







离散特征的独热编码
先按照示例代码过一遍,一次性处理data数据中所有的连续变量和离散变量
1. 读取data数据
2. 对离散变量进行one-hot编码
3. 对独热编码后的变量转化为int类型
4. 对所有缺失值进行填充
先说说离散变量,离散变量取值有限,可以是有序或无序的,通常是分类数据或字符串,在 pandas 库里数据类型默认显示为 object 类型。独热编码(One-Hot Encoding)是一种将离散变量转换为二进制向量的方法,好处就是:机器学习算法通常需要数值输入,离散变量经过编码处理能方便后续计算和模型训练;避免类别之间的数值关系误导模型,如果直接将离散变量的类别用数字编码(如0、1、2),模型可能会错误地认为这些数字之间存在大小或顺序关系,而独热编码则不会产生这种误导,每个类别都是独立且平等的,模型可以更好地学习到不同类别之间的差异
一句话总结:独热编码适合没有顺序关系的离散变量类别
(提一下:有序类别用标签编码)
# 错误的编码方式
颜色 = {'红': 1, '蓝': 2, '绿': 3}
# 这会暗示 绿 > 蓝 > 红,但实际上它们只是类别
# 正确的独热编码
红 = [1, 0, 0]
蓝 = [0, 1, 0]
绿 = [0, 0, 1]
# 这样每个颜色都是独立的,没有数值关系1.读取data数据
import pandas as pd
data = pd.read_csv(r'python60-days-challenge-master\data.csv')
# 昨天的内容都有,不重复了2.对离散变量进行one-hot编码
2.1找到离散变量
discrete_list = [] # 新建个空列表,存放是离散变量的数据列名
for discrete_col in data.columns: # 遍历每一列
if data[discrete_col].dtype == 'object': # 列的数据类型为object,即为离散变量
discrete_list.append(discrete_col)
discrete_list
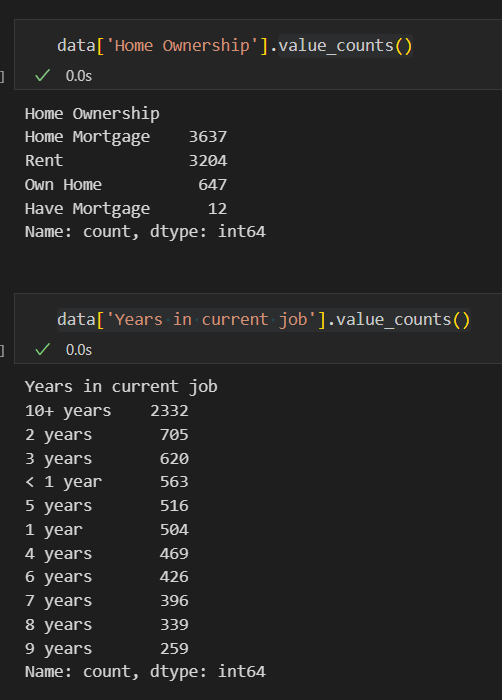
# 结果是['Home Ownership', 'Years in current job', 'Purpose', 'Term']这四个列为离散变量(提一下:昨天说将数据的列转换成列表再来遍历每一列方便修改数据,其实不用 tolist()转换成列表也行)
上面说独热编码的前提条件,这四个离散变量的类别都是没有顺序关系的吗?用 value_counts() 看看每个变量的类别,并且顺带统计一下每个类别的个数,下图以前两个变量为例:
2.2离散变量独热编码
data = pd.get_dummies(data, columns=discrete_list) # 独热编码说明:pd.get_dummies() 函数的 data 参数必须是 pandas 的数据结构(DataFrame、Series),columns 参数指定要进行独热编码的列名,可以是一个包含列名的列表
