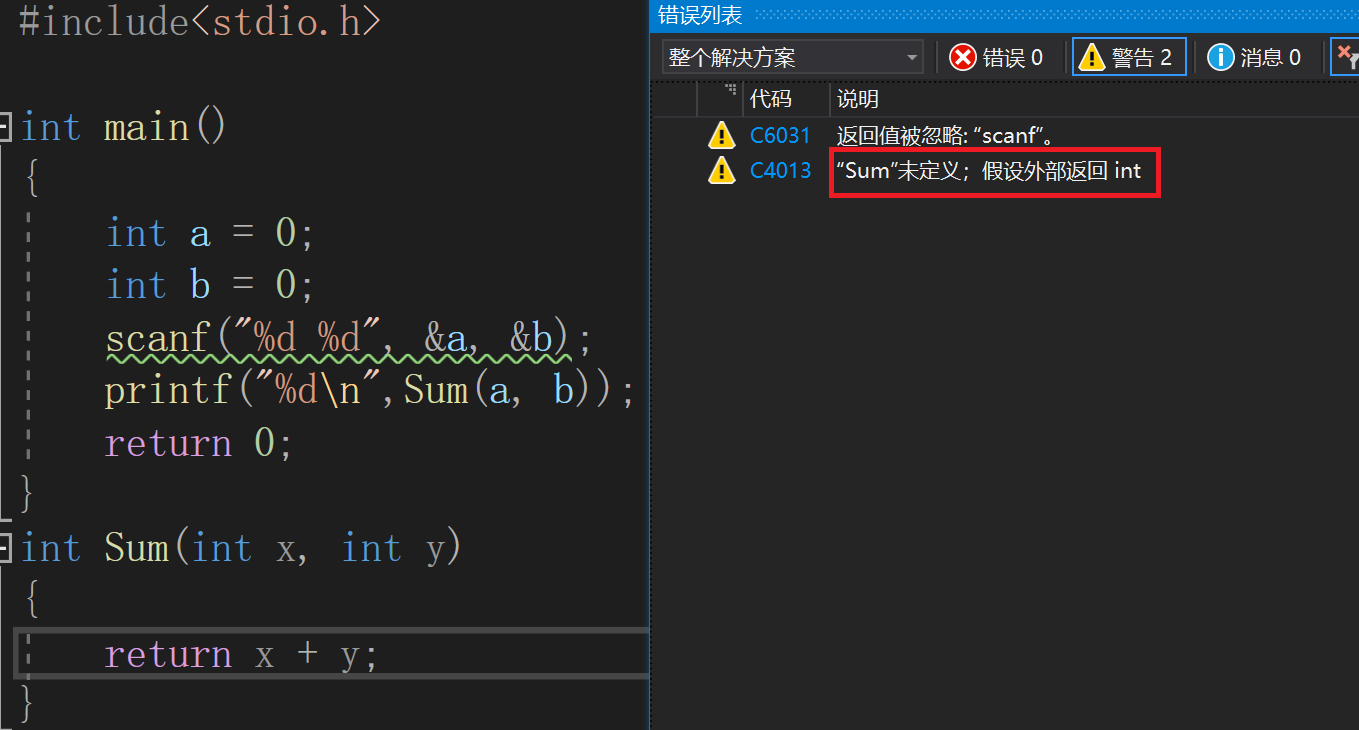
🤼接受一个无符号整形数,按照顺序打印它的每一位,例如输入:1234,输出1 2 3 4。
#include<stdio.h>
void Print(unsigned int n)
{
if (n > 9)
{
Print(n / 10);
}
printf("%d ", n % 10);
}
int main()
{
unsigned int n = 0;
scanf("%u", &n);
Print(n);
return 0;
}输入:1234
输出:1 2 3 4
上面我们说到了,递归分为两步递推和回归,所以此程序分为两步
第一步:递推,我们每次递推(调用)后的下一次递推,if语句里面的n越来越接近终止条件。第一次递推if语句中n=123,第二次递推if语句中n=12,第三次递推if语句中n=1,执行printf语句并输出1 。当n=1时终止递推,此时执行printf语句输出1 。
第二步:回归,每次回归(回调)时也是要调用Print函数的只不过每次判断的时候都为假,每次的回归n始终为1,原n还是原来的值。第一次回归判断n=1,原n=12,执行printf语句并输出2 。第二次回归判断n=1,原n=123,执行printf语句并输出3 。第三次回归判断n=1,原n=1234,执行printf语句并输出4 。我们可以这样理解,回归的每一次判断都为假,但原来n的值还在内存中存放着,所以每次输出的都是原n的值%10。
最后:屏幕上打印1 2 3 4
递推:递推前n=1234,第一次递推n=123,第二次递推n=12,第三次递推n=1,结束递推,执行printf语句,输出1 。
回归:第一次回归n=1,原n=12,if判断为假输出 2。第二次回归n=1,原n=123,if判断为假输出 3。第三次回归n=1,原n=1234,if判断为假输出4 。
最后:可能有小伙伴说那你Print函数怎么不返回主函数呢?因为Print函数的返回类型为void所以并不返回主函数,我们只是在函数里面调用函数(递归)。可以理解为每一次的调用都是形参,所以每一次调用前的n都还是原来的n,只不过最后一次返回的n是1导致返回给之前的每一次if判断都为假。如果您函数的返回与不返回或者实参与形参的概念还不太懂,可以看看我上一期的函数讲解😊
