






一,MySQL服务器的安装与配置
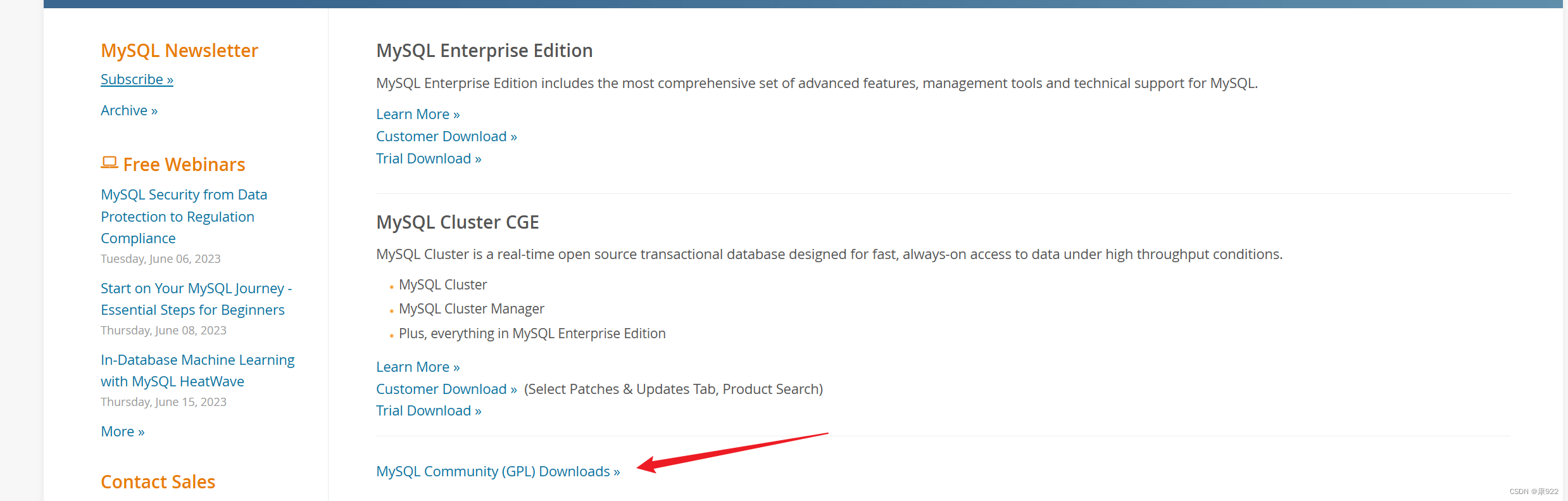
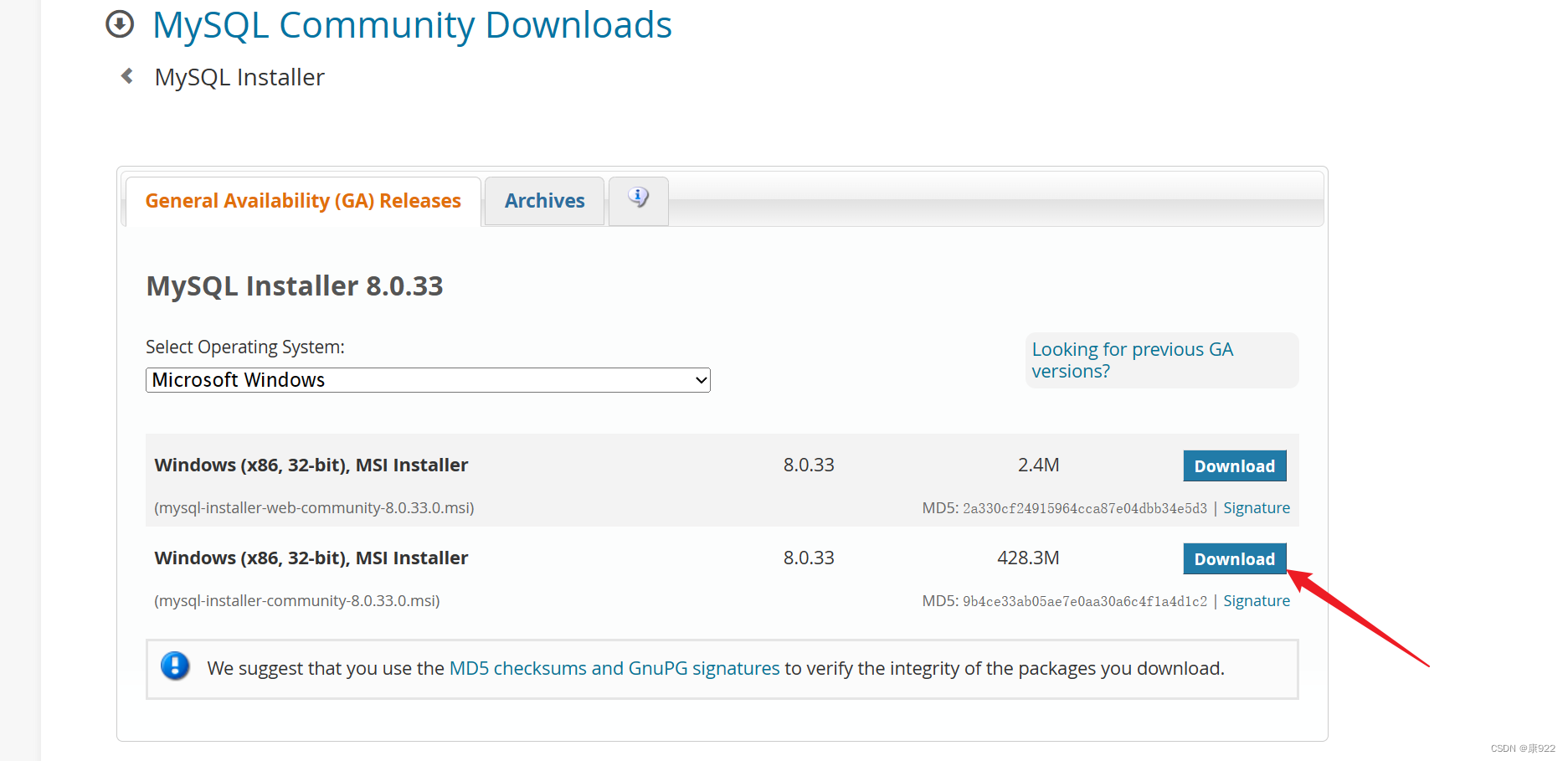
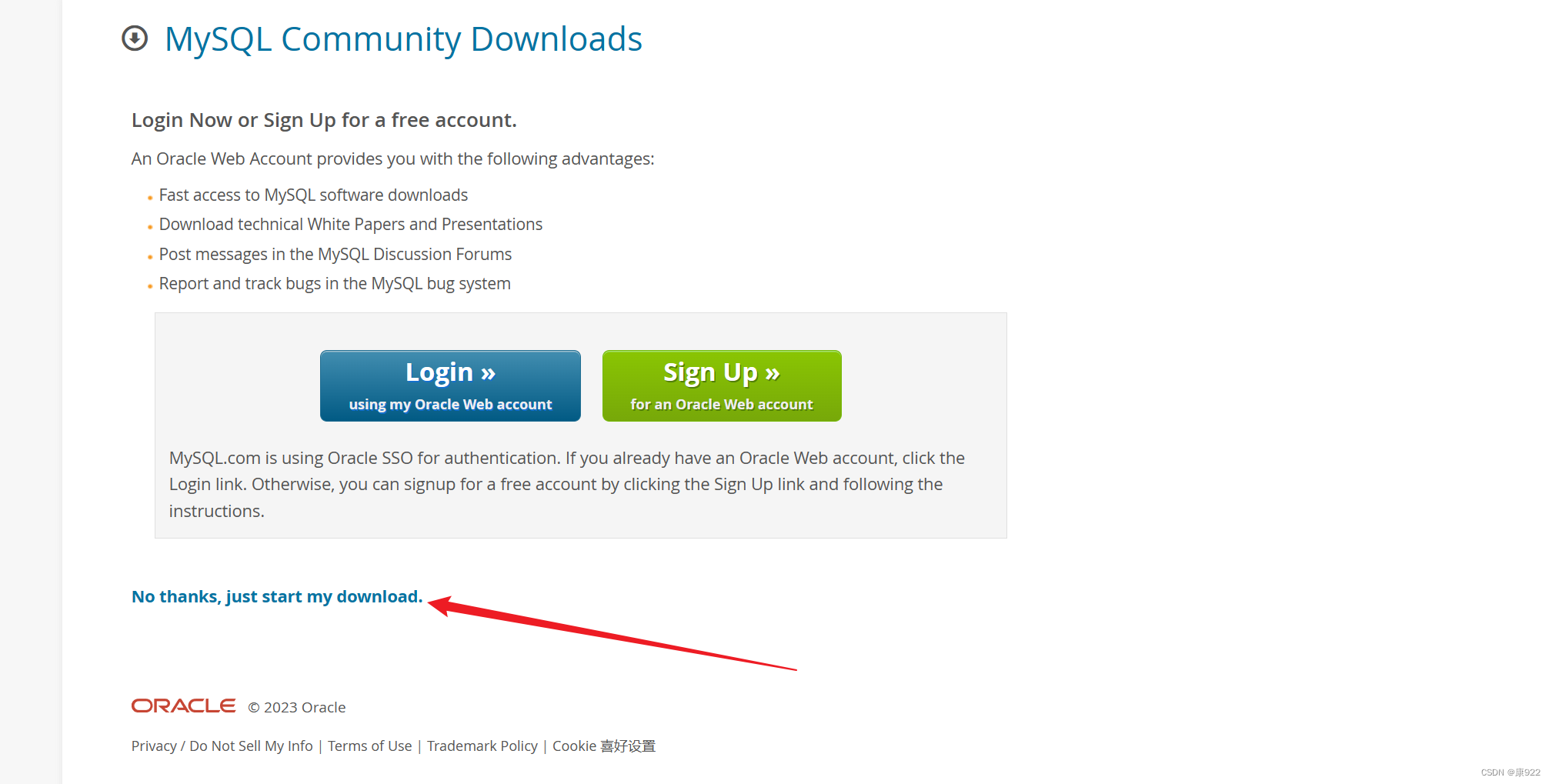
1.到官网www.mysql.com下载并安装MySQL
