







初识pandas库与缺失数据的补全
按照示例代码的要求,去尝试补全信贷数据集中的数值型缺失值
- 打开数据(csv文件、excel文件)
- 查看数据(尺寸信息、查看列名等方法)
- 查看空值
- 众数、中位数填补空值
- 利用循环补全所有列的空值
对数据进行查看和处理前,先导入一下库,本质上就是封装了很多类啊函数啊的包,可导入全部也可导入部分,导入库就是为了用别人写好的东西。今天的内容只需要 pandas 库和 numpy 库,pandas:提供高性能、易于使用的数据结构如 DataFrame 和 Series,可方便地进行数据清洗、转换、聚合、可视化等操作,为机器学习提供高质量的数据输入。numpy:提供高效的多维数组对象 ndarray 及各类数学运算功能,能实现快速的数据处理、线性代数计算与随机数生成,是科学计算、数据分析和机器学习的基础支撑库。
DataFrame:是一个二维的带标签数据结构,类似于 Excel 表格或者 SQL 数据库中的表,由行和列组成,每一列可以是不同的数据类型,例如一列可以是整数,另一列可以是字符串,可看作是由多个Series 组成的
Series:本质上是一维带标签的数组,它可以存储任意类型的数据,通常情况下,Series 中的所有元素都属于同一种数据类型
!pip install pandas -i https://mirrors.aliyun.com/pypi/simple/ # 用阿里的源安装一下pandas库,现在是在jupyter里运行,运行一次就安装好了,之后可以删了这句
#pip install pandas -i https://mirrors.aliyun.com/pypi/simple/ # 也可以在编译器的终端安装,也可以再anaconda进入环境安装,推荐后者
import pandas as pd # 导入pandas库1.打开数据(csv文件、excel文件)
data = pd.read_csv(r'python60-days-challenge-master\data.csv') # 调用pandas库中用于读取 CSV 文件的函数
type(data) # 看一下数据类型
# 结果为pandas.core.frame.DataFrame,说明将 CSV 文件读取为 DataFrame 对象文件路径前的 r 前缀表示"原始字符串"(raw string),防止 Python 将路径里的反斜杠解释为转义字符比如 "\nature.csv" 不加 r 前缀就不行了,所以即使路径中没有特殊字符,使用 r 也是一个好习惯。我这里用的相对路径,也可以用绝对路径,无所谓的
对于 excel 文件,要安装一个openpyxl库,别的都大差不差
