






62.不同路径
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为 “Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为 “Finish” )。
问总共有多少条不同的路径?
分析:
1、确定dp数组(dp table)以及下标的含义dp[i][j] :
表示从(0 ,0)出发,到(i, j) 有dp[i][j]条不同的路径。
2、确定递推公式
想要求dp[i][j],只能有两个方向来推导出来,即dp[i - 1][j] 和 dp[i][j - 1]。
此时在回顾一下 dp[i - 1][j] 表示啥,是从(0, 0)的位置到(i - 1, j)有几条路径,dp[i][j - 1]同理。
那么很自然,dp[i][j] = dp[i - 1][j] + dp[i][j - 1],因为dp[i][j]只有这两个方向过来。
3、dp数组的初始化
首先dp[i][0]一定都是1,因为从(0, 0)的位置到(i, 0)的路径只有一条,那么dp[0][j]也同理。
所以初始化代码为:
for (int i = 0; i < m; i++) dp[i][0] = 1;
for (int j = 0; j < n; j++) dp[0][j] = 1;
4、确定遍历顺序
这里要看一下递推公式dp[i][j] = dp[i - 1][j] + dp[i][j - 1],dp[i][j]都是从其上方和左方推导而来,那么从左到右一层一层遍历就可以了。
这样就可以保证推导dp[i][j]的时候,dp[i - 1][j] 和 dp[i][j - 1]一定是有数值的。
——时间空间复杂度都是o(m*n)相当于都要遍历一遍
**但是实际上用一个一维数组也可以完成,用dp[i]=dp[i] 实际上是上一层的值+dp[i-1] 是左边的值
可以将空间复杂度优化至o(n)
二维数组解法:
int uniquePaths(int m, int n) {
//二维数组的创建
int **dp=(int **)malloc(sizeof(int *)* m);
for (int i=0;i<m;i++){
dp[i]=malloc(sizeof(int)*n);
dp[i][0]=1;
}
for(int i = 0; i < m; ++i)
dp[i][0] = 1;
for(int j = 0; j < n; ++j)
dp[0][j] = 1;
for(int i = 1; i < m; ++i) {
for(int j = 1; j < n; ++j) {
dp[i][j] = dp[i-1][j] + dp[i][j-1];
}
}
return dp[m-1][n-1];
}一维数组解法:
int uniquePaths(int m, int n) {
int *dp=(int *)malloc(sizeof(int )* n);
for(int j = 0; j < n; ++j)
dp[j] = 1;
for (int x=1;x<m;x++){
for(int i = 1; i < n; ++i) {
dp[i] = dp[i] + dp[i-1];
}
}
return dp[n-1];
}63. 不同路径 II
一个机器人位于一个 m x n 网格的左上角 (起始点在下图中标记为“Start” )。
机器人每次只能向下或者向右移动一步。机器人试图达到网格的右下角(在下图中标记为“Finish”)。
现在考虑网格中有障碍物。那么从左上角到右下角将会有多少条不同的路径?
分析:
递归公式需要修改:
考虑到这格本来是障碍物的话——能走到这里的路径数目为0
这格前面有障碍物——来自这个方向的路径数目为0
初始化需要修改:
在第一行第一列可能出现障碍物,在第一行第一列中出现障碍物后的右侧/下侧 应当初始化为0
int uniquePathsWithObstacles(int** obstacleGrid, int obstacleGridSize, int* obstacleGridColSize) {
int m=obstacleGridSize;
int n=*obstacleGridColSize;
int **bp=(int**)malloc(sizeof(int*)*m);
int i,j;
if(obstacleGrid[0][0]==1) return 0;
int flag=1;
for (i=0;i<m;i++){
bp[i]=malloc(sizeof(int)*n);
bp[i][0]=flag;
if(obstacleGrid[i][0]==1) {
bp[i][0]=0;
flag=0;
}
}
flag=1;
for (j=0;j<n;j++){
bp[0][j]=flag;
if(obstacleGrid[0][j]==1) {
bp[0][j]=0;
flag=0;
}
}
for (i=1;i<m;i++){
for (j=1;j<n;j++){
if(obstacleGrid[i][j]==1) bp[i][j]=0;
else bp[i][j]=bp[i-1][j]+bp[i][j-1];
}
}
return bp[m-1][n-1];
}343. 整数拆分
给定一个正整数 n,将其拆分为至少两个正整数的和,并使这些整数的乘积最大化。 返回你可以获得的最大乘积。
示例 1:
- 输入: 2
- 输出: 1
- 解释: 2 = 1 + 1, 1 × 1 = 1。
示例 2:
- 输入: 10
- 输出: 36
- 解释: 10 = 3 + 3 + 4, 3 × 3 × 4 = 36。
- 说明: 你可以假设 n 不小于 2 且不大于 58。
分析:
1、dp数组的意义:i这个数字能拆分出的最大积存放在dp【i】中
2、递归:拆分成2个——j*(i-j)
拆分成很多个——bp【i-j】*j
**实际上不需要考虑 bp【i-j】*bp【j】这类情况——在上一部分就已经是拆成多个了,这个和上一个重复
3、初始化:其实从题目要求的2开始就可以了!
