






提示1:本篇使用Python实现算法代码
一、堆的前备知识
(一)树、二叉树介绍
1.树
树是一种数据结构,那么什么是树结构呢?
树结构好比你电脑的文件目录结构,其底层就是树结构的层级关系。
树也是一种可以递归定义的数据结构,树是由n个节点组成的集合:如果n=0,那这是一颗空树;如果n>0,那么存在一个节点作为树的根节点(下一段有介绍),其他节点可以分为m个集合,每个集合本身又是一颗树。为了能够理解这句话,我给出下面一张树的图,如图我们看,如果n=0,那么这棵树没有任何节点,则是一颗空树,如果n>0则A就是这整棵树的根节点,而诸如B、C、D、E等等,其余下部分本身又都是一棵树(如图二给出的部分示例)。
图一

图二

怎么看待树结构呢?
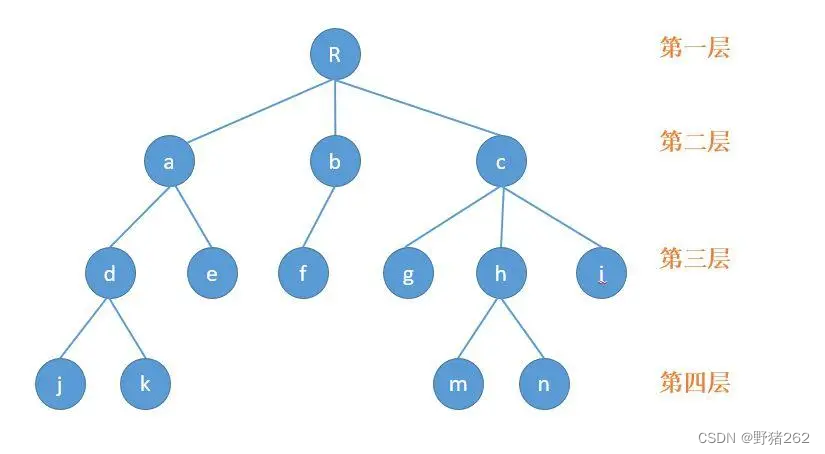
简单来说,树就是由许多个节点连接组成,且有相应的层级关系,类似于族谱,在最上面的“祖宗”我们称他为根节点,但在树结构中没有爷爷或者其他一说,节点和节点之间的关系只有父节点和子节点。这里我给出下面这张图,如图R是根节点,而a,b,c都是R的子节点,那么R就是a、b、c的父节点,同样的以下节点都有相应的相互关系。
接下来介绍关于树的几个概念:
叶子节点,为了能够更好的理解叶子节点,我们不如将图三中的树倒过来看,就像一颗树,树的最顶端最上面才是叶子,那么在树结构中也是同样的道理,最顶端的节点就是叶子节点,下图中的j、k、e、f、g、m、n、i均为叶子节点
树的深度(高度):很显然,树的深度就是树的层数,如下图树的深度为4。
树的度:在介绍树的度之前我想先介绍一下节点的度,什么是节点的度,简单来说就是这个节点有多少个子节点,例如图中的R有三个子节点,那么他的度为3,以此类推。那么什么是树的度呢,树的度就是这整颗树中所有节点中最大的那个度,下图中该树的度为3,因为R节点和c节点的度都为3且最大。
子树:关于子树,上面的图二中有很多示例,很简单,把根节点R看成树的下半部分,从他的子节点开始当做树的树枝部分,你每掰下一串树枝都可以成为这棵树的子树。
图三
2.二叉树
二叉树基本介绍:
1.二叉树为度不超过2的树
2.树的每个节点最多有两个子节点(根据上面树的介绍其实和第一点是一个道理)
3.两个子节点被区分为左子结点和右子节点
了解完二叉树的基本性质之后,完成堆排序我们需要了解以下几种二叉树:
第一种:满二叉树,一个二叉树,如果每一层的节点数都达到最大值,则这个二叉树就是满二叉树。
图四 满二叉树

第二种:完全二叉树,叶子节点只能出现在最下层和次下层,并且最下层的节点都集中在该层最左边的若干位置的二叉树。
图五 完全二叉树
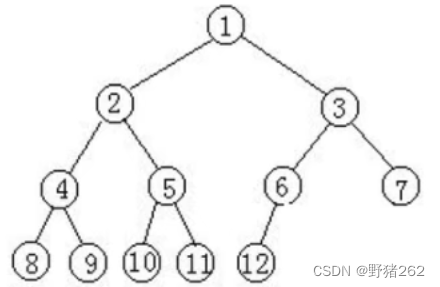
第三种:非完全二叉树,根据完全二叉树的定义,不满足其定义的二叉树就是非完全二叉树,如下图中的二叉树均不是完全二叉树,因为其某些叶子节点不在该层的最左边位置。
图六 非完全二叉树