2.查看数据(尺寸信息、查看列名等方法)
data.head(10) # 查看前十行数据,不改参数默认前五行
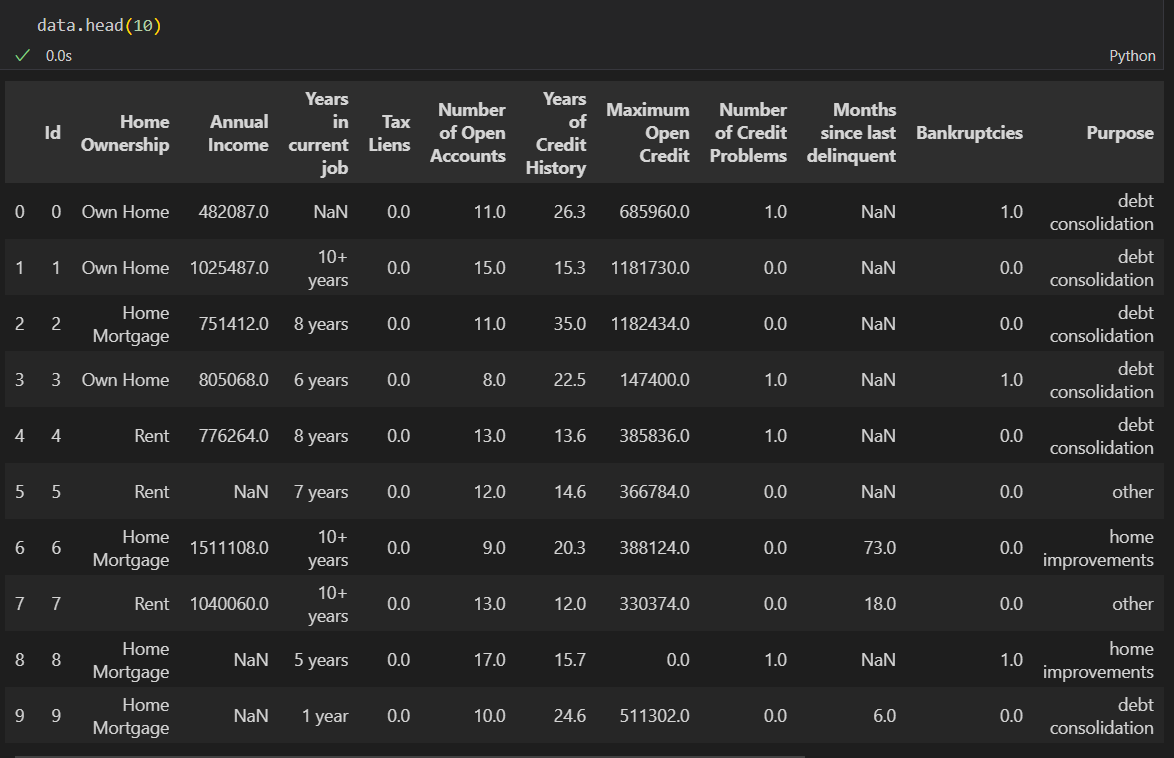
data.info() # 查看数据基本信息,行数、列数、列名、每列非空值和数据类型
只想看行数列数,用 data.shape,只想看列名,用 data.columns,只想看每列数据类型,用 data.dtypes,这都是data的属性,上面俩都是data的方法。面向对象的编程中,类包含方法和属性,方法是类中定义的函数,通常描述为"执行某个操作";属性是类中定义的变量,通常描述为"返回某个值",注意区分
只想看指定列的数据类型,用 data["Id"].dtype
辨析一下 data["Id"].dtype 和 type(data["Id"]):
- type() 回答:"这是什么对象?",用于检查对象类型(即数据结构的类型,例 pandas 里面的两类 DataFrame 和 Series)
- dtype 回答:"这个对象里装的是什么类型的数据?",用于检查数据类型(即数据具体内容的类型,例整数、浮点、字符串、布尔值等)其实从名字上也好分辨,dtype = data type
3.查看空值
data.isnull() # 布尔矩阵显示缺失值,这个方法返回一个布尔矩阵,其中True表示对应位置的值是缺失值,False表示对应位置的值不是缺失值
所以调用了data.isnull() 函数后返回的是一个布尔值的矩阵,查看数据结构类型也应该是 DataFrame
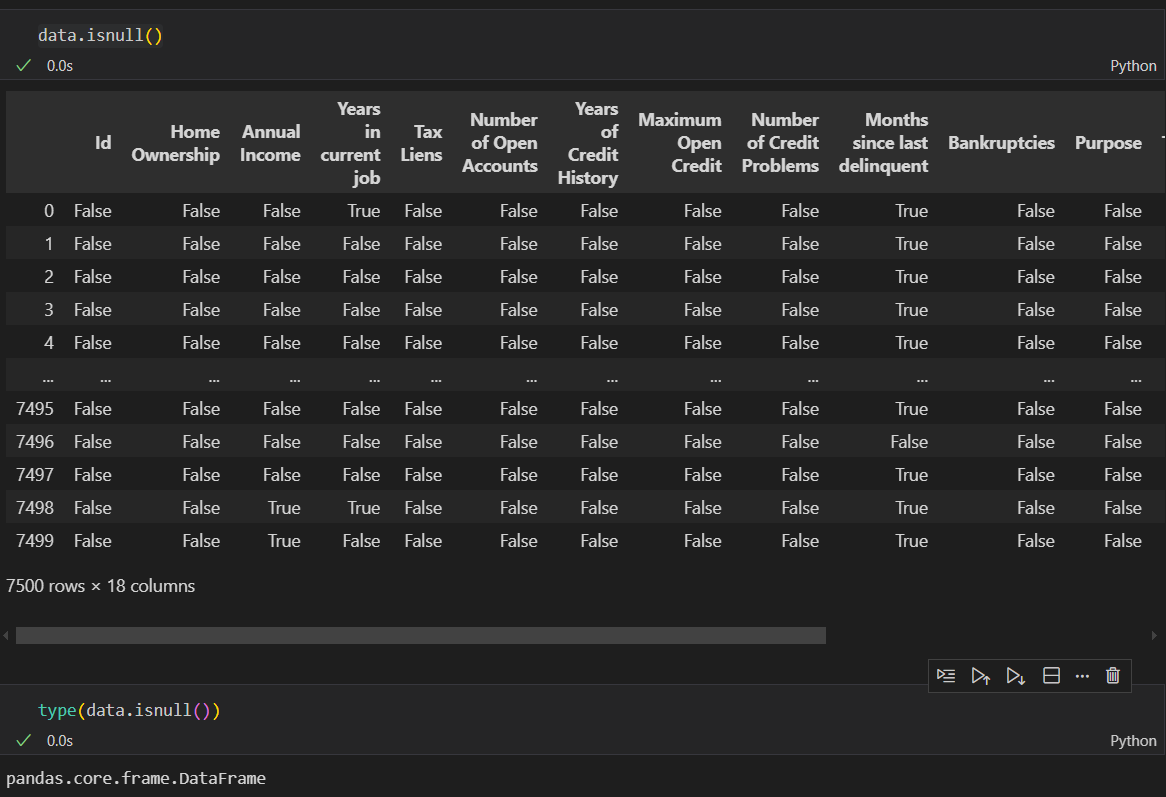
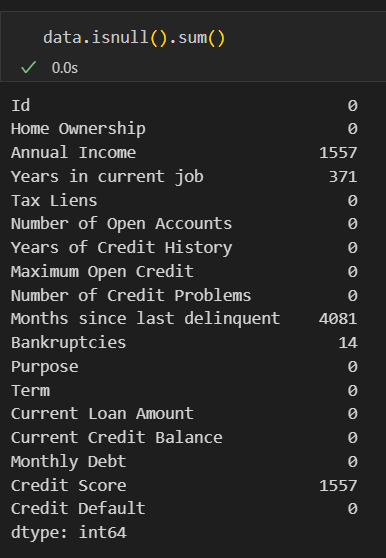
布尔矩阵虽然显示了如何找到每一列哪个位置有缺失值,但位置太多了也不便于我们统计具体每列有几个数据缺失,可以考虑每列求和 (True = 1 = 缺失,False = 0 =非空)
data.isnull().sum() # 每列缺失值计数,sum方法为求每一列的和,data.isnull() 也是对象,也有 sum() 这个方法,所以可以这样写
4.众数、中位数填补空值
众数填补
mode = data['Annual Income'].mode() # 求众数
print(mode) # 这一步执行完了这一列有5个众数,选一个填不然报错