下载教程如下:

2.环境变量配置
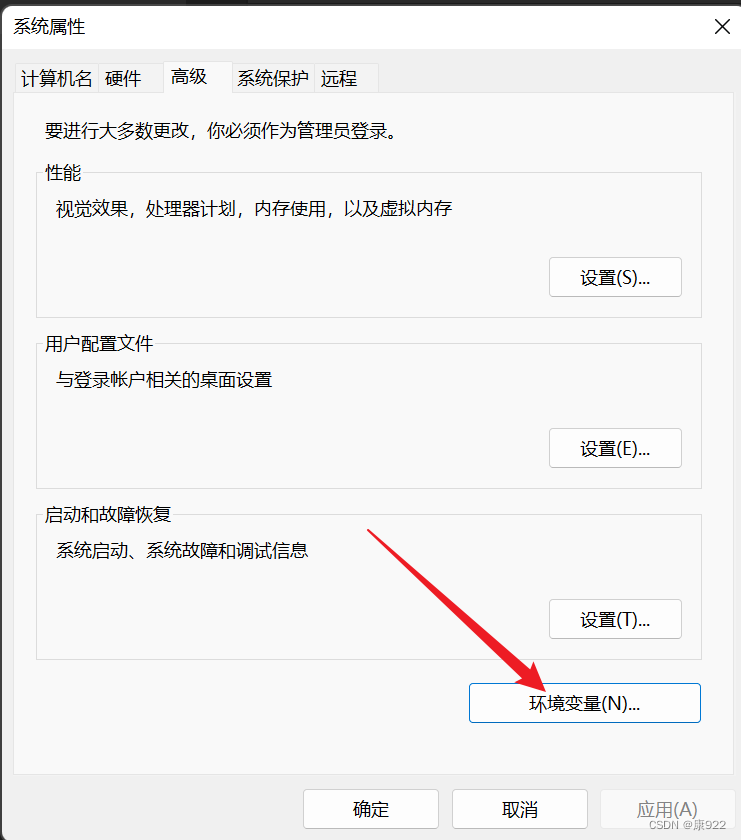
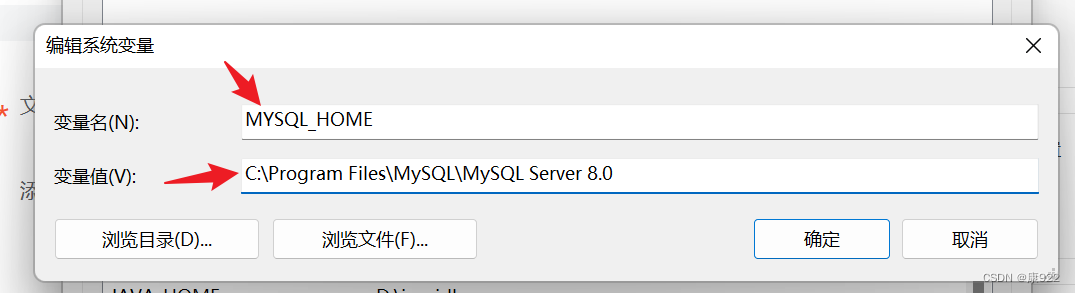
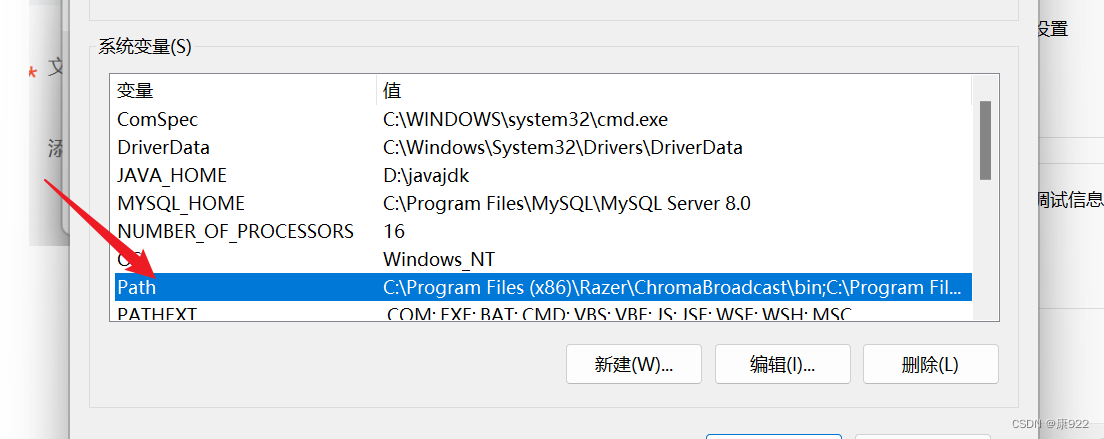
点击编辑并新建
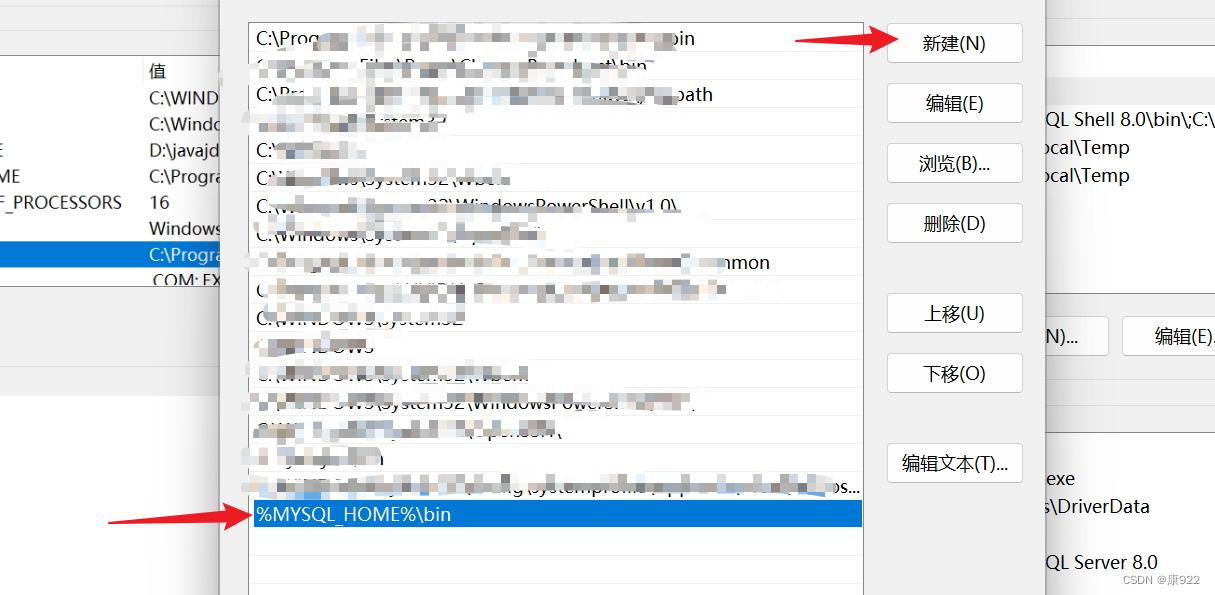
最后到控制面板输入mysql验证结果
二,数据库设计
1.创建与管理数据库
使用CREATE DATABASE语句创建数据库,指定数据库的名称
CREATE DATABASE 数据库名如果需要指定字符集和排序规则,可以在CREATE DATABASE语句后面添加相应的选项
CREATE DATABASE 数据库名
CHARACTER SET 字符集
COLLATE 排序规则;2.创建数据表
首先使用到当前数据库
use 数据库名使用CREATE TABLE语句创建数据表,指定表名和各个列的名称、数据类型和约束条件。例如,要创建一个名为users的数据表,包含id, name, age和email四个列,可以使用以下命令:
CREATE TABLE users (
--列名 数据类型 是否为空...
