






第1关:堆叠操作
任务描述
本关任务:根据本关所学知识,实现均值统计功能。
相关知识
为了完成本关任务,你需要掌握: stack 。
stack
stack 的意思是堆叠的意思,所谓的堆叠就是将两个 ndarray 对象堆叠在一起组合成一个新的 ndarray 对象。根据堆叠的方向不同分为 hstack 以及 vstack 两种。
hstack
假如你是某公司的 HR,需要记录公司员工的一些基本信息。可能你现在已经记录了如下信息:
| 工号 | 姓名 | 出生年月 | 联系电话 |
|---|---|---|---|
| 1 | 张三 | 1988.12 | 13323332333 |
| 2 | 李四 | 1987.2 | 15966666666 |
| 3 | 王五 | 1990.1 | 13777777777 |
| 4 | 周六 | 1996.4 | 13069699696 |
世界上没有不变的需求,你的老板让你现在记录一下公司所有员工的居住地址和户籍地址,此时你只好屁颠屁颠的记录这些附加信息。然后可能会有这样的结果:
| 居住地址 | 户籍地址 |
|---|---|
| 江苏省南京市禄口机场宿舍202 | 江西省南昌市红谷滩新区天月家园A座2201 |
| 江苏省南京市禄口机场宿舍203 | 湖南省株洲市天元区新天华府11栋303 |
| 江苏省南京市禄口机场宿舍204 | 四川省成都市武侯祠安置小区1栋701 |
| 江苏省南京市禄口机场宿舍205 | 浙江省杭州市西湖区兴天世家B座1204 |
接下来你需要把之前记录的信息和刚刚记录好的附加信息整合起来,变成酱紫:
| 工号 | 姓名 | 出生年月 | 联系电话 | 居住地址 | 户籍地址 |
|---|---|---|---|---|---|
| 1 | 张三 | 1988.12 | 13323332333 | 江苏省南京市禄口机场宿舍202 | 江西省南昌市红谷滩新区天月家园A座2201 |
| 2 | 李四 | 1987.2 | 15966666666 | 江苏省南京市禄口机场宿舍203 | 湖南省株洲市天元区新天华府11栋303 |
| 3 | 王五 | 1990.1 | 13777777777 | 江苏省南京市禄口机场宿舍204 | 四川省成都市武侯祠安置小区1栋701 |
| 4 | 周六 | 1996.4 | 13069699696 | 江苏省南京市禄口机场宿舍205 | 浙江省杭州市西湖区兴天世家B座1204 |
看得出来,你在整合的时候是将两个表格(二维数组)在水平方向上堆叠在一起组合起来,拼接成一个新的表格(二维数组)。像这种行为称之为 hstack(horizontal stack)。
NumPy 提供了实现 hstack 功能的函数叫 hstack,hstack 的使用套路代码如下:
import numpy as npa = np.array([[8, 8], [0, 0]])b = np.array([[1, 8], [0, 4]])'''将a和b按元组中的顺序横向拼接结果为:[[8, 8, 1, 8],[0, 0, 0, 4]]'''print(np.hstack((a,b)))c = np.array([[1, 2], [3, 4]])'''将a,b,c按元组中的顺序横向拼接结果为:[[8, 8, 1, 8, 1, 2],[0, 0, 0, 4, 3, 4]]'''print(np.hstack((a,b,c)))
vstack
你还是某公司的 HR,你记录了公司员工的一些信息,如下:
| 工号 | 姓名 | 出生年月 | 联系电话 |
|---|---|---|---|
| 1 | 张三 | 1988.12 | 13323332333 |
| 2 | 李四 | 1987.2 | 15966666666 |
| 3 | 王五 | 1990.1 | 13777777777 |
| 4 | 周六 | 1996.4 | 13069699696 |
今天有两位新同事入职,你需要记录他们的信息,如下:
| 工号 | 姓名 | 出生年月 | 联系电话 |
|---|---|---|---|
| 5 | 刘七 | 1986.5 | 13323332331 |
| 6 | 胡八 | 1997.3 | 15966696669 |
然后你需要将新入职同事的信息和已经入职的员工信息整合在一起。
| 工号 | 姓名 | 出生年月 | 联系电话 |
|---|---|---|---|
| 1 | 张三 | 1988.12 | 13323332333 |
