






任务描述
本关任务:根据本关卡所学知识,用
Python实现线性回归常用评估指标,并对构造的线性回归模型进行评估。相关知识
为了完成本关任务,你需要掌握:1.均方误差
(MSE),2.均方根误差(RMSE),3.平均绝对误差(MAE),4.R-Squared。前言
大家知道已经,机器学习通常都是将训练集上的数据对模型进行训练,然后再将测试集上的数据给训练好的模型进行预测,最后根据模型性能的好坏选择模型,对于分类问题,大家很容易想到,可以使用正确率来评估模型的性能,那么回归问题可以使用哪些指标用来评估呢?
MSE
MSE (Mean Squared Error)叫做均方误差,公式如下:m1sumi=1m(yi−pi)2
其中yi表示第
i个样本的真实标签,pi表示模型对第i个样本的预测标签。线性回归的目的就是让损失函数最小。那么模型训练出来了,我们在测试集上用损失函数来评估模型就行了。RMSE
RMSE(Root Mean Squard Error)均方根误差,公式如下:sqrtm1sumi=1m(yi−pi)2
RMSE其实就是MSE开个根号。有什么意义呢?其实实质是一样的。只不过用于数据更好的描述。例如:要做房价预测,每平方是万元,我们预测结果也是万元。那么差值的平方单位应该是千万级别的。那我们不太好描述自己做的模型效果。怎么说呢?我们的模型误差是多少千万?于是干脆就开个根号就好了。我们误差的结果就跟我们数据是一个级别的了,在描述模型的时候就说,我们模型的误差是多少万元。
MAE
MAE(平均绝对误差),公式如下:m1sumi=1m∣yi−pi∣
MAE虽然不作为损失函数,确是一个非常直观的评估指标,它表示每个样本的预测标签值与真实标签值的L1距离。R-Squared
上面的几种衡量标准针对不同的模型会有不同的值。比如说预测房价 那么误差单位就是万元。数子可能是
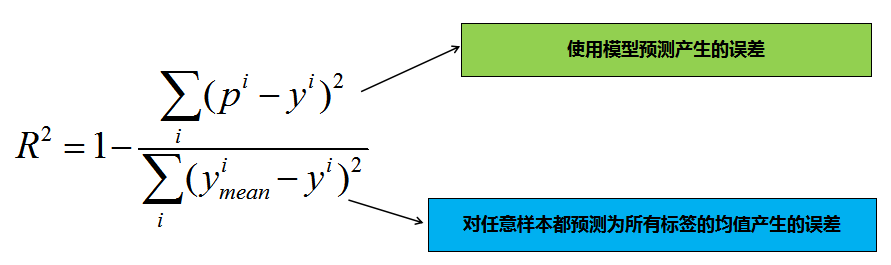
3,4,5之类的。那么预测身高就可能是0.1,0.6之类的。没有什么可读性,到底多少才算好呢?不知道,那要根据模型的应用场景来。 看看分类算法的衡量标准就是正确率,而正确率又在0~1之间,最高百分之百。最低0。如果是负数,则考虑非线性相关。很直观,而且不同模型一样的。那么线性回归有没有这样的衡量标准呢?R-Squared就是这么一个指标,公式如下:R2=1−sumi(ymeani−yi)2sumi(pi−yi)2
其中ymean表示所有测试样本标签值的均值。为什么这个指标会有刚刚我们提到的性能呢?我们分析下公式:
其实分子表示的是模型预测时产生的误差,分母表示的是对任意样本都预测为所有标签均值时产生的误差,由此可知:
R2leq1,当我们的模型不犯任何错误时,取最大值
1;当我们的模型性能跟基模型性能相同时,取
0;如果为负数,则说明我们训练出来的模型还不如基准模型,此时,很有可能我们的数据不存在任何线性关系。
编程要求
根据提示,在右侧编辑器
Begin-End处补充代码,用Python实现R-Squared指标,并用实现的R-Squared指标来评估上一关的线性回归模型。函数说明
- numpy方法:
numpy.mean(array, axis) 指定轴上数组元素计算算术平均数。
numpy.mean([ [1,2,3],[4,5,6],[7,8,9]],axis=0)[4. 5. 6.]numpy.var(array, axis) 指定轴上数组元素计算方差。
numpy.var([ [1,2,3],[4,5,6],[7,8,9]],axis=0)[6. 6. 6.]numpy.ones(shape) 返回一个包含给定形状和数据类型的新数组。
numpy.ones([3, 3])[[1. 1. 1.][1. 1. 1.][1. 1. 1.]]numpy.hstack((a, b)) 按水平方向(列顺序)堆叠数组构成一个新的数组。
numpy.hstack(([1,2,3],[4,5,6]))[1 2 3 4 5 6]numpy.vstack((a, b)) 按垂直方向(行顺序)堆叠数组构成一个新的数组。
numpy.vstack(([1,2,3],[4,5,6]))[[1 2 3][4 5 6]]- numpy线性代数方法:
numpy.linalg.inv(m) 返回 m 的逆矩阵
numpy.linalg.inv([[2,5],[1,3]])[[ 3. -5.][-1. 2.]]numpy.dot(m1, m2) 矩阵 m1 与矩阵 m2 点乘。
numpy.dot([[2,5],[1,3]], [[3,-5],[-1,2]])[[1 0][0 1]]m.T 矩阵 m 的转置矩阵。
m = np.array([[2,5],[1,3]])m.T[[2 1][5 3]]测试说明
只需返回预测结果即可,程序内部会检测您的代码,
R-Squared指标高于0.6视为过关。#encoding=utf8 import numpy as np #mse def mse_score(y_predict,y_test): mse = np.mean((y_predict-y_test)**2) return mse #r2 def r2_score(y_predict,y_test): ''' input:y_predict(ndarray):预测值 y_test(ndarray):真实值 output:r2(float):r2值 ''' #********* Begin *********# r2 =1-mse_score(y_predict,y_test)/np.var(y_test) #********* End *********# return r2 class LinearRegression : def __init__(self): '''初始化线性回归模型''' self.theta = None def fit_normal(self,train_data,train_label): ''' input:train_data(ndarray):训练样本 train_label(ndarray):训练标签 ''' #********* Begin *********# x = np.hstack([np.ones((len(train_data),1)),train_data]) self.theta =np.linalg.inv(x.T.dot(x)).dot(x.T).dot(train_label) #********* End *********# return self def predict(self,test_data): ''' input:test_data(ndarray):测试样本 ''' #********* Begin *********# x = np.hstack([np.ones((len(test_data),1)),test_data]) return x.dot(self.theta) #********* End *********#















12-05
 1480
1480
1480

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