id INT(11) NOT NULL AUTO_INCREMENT, --自增
name VARCHAR(50) NOT NULL,
age INT(3) DEFAULT '0',
email VARCHAR(100) NOT NULL,
PRIMARY KEY (id), --主键
UNIQUE KEY (email) --唯一列
);以上命令将创建一个名为users的数据表,包含id, name, age和email四个列。其中id列是主键,并且自动递增;name和email列是必填项,不允许为空;age列有默认值0;email列是唯一键,用于确保每个用户的电子邮件地址唯一。
3.修改数据表
3.1 添加新列
要添加新列,可以使用ADD COLUMN子句,例如:
ALTER TABLE users ADD COLUMN address VARCHAR(200) AFTER name;以上命令将在users表中添加一个名为address的VARCHAR类型的列,并将其放置在name列之后。
3.2 修改列定义
要修改列定义,可以使用MODIFY COLUMN子句,例如:
ALTER TABLE users MODIFY COLUMN age TINYINT UNSIGNED NOT NULL DEFAULT '0';以上命令将将age列的数据类型从INT改为TINYINT UNSIGNED类型,并设置为必填项,同时将其默认值改为0。
3.3 删除列
要删除列,可以使用DROP COLUMN子句,例如:
ALTER TABLE users DROP COLUMN email;以上命令将从users表中删除名为email的列。
在执行ALTER TABLE语句时,需要注意数据表中已有的数据可能会受到影响,因此建议先备份数据表再进行修改。
4.删除表
4.1删除单个表
要删除单个表,可以使用以下语句:
DROP TABLE users;以上命令将删除名为users的数据表。
4.2删除多个表
要删除多个表,可以使用以下语句:
DROP TABLE users, orders, payments;以上命令将删除名为users、orders和payments的三个数据表。
在执行DROP TABLE语句时,需要注意已有的数据表和其中的数据将被永久删除,因此建议在执行前先备份数据。如果想要删除表中的数据而保留表结构,请使用DELETE语句 。
5.数据完整性
在关系型数据库中,为了保证数据的正确性和完整性,常常需要定义一些约束条件来控制表中数据的输入和修改。常用的数据完整性约束包括以下几类:
5.1主键约束(PRIMARY KEY)
主键约束是指表中某个或某些列的值唯一标识该行数据,并且不能为空。使用主键可以确保表中每一行数据都有唯一的标识,方便对数据进行增删改查等操作。
5.2唯一约束(UNIQUE)
唯一约束是指表中某个或某些列的值必须唯一,但可以为空。与主键不同的是,唯一约束可以包含多列,且表中可以存在多个唯一约束。
5.3非空约束(NOT NULL)
非空约束是指表中某个列必须有值,不允许为空。通过对某些关键列设置非空约束,可以避免输入或修改时漏填关键信息。
5.4外键约束(FOREIGN KEY)
外键约束是指表中某个列的值必须满足另一个表中某一列的值,以实现表与表之间的关联。通过外键约束可以确保数据的一致性、完整性和可靠性。
以上约束可以通过CREATE TABLE语句中的约束子句来定义,也可以在已经创建的表上使用ALTER TABLE语句来修改。在MySQL数据库中,使用约束可以避免数据错误或不一致的情况发生,提高数据的完整性和可靠性。
6.数据修改
在关系型数据库中,对于已经存在的数据,可以使用UPDATE语句对其进行修改。UPDATE语句的基本语法如下:
UPDATE table_name SET column1=value1, column2=value2 WHERE condition;其中,table_name为要更新的表名,column1和column2为要更新的列名,value1和value2为要更新的值,WHERE子句是可选的,用于指定筛选条件。如果没有指定WHERE子句,则会将所有行的指定列都更新为指定的值。以下是几个UPDATE语句的示例:
6.1修改单个数据行
要修改表中某一行的数据,可以使用以下语句:
UPDATE users SET age=30 WHERE id=1;以上命令将会把id为1的用户的年龄修改为30岁。
6.2批量修改数据行
要批量修改数据行,可以使用以下语句:
UPDATE users SET age=age+1 WHERE gender='male';以上命令将会把表中所有gender为'male'的用户的年龄都加1岁。
6.3同时修改多个列的值
要同时修改多个列的值,可以使用以下语句:
UPDATE users SET age=25, gender='female' WHERE name='Lucy';以上命令将会把name为'Lucy'的用户的年龄修改为25岁,并将性别修改为'female'。
在执行UPDATE语句时,需要注意已有的数据将被永久性修改,因此建议在执行前先备份数据,并谨慎选择更新范围和更新内容。
7.数据删除
在关系型数据库中,可以使用DELETE语句删除表中的数据行。DELETE语句的基本语法如下:
DELETE FROM table_name WHERE condition;其中,table_name为要删除数据行的表名,WHERE子句是可选的,用于指定筛选条件。如果没有指定WHERE子句,则会将所有行都删除。以下是几个DELETE语句的示例:
7.1删除单个数据行
要删除表中某一行的数据,可以使用以下语句:
DELETE FROM users WHERE id=1;以上命令将会把id为1的用户数据行从表中删除。
7.2批量删除数据行
要批量删除数据行,可以使用以下语句:
DELETE FROM users WHERE gender='male';以上命令将会删除表中所有gender为'male'的用户数据行。
在执行DELETE语句时,需要注意已有的数据将被永久删除,因此建议在执行前先备份数据,并谨慎选择删除范围和删除内容。特别地,应当避免误删所有数据或误删关键数据,以防止对业务的影响。同时,也可以使用事务(Transaction)来保证删除操作的原子性和可靠性。
三,数据查询
1.单表查询
在关系型数据库中,使用SELECT语句可以对表中的数据进行查询,从而获取所需的信息。下面介绍几种常用的SELECT语句:
1.1查询所有数据行
要查询表中所有的数据行,可以使用以下语句:
SELECT * FROM table_name;*表示查询所有列,table_name为要查询的表名。
1.2查询指定列的数据
要查询表中指定列的数据,可以使用以下语句:
SELECT column1, column2 FROM table_name;column1和column2为要查询的列名,多个列名之间以逗号分隔。
1.3带条件查询
要根据指定的条件筛选数据行,可以使用以下语句:
SELECT * FROM table_name WHERE condition;condition为筛选条件,可以使用比较运算符(=、<、>等)和逻辑运算符(AND、OR等)连接多个条件。
1.4排序查询结果
要按照指定的排序规则返回查询结果,可以使用以下语句:
SELECT * FROM table_name ORDER BY column1 ASC/DESC;ORDER BY子句用于指定排序依据的列名,并通过ASC(升序)或DESC(降序)来控制排序方式。
1.5分组查询
要对查询结果进行分组汇总,可以使用以下语句:
SELECT column1, COUNT(*) FROM table_name GROUP BY column1;GROUP BY子句用于指定分组依据的列名,COUNT(*)表示对每个分组进行计数。
以上是单表查询中的一些基本语句,可以通过它们来获取所需的信息,并支持复杂的筛选、排序和计算等操作
where子句
WHERE子句用于从表中筛选符合指定条件的数据行,并将其返回给用户。WHERE子句可以根据各种逻辑和比较运算符进行筛选,以下是一些常见的WHERE子句语法:
1.筛选等于某个值的数据行
要筛选某个列的值等于指定值的数据行,可以使用以下语句:
SELECT * FROM table_name WHERE column_name = value;table_name为表名,column_name为列名,value为指定值。
筛选包含某个字符串的数据行
要筛选某个列包含指定字符串的数据行,可以使用以下语句:
SELECT * FROM table_name WHERE column_name LIKE '%string%';LIKE操作符用于模糊匹配,%表示任意字符,所以'%string%'表示包含string字符串的任意位置。
2.筛选不等于某个值的数据行
要筛选某个列的值不等于指定值的数据行,可以使用以下语句:
SELECT * FROM table_name WHERE column_name <> value;<>表示不等于。
3.筛选大于某个值的数据行
要筛选某个列的值大于指定值的数据行,可以使用以下语句:
SELECT * FROM table_name WHERE column_name > value;>表示大于。
4.筛选小于某个值的数据行
要筛选某个列的值小于指定值的数据行,可以使用以下语句:
SELECT * FROM table_name WHERE column_name < value;<表示小于。
5.筛选在某个值范围内的数据行
要筛选某个列的值在指定范围之内的数据行,可以使用以下语句:
SELECT * FROM table_name WHERE column_name BETWEEN value1 AND value2;BETWEEN关键字用于指定范围,value1和value2为范围的起始值和终止值。
以上是WHERE子句中的一些常见语法,它们可以灵活地组合使用,以产生更复杂和精确的查询结果。需要注意的是,在使用WHERE子句时,应当根据实际情况选择合适的比较运算符和逻辑运算符,并考虑索引的利用和查询效率的问题。
2.多表查询
在关系型数据库中,多表查询常用于在多个相关的表中查询数据,并根据关联信息将这些数据进行关联、聚合等操作。以下是一些常见的多表查询语法:
2.1内连接查询
内连接(INNER JOIN)是最常用的多表查询方式,它将两个表中符合条件的记录进行匹配,并返回匹配结果。内连接查询通常需要指定连接条件,例如:
SELECT * FROM table1 INNER JOIN table2 ON table1.column_name = table2.column_name;table1和table2为要连接的两个表名,ON子句用于指定连接条件,即连接所依据的列名。
2.2左连接查询
左连接(LEFT JOIN)将左表中的所有记录和右表中符合条件的记录进行匹配,并返回匹配结果。如果右表中不存在符合条件的记录,则返回NULL。左连接查询通常使用以下语句:
SELECT * FROM table1 LEFT JOIN table2 ON table1.column_name = table2.column_name;table1和table2为要连接的两个表名,ON子句用于指定连接条件,即连接所依据的列名。
2.3右连接查询
右连接(RIGHT JOIN)与左连接相反,将右表中的所有记录和左表中符合条件的记录进行匹配,并返回匹配结果。如果左表中不存在符合条件的记录,则返回NULL。右连接查询通常使用以下语句:
SELECT * FROM table1 RIGHT JOIN table2 ON table1.column_name = table2.column_name;table1和table2为要连接的两个表名,ON子句用于指定连接条件,即连接所依据的列名。
2.4全连接查询
全连接(FULL OUTER JOIN)将左表和右表中的所有记录进行匹配,并返回匹配结果。如果左表或右表中不存在符合条件的记录,则返回NULL。全连接查询通常使用以下语句:
SELECT * FROM table1 FULL OUTER JOIN table2 ON table1.column_name = table2.column_name;table1和table2为要连接的两个表名,ON子句用于指定连接条件,即连接所依据的列名。
以上是多表查询中的一些基本语法,可以通过这些语句来完成复杂的数据关联和聚合操作。需要注意的是,在使用多表查询时需要考虑到表间关系、连接条件和查询效率等因素。
3.子查询
3.1标量子查询
标量子查询是指返回单一值的子查询,在外层SQL语句中可以使用这个单一值进行比较、计算等操作。例如
SELECT * FROM table_name WHERE column_name = (SELECT column_name2 FROM table_name2 WHERE condition);内层SQL语句返回单一值column_name2,外层SQL语句将这个单一值与外层表的column_name列进行比较。
3.2列子查询
列子查询是指返回一列值的子查询,在外层SQL语句中可以使用这一列值来进行比较、聚合等操作。例如:
SELECT column_name FROM table_name WHERE column_name IN (SELECT column_name2 FROM table_name2 WHERE condition);内层SQL语句返回列column_name2,外层SQL语句将这一列值与外层表的column_name列进行比较。
3.3表子查询
表子查询是指返回一张表的子查询,在外层SQL语句中可以对这张表进行查询、聚合等操作。例如:
SELECT * FROM (SELECT * FROM table_name WHERE condition) t WHERE t.column_name = value;内层SQL语句返回一张表,外层SQL语句使用别名t来表示这张表,并对其进行进一步的查询和筛选。
以上是子查询中的一些常见语法,可以灵活地组合使用,以满足不同的查询需求。需要注意的是,在使用子查询时应当考虑到查询效率和优化, 尽量避免过深的嵌套层数和复杂的查询条件。
四,数据视图
数据视图是一种虚拟表格,其内容是从一个或多个基础表中抽象出来的。它可以被理解为主要用于存储查询中需要的数据,以便在不影响基础表的情况下将它们组合成更复杂和有用的结构。数据视图可以简化用户对数据库的访问,隐藏了基础表的复杂性,并提供了对数据子集的高效访问。
在关系型数据库中,有以下两种类型的数据视图:
1.查询视图
查询视图是基于一个或多个基础表上的 SELECT 语句创建的。与基础表不同,查询视图不包含实际存储的数据,而是根据 SELECT 语句检索基础表的数据,并根据查询结果定义视图的内容。
例如,我们可以创建一个查询视图,该视图只显示数据表中某些列的内容:
CREATE VIEW view_name AS SELECT column1, column2, column3 FROM table_name WHERE condition;这个视图将只显示 column1、column2 和 column3 列,且仅包含满足条件的数据。
2.更新视图
更新视图是允许用户通过视图插入、更新或删除数据行的视图。与查询视图不同,它们可以更改基础表中数据的状态。
例如,我们可以创建一个更新视图,使用户可以通过该视图向基础表中添加新行:
CREATE VIEW view_name AS SELECT column1, column2, column3 FROM table_name WHERE 1 = 0 WITH CHECK OPTION;注意,这个视图使用了 WITH CHECK OPTION 选项,以限制用户只能插入满足 WHERE 子句条件的行。如果尝试插入不属于这个条件的行,则操作将失败。
总的来说,数据视图可以大大简化对数据库的访问和管理。数据视图可以被视为虚拟表格,它消除了对底层基础表的直接访问,提供了数据的抽象化,使操作更加方便、高效且安全。
五,数据库编程
1.存储过程与存储函数
存储过程和存储函数是关系型数据库中的两种常见对象,它们都是一组被命名的SQL语句集合,可以作为程序单元在数据库服务器端进行处理。但是存储过程和存储函数有些不同之处:
1.1存储过程是一组预定义的SQL语句集合,可以完成一系列操作,并且可以调用其他存储过程,存储过程不能返回值给客户端。
1.2存储函数是一组预定义的SQL语句集合与存储过程类似,但是它会返回一个结果集合给客户端。
1.3存储过程和存储函数都可以传递参数,包括输入参数和输出参数。输入参数是由客户端向存储过程或存储函数传递的值,输出参数是由存储过程或存储函数返回给客户端的值。
1.4存储过程和存储函数都可以被预编译和缓存,从而提高执行效率。
1.5通常情况下,存储过程用于实现复杂的业务逻辑和数据处理,而存储函数则用于简单的计算和数据转换等。
下面是创建存储过程和存储函数的例子:
创建存储过程:
CREATE PROCEDURE procedure_name(parameter1_data_type parameter1_value, parameter2_data_type parameter2_value,...)
BEGIN
SQL statements;
END;创建存储函数:
CREATE FUNCTION function_name(parameter1_data_type, parameter2_data_type,...)
RETURNS return_data_type
BEGIN
DECLARE variable_name data_type;
SQL statements;
RETURN return_value;
END;总的来说,存储过程和存储函数是关系型数据库中非常有用和常用的技术。它们可以帮助开发者快速完成复杂的业务逻辑和数据处理,提高数据库系统的效率和可维护性。
六,数据库安全
1.用户管理:通过创建和管理用户账号来限制数据库的访问权限,例如分配用户名和密码、授权和收回用户的访问权限等方式,来确保只有授权的用户才能访问数据库。
2.角色管理:角色是一组权限的集合,可以将一组用户分配到一个角色中,并给予该角色一定的权限。通过角色管理,可以简化用户权限管理的复杂性,提高管理的效率和安全性。
3.数据访问权限控制:通过访问控制列表(ACL)或基于角色的访问控制(RBAC)等方式,对数据进行访问控制,以确保只有授权的用户或角色才能读取或修改数据。
4.数据加密:对于敏感数据,采用加密方式对其进行保护,例如使用对称加密算法、非对称加密算法或者哈希算法等,来确保未经授权的人员无法读取数据。
5.数据备份和还原:定期备份数据库,并使用恢复功能来保证数据的可靠性。此外,也可以设置权限级别和限制数据备份的用户,以确保数据备份的安全性。
创建用户账号:
CREATE USER 'username'@'localhost' IDENTIFIED BY 'password';授权用户访问数据库:
GRANT ALL PRIVILEGES ON dbname.* TO 'username'@'localhost';创建角色:
CREATE ROLE 'rolename';给角色授予权限:
GRANT SELECT, INSERT, UPDATE ON dbname.tablename TO 'rolename';将用户添加到角色中:
GRANT 'rolename' TO 'username'@'localhost';基于ACL的数据访问控制:
SET GLOBAL table_privileges= "user1@localhost:SELECT,UPDATE\n user2@localhost:INSERT,DELETE";数据加密:
CREATE TABLE users ( id INT PRIMARY KEY, username VARCHAR(50), password VARBINARY(255) ); INSERT INTO users (id, username, password) VALUES (1, 'user1', AES_ENCRYPT('password123', 'secret')), (2, 'user2', AES_ENCRYPT('abcde789', 'secret')); SELECT id, username, CAST(AES_DECRYPT(password, 'secret') AS CHAR(50)) AS decrypted_password FROM users;那么,数据库的基础知识学习和归纳就到此为止了!学习愉快















 510
510











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









