






这一分析方法会用到的库有——pandas、sklearn
部分原始数据如图所示:
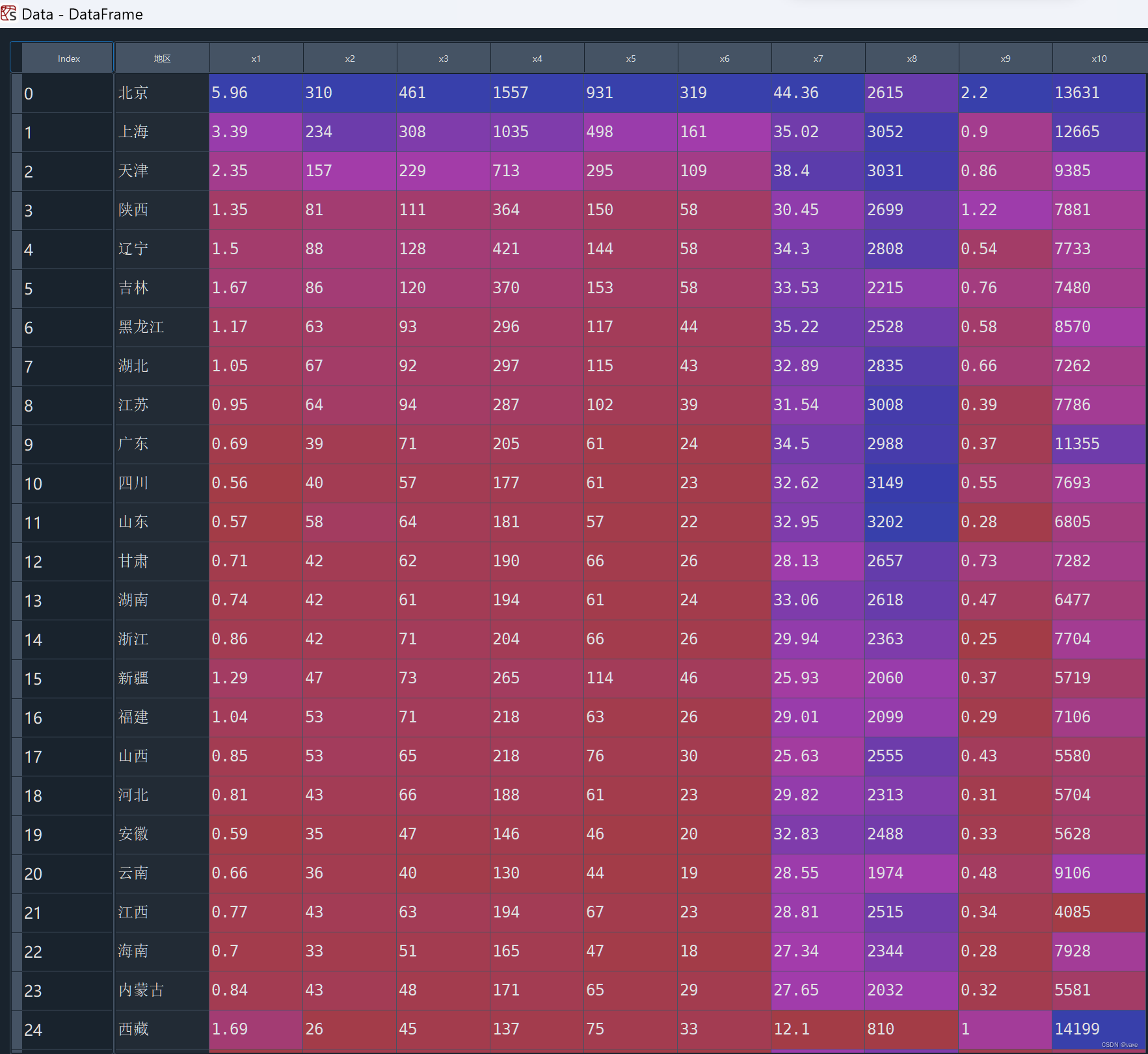
首先我们需要导入所需用到的库:
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
其次我们需要将数据进行获取及标准化处理:
Data=pd.read_excel("高等教育发展数据.xlsx")
X=Data.iloc[:,1:]
scaler=StandardScaler()
scaler.fit(X)
X=scaler.transform(X)紧接着我们会得到标准化处理之后的数据如下所示:
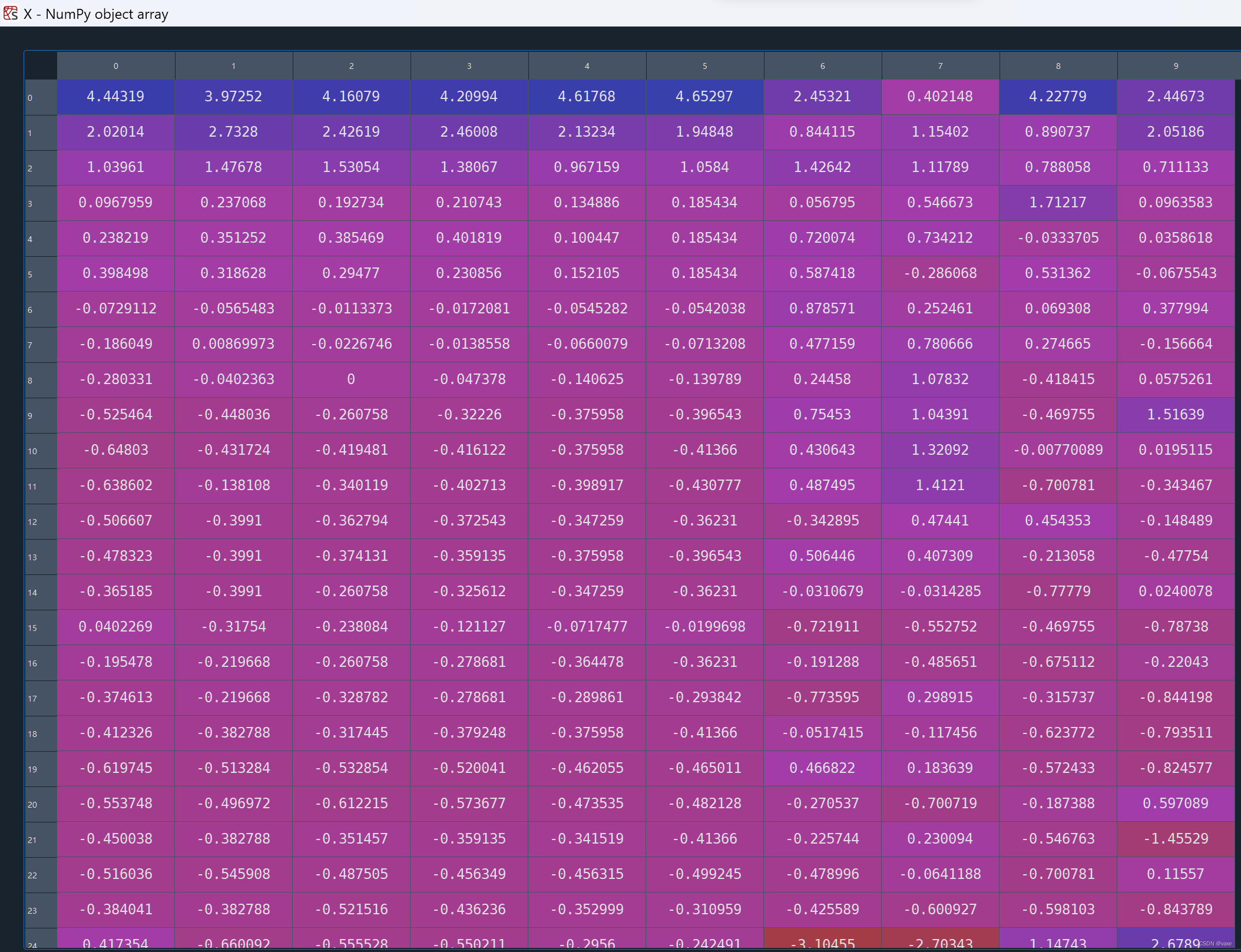
现在正式进行k-means聚类分析:
1、导入k-means聚类模块:
from sklearn.cluster import KMeans
2、利用KMeans创建K-均值聚类对象:
model=KMeans(n_clusters=4,random_state=0,max_iter=500)设置的参数有如下的说明:
n_clusters:设置的聚类个数
random_state:随机初始状态,设置为0即可
max_iter:最大迭代次数3、调用model对象中的fit()方法进行拟合训练
model.fit(X)
4、调用modle对象中的labels_属性,可以返回其聚类的标签
c=model.labels_完整代码如下所示:
import pandas as pd
from sklearn.preprocessing import StandardScaler
from sklearn.cluster import KMeans
#先对数据进行规范化处理
Data=pd.read_excel("高等教育发展数据.xlsx")
X=Data.iloc[:,1:]
scaler=StandardScaler()
scaler.fit(X)
X=scaler.transform(X)
model=KMeans(n_clusters=4,random_state=0,max_iter=500)
model.fit(X)
c=model.labels_
Fs=pd.Series(c,index=Data['地区'])
print(Fs)
Fs=Fs.sort_values(ascending=True)得到的结果各位自行运行吧!!!















 3912
3912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









