





《基于Transformer调制融合的语声情感识别》
论文地址:https://doi.org/10.48550/arXiv.2010.02057
摘要:
本文旨在为情感识别和情感分析提供一种轻量级而强大的解决方案。我们的动机是提出两种基于Transformers和调制的架构,结合来自广泛数据集的语言和声音输入以挑战,有时甚至超越该领域的最先进技术。
为了证明我们的模型的效率,我们仔细评估了它们在IEMOCAP、MOSI、MOSEI和MELD数据集上的性能。实验可以直接复制,代码对未来的研究完全开放。
1 引言
理解表达的情感和情绪是人类多模态语言的两个关键因素,但从多媒体中预测情感状态仍然是一项具有挑战性的任务。情感识别任务已经存在于不同类型的信号上,典型的是音频、视频和文本。
深度学习技术允许开发新的范式,在一个模型中使用这些不同的信号,以利用从不同来源的联合信息提取。这些模型通常需要模态之间的融合,分类器使用这些特征输出可能答案的概率,这是计算表达多模态特征的关键步骤。
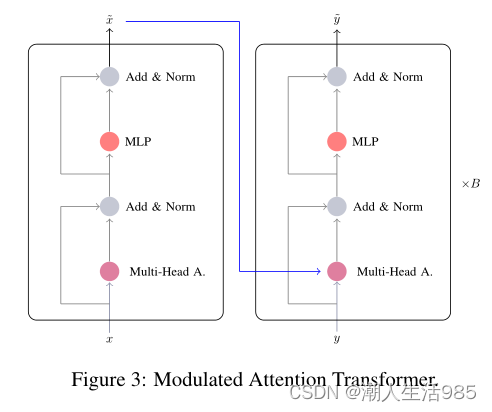
在本文中,我们提出一个架构基于两个阶段:一个基于LSTM的独立序列阶段, 其中模态特征分别计算,第二个阶段基于Transformers,其中我们迭代计算和融合新的多通道表示。
本文提出通过注意调制和线性调制,融合声学和语言特征,这是一种强大的工具,可以在给定另一种模态的表示的情况下,转换和缩放一种模态的特征图。
这种复合编码和调制融合的结合在情感识别和情感分析的广泛数据集上显示了非常强的结果。除了它提供的有趣的性能,调制不需要或很少的学习参数,使它快速和容易训练。本文的结构如下:我们首先在第2节介绍我们实验中用于比较的不同研究,然后在第3节简要介绍不同的数据集。然后,我们在第4节详细描述了基于LSTM的序列特征提取,在第5节详细描述了两个分层调制融合模型,调制注意转换器(MAT)和调制归一化转换器(MNT)。最后,我们将在第6节解释实验设置,并在第7节报告我们的模型变量的结果。
2 相关工作
本文所做的工作为我们的实验作了比较。我们继续简要描述他们提出的模型。
首先,Zadeh等人(2018b)提出了一种新的多模态融合技术,称为动态融合图(Dynamic fusion Graph, DFG),以研究多模态语言中跨模态动力学的本质。DFG包含了与模态如何相互作用直接相关的内置功效。
通过所有模式捕捉对话的上下文,对话中当前的说话者和听者,以及通过适当的融合机制捕捉现有模式之间的相关性和关系,Shenoy 和Sardana(2020)提出了一种循环神经网络架构,试图考虑所有提到的缺陷,并跟踪对话的上下文,对话者状态,以及对话中说话人所传达的情感。
Pham等人(2019)提出了一个通过模态间循环转换(MCTN)学习鲁棒联合表示的模型,该模型在各种单词对齐的人类多模态语言任务中取得了强大的结果。
Wang等人(2019)提出了循环参与V变化嵌入网络(RAVEN),通过分析词段中发生的细粒度的视觉和听觉模式来建模表达性非语言表征。此外,他们还试图通过改变非语言行为的词语表征来捕捉非语言意图的动态本质。
但相关工作,可能是最接近我们的多通道转换器(蔡et al ., 2019;delbrock等人,2020),因为他们也使用基于Transformer的解决方案来编码他们的模式。尽管如此,我们在很多方面都不同。首先,他们的最佳解决方案和得分报告都使用了视觉支持。其次,利用Transformer对每个模态对进行交叉模态编码;这相当于6个Transformer模块(每模态2对),而我们只使用两个Transformer(每模态1个)。最后,将每个输出对连接起来,通过Transformer编码的第二个阶段。我们在如何提取特征上也存在分歧:他们基于CNN而我们使用LSTM。在本文中,需要注意的是,我们将我们的结果与他们的非单词对齐分数进行比较,因为我们也不使用单词对齐。
3 数据集
3.1 IEMOCAP 数据集
IEMOCAP (Busso et al., 2008)是参与者二元对话的多模态数据集。记录的模式是音频、视频和动作捕捉数据。所有的对话都被分割、转录并标注了两种不同的情绪类型标签:情绪类别(6种基本情绪(Ekman, 1999)——快乐、悲伤、愤怒、惊讶、恐惧、厌恶——加上沮丧、兴奋和中立)和持续的情绪维度(效价、觉醒和支配)。
对于分类标签,如果他们发现情绪不能用其中一个形容词来描述,注释者也可以选择“其他”。分类标签由3-4名评估者给出。多数投票被用来确定最终的标签。在公平交易的情况下,被认为在评价者之间的协定方面不一致;10039段中的7532段达成一致。
