







黑马Oracle练习题
统计某日的收费,按区域分组汇总,效果如下
select (select name from t_area where id = areaid ) 区域,
sum(usenum)/1000 用水量,sum(money) 金额
from t_account
where to_char(feedate,'yyyy-mm-dd')='2012-05-14'
group by areaid
统计某收费员某日的收费,按区域分组汇总,效果如下
select (select name from t_area where id = areaid ) 区域,
sum(usenum)/1000 用水量,sum(money) 金额
from t_account
where to_char(feedate,'yyyy-mm-dd')='2012-05-14'
and feeuser=2
group by areaid
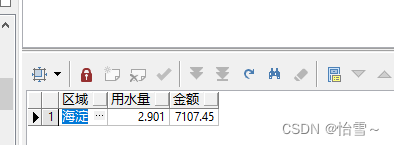
统计某年某月的收费记录,按区域分组汇总
select (select name from t_area where id = areaid ) 区域,
sum(usenum)/1000 用水量,sum(money) 金额
from t_account
where to_char(feedate,'yyyy-mm')='2012-05'
group by areaid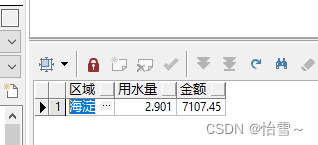
统计某年收费情况,按区域分组汇总,效果如下
select (select name from t_area where id = areaid ) 区域,
sum(usenum)/1000 用水量,sum(money) 金额
from t_account
where to_char(feedate,'yyyy') = '2012'
group by areaid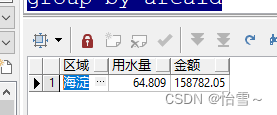
统计某年收费情况,按月份分组汇总,效果如下
select to_char(feedate,'mm') 月份,sum(usenum)/1000 使用吨数,sum(money) 金额
from t_account
where to_char(feedate,'yyyy') = '2012'
group by to_char(feedate,'mm')
order by to_char(feedate,'mm')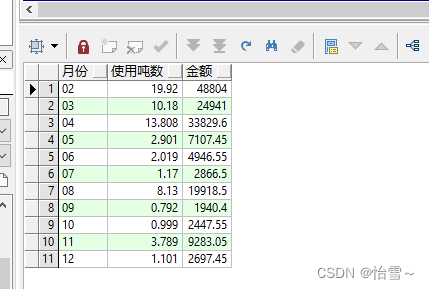
统计某年收费情况,按月份分组汇总,效果如下

select '用水量(吨)' 统计项,
sum(case when to_char(feedate,'mm')='01' then usenum else 0 end)/1000 一月,
sum(case when to_char(feedate,'mm')='02' then usenum else 0 end)/1000 二月,
sum(case when to_char(feedate,'mm')='03' then usenum else 0 end)/1000 三月,
sum(case when to_char(feedate,'mm')='04' then usenum else 0 end)/1000 四月,
sum(case when to_char(feedate,'mm')='05' then usenum else 0 end)/1000 五月,
sum(case when to_char(feedate,'mm')='06' then usenum else 0 end)/1000 六月,
sum(case when to_char(feedate,'mm')='07' then usenum else 0 end)/1000 七月,
sum(case when to_char(feedate,'mm')='08' then usenum else 0 end)/1000 八月,
sum(case when to_char(feedate,'mm')='09' then usenum else 0 end)/1000 九月,
sum(case when to_char(feedate,'mm')='10' then usenum else 0 end)/1000 十月,
sum(case when to_char(feedate,'mm')='11' then usenum else 0 end)/1000 十一月,
sum(case when to_char(feedate,'mm')='12' then usenum else 0 end)/1000 十二月
from t_account
where to_char(feedate,'yyyy')='2012'
union all
select '金额' 统计项,
sum(case when to_char(feedate,'mm')='01' then money else 0 end) 一月,
sum(case when to_char(feedate,'mm')='02' then money else 0 end) 二月,
sum(case when to_char(feedate,'mm')='03' then money else 0 end) 三月,