4、顺序:从前往后
5、打印
int integerBreak(int n) {
int *bp=(int *)malloc(sizeof(int)*(n+1));
bp[0]=0;
bp[1]=0;
bp[2]=1;
for (int i=2;i<=n;i++){
for (int j=1;j<i;j++){
bp[i]=fmax(bp[i], fmax(j*(i-j), fmax(j*bp[i-j], bp[j]*bp[i-j])));
}
}
return bp[n];
}96.不同的二叉搜索树
给定一个整数 n,求以 1 ... n 为节点组成的二叉搜索树有多少种?
分析:
先举几个例子——找规律
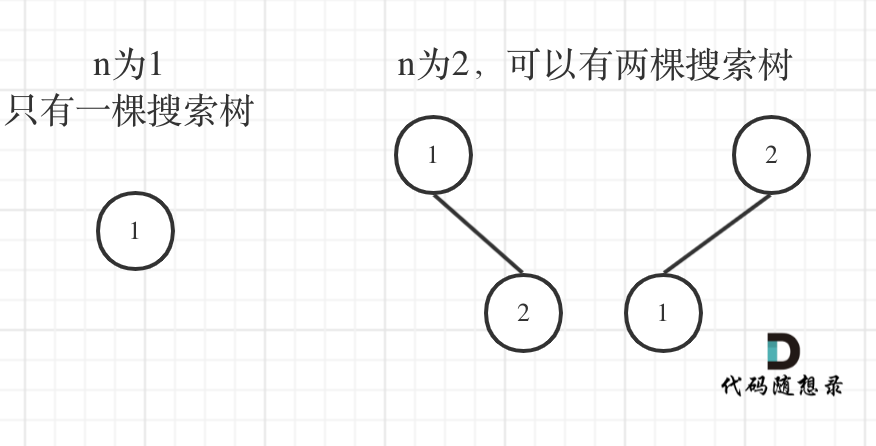

来看看n为3的时候,有哪几种情况。——只关心搜索树的数量!!
当1为头结点的时候,其右子树有两个节点,看这两个节点的布局,是不是和 n 为2的时候两棵树的布局是一样的啊!
当3为头结点的时候,其左子树有两个节点,看这两个节点的布局,是不是和n为2的时候两棵树的布局也是一样的啊!
当2为头结点的时候,其左右子树都只有一个节点,布局是不是和n为1的时候只有一棵树的布局也是一样的啊!
发现到这里,其实我们就找到了重叠子问题了,其实也就是发现可以通过dp[1] 和 dp[2] 来推导出来dp[3]的某种方式。
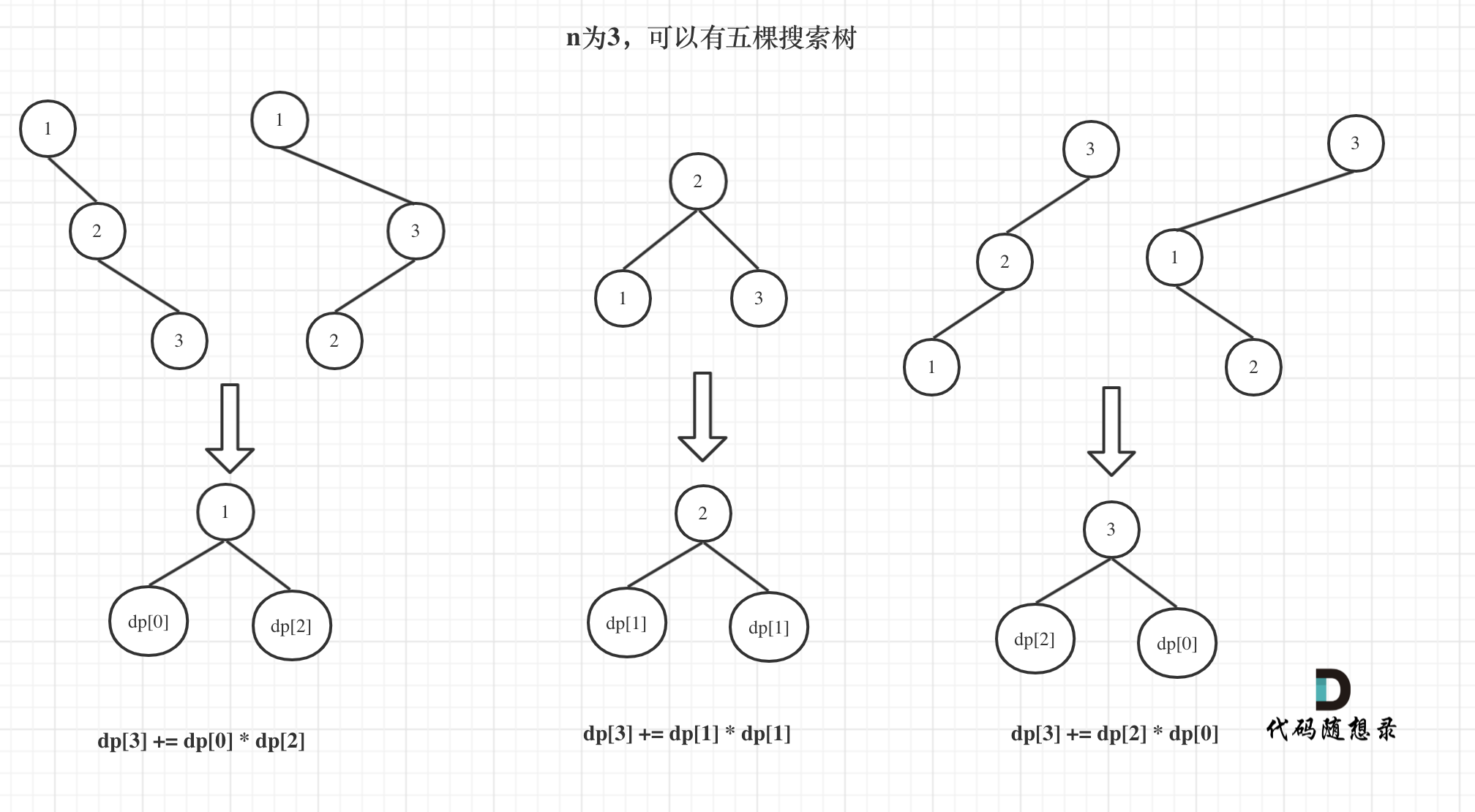
dp[3],就是 元素1为头结点搜索树的数量 + 元素2为头结点搜索树的数量 + 元素3为头结点搜索树的数量
元素1为头结点搜索树的数量 = 右子树有2个元素的搜索树数量 * 左子树有0个元素的搜索树数量
元素2为头结点搜索树的数量 = 右子树有1个元素的搜索树数量 * 左子树有1个元素的搜索树数量
元素3为头结点搜索树的数量 = 右子树有0个元素的搜索树数量 * 左子树有2个元素的搜索树数量
有2个元素的搜索树数量就是dp[2]。
有1个元素的搜索树数量就是dp[1]。
有0个元素的搜索树数量就是dp[0]。
所以dp[3] = dp[2] * dp[0] + dp[1] * dp[1] + dp[0] * dp[2]
如图所示:
1、确定dp数组(dp table)以及下标的含义dp[i] : 1到i为节点组成的二叉搜索树的个数为dp[i]。