| 2 | 李四 | 1987.2 | 15966666666 |
| 3 | 王五 | 1990.1 | 13777777777 |
| 4 | 周六 | 1996.4 | 13069699696 |
| 5 | 刘七 | 1986.5 | 13323332331 |
| 6 | 胡八 | 1997.3 | 15966696669 |
在这种情况下,你在整合的时候是将两个表格(二维数组)在竖直方向上堆叠在一起组合起来,拼接成一个新的表格(二维数组)。像这种行为称之为 vstack(vertical stack)。
NumPy 提供了实现 vstack 功能的函数叫 vstack,vstack 的使用套路代码如下:
import numpy as npa = np.array([[8, 8], [0, 0]])b = np.array([[1, 8], [0, 4]])'''将a和b按元组中的顺序纵向拼接结果为:[[8, 8][0, 0][1, 8][0, 4]]'''print(np.vstack((a,b)))c = np.array([[1, 2], [3, 4]])'''将a,b,c按元组中的顺序纵向拼接结果为:[[8 8][0 0][1 8][0 4][1 2][3 4]]'''print(np.vstack((a,b,c)))
编程要求
根据提示,在右侧编辑器 Begin-End 部分补充代码,补充完成 get_mean(featur1, feature2) 函数,其中:
-
feature1:待hstack的ndarray; -
feature2:待hstack的ndarray; -
返回值:类型为
ndarray,其中值为hstack后每列的平均值; -
具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试。你只需按要求完成函数即可。
测试用例输入是一个字典,feature1 部分代表函数中的 feature1, feature2 部分代表函数中的 feature2。
测试输入: {'feature1':[[1, 2, 3, 4], [4, 3, 2, 1], [2, 3, 4, 5]], 'feature2':[[1], [2], [3]]}
预期输出: [2.33333333 2.66666667 3. 3.33333333 2. ]
代码如下:
import numpy as np
def get_mean(feature1, feature2):
'''
将feature1和feature2横向拼接,然后统计拼接后的ndarray中每列的均值
:param feature1:待`hstack`的`ndarray`
:param feature2:待`hstack`的`ndarray`
:return:类型为`ndarray`,其中的值`hstack`后每列的均值
'''
#********* Begin *********#
feature3 = np.hstack((feature1,feature2))
return feature3.mean(axis=0)
#********* End *********#
第2关:比较、掩码和布尔逻辑
任务描述
本关任务:编写一个能比较并筛选数据的程序。
相关知识
为了完成本关任务,你需要掌握:
- 比较;
- 布尔数组作掩码;
- 布尔逻辑。
比较
在许多情况下,数据集可能不完整或因无效数据的存在而受到污染。我们要基于某些准则来抽取、修改、计数或对一个数组中的值进行其他操作时,就需要掩码了。接下来将学习如何用 布尔掩码 来查看和操作数组中的值。
和算术运算符一样,比较运算符在 numpy 中也是通过通用函数来实现的。比较运算符和其对应的通用函数如下:
| 比较运算符 | 通用函数 |
|---|---|
== | np.equal |
!= | np.not_equal |
< | np.less |
<= | np.less_equal |
> | np.greater |
>= | np.greater_equal |
这些比较运算符通用函数可以用于任意形状、大小的数组。示例如下:
data=np.array([('Alice', 4, 40),('Bob', 11, 85.5),('Cathy', 7, 68.0),('Doug', 9, 60)],dtype=[("name","S10"),("age","int"),("score","float")]) #构造结构化数组print(data["age"]<10)'''输出:array([ True, False, True, True])'''print(data["score"]>60)'''输出:array([False, True, True, False])'''print(data["score"]>=60)'''输出:array([False, True, True, True])'''print(data["score"]<=60)'''输出:array([ True, False, False, True])'''print(data["age"]!=9)'''输出:array([ True, True, True, False])'''print((data["age"]/2)==(np.sqrt(data["age"])))'''输出:array([ True, False, False, False])'''
布尔数组作掩码
一种更加强大的模式是使用布尔数组作为掩码,通过该掩码选择数据的子数据集,实现一些操作:
data=np.array([('Alice', 4, 40), ('Bob', 11, 85.5) ,('Cathy', 7, 68.0),('Doug', 9, 60)],dtype=[("name","S10"),("age","int"),("score","float")])print(data)'''输出:[(b'Alice', 4, 40. )(b'Bob', 11, 85.5)(b'Cathy', 7, 68. )(b'Doug', 9, 60. )]'''print(data["score"]>60) #使用比较运算得的一个布尔数组'''输出:[False True True False]'''print(data[data["score"]>60]) #进行简单的索引,即掩码操作将值为True的选出'''输出:[(b'Bob', 11, 85.5) (b'Cathy', 7, 68. )]'''
布尔逻辑
结合 Python 的逐位逻辑运算符一起使用。逻辑运算符对应 numpy 中的通用函数如下表:
| 逻辑运算符 | 通用函数 |
|---|---|
| & | np.bitwise_and |
| | | np.bitwise_or |
| ^ | np.bitwise_xor |
| ~ | np.bitwise_not |
print(np.count_nonzero(data["age"]<10))#统计数组中True的个数'''输出:3'''#还可以用np.sum(),输出结果和count_nonzero一样,sum()的好处是可以沿着行或列进行求和print(np.sum(data["age"]<10))print(np.any(data["score"]<60))#是否有不及格的'''输出:True'''print(np.all(data["age"]>10))#是否都大于10岁'''输出:False'''print(data[data["age"]>10])#打印年龄大于10的信息'''输出:array([(b'Bob', 11, 85.5)],dtype=[('name', 'S10'), ('age', '<i4'), ('score', '<f8')])'''
编程要求
根据提示,在右侧编辑器 Begin-End 部分补充代码,根据输入的数据筛选出大于 num 的值。
- 具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入: [[ 3 ,15, 9 ,11 , 7],[ 2, 0 , 8, 19 ,16],[ 6 , 6, 16 , 9, 5],[ 7 , 5 , 2 , 6 ,13]] 10
预期输出: [15 11 19 16 16 13]
代码如下:
import numpy as np
def student(num,input_data):
result=[]
# ********* Begin *********#
a=np.array(input_data)
result=a[a > num]
# ********* End *********#
return result
第3关:花式索引与布尔索引
任务描述
本关任务:根据本关所学知识,过滤大写字母。
相关知识
为了完成本关任务,你需要掌握:
- 花式索引;
- 布尔索引。
花式索引