sum(case when to_char(feedate,'mm')='04' then money else 0 end) 四月,
sum(case when to_char(feedate,'mm')='05' then money else 0 end) 五月,
sum(case when to_char(feedate,'mm')='06' then money else 0 end) 六月,
sum(case when to_char(feedate,'mm')='07' then money else 0 end) 七月,
sum(case when to_char(feedate,'mm')='08' then money else 0 end) 八月,
sum(case when to_char(feedate,'mm')='09' then money else 0 end) 九月,
sum(case when to_char(feedate,'mm')='10' then money else 0 end) 十月,
sum(case when to_char(feedate,'mm')='11' then money else 0 end) 十一月,
sum(case when to_char(feedate,'mm')='12' then money else 0 end) 十二月
from t_account
where to_char(feedate,'yyyy')='2012'
根据业主类型分别统计每种居民的用水量(整数,四舍五入)及收费金额 ,如果该类型在台账表中无数据也需要列出值为0的记录 , 效果如下:
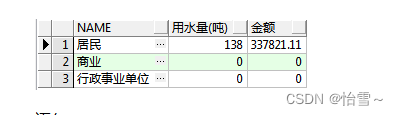
select ow.name NAME,
nvl(round(sum(usenum)/1000),0) "用水量(吨)",
nvl(sum(money),0) 金额
from t_ownertype ow,t_account ac
where ow.id=ac.ownertype(+)
group by ow.name #左外连接: LEFT JOIN 是以左表的记录为基础表,右表的记录为补充表,示例中A表可以看成左表,B表可以看成右表,它的结果集是A表中的全部数据,再加上A表和B表匹配后的数据。换句话说,左表(A)的记录将会全部表示出来,而右表(B)只会显示符合搜索条件的记录。A表有B表没有的记录对应的B表列显示为NULL。 #sum(): SUM(x) 添加x中的所有值,并返回总和。 #分组group by: group by 有一个原则,就是 select 后面的所有列中,没有使用聚合函数的列,必须出现在 group by 后面 group by 语法规范 首先我们准备一张Student表
CREATE TABLE STUDENT
( SNO VARCHAR2(10) not null,
SNAME VARCHAR2(20),
SAGE NUMBER(2),
SSEX VARCHAR2(5) )往里面插入几条学生实体记录。再查看数据: SELECT * FROM STUDENT;
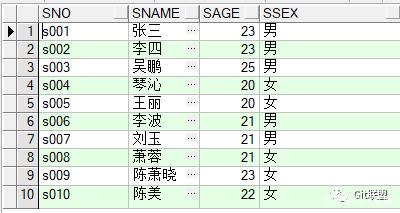
我们使用group by将这些数据按照性别进行分组: SELECT * FROM STUDENT GROUP BY SSEX; 不幸的是,执行失败了,提示:不是 GROUP BY 表达式!
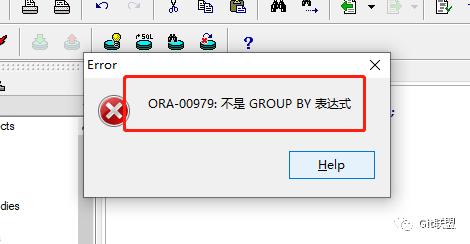
原因是group by 分组查询,select子句后的字段必须来自group by后的分组字段。于是 我们执行SQL SELECT SSEX FROM STUDENT GROUP BY SSEX;
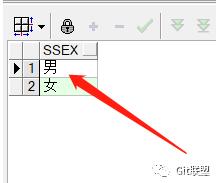
这下成功地将数据分为了两组。我们接下来使用下聚合函数 SELECT SSEX,MAX(SAGE) FROM STUDENT GROUP BY SSEX; 注意这条sql语句,select子句中聚合函数使用了SAGE(年龄)这个字段,那会不会违背了前面所说的 “select子句后的字段必须来自group by后的分组字段”这个规律呢,我们来执行一下:
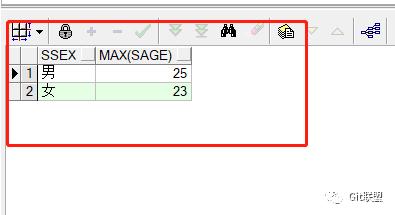
能正常执行,成功地按照了性别分组,并且查询出了性别对应年龄最大的学生。于是我们可以得出规律:select子句后的任一非聚合函数字段都应来源于group by 分组语句后,否则语法会编译不通过
#round(): Round函数用法: 截取数字 格式如下:ROUND(number[,decimals]) 其中:number 待做截取处理的数值 decimals 指明需保留小数点后面的位数。可选项,忽略它则截去所有的小数部分,并四舍五入。如果为负数则表示从小数点开始左边的位数,相应整数数字用0填充,小数被去掉。需要注意的是,和trunc函数不同,对截取的数字要四舍五入。 #nvl() NVL函数是一个空值转换函数 NVL(表达式1,表达式2) 如果表达式1为空值,NVL返回值为表达式2的值,否则返回表达式1的值。该函数的目的是把一个空值(null)转换成一个实际的值。其表达式的值可以是数字型、字符型和日期型。但是表达式1和表达式2的数据类型必须为同一个类型。