unsigned:无符号位格式符%u
3.2.2练习2
题目:编写函数不允许创建临时变量,求字符串的长度
🤼♀️我们先来看允许使用教临时变量的情况:
#include<stdio.h>
int Str(char* str)
{
int count = 0;
while (*str != '、0')
{
str++;
count++;
}
return count;
}
int main()
{
char arr[] = "abcdef";
printf("%d",Str(arr));
return 0;
}结果:6
上述程序中,主函数main定义一个名为arr的字符串类型数组, Str函数创建一个字符型指针变量str来接受这个arr数组。那么str默认指向的是arr数组的首地址也就是第一个元素的a的地址。并且arr数组里面的每个元素的地址是连续的。知道这个原理后,我们来解答Str函数内部原理。
第一次:对str解引用if判断*str!='/0',str++,count++。此时str指向arr第二个元素地址,count=1。
第二次:再次对str解引用if判断*str!='/0',str++,count++。此时str指向arr第三个元素地址,count=2。
依此类推(省略四次)
最后一次:对str解引用if判断*str='/0'结束while循环,此时count=6。返回6给实参,并输出6。

🤼不允许创建临时变量情况下 :
#include<stdio.h>
int Str(char* str)
{
if (*str != '\0')
return 1 + Str(str+1);
return 0;
}
int main()
{
char arr[] = "abc";
printf("%d\n",Str(arr));
return 0;
}输出:3
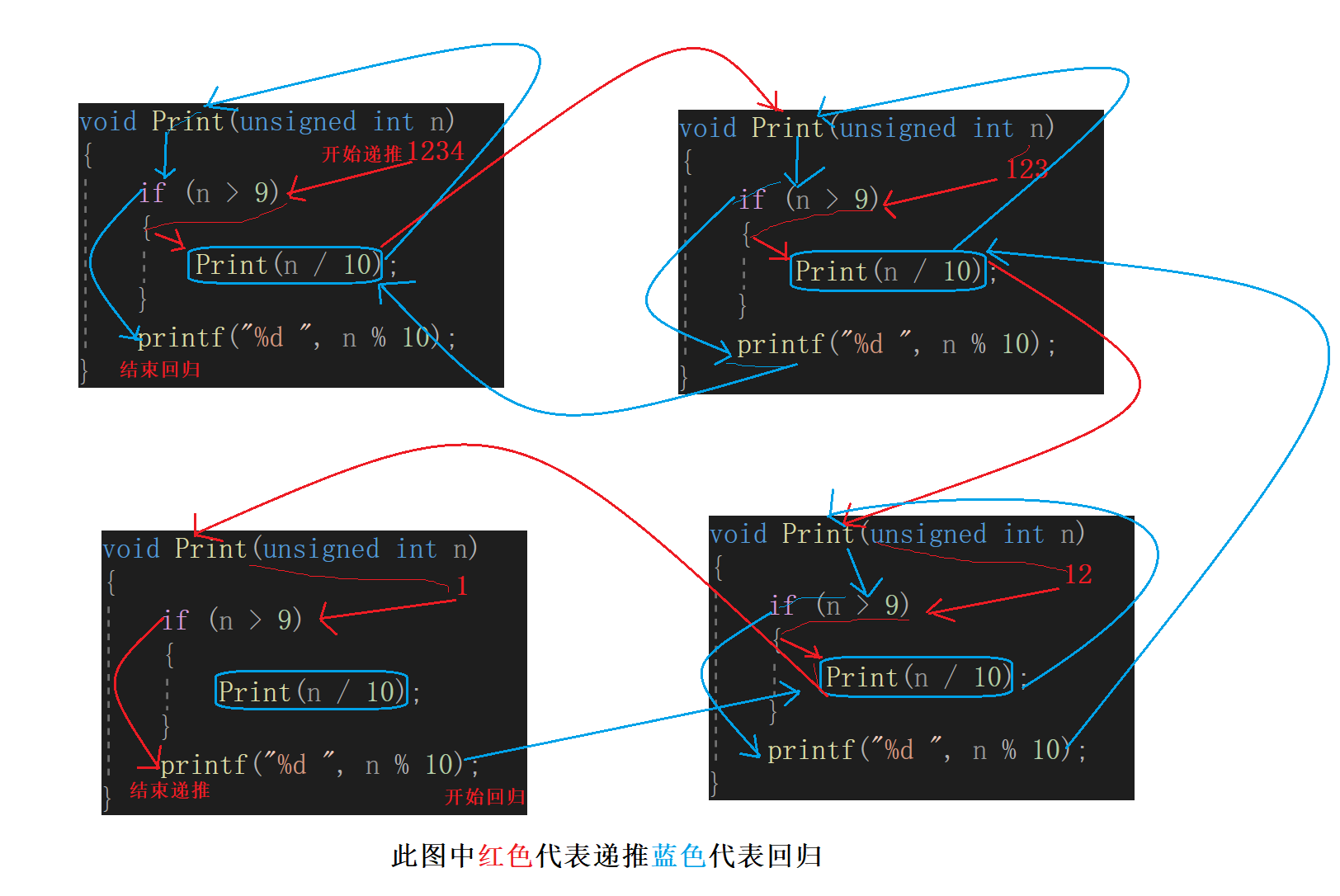
那么不采用临时变量的情况下,我们就用递归来解决这个程序。也是与上个程序一样,主函数里面定义一个arr数组。Str函数定义一个指针字符变量str来接受,也是指向该数组的第一个元素的地址。并且arr数组里面各个元素的地址是连续的,知道了这些原理后。我们来解答递归的过程。首先我们看一组图片,然后结合下方解析理解。