花式索引(Fancy Indexing)是 NumPy 用来描述使用整型数组(这里的数组,可以是 NumPy 的数组,也可以是 python 自带的 list)作为索引的术语,其意义是根据索引数组的值作为目标数组的某个轴的下标来取值。
使用一维整型数组作为索引,如果被索引数组(ndarray)是一维数组,那么索引的结果就是对应位置的元素;如果被索引数组(ndarray)是二维数组,那么就是对应下标的行。如下图所示:
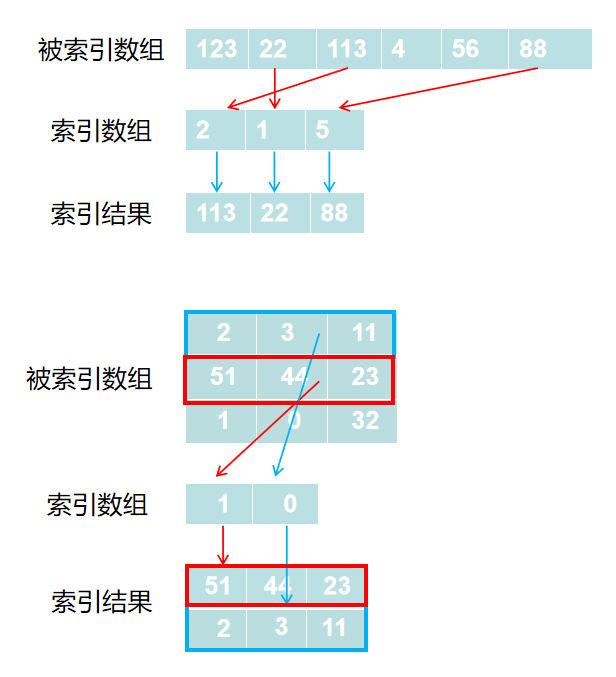
示例代码如下:
import numpy as nparr = np.array(['zero','one','two','three','four'])'''打印arr中索引为1和4的元素结果为:['one', 'four']'''print(arr[[1,4]])arr = np.array([[1, 2, 3], [4, 5, 6], [7, 8, 9]])'''打印arr中索引为1和0的行结果为:[[4, 5, 6],[1, 2, 3]]'''print(arr[[1, 0]])'''打印arr中第2行第1列与第3行第2列的元素结果为:[4, 8]'''print(arr[[1, 2], [0, 1]])
布尔索引
我们可以通过一个布尔数组来索引目标数组,以此找出与布尔数组中值为 True 的对应的目标数组中的数据,从而达到筛选出想要的数据的功能。如下图所示:(PS:需要注意的是,布尔数组的长度必须与被索引数组对应的轴的长度一致)

不过单纯的传入布尔数组进去有点蠢,有没有更加优雅的方式使用布尔索引来达到筛选数据的效果呢?
当然有!我们可以想办法根据我们的需求,构造出布尔数组,然后再通过布尔索引来实现筛选数据的功能。
假设有公司员工绩效指数的数据如下(用一个一维的 ndarray 表示),现在想要把绩效指数大于 3.5 的筛选出来进行股权激励。

那首先就要构造出布尔数组,构造布尔数组很简单,performance > 3.5即可。此时会生成想要的布尔数组。

有了布尔数组就可以使用布尔索引来实现筛选数据的功能了。

示例代码如下:
import numpy as npperformance = np.array([3.25, 3.5, 3.75, 3.5, 3.25, 3.75])'''筛选出绩效高于3.5的数据结果为:[3.75, 3.75]'''print(performance[performance > 3.5])'''筛选出绩效高于3.25并且低于4的数据注意:&表示并且的意思,可以看成是and。&左右两边必须加上()结果为:[3.5 3.75 3.5 3.75]'''print(performance[(performance > 3.25) & (performance < 4)])
编程要求
根据提示,在右侧编辑器 Begin-End 部分补充代码,根据函数参数 input_data 过滤出所有的大写字母。
- 具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入: ["d","a","A","p","b","I","C","K"]
预期输出: ['A' 'I' 'C' 'K']
代码如下:
import numpy as np
def student(input_data):
result=[]
#********* Begin *********#
d=np.array(input_data)
result=d[(d>='A')&(d<='Z')]
# ********* End *********#
return result
第4关:广播机制
任务描述
本关任务:利用广播机制实现 Z-score 标准化。
相关知识
为了完成本关任务,你需要掌握:
- 什么是广播;
- 广播的原则。
什么是广播
两个 ndarray 对象的相加、相减以及相乘都是对应元素之间的操作。
import numpy as npx = np.array([[2,2,3],[1,2,3]])y = np.array([[1,1,3],[2,2,4]])print(x*y)'''输入结果如下:[[ 2 2 9][ 2 4 12]]'''
当两个 ndarray 对象的形状并不相同的时候,我们可以通过扩展数组的方法来实现相加、相减、相乘等操作,这种机制叫做广播(broadcasting)。
比如,一个二维的 ndarray 对象减去列平均值,来对数组的每一列进行取均值化处理:
import numpy as np# arr为4行3列的ndarray对象arr = np.random.randn(4,3)# arr_mean为有3个元素的一维ndarray对象arr_mean = arr.mean(axis=0)# 对arr的每一列进行demeaned = arr - arr_mean
很明显上面代码中的 arr 和 arr_mean 维度并不形同,但是它们可以进行相减操作,这就是通过广播机制来实现的。
广播的原则
广播的原则:如果两个数组的后缘维度(trailing dimension,即从末尾开始算起的维度)的轴长度相符,或其中的一方的长度为1,则认为它们是广播兼容的。广播会在缺失或长度为1的维度上进行,这句话是理解广播的核心。
广播主要发生在两种情况,一种是两个数组的维数不相等,但是它们的后缘维度的轴长相符,另外一种是有一方的长度为1。
我们来看一个例子:
import numpy as nparr1 = np.array([[0, 0, 0],[1, 1, 1],[2, 2, 2], [3, 3, 3]])arr2 = np.array([1, 2, 3])arr_sum = arr1 + arr2print(arr_sum)'''输入结果如下:[[1 2 3][2 3 4][3 4 5][4 5 6]]'''
arr1 的 shape 为(4,3),arr2的 shape 为 (3,)。可以说前者是二维的,而后者是一维的。但是它们的后缘维度相等, arr1 的第二维长度为3 ,和 arr2 的维度相同。
arr1 和 arr2 的 shape 并不一样,但是它们可以执行相加操作,这就是通过广播完成的,在这个例子当中是将 arr2 沿着 0 轴进行扩展。
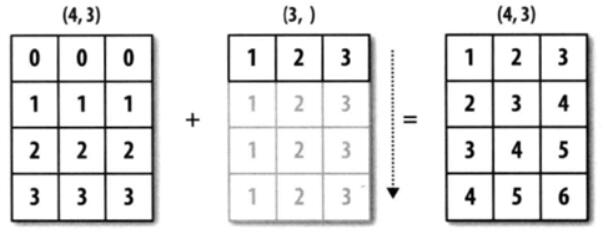
我们再看一个例子:
import numpy as nparr1 = np.array([[0, 0, 0],[1, 1, 1],[2, 2, 2], [3, 3, 3]]) #arr1.shape = (4,3)arr2 = np.array([[1],[2],[3],[4]]) #arr2.shape = (4, 1)arr_sum = arr1 + arr2print(arr_sum)'''输出结果如下:[[1 1 1][3 3 3][5 5 5][7 7 7]]'''
arr1 的 shape 为 (4,3),arr2 的 shape 为 (4,1),它们都是二维的,但是第二个数组在1轴上的长度为 1,所以,可以在 1 轴上面进行广播。
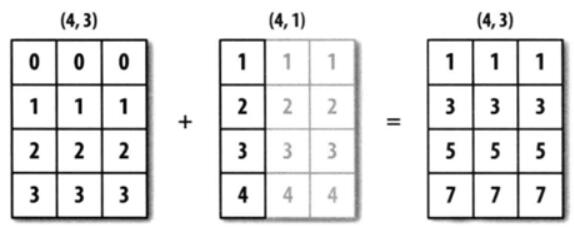
编程要求
根据提示,在右侧编辑器 Begin-End 部分补充代码,将输入数据转换为 array 并计算它们的和。
- 具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
[[9, 3, 1], [7, 0, 6], [4, 6, 3]] [1, 5, 9] [[9], [6], [7]]
预期输出:
[[19 17 19][14 11 21][12 18 19]]
代码如下:
import numpy as np
def student(a,b,c):
result=[]
# ********* Begin *********#
a = np.array(a)
b = np.array(b)
c = np.array(c)
result = a + b + c
# ********* End *********#
return result
第5关:线性代数
任务描述
本关任务:编写一个能求解线性方程的函数。
相关知识
为了完成本关任务,你需要掌握:
numpy的线性代数;- 常用函数。
numpy 的线性代数
线性代数(如矩阵乘法、矩阵分解、行列式以及其他方阵数学等)是任何数组库的重要组成部分,一般我们使用*对两个二维数组相乘得到的是一个元素级的积,而不是一个矩阵点积。因此 numpy 提供了线性代数函数库 linalg ,该库包含了线性代数所需的所有功能。
常用的 numpy.linalg 函数:
| 函数 | 说明 |
|---|---|
| dot | 矩阵乘法 |
| vdot | 两个向量的点积 |
| det | 计算矩阵的行列式 |
| inv | 计算方阵的逆 |
| svd | 计算奇异值分解(SVD) |
| solve | 解线性方程组 Ax=b,A是一个方阵 |
| matmul | 两个数组的矩阵积 |
常用函数