为了与之前的研究相比较,我们使用了四种类型:中性、悲伤、快乐、愤怒。快乐类别是通过合并兴奋和快乐标签获得的(Y oon et al., 2018),我们得到了5531个话语:1636个快乐,1084个悲伤,1103个愤怒,1708个中立。训练测试的划分是根据Poria等人(2017)做出的,因为这似乎是最近工作的常态。
3.2 CMU-MOSI 数据集
CMU-MOSI (Zadeh et al., 2016)数据集是包含观点的视频剪辑的集合。这些收集到的视频来自youtube,并使用#vlog(视频博客)标签的元数据进行选择,该标签描述了一种特定类型的视频,通常包含人们表达自己的观点,结果数据集包括不同种族但都说英语的演讲者的片段。这篇演讲是手工誊写的。这些转录与音频在单词水平上是一致的。每段视频都有五名员工使用亚马逊的土耳其机器人(Mechanical Turk)对视频进行了7分的李克特评分(从-3到3)。
3.3 CMU-MOSEI 数据集
MOSEI(德et al ., 2018 c)是下一代的MOSI数据集。他们还利用含有表达意见的在线视频。他们用人脸检测算法分析了视频,并选择了只有一个人关注摄像头的视频。他们使用了一组250个不同的关键词来抓取视频,并保留每个视频最多10个,包括手动抄写。然后手动管理数据集,只保留质量好的数据。它使用7点李克特量表以及6种基本情绪类别进行标注(Ekman, 1999)。
3.4 MELD 数据集
多模态情感线数据集(MELD) (Poria等人,2019年)包含对话实例,包括音频和视觉模态以及文本。MELD收录了《老友记》电视剧中的1400多个对话和13000个话语。多名发言人参与了对话。对话中的每句话都被标记为以下7种情绪中的任何一种:愤怒、厌恶、悲伤、喜悦、中立、惊讶和恐惧。MELD对每个话语都有情绪(积极的、消极的和中性的)注释。
4 特征提取
本节旨在描述作为我们提出的基于Transformers的调制融合输入的语言和声学特征。提取是对数据集的每个样本独立执行的。我们将提取的语言特征表示为 ,声学特征表示为
。最后,
和
都有一个大小
,其中
是时间轴大小,
是特征大小。需要注意的是,
对于每个样本都是不同的,而
是一个超参数。
4.1 Linguistic(语言学)
一个句子被标记化和小写。我们去掉了特殊字符和标点符号。我们根据数据集的训练集构建词汇,并使用GloV e (Pennington et al., 2014)将每个单词嵌入一个300维的向量中。如果来自验证或测试集的单词不在我们的词汇表中,我们将其替换为未知标记“unk”。每个句子都通过一个大小为 的单向单层LSTM。因此,每个语言示例
的大小为
,其中
为句子中的单词数。
4.2 Acoustic features(声学特征)
在多模态情感识别的文献中,许多作品使用手工设计的声学特征集来捕捉韵律和音质信息,如Interspeech会议的ComPaRe (Computational Paralinguitic Challenge)特征集。
然而,随着深度学习模型的发展,较低层次的特征,如混合谱图,已经显示出对语音相关任务(如语音识别和语音合成)非常强大的功能。在这项工作中,我们提取语音谱图的过程与典型的seq2seq文本到语音系统相同。具体来说,我们的mel-谱图的提取过程与(Tachibana等人,2018)中librosa python库(McFee等人,2015)中80个滤波器组(因此嵌入大小为80)的提取过程相同。然后通过每16帧选择一帧来应用时间缩减。然后,每个声谱图通过一个尺寸为C的单向单层 LSTM。因此,每个声学示例 的大小为
,其中
为声谱图中的帧数。
5 Models(模型)
本节旨在描述在我们的实验中评估的三种模型变量。首先,我们描述第4节中提取的特征在情感和情感类上的映射(P),而不使用任何 Transformer。这与我们实验的基线相对应。其次,我们提出(Naive Transformer, NT)模型,这是一种基于Transformer的编码,输入是单独编码的,语言和声学特征不相互影响: 没有调制融合。最后,我们介绍了本文的两个重点,调制注意Transformer(MA T)和调制归一化Transformer(MNT),这两个解决方案的编码语言表示调制整个过程的声音编码。
5.1 Projection
考虑到在第4节中提取的语言特征 x 和声学特征 y ,我们将映射定义为两步过程。首先,我们在每个模态上使用注意减少机制,然后使用简单的elementwise求和融合两个模态向量。
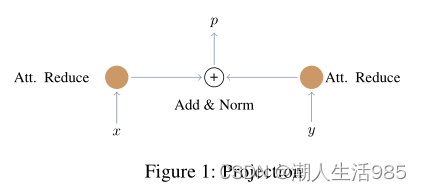
注意减少机制包括对自身的软注意和根据注意权重计算的加权总和。如果我们考虑特征输入 x 的大小为 [T, C]:
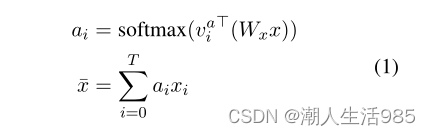
经过这种减少机制后,输入变为向量大小 [1,C]。然后我们可以应用按元素求和如下:

其中 p为可能答案的概率分布,LayerNorm表示层归一化(Ba et al., 2016)。假设输入特征x的形状为[T, C],对于每个特征通道C∈{1,2,···,C}

最后,对于每个通道,我们有可学习的参数 和
,这样:

5.2 Naive Transforme
Naive Transformer模型是在第4节提取的语言和声学特征上叠加一个Transformer,然后进行5.1节映射。Transformer是独立的,它们各自的输入特性不会相互影响。
一个Transformer是由一堆相同的B块组成的,但它们有自己的一组训练参数。每个块有两个子层。两个子层周围都有一个残差连接,然后进行层归一化(Ba et al., 2016)。每个子层的输出可以写成这样:

式中,subblayer (x)为子层自身实现的函数。在传统的Transformer中,两个子层分别是一个多头自我注意机制和一个简单的多层感知器(MLP)。
注意机制由键K和查询 Q 组成,它们相互作用,输出一个应用于Value V 的注意图:

在自我注意的情况下,K, Q和V是相同的输入。如果这个输入的大小为T × C,通过 运算得到一个平方的注意矩阵,其中包含了每一行 T 之间的亲和度。表达式
是一个比例因子。多头注意(multi-head attention, MHA)是将来自不同表示子空间的信息在不同位置上叠加多个自我注意的思想:
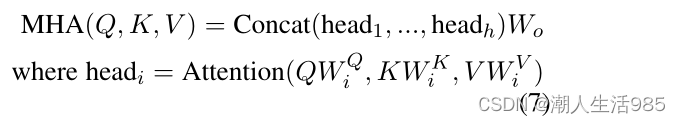
一个子空间被定义为特征维数为 k的切片。当有四头时,一个切片的大小 。其思想是为不同的特征子空间产生不同的注意权重集。在Transformers的背景下,Q, K和V为语言转换器 x 和 y 的声学Transformer。在整个MHA过程中,x 和 y的特征大小保持不变,即 C。MLP由两个不同大小的层
和
组成。通过块编码后,输出可以使用
和
分类的映射层(5.1节)。在图2中,我们显示了语言特征 x 及其相应输出
的编码。