也可以理解是i个不同元素节点组成的二叉搜索树的个数为dp[i] ,都是一样的。
以下分析如果想不清楚,就来回想一下dp[i]的定义
2、确定递推公式:
dp[i] += dp[以j为头结点左子树节点数量] * dp[以j为头结点右子树节点数量]
j相当于是头结点的元素,从1遍历到i为止。
所以递推公式:dp[i] += dp[j - 1] * dp[i - j]; ,j-1 为j为头结点左子树节点数量,i-j 为以j为头结点右子树节点数量
3、dp数组如何初始化初始化:只需要初始化dp[0]就可以了,推导的基础,都是dp[0]。
那么dp[0]应该是多少呢?
从定义上来讲,空节点也是一棵二叉树,也是一棵二叉搜索树,这是可以说得通的。
从递归公式上来讲,dp[以j为头结点左子树节点数量] * dp[以j为头结点右子树节点数量] 中以j为头结点左子树节点数量为0,也需要dp[以j为头结点左子树节点数量] = 1, 否则乘法的结果就都变成0了。
所以初始化dp[0] = 1
4、确定遍历顺序:
首先一定是遍历节点数,从递归公式:dp[i] += dp[j - 1] * dp[i - j]可以看出,节点数为i的状态是依靠 i之前节点数的状态。
那么遍历i里面每一个数作为头结点的状态,用j来遍历。
代码如下:
for (int i = 1; i <= n; i++) {
for (int j = 1; j <= i; j++) {
dp[i] += dp[j - 1] * dp[i - j];
}
}
int numTrees(int n){
//开辟dp数组
int *dp = (int *)malloc(sizeof(int) * (n + 1));
int i;
for(i = 0; i <= n; ++i)
dp[i] = 0;
dp[0] = 1;
int j;
for(i = 1; i <= n; ++i) {
for(j = 1; j <= i; ++j) {
//递推公式:dp[i] = dp[i] + 根为j时左子树种类个数 * 根为j时右子树种类个数
dp[i] += dp[j - 1] * dp[i - j];
}
}
return dp[n];
}














 611
611

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









