







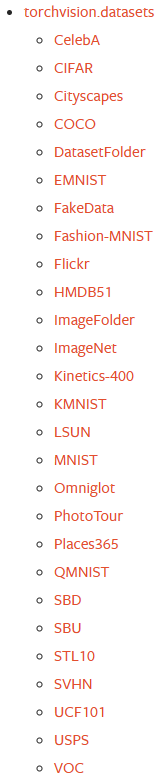
torchvison是专门用于计算机视觉的一个模块,在torchvision.datasets模块中内置了非常多现成的数据集,如下图所示:
以下操作以一个较小的数据集——CIFAR-10数据集为例
CIFAR-10:
CIFAR-10 数据集由 10 类共 60000 张 32x32的 彩色图像组成,每类 6000 张图像。有 50000 张训练图像和 10000 张测试图像。

数据集的下载与读取
数据集的读取:
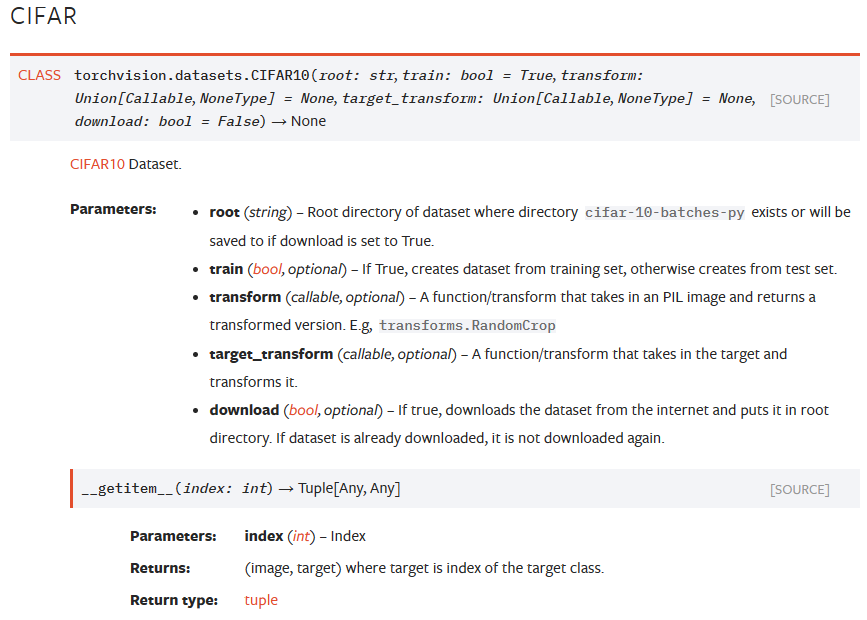 其中target为标签,指出其对应的图片的是什么
其中target为标签,指出其对应的图片的是什么
我们需要给出数据集存放位置(root),是否为训练集(train),以及对图片或标签做transform处理,以及是否自动下载数据集。使用读取数据集时会以元组的形式返回image和它的target
实例:
dataset_transform = torchvision.transforms.Compose([
torchvision.transforms.ToTensor()
])
train = torchvision.datasets.CIFAR10(root='./dataset', train=True,
transform=dataset_transform, download=False)
test = torchvision.datasets.CIFAR10(root='./dataset', train=False,
transform=dataset_transform, download=False)数据集的下载:
- 方式一:在读取的时候选择download=True,若root指定的位置无数据集,数据集会自动开始下载,但速度较慢,不推荐这种做法
- 方式二:在官网手动进行下载,并放到root指定的位置。按住ctrl键进入数据集的源码,可以找到官网的url


选择对应的版本下载即可。然后运行,python会自动解压缩。
3. 方式三:复制完url后打开迅雷下载,可以看到速度会比较快一些
关于数据集:
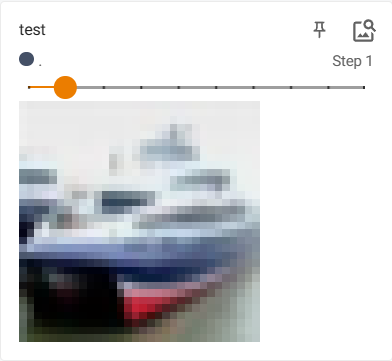
读取测试集第一个数据看看
img, target = test[0]
print(img)
print(target)
print(test.classes) # 查看target列表
print(test.classes[target])
图片格式为PIL(此处删去了读取数据集时的transform参数,但一般都要转化为tensor)还附带一个target,其中target直接使用target列表的索引直接代替了其对应的标签
使用for循环读取数据集:
writer = SummaryWriter("logs")
for i in range(10):
img, target = test[i]
writer.add_image("test", img, i)
writer.close()















 963
963











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