5.3 调制融合
调制融合由调制声学特征的编码 y 给定编码的语言特征 。在声学Transformer的这种调制允许其结果将是
的两个模态的早期融合。这种调制可以通过MultiHead Attention或Layer-Normalization来执行。在这之后,输出
和n
被用作来自5.1节的投影的输入。在下一小节中,我们将继续描述这两种方法。
5.3.1 Modulated Attention Transformer(调制注意Transformer)
为了通过语言输出调节声音的自我注意,我们将自我注意的键 K 和值 V 从y 切换到 。操作
结果在一个注意力图,像一个亲和力矩阵之间的模态矩阵
和 y。这个计算的对齐被应用在值 V(现在
),最后我们添加残差连接 y 。下面的方程描述在声学Transformer新的注意力层
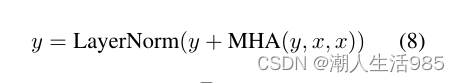
为操作 工作以及残差连接(添加),
和 y 的特征尺寸C必须相等。这可以通过MHA模块的不同变换矩阵或第4节的LSTM大小进行调整。
如果我们认为 大小是
和 y的大小是
,那么这个调制注意的矩阵乘法操作的大小可以写如下(其中×表示矩阵乘法):

式11表示 (y + MHA(y, x, x)) 运算。
我们在实验中称调制注意力转换器为“MAT”。
5.3.2 Modulated Normalization Transformer(调制归一化Transformer)
通过预测来自 的每个块的两个标量来调制规范化层是可能的,即∆γ和∆β,将被添加到方程4的可学习参数中:

其中∆γ,∆β = MLP( )和MLP有一层大小 [C, 4 × B]。每个块预测两对标量,因此标准化层之间不会共享标量。
我们相应更新层归一化方程
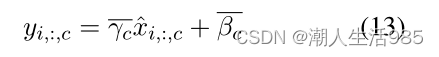
调制归一化是一种计算效率高、功能强大的神经激活调制方法。它使语言输出能够通过放大或缩小、否定或关闭整个声音特征图来操纵它们。由于每个特征图只有两个参数,所以新的训练参数总数很少。这使得调制规范化成为一种非常可扩展的方法。
在实验中,我们称调制归一化Transformer为MNT。
6 实验设置
我们使用Adam优化器(Kingma and Ba, 2014)训练我们的模型,学习率为1e−4,小批量大小为32。如果验证集上的准确性得分在给定时期内没有增加,我们就应用0.5的学习速率衰减系数。我们的学习率下降了2倍。之后,我们在准确性上使用了10个epochs。本文的结果来自于最多10个模型的平均预测。除非另有说明,LSTM的大小C(因此Transformer的大小)是512。我们对P和NT模型使用 B = 2 转换器块,对MNT和MAT模型使用 B = 4。我们使用8个多头,无论模型或编码的形式。MLP的大小 设置为2048。我们对每个块迭代的输出应用0.1的dropout,对映射层的输入(x + y)应用0.5(公式2)。
7 结果
我们在四个情感和情感识别数据集IEMOCAP、MOSEI、MOSI和MELD上给出了研究结果。对于每个数据集,结果以数据集使用的流行指标的形式呈现。大多数情况下采用F1分数,有时也采用加权 F1分数来考虑情绪或情绪类之间的不平衡。
IEMOCAP 我们首先在表3中比较了两个模型变量在IEMOCAP上的精确度、召回率和未加权F1分数。我们注意到MAT模型是最上面的。