若还不能理解,下面给出一篇优秀博客,详尽的介绍了树以及二叉树的相关概念。
树、二叉树、完全二叉树、满二叉树的概念和性质-CSDN博客![]() https://blog.csdn.net/weixin_57675461/article/details/121323091
https://blog.csdn.net/weixin_57675461/article/details/121323091
3.练习
给出下面几张树的图片,请判断其为什么二叉树(结尾附答案)
图七 某树

图八 某树
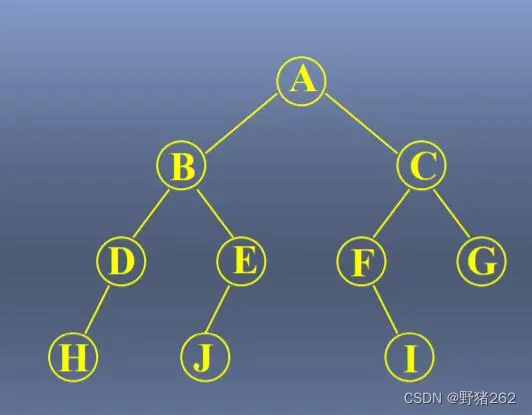
图九 某树

4. 二叉树的顺序存储方式
为了介绍二叉树的顺序存储方式,这里先引入一个数组:
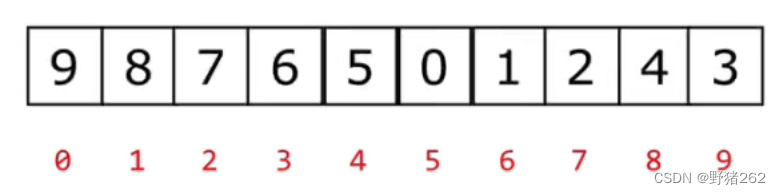
学过编程基础知识的都知道,计算机中数组的存储下标索引一般是从0开始,以数组长度减一结束。那么我们怎么样将数组按顺序存储到树当中的呢?在这之前首先说明一下,堆排序所使用的堆必须为完全二叉树,至于为什么要完全二叉树,后面将有讲解。接着说,数组在完全二叉树中的存储如下图,将数组中的数按顺序存入完全二叉树中。
通过以上的了解,我们知道在树中我们是通过父节点和子节点之间建立联系的,那么完全二叉树如何能像数组一样通过索引去遍历出树中的所有数据呢?在二叉树中,我们有以下的方式来建立父节点和左右子节点之间的联系。
举个简单的例子,我们看下面这个图中所有的父节点与左子节点的下标索引之间的关系:0-1、1-3、2-5、3-7、4-9,你是否已经看出规律,这里我就直接说明了,父节点与左子节点的关系是:假设父节点的下标索引为i,那么其左子节点的下标索引为2 * i + 1。同样的父节点与右节点的关系是父节点的下标索引为i。那么右子节点的下标索引为2 * i + 2。
图十 数组在完全二叉树中的存储

至此,树和二叉树的介绍就告一段落,如果还有不了解的地方,请参考第二节后面给出的链接博客。
(二)堆及堆排序简介
1.堆的基本概念
- 堆是一颗特殊的完全二叉树
- 堆的向下调整性质
- 任意根节点值>=子节点值,叫做大根堆。
- 任意根节点值<=子节点值,叫做小根堆。
- 堆的基本作用是快速找到数组中的最值。
2.堆排序
堆排序(英文名:Heapsort)是指利用堆这种数据结构所设计的一种排序算法。堆是一个近似完全二叉树的结构,并同时满足堆积的性质:即子结点的键值或索引总是小于(或者大于)它的父节点。
堆排序主要是利用堆删除的思想来进行排序:将堆顶与末尾位置进行交换,此时必然会破坏堆的结构,所以在交换后,需要重新对二叉树进行调整使之重新成为一个堆,但是交换后来的元素不会参与后续的调整,这里可以通过设置一个末尾标志位实现,没完成一次交换,末尾标志位向前移动一位,直到调整完整个序列,完成堆排序。以上是关于堆的向下调整,将在下一章介绍。
(三)堆的类型
1.大根堆
上一节中就有介绍,通俗来说大根堆就是所有的父节点都比其自身的子节点都大,才满足大根堆的特性。
图十一 大根堆