3. 对独热编码后的变量转化为int类型
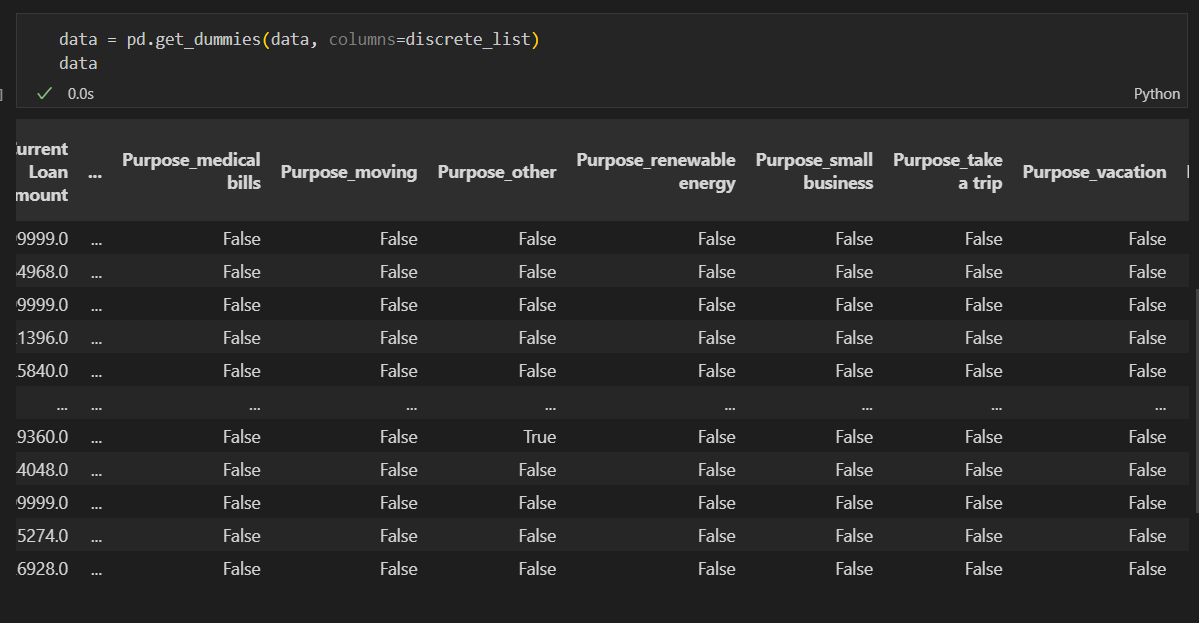
有独热编码后的部分截图可知,编码后的数据是布尔值,还需要转换成数值型,如何将独热编码后的新列全部找出来转换?很简单,和最开始的数据进行列的比对,写法很多
# 法一 循环依次填入列表
data_original = pd.read_csv(r'python60-days-challenge-master\data.csv')
add_col_list = [] # 创建一个空列,存放独热编码后多出来的列
for col in data.columns: # 独热编码后的数据进行每一列遍历
if col not in data_original.columns:
add_col_list.append(col)
add_col_list
# 法二 利用集合差集
add_col_list = list(set(data.columns) - set(data_original.columns))
# 法三 使用列表推导式
add_col_list = [col for col in data.columns if col not in data_original.columns]
# 法四 使用pandas的difference()找出列(series类型),上面方法找出来列都进入列表里了
add_col_list = data.columns.difference(data_original.columns)找出来可以进行类型转换了
for col in add_col_list:
data[col] = data[col].astype(int) # 类型转换,bool型转换为 int 型
data.head() 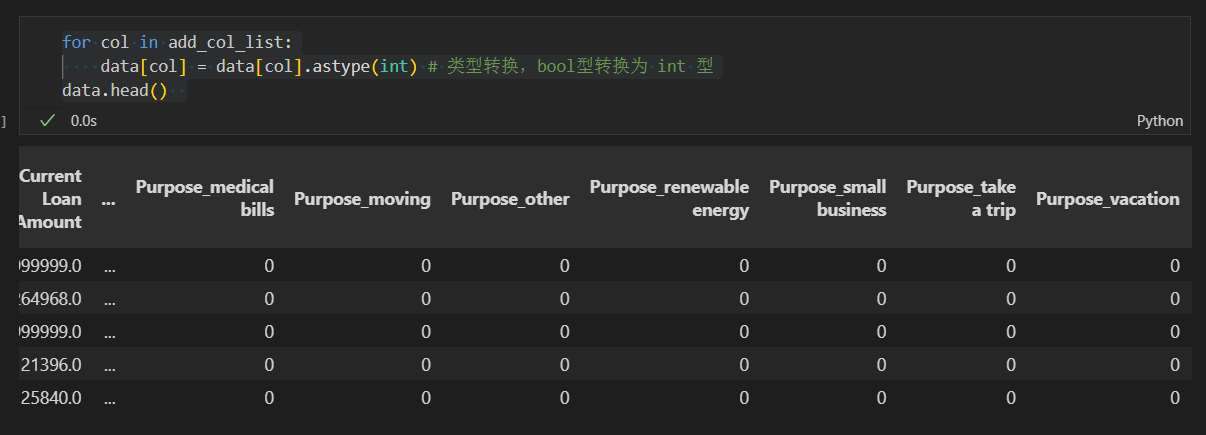
4.对所有缺失值进行填充
这个是昨天的内容,不重复了
for col in data.columns:
if data[col].isnull().sum() > 0: # 有缺失值
mean = data[col].mean() # 求平均值
data[col] = data[col].fillna(mean) # 平均值填补
data.isnull().sum() # 看看整个数据还有没有缺失值 收获心得:
代码肯定还是有优化的地方,比如判断离散变量和独热编码后类型转换都在遍历列,这个操作挺冗余的,更简洁直接的方法也有。其次,具体函数啊,函数有哪些参数啊之类的能熟悉最好,实在记不住,写代码的时候多问问大模型,搞清楚流程才是最重要的


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