表1:IEMOCAP的四种情绪任务结果。
Prec.表示精度,F1为未加权的F1分数。
如果我们比较每个类别的 F1 分数(表2),我们注意到我们的模型MAT优于以往的研究,最大的差距是在快乐类别。模型MulT (Tsai et al., 2019)仍然在中性类别中名列前茅。
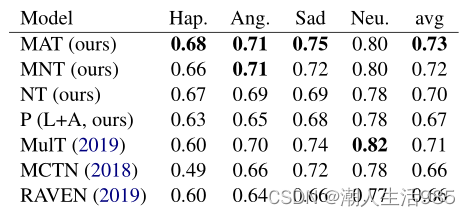
表2:IEMOCAP:每个情感类的 F1分数。Avg为 F1分数的加权平均值。
在图4中我们可以看到,我们的MNT模型有一个很好的召回在中性范畴,但MAT在快乐的愤怒类别上明显优于MNT。然而,我们可以看到,令人惊讶的是,快乐类仍然是模型的一个挑战。我们的MAT模型预测,当真正的标签感到高兴时,大约有17%的时间是“生气”的。
相反,当真正的标签是“悲伤”时,我们的模型预测19%的时间是“快乐”的,而当真正的标签是“愤怒”时,我们的模型预测17%的时间是“快乐”的。我们可以看到,对于这种矛盾的标签,这仍然是一个很大的误差范围。这表明,视觉线索可能是进一步提高表现的必要条件。
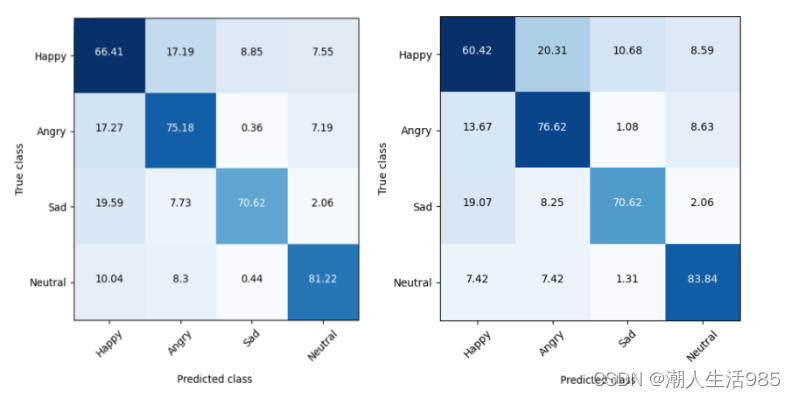
图4:IEMOCAP情感任务的混淆矩阵
MOSI MOSI是一个小数据集,训练示例很少。为了训练这样的模型,通常需要正则化来避免训练集过拟合。在我们的例子中,dropout足以超过这个数据集上最先进的结果。即使数据集在二进制答案(正的和负的)之间有点不平衡,相应地对损失进行加权并不能改善结果。它表明我们的模型变量能够有效地区分这两个类。
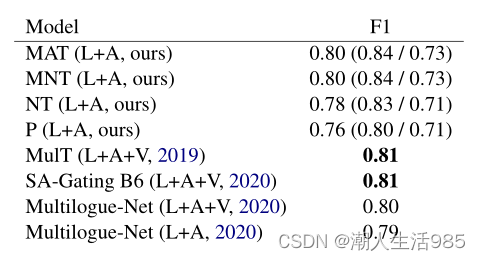
表3 :MOSI的二情任务结果。给出的结果是加权 F1得分。
MOSEI MOSEI是一个相对较大规模的数据集。我们希望看到调制变压器与朴素变压器和投影基线之间的分数有更明显的差异。在表4的情绪测试中,MNT得分最高,比最先进的“惊讶和恐惧”得分有明显的提高。

表4:MOSEI 6-emotions分类任务的结果。报告的指标是加权F1分数。
M-logue表示多语言网络,G-MFN表示图形-MFN。
多声道仍然在Happy和Angry类别中显示了强劲的结果,这是MOSEI数据集的两个重要类别,因为它们拥有最大的支持(分别为2505和1071个样本超过6336个测试集)。在二元情感分类中(表5),MA T是报道最强烈的模型。
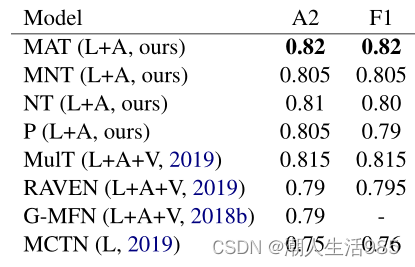
表5:MOSEI 2-sentiments任务的结果。给出的结果是准确性和加权F1分数。
MELD MELD是一个用于对话中情感识别的数据集。即使我们的方法没有考虑到上下文,我们可以看到它会导致有趣的结果。更准确地说,我们的变体能够检测出困难的情绪,比如恐惧和厌恶,尽管它们在训练和测试集中的数量非常少。
从表6中我们可以看到,即使我们不使用上下文信息和说话人信息,我们的模型在恐惧和厌恶两类中都取得了很好的结果。为了帮助理解这些结果,我们在图5中给出了两个MELD示例。在上面的例子中,“你睡着了!”如果没有上下文,它可能是惊讶或恐惧。这就是为什么我们的“愤怒”得分很低的原因。在下面的例子中,“你不知道他们有多大声”也很可能是“愤怒”,但碰巧被标记为“厌恶”。