2.小根堆
同样的,小根堆就是所有的父节点都比其子节点的值小,称为小根堆。
图十二 小根堆

二、堆的向下调整(以大根堆为例)
(一)向下调整的介绍
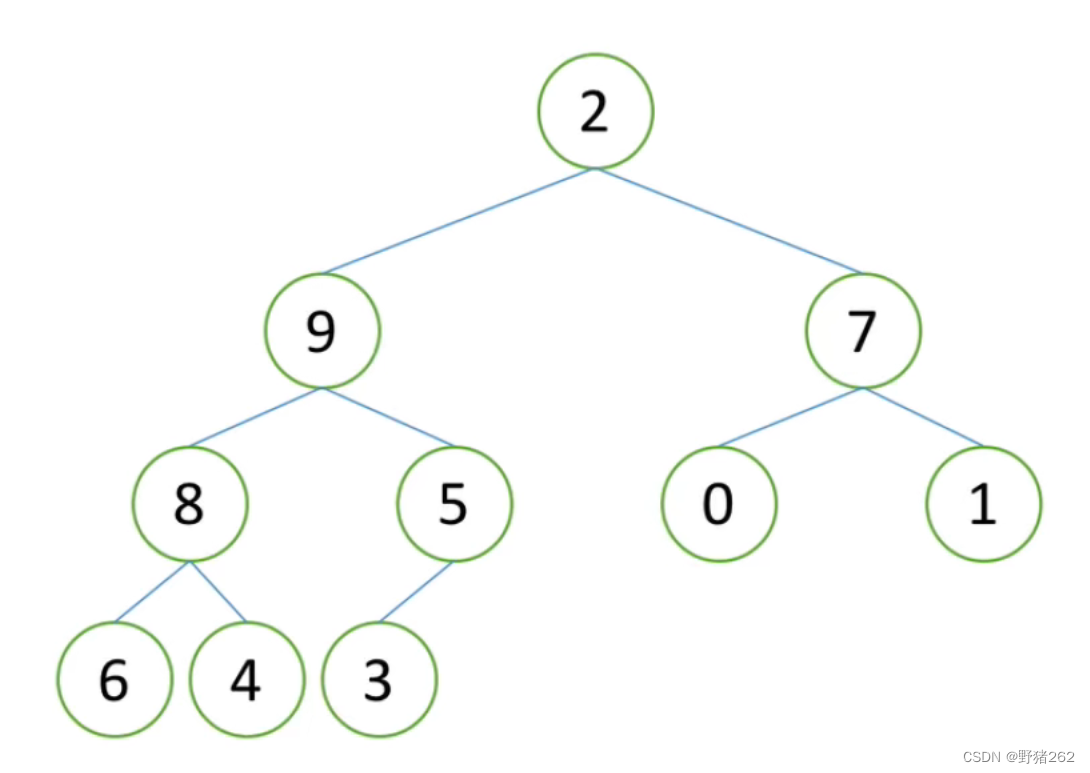
关于堆的向下调整算法,这里将给出一个例子,我们首先需要做出一个假设,假设节点的左右子树都是堆,但自身不是堆。怎么理解这句话,看下面的图,很显然这个堆并不是一个大根堆,因为根节点2小于其子节点。但是,根节点以下的左右子树都是堆,那么我们现在需要的是如何将这整棵树变成一个堆,很简单,我们可以进行一次堆的向下调整。
图十三 待调整的堆
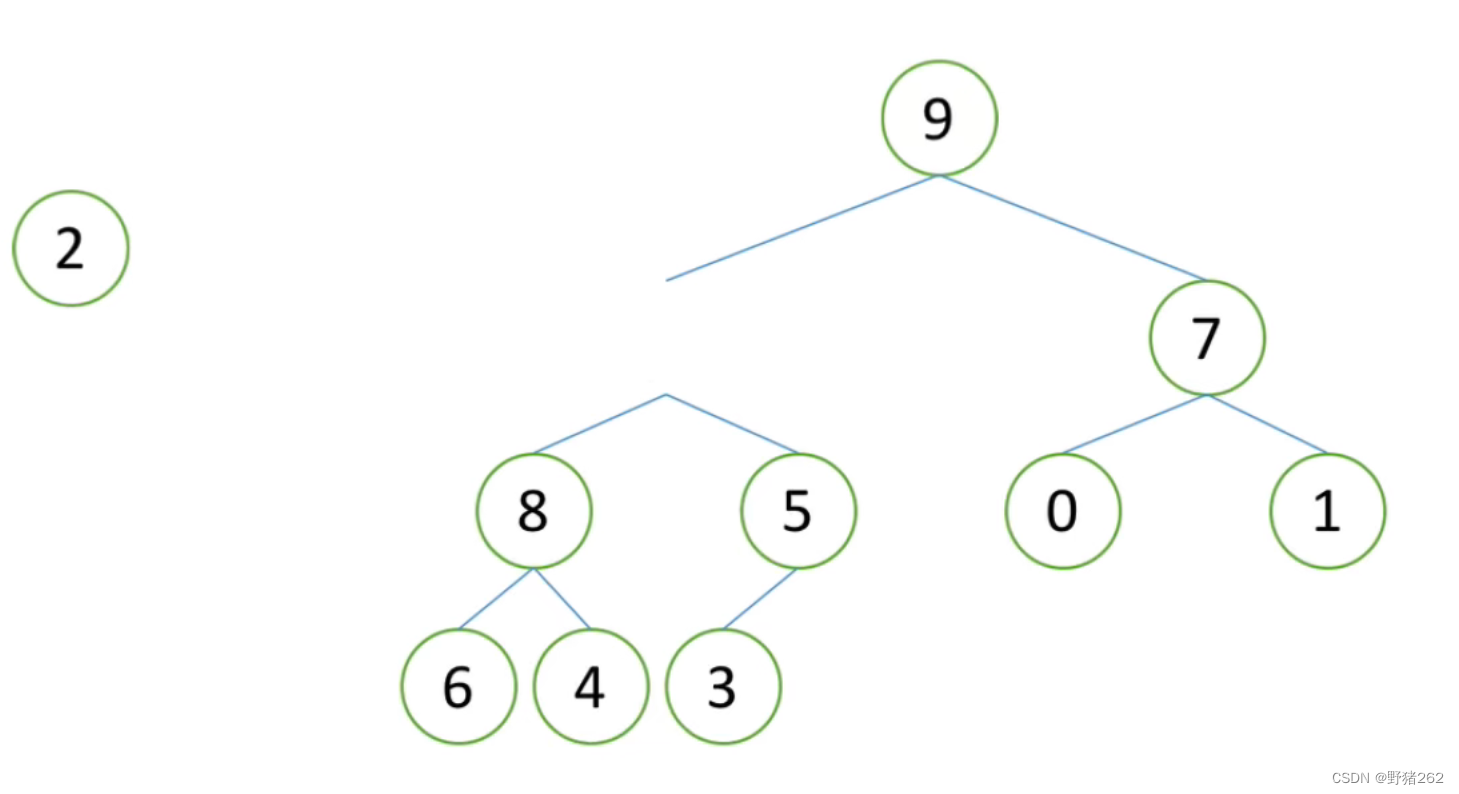
堆的向下调整,我们首先取出了原来的根节点2,那么现在的问题就是,根节点的这个位置应该放谁呢?很明显,我们需要建立的是一个大根堆,所以应该是子节点中大的那一个数往上走,占领根节点的位置,此时若将2放到原来9的位置,同样的,再进行一次判断,因为2比8和5都小,所以2不能作为8和5的父节点,再进行一次向下调整,需要注意的是,这个过程类似于递归,但不同于递归,向下调整实质上就是利用递归的思想进行一步一步的判断并进行调整。
图十四 取出树的根节点

