







雪花算法
首先雪花算法为什么出现呢,因为现在的服务基本是分布式、微服务形式的,而且大数据量也导致分库分表的产生,对于水平分表就需要保证表中 id 的全局唯一性。
如果还是借助数据库主键自增的形式,那么可以让不同表初始化一个不同的初始值,然后按指定的步长进行自增。例如有3张拆分表,初始主键值为1,2,3,自增步长为3。
而这种方法又有些许的复杂,不同互联网公司也有自己内部的实现方案。雪花算法是其中一个用于解决分布式 id 的高效方案,也是许多互联网公司在推荐使用的。
什么是雪花算法呢?
SnowFlake 雪花算法
SnowFlake 中文意思为雪花,故称为雪花算法。最早是 Twitter 公司在其内部用于分布式环境下生成唯一 ID。在2014年开源 scala 语言版本。
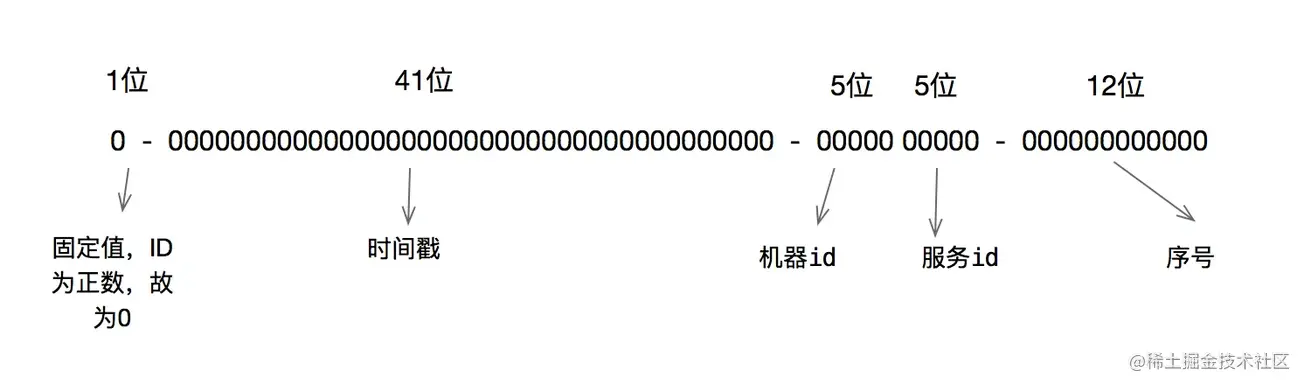
雪花算法的原理就是生成一个的 64 位比特位的 long 类型的唯一 id。
第一部分:最高 1 位固定值 0,因为生成的 id 是正整数,如果是 1 就是负数了。
第二部分:接下来 41 位存储毫秒级时间戳,2^41/(1000*60*60*24*365)=69,大概可以使用 69 年。
第三部分:再接下 10 位存储机器码,包括 5 位 datacenterId 和 5 位 workerId。最多可以部署 2^10=1024 台机器。
第四部分:最后 12 位存储序列号。同一毫秒时间戳时,通过这个递增的序列号来区分。即对于同一台机器而言,同一毫秒时间戳下,可以生成 2^12=4096 个不重复 id。
简单来说:如果你的服务需要生成一个全局唯一的id,那么就可以发送一个请求给部署了雪花算法的系统,由雪花算法系统来生成唯一的id.
雪花算法的优点:
1、由于生成的id中有时间戳,整体上就是按照时间戳来递增的,所以生成的id不会重复
2、如果部署多台服务器,利用雪花算法,也不会生成重复的id
3、在同一毫秒戳下,可以生成生成 2^12=4096 个不重复 id,也就是1秒4096000个id
4、雪花算法是不依赖数据库的,是在内存中生成的
雪花算法的缺点:
由于雪花算法依赖时间完成,所以如果时间被回调,那么就也可能出现id重复的情况,不过一般情况下不会发生。















 983
983











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