第一次递推:str指向的地址为b的地址,此时1+Str(str+1),传过去的参数为bc\0的地址;
第二次递推:str指向的地址为c的地址,此时1+1+Str(str+1),传过去的参数为c\0的地址;
第三次递推:str指向的地址为\0的地址,此时1+1+1+Str(str+1),传过去的参数为\0的地址,结束程序;
第一次回归为:0+1;
第二次回归为:0+1+1;
第三次回归为:0+1+1+1;
Str函数返回给主函数的值为:3,最后输出3。


相信大家通过上面两个练习懂得了递归的原理,我们来看下一节
3.3递归与迭代
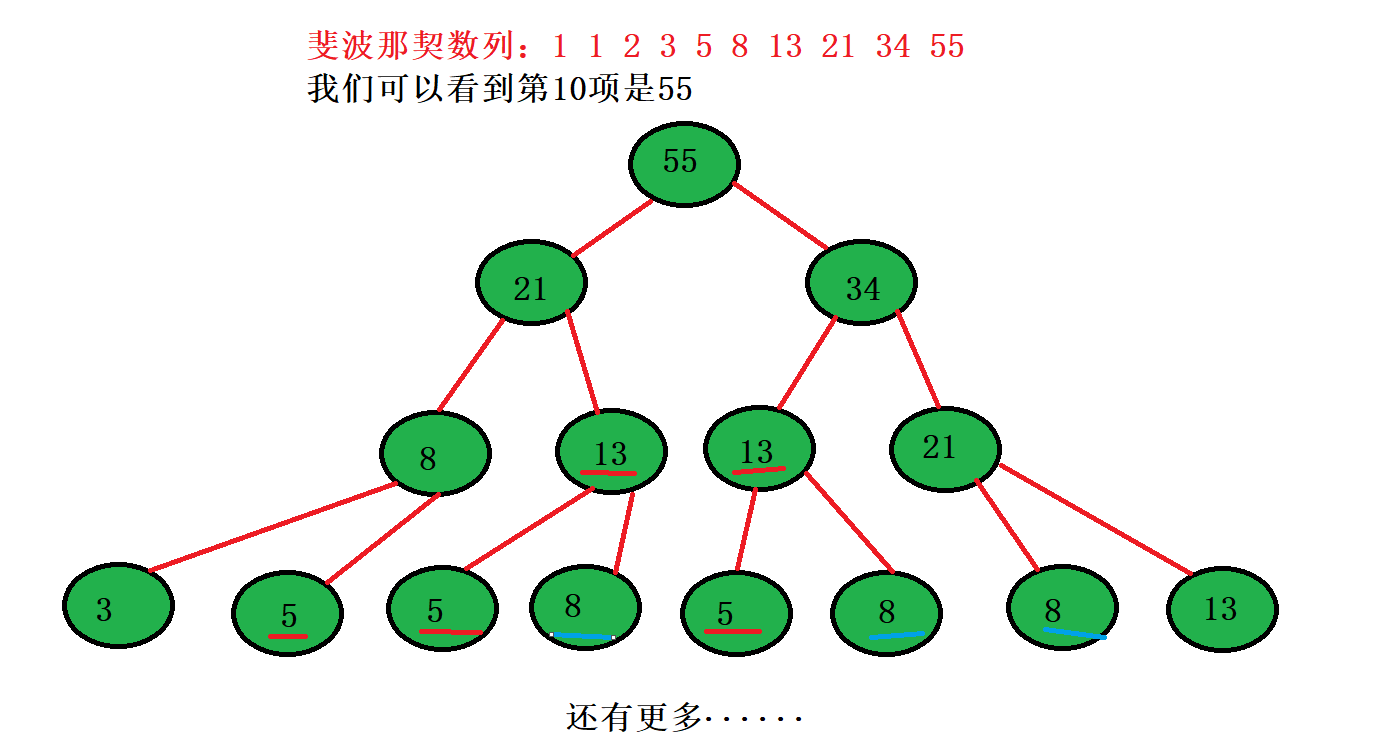
迭代就是循环,上面我们说到了,递归就是把一个大的问题化成多个小的问题来解决。但当一个问题变得特别大的时候,递归真的就非常的适合我们去使用吗?我们来看一个程序:求第n个斐波那契数(不考虑溢出)
#include<stdio.h>
int Fib(int n)
{
if (n <= 2)
return 1;
else
return Fib(n - 1) + Fib(n - 2);
}
int main()
{
int n = 0;
scanf("%d", &n);
printf("%d", Fib(n));
return 0;
}输入:10 输出:55
输入:30 输出:832040
斐波那契数列:1 1 2 3 5 8 13 21 34 55 89 ....... ,当我们输入的项数很小的时候,程序能立马运行出来,例如输入10和30。但如果输入50程序此时就不能立马运算出来,就如下图一样。第10项都需要运算这么多次,更别说第50项了。所以递归在问题过大的时候并不适合应用。
那递归不方便我们采用什么方法来算呢?我们可以采用迭代的方式来设计程序,迭代就是循环。
🤼♀️用迭代,求第n项斐波那契数(不考虑溢出)
#include<stdio.h>
int Fib(int n)
{
int a = 1;
int b = 1;
int c = 0;
while (n>2)
{
c = a + b;
a = b;
b = c;
n--;
}
return c;
}
int main()
{
int n = 0;