图十五 调整中的堆
通过堆的向下调整,我们成功的构造出了一个大根堆,那么其他的情况也类似,记住一点,不论是大根堆还是小根堆,进行向下调整的过程就是将父节点与其左右子节点进行比较的过程,利用递归的思想将整个堆调整成我们需要的类型,以便我们接下来进行的堆排序。
图十六 调整完的堆(大根堆)

如果关于堆的调整方式想有更加透彻的了解,下面为您找到一篇优秀的博客。
堆的向上与向下调整-CSDN博客![]() https://blog.csdn.net/m0_73299809/article/details/131463936
https://blog.csdn.net/m0_73299809/article/details/131463936
(二)向下调整代码实现
# 调整函数
def sift(arr, low, high):
i = low # 指向堆顶
j = 2 * i + 1 # 指向堆顶的左子结点
tmp = arr[i] # 临时存储父节点
while j <= high: # 只要子节点索引小于列表最大索引
if j + 1 <= high and arr[j+1] > arr[j]:
# 判断左右子节点的大小,如果右边大把j指向右边
j = j + 1
if arr[j] > tmp:
arr[i] = arr[j]
i = j
j = 2 * i + 1
else:
# 如果父节点比左右子节点都大
arr[i] = tmp
break
else:
# 跳出循环表示上面已经调整完毕,
# i指向了叶子结点,表示tmp存的数
# 比其父节点都小,所以将其赋值到
# 叶子节点上
arr[i] = tmp代码导读:
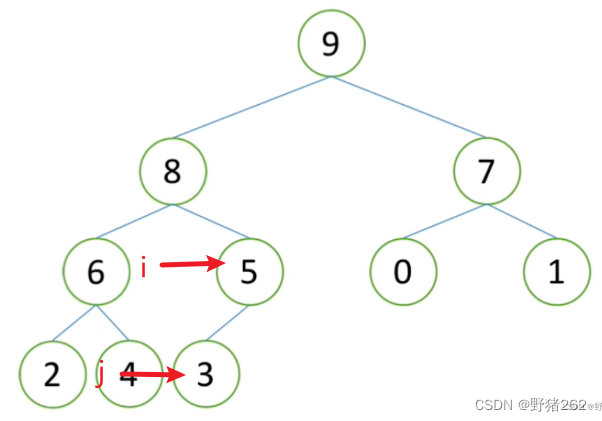
首先定义一个函数,我们名为sift,传入参数:数组arr,堆的根节点索引low,堆最后一个节点索引high。将i赋值为low,意思是让i指向根节点,从根节点开始进行向下调整,j指向的是根节点的左子节点,如图十七。
由于我们调整中需要把其比较的父节点(示例中指的是根节点)拿出来,所以我们需要用一个临时变量将其存储起来避免数据被覆盖,上述中我们知道需要利用递归的思想但又不同于递归,我们不需要再次调用这个调整函数,我们只需要写一个while循环即可,那么循环的结束判断语句是什么,这里需要注意了,我们在进行调整的过程中当i指向最后一个非叶子节点(叶子节点第一章有介绍),j就指向了堆的最后一个元素,也就是最后一个非叶子节点的左叶子节点,如图十八,你可能会问,那假如最后一个非叶子节点有右子节点呢,如果有右子节点,那么此时的j还满足循环条件,此时我们需要讨论循环中的内容了。
循环内的代码不难推断,第一个if判断了左右子节点的大小,如果右边大就把j指向右子节点(执行的操作就是j = j + 1),判断条件是j+1要比堆的最后一个下标索引小,意思就是其非叶子节点存在右子节点。第二个if判断如果子节点中大的那个节点比其父节点的数值要大,那么进行一次调整,然后将i赋值为j,j赋值为2*i+1,同样还是指向新的i的左子节点,接而进行下一轮调整。else执行的条件是如果父节点比其子节点都大,就把取出的数值再赋值回来。
跳出循环的else,表示上面已经调整完毕,此时i指向了某个叶子节点,我们需将被取出的tmp值再赋值回去,避免数值被覆盖。
图十七 指针指向的节点