dot():该函数返回俩个数组的点积。对于二维向量,效果等于矩阵乘法;对于一维数组,它是向量的内积;对于N维数组,它是a的最后一个轴上的和与b的倒数第二个轴的乘积。
a=np.array([[1,2],[3,4]])a1=np.array([[5,6],[7,8]])np.dot(a,a1)'''输出:array([[19, 22],[43, 50]])'''
det():该函数用于计算输入矩阵的行列式。
a = np.array([[14, 1], [6, 2]])a=linalg.det(a)print(a)'''输出:21.999999999999996'''
inv():该函数用于计算方阵的逆矩阵。逆矩阵的定义维如果两个方阵 A、B,使得 AB = BA = E,则A称为可逆矩阵,B 为 A 的逆矩阵,E 为单位矩阵。
a=np.array([[1,2],[3,4]])b=linalg.inv(a)print(np.dot(a,b))'''输出:array([[1.0000000e+00, 0.0000000e+00],[8.8817842e-16, 1.0000000e+00]])'''
solve():该函数用于计算线性方程的解。
假设有如下方程组:3x+2y=7 x+4y=14;
写成矩阵的形式:[[3,2][1,4]]*[[x],[y]]=[[7],[14]];
解如上方程组代码如下:
a=np.array([[3,2], [1,4]])b=np.array([[7],[14]])linalg.solve(a,b)'''输出:array([[0. ],[3.5]])最后解出x=0,y=3.5'''
matmul():函数返回两个数组的矩阵乘积。如果参数中有一维数组,则通过在其维度上附加1来提升为矩阵,并在乘法之后去除。
a=[[3,4],[5,6]]b=[[7,8],[9,10]]np.matmul(a,b)'''输出:array([[ 57, 64],[ 89, 100]])'''b=[7,8]np.matmul(a,b)'''输出:array([53, 83])'''
svd():奇异值分解是一种矩阵分解的方法,该函数用来求解 SVD。
a=[[0,1],[1,1],[1,0]]linalg.svd(a)'''输出:(array([[-4.08248290e-01, 7.07106781e-01, 5.77350269e-01],[-8.16496581e-01, 2.64811510e-17, -5.77350269e-01],[-4.08248290e-01, -7.07106781e-01, 5.77350269e-01]]), array([1.73205081, 1. ]), array([[-0.70710678, -0.70710678],[-0.70710678, 0.70710678]]))'''
编程要求
根据提示,在右侧编辑器 Begin-End 部分补充代码,计算性别为男的线性方程解,前两个数为方程左边,最后一个数为方程右边。
- 具体要求请参见后续测试样例。
请先仔细阅读右侧上部代码编辑区内给出的代码框架,再开始你的编程工作!
测试说明
平台会对你编写的代码进行测试,对比你输出的数值与实际正确的数值,只有所有数据全部计算正确才能进入下一关。
测试输入:
[["男",2,4,40],["女",8,3,17],["男",8,6,24]]
预期输出:
[[-7.2][13.6]]
提示:测试数据的方程为 2x+4y=40,8x+6y=24。
代码如下:
from numpy import linalg
import numpy as np
def student(input_data):
result=[]
# ********* Begin *********#
a = np.array(input_data)
x=[]
y=[]
for i in a:
if i[0]=="男":
x.append([int(i[1]),int(i[2])])
y.append([int(i[-1])])
if x==[] and y==[]:
return result
x=np.array(x)
y=np.array(y)
result=linalg.solve(x,y)
# ********* End *********#
return result















 1313
1313

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