data['Annual Income'] = data['Annual Income'].fillna(mode[1]) # 用众数填充,调用 fillna() 函数
#data['Annual Income'].fillna(mode, inplace=True) # inplace=True时返回None表示直接在原DataFrame上进行修改
# 系统给了警告,还是创建一个新的DataFrame安全
data['Annual Income'].isnull().sum() # 再看看填完了还有没有缺失值中位数填充
data = pd.read_csv(r'python60-days-challenge-master\data.csv') # 刚才执行完数据变了,重新读一下数据
median = data['Annual Income'].median() # 求中位数
print(median)
data['Annual Income'] = data['Annual Income'].fillna(median) # 用中位数填充,调用 fillna() 函数
data['Annual Income'].isnull().sum()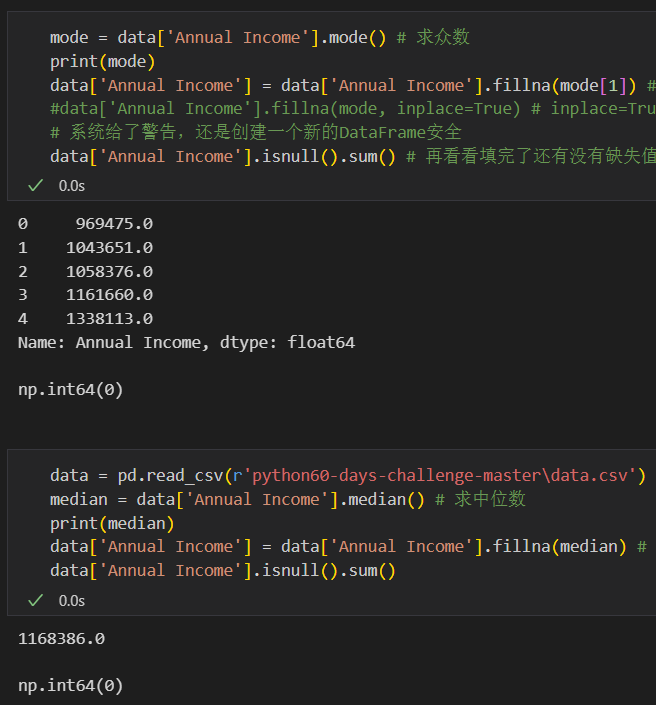
5.利用循环补全所有列的空值
根据刚才查看空值,需要找到所有有缺失值的列,并且列的数据类型为数值的,并且遍历这些列依次填补缺失值。很显然这些列的数据结构不是列表,如果需要修改或进行复杂操作,转换为列表更方便,numpy库的 tolist() 可以实现将numpy数组和pandas对象转换成list
import numpy as np
columns_list = data.columns.tolist() # 将数据的列转换成列表
for i in columns_list: # 遍历每一列
if data[i].dtype in ['int64', 'float64']: # 该列数据类型为数值型时
if data[i].isnull().sum() > 0: # 有缺失值
median = data[i].median()
data[i] = data[i].fillna(median)
data[i].isnull().sum()收获心得:
学的东西挺多的,都有在上面提到,就不赘述了

















 1669
1669

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