图十八 指向最后一个非叶子节点
三、堆排序过程演示
(一)过程演示
这里给出一个算法可视化演示的网址,以便大家以后进行算法学习时,有助于理解:
Data Structure Visualization (usfca.edu)![]() https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
下面是堆排序的可视化演示过程:
Heap Sort Visualization (usfca.edu)![]() https://www.cs.usfca.edu/~galles/visualization/HeapSort.html
https://www.cs.usfca.edu/~galles/visualization/HeapSort.html
(二)总结堆排序过程
- 第一步建立一个堆
- 得到堆顶元素(根节点)
- 去掉堆顶元素,将堆的最后一个元素放到堆顶,此时可以通过前面写的调整函数进行一次调整使得堆重新有序
- 此时的堆顶元素为整个堆中第二大的元素,取出
- 重复以上步骤,直到堆变空
四、堆排序代码实现
(一)建堆
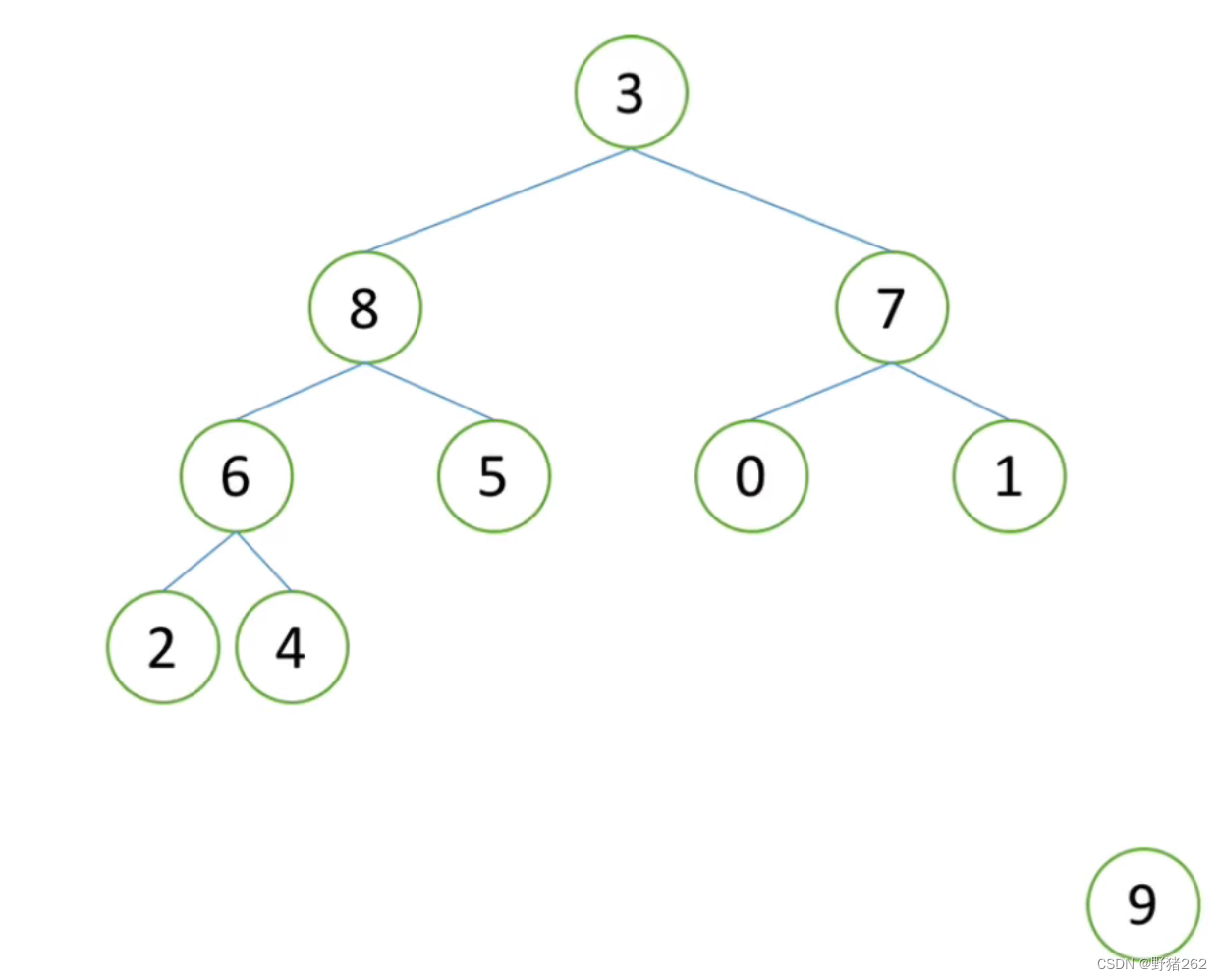
建堆是一个及其重要的过程,我们不能侥幸的每次都能得到向之前示例中的堆(除了堆顶元素,其左右子树都是堆),为此我们需要如何去构造一个堆,构造堆的难度不大,但需要理解透彻。以下我会用非常通俗的方式来讲解。
图十九 需构造堆的完全二叉树
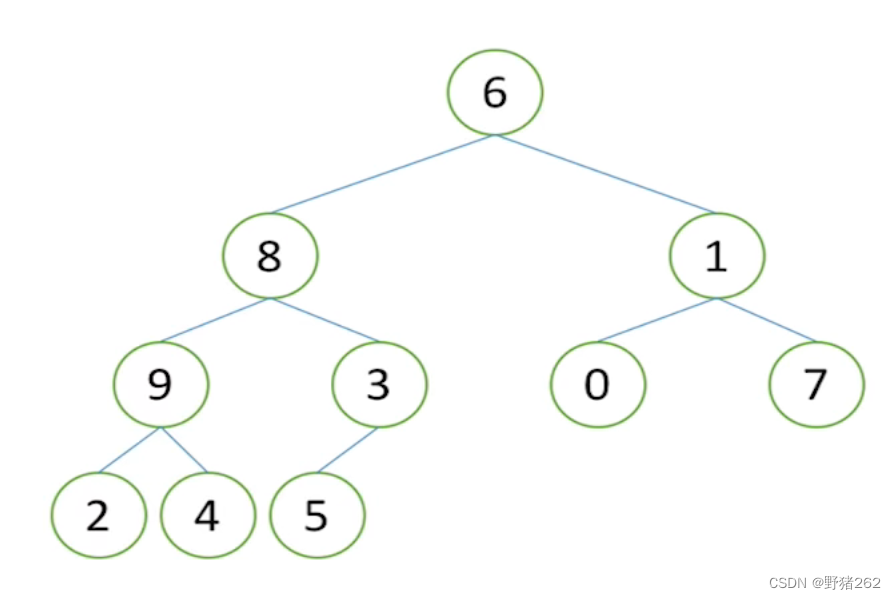
怎样使得这个完全二叉树变成一个堆呢?给出的方法是“农村包围城市” ,什么意思,我们从最底层也就是最下面开始进行建堆,从一颗颗子树开始建堆,过程也类似于递归的思想。如图十九,我们得出最下面的子树如下图,我们根据大根堆的性质对其进行调整,把3跟5进行一个交换,此时这颗子树就是一个堆了,同样的重复这样的方法,如图二十一、二十二,直到将整个完全二叉树建造成一个大根堆。
图二十 最下面的子树
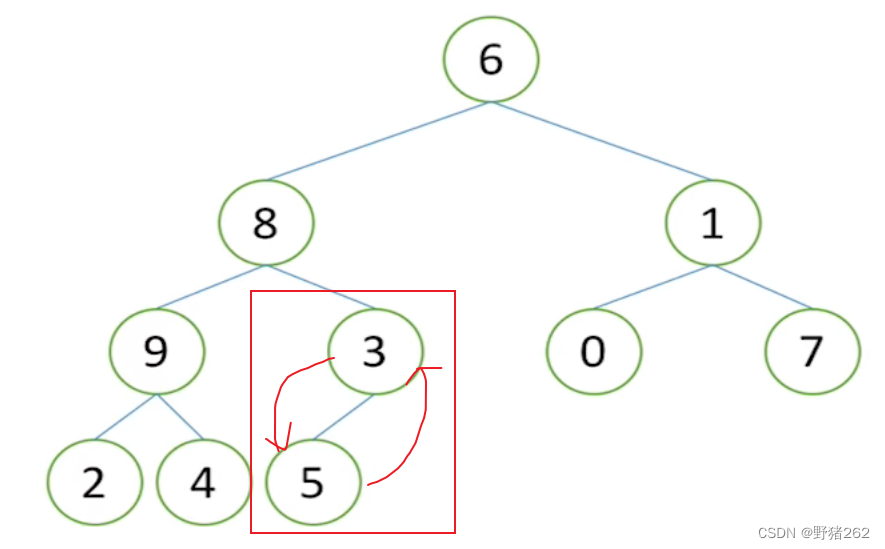
图二十一