scanf("%d", &n);
printf("%d\n", Fib(n));
}输入:50 输出:一个随机数
因为第50项的数太大了,因此导致程序随机生成一个数,但我想表达的是同样一个问题用递归和迭代来做,效率是不同的。同一个类型程序我用递归写出的结果很慢而我用迭代来写出的结果非常快,这就是迭代与递归效率的不同。
4、程序的模块化
为了方便于开发,在我们程序的设计时,为了某一功能的实现我们程序员开发一段程序和子程序(包括函数),如果我们把这些程序全写在main函数里面,那将非常的不利于我们调试,也不方便他人使用,因此我们要模块化程序。模块化的好处是:
- 实现方便利于调试查错,提高代码的维护性
- 多人使用,提供代码的共享性
- 课对程序进行封装,提高代码的隐蔽性
🤼那么有一程序,求两数之间最大的那位数:
#include<stdio.h>
int Max(int x, int y)
{
return x > y ? x : y;
}
int main()
{
int a = 0;
int b = 0;
scanf("%d %d", &a, &b);
printf("%d\n", Max(a, b));
return 0;
}输入:5 3 输出:5
正常来讲,这是我们写出的程序 ,这是比较简单的程序几行代码就能搞定。但是当我们遇见相当复杂的程序,代码非常的长。主函数里面还要有其他的代码,这时候我们可以模块化程序。还是拿上面程序举例子,我们可以这样做:创建两个名为add.c和test.c的源文件,创建一个名为add.h的头文件。我们把Max函数的声明写在add.h里面,Max函数的定义写在add.c源文件里面,主函数main写在test.c里面。这样我就可以从test.c里面调用add.h,类似于库函数的头文件。如何操作见下图:
我们可以看到,test.c函数里面引入add.h头文件。这样我们的程序就模块化了,通过这一个小例子,我们可以了解到程序的模块化基本概念,后期博客中我会深入讲解模块化操作。

本次博客就到这里结束了,感谢大家的阅读。

















 1826
1826











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