统计每个区域的业主户数,并列出合计
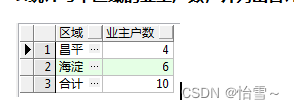
select ar.name 区域,count(ow.id) 业主户数
from
t_owners ow,t_area ar,t_address ad
where ow.addressid=ad.id and ad.areaid = ar.id
group by ar.name
union all
select '合计',count(1) from T_OWNERS
UNION语法如下:
SELECT column1,column2,... FROM table1 UNION SELECT column1,column2,... FROM table2
UNION操作的结果会去除相同的数据记录,并且按默认升序的方式把结果集排序 例如:我们创建TEST1以及TEST2两张表如下: 创建表test1:
create table TEST1
(
ID VARCHAR2 (10 ),
NAME VARCHAR2 (20 )
);
insert into test1( id, name ) values ( '1', 'andy');
insert into test1(id,name) values('2','ashely');
insert into test1(id,name) values('3','dona');
create table TEST1 创建表test2并插入三条数据
create table TEST2
(
ID VARCHAR2 (10 ),
NAME VARCHAR2 (20 )
);
insert into test1( id, name ) values ( '1', 'andy');
insert into test1(id,name) values('2','ashely');
insert into test1(id,name) values('3','beta'); UNION测试: SELECT id,name FROM test1 结果如下: ID NAME 1 andy 2 ahsely 3 dona SELECT id,name FROM test2 结果如下: ID NAME 1 andy 2 ahsely 3 beta 而这两个SELECT结果集UNION的结果如下: SELECT id,name FROM test1 UNION SELECT id,name FROM test2 结果如下: ID NAME 1 andy 2 ahsely 3 beta 3 dona 从结果我们可以看出: 1、UNION 在合并两个结果集会选择不同的值,把重复的数据记录只保留一份 2、UNION后的数据集会默认排序,如果我们需要按照需要进行排序的话,只用在最后一个SELECT语句中 加上排序语句如 SELECT id,name FROM test1 UNION SELECT id,name FROM test2 ORDER BY name ASC;就会按照name进行升序排序 3、UNION的结果列名会自动取第一个SELECT的列名作为返回数据集的列名与其他SELECT列名无关,因此其他数据列列名可省略是需要数据列数目相同,并且对应列的类型相同或者可以自动转换,但是实际应用中最好每个SELECT语句中加上对应的列名
UNION ALL
UNION ALL 我们直接看下TEST1与TEST2使用UNION ALL的结果集: SELECT id,name FROM test1 UNION ALL SELECT id,name FROM test2 其结果集如下: ID NAME 2 ahsely 2 ahsely 1 andy 1 andy 3 beta 3 dona 从查询的结果集我们可以得出以下结论: 1、UINON ALL合并的两个SELECT数据集会把所有的记录都列出来,包括重复的数据 2、UNION ALL的结果集没有顺序,如果需要对结果集进行排序,需要在最后一个SELECT语句中使用ORDER BY 如: SELECT id,name FROM test1 UNION ALL SELECT id,name FROM test2 ORDER BY name; 3、UNION ALL与UNION类似返回的结果集的列名与第一个SELECT列名相同,与其他SELECT的列名无关 因此在实际的开发和使用过程中,需要根据需求来确定使用UNION还是UNION ALL
统计每个区域的业主户数,如果该区域没有业主户数也要列出 0
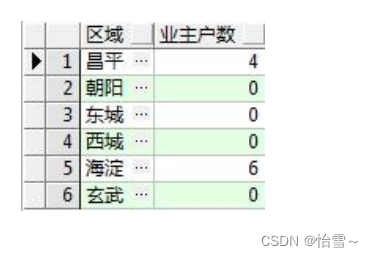
select ar.name 区域,count(owad.name) 业主户数
from T_AREA ar ,
(
select ow.id,ow.name,ad.areaid from T_OWNERS ow,T_ADDRESS ad where ow.addressid=ad.id
)
owad
where ar.id=owad.areaid(+)
group by ar.name














 557
557











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