图二十二

建堆的Python代码:
def heap_sort(arr):
n = len(arr) # 列表长度
# 关于(n-2)//2:农村包围城市,从最后一个
# 非叶子节点开始调整,n-1表示最后一个元素
# 根据子节点找父节点的公式可得其父节点可表示为
# (n-1-1)//2
for i in range((n-2)//2, -1, -1):
sift(arr, i, n-1)
print(arr) # 打印建堆完成的数组
arr = [i for i in range(1000)]
import random
random.shuffle(arr)
print(arr)
heap_sort(arr)
print(arr)代码导读:
堆排序的英文名为heapsort,所以我们将函数名取为heap_sort,传入一个参数为数组,(n-2)//2表示从i指向最后一个非叶子节点开始,使用“农村包围城市”的方法进行堆的构建。最后我们随机生成一个大小为1000,数值为1000以内的数组,利用random模块中的shuffle方法进行数据的打乱,然后利用heap_sort进行建堆,最后结果如图二十三:
图二十三 建堆部分结果

怎么看下面那排是已经建好的堆,我们同样像之前那样按顺序将建堆完成的数组填入到二叉树中,得出的便是一个堆。
建堆完成后我们就看到了如图十八一样的堆,接下来我们将利用建造完成的堆进行排序算法的实现了。
(二)排序
我们从第三章第二节的堆排序总结中得出,我们需要将堆的堆顶元素取出,依次取出就可以得到有序的数组,如图二十四。那么我们有必要再创建一个列表来存储这些数据吗,如果再创建一个列表我们将会浪费很多内存资源,在数据为数以十万计百万计等的时候。所以很显然,肯定有不需要再创建一个新列表的办法,科学家很聪明的提出,可以利用原有的堆储存有序数组,当有序数组填满整个堆时我们可以利用堆的性质来遍历得到有序数组。
图二十四
我们得到堆中最大元素后将其存入堆的最后一个位置,我们将其称为堆的有序区,而其他的部分称为无序区,此时我们应该将调整函数中的high值减一,以免将有序区的数也进行调整。如此循环进行,我们可以得到由原来的堆内存存储的一个完全有序的堆。
heap_sort完整代码:
def heap_sort(arr):
n = len(arr) # 列表长度
# 关于(n-2)//2:农村包围城市,从最后一个
# 非叶子节点开始调整,n-1表示最后一个元素
# 根据子节点找父节点的公式可得其父节点可表示为
# (n-1-1)//2
for i in range((n-2)//2, -1, -1):
sift(arr, i, n-1)
print(arr) # 打印建堆完成的数组
for i in range(n-1, -1, -1):
# 利用现有数组进行元素存储
# 堆顶元素为数组最大的元素
# 用列表最后一个元素进行交换从后面开始
# 存储有序列表
arr[0], arr[i] = arr[i], arr[0]
# i-1表示待调整堆的最后一个元素
sift(arr, 0, i-1)代码导读:
我们通过前面进行了堆的建立,此时我们应该将堆顶的最大元素与堆的最后一个元素进行交换,然后再将堆的最后一个元素指向有序区的前一位,循序进行,直到i指向堆顶,堆中只剩下最后一个元素,也就是最小的元素时,循环结束,此时整个堆中就是一个有序的数组。
(三)完整代码
# 调整函数
def sift(arr, low, high):
i = low # 指向堆顶
j = 2 * i + 1 # 指向堆顶的左子结点
tmp = arr[i] # 临时存储父节点
while j <= high: # 只要子节点索引小于列表最大索引
if j + 1 <= high and arr[j+1] > arr[j]:
# 判断左右子节点的大小,如果右边大把j指向右边
j = j + 1
if arr[j] > tmp:
arr[i] = arr[j]
i = j
j = 2 * i + 1
else:
# 如果父节点比左右子节点都大
arr[i] = tmp
break
else:
# 跳出循环表示上面已经调整完毕,
# i指向了叶子结点,表示tmp存的数
# 比其父节点都小,所以将其赋值到
# 叶子节点上
arr[i] = tmp
# 建堆
"""
找左子结点:2 * i + 1
找右子结点:2 * i + 2
找父节点:(i-1)//2
"""
def heap_sort(arr):
n = len(arr) # 列表长度
# 关于(n-2)//2:农村包围城市,从最后一个
# 非叶子节点开始调整,n-1表示最后一个元素
# 根据子节点找父节点的公式可得其父节点可表示为
# (n-1-1)//2
for i in range((n-2)//2, -1, -1):
sift(arr, i, n-1)
print(arr) # 打印建堆完成的数组
for i in range(n-1, -1, -1):
# 利用现有数组进行元素存储
# 堆顶元素为数组最大的元素
# 用列表最后一个元素进行交换从后面开始
# 存储有序列表
arr[0], arr[i] = arr[i], arr[0]
# i-1表示待调整堆的最后一个元素
sift(arr, 0, i-1)
arr = [i for i in range(1000)]
import random
random.shuffle(arr)
print(arr)
heap_sort(arr)
print(arr)运行结果:
图二十五 部分运行结果