表6:MELD的7种情绪(愤怒、厌恶、恐惧、喜悦、中立、悲伤、惊讶)任务结果。以f1分数给出结果。DRNN为DialogueRNN, G-MFN为Graph-MFN, CGCN为ConGCN。*表示模型使用上下文信息和†扬声器信息。
我们的模型在没有任何关于话语的先验或上下文偏见的情况下,有可能把类似于“你睡着了”或“你不知道怎么回事”的句子归类为“厌恶”或“恐惧”。对我们的模型为何表现如此出色的进一步分析可以揭示这种奇怪的行为。与GCN相比,我们在悲伤和惊讶这一类别上也有不足之处,这表明我们提出的模型的变体如果考虑到上下文,可能会导致具有竞争力的结果。
8 Further analysis(进一步分析)
对结果可以提出一些补充意见。首先,我们注意到转换器带来的网络层次结构确实在所有数据集上都带来了改进。事实上,与仅由LSTM和投影层组成的P模型相比,即使是NT模型也带来了显著的性能提升。我们的解决方案的一个很好的特性是,很少的transformer层需要被找到的设置。它通常从2到4层,让我们收敛迅速的解决方案。

图5:MELD:两个上下文示例,每个包含三个训练样本。
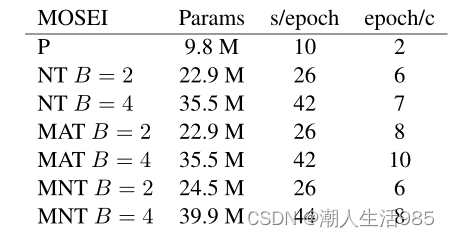
表7:C = 512时单个GTX 1080 Ti的结果。统计报告来自情绪的MOSEI数据集的任务,因为它包含最训练样本(16320)。S /epoch表示每个epoch的秒数,epoch/c表示收敛的epoch数。参数报告在百万。
另一点是,MA T变体不需要额外的训练参数,也不需要计算能力(如表7所示),该解决方案只将多头注意力的一个输入从一个模态矩阵切换到另一个。对于MNT, Transformer块只实现2个归一化层,因此条件层必须仅为∆γ和∆β计算2048个标量(假设C为512),或每个块大约100万个参数。
这个解决方案随着隐藏的大小线性增长,但是我们在C = 512而不是1024时得到了更好的结果。
MAT与MNT变体差异不大,但MAT似乎更适合于二值情感分类。通过调整注意语言和声学模态被证明是一个可以接受的解决2类问题的解决方案,但似乎不适合更微妙的分类,如多类情绪识别。MNT似乎更适合这个任务,正如MOSEI和MELD所示。MAT的一个潜在问题是,与最近的NLP解决方案(如BERT)相比,我们使用的架构较浅(B = 4),使用的层多达48层。在给出的数据集范围内,我们没有足够的样本来训练这样的架构。MNT可能对浅层进行更好的调整,因为它可以对每个区块的整个特征图进行两次调制。
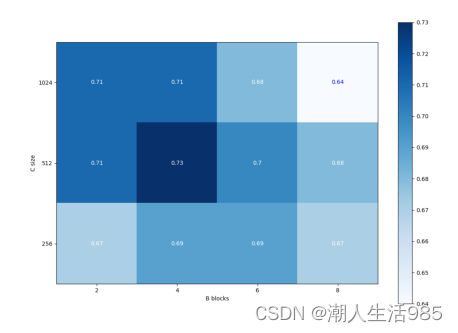
图6:热图显示影响f1-scores IEMOCAP参数B和C
9 结论
本文提出了两种不同的情感识别和情感分析体系结构:调制注意变转换器(MA T)和调制归一化转换器(MNT)。它们以Transformer 为基础,使用两种模式:语言和声音。
通过与Naive Transformer基线和适合我们实验的几个数据集上最相关的工作进行比较,我们的方法的性能得到了彻底的研究。
我们表明,与最先进的技术相比,我们单独的Transformer基线编码已经表现得很好。解决方案包括一种调频从另一种调频显示更高的性能。总的来说,该体系结构提供了一种高效、轻量级和可伸缩的解决方案,挑战,有时超越了该领域的前几项工作。















 764
764











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