最后一排数据便是排序完成的数组。
五、堆排序引出的topk问题
(一)topk简介
topk问题:在一组数据中取出前k大的数据。顾名思义如果我们需要从一组无序列表中找到前k大的数据,首先我们应该对其进行排序,然后再取出其前k大的数据。
1. 用数据集合中前k个元素来建堆
- 取前k个最大的元素,建小堆
- 取前k个最小的元素,建大堆
2.用剩余的N-k个元素依次与堆顶元素来比较,不满足则替换堆顶元素,在进行向下调整。
将剩余N-k个元素依次与堆顶元素比较完之后,堆中剩余的K个元素就是所求的前K个最小或者最大的元素。
实际应用:微博热搜、抖音热搜、百度指数等
(二)代码实现
先附上完整代码,因类似于堆排序,故无需做过多介绍:
# topk问题
# 调整函数
def sift1(arr, low, high):
i = low
j = 2 * i + 1
tmp = arr[low]
while j <= high:
if j + 1 <= high and arr[j+1] < arr[j]:
j = j + 1
if arr[j] < tmp:
arr[i] = arr[j]
i = j
j = 2 * i + 1
else:
arr[i] = tmp
break
else:
arr[i] = tmp
def topk(arr, k):
heap = arr[0:k]
for i in range((k-2)//2, -1, -1):
sift1(heap, i, k-1)
for i in range(k, len(arr)-1):
if arr[i] > heap[0]:
heap[0] = arr[i]
sift1(heap, 0, k-1)
for i in range(k-1, -1, -1):
heap[0], heap[i] = heap[i], heap[0]
sift1(heap, 0, i-1)
return heap
arr = [i for i in range(1000)]
import random
random.shuffle(arr)
print(arr)
print(topk(arr, 10))代码导读:
因为我们需要取出前k大的数,所以你仔细看topk的调整函数中的判断条件有略微的变化,其实就是将大根堆变成了小根堆,这样我的获取前k大的数更加的方便。根据第一节中topk的简介我们知道先对前k个数据进行建堆,然后从后面k+1个1元素开始遍历,与前k个数中的数进行比较,再次进行调整得出新的堆,最后利用“农村包围城市”的方法进行堆的排序。
六、总结
堆排序的时间复杂度:怎么判断堆排序的时间复杂度,我们可以看出,sift调整函数是一个折半调整的过程,所以一次sift的时间复杂度是O(logn),而在排序函数中每一次for循环的时间复杂度为O(n),那么整个堆排序的时间复杂度为O(n * logn),属于相对于冒泡排序、选择排序、插入排序较快的一种排序算法,但归根结底都属于比较排序中的一种,且堆排序是一种不稳定的排序算法。
七、附答案
图七:完全二叉树
图八:非完全二叉树
图九:满二叉树














 471
471











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









