







结构体内存对齐规则
1.第一个成员在与结构体变量偏移量为0的地址处。
2.第一个成员之后的其他成员要对齐到某个数字(对齐数)的整数倍的地址处
对齐数 = 编译器默认的对齐数与成员自身大小的较小值
3.结构体总大小是最大对齐数的整数倍(结构体每一个成员都有对齐数)
4.如果结构体嵌套类结构体的情况,嵌套的结构体对齐到自己最大对齐数的整数倍处,结构体的总大小就是所有对齐数里面最大对齐数的整数倍
int a;
对齐数 = min(sizeof(a),默认对齐数);
vs编译器默认对齐数是8 gcc没有规定默认的对齐数
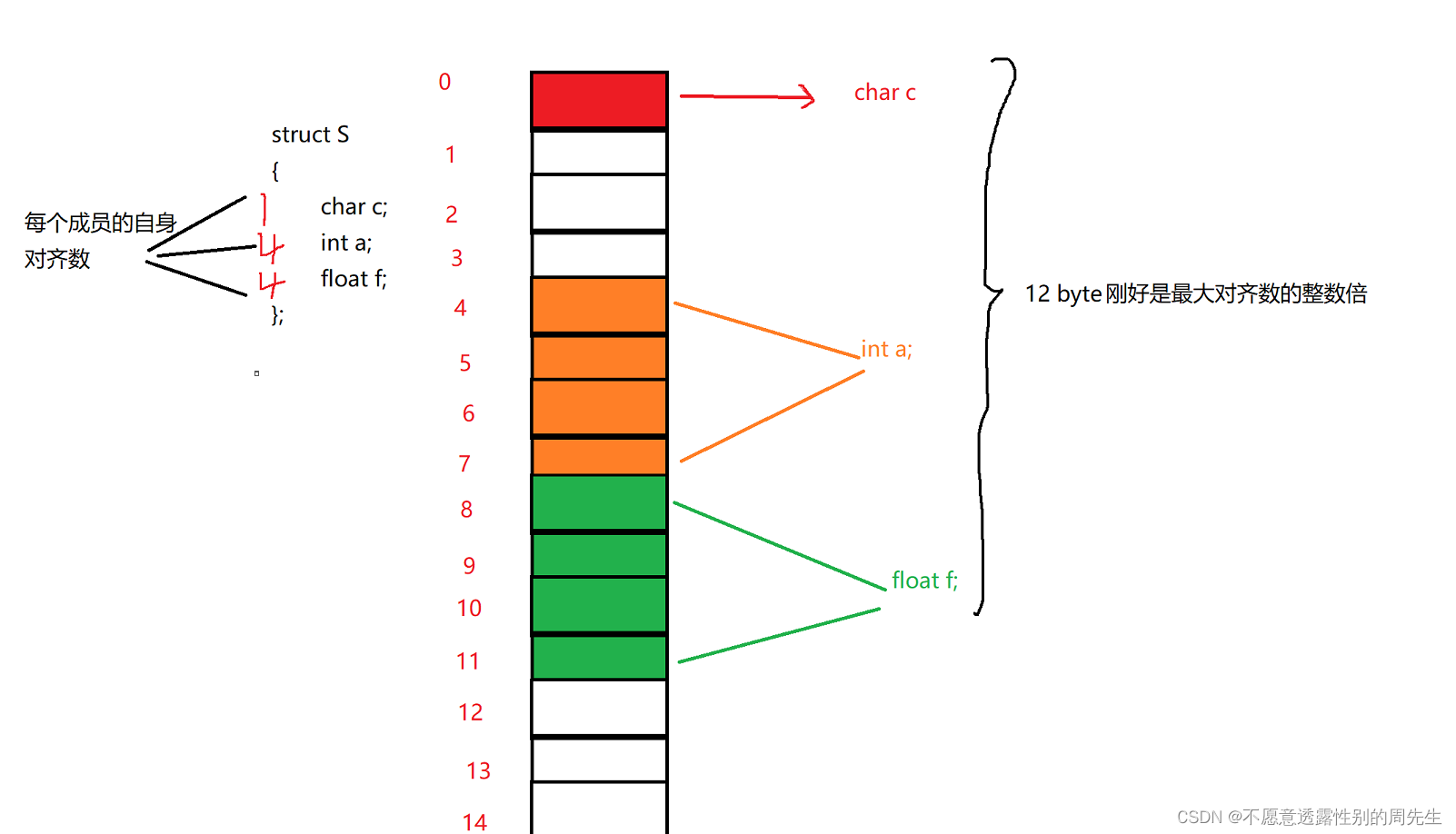
实例分析
struct S
{
char c;
int a;
float f;
};

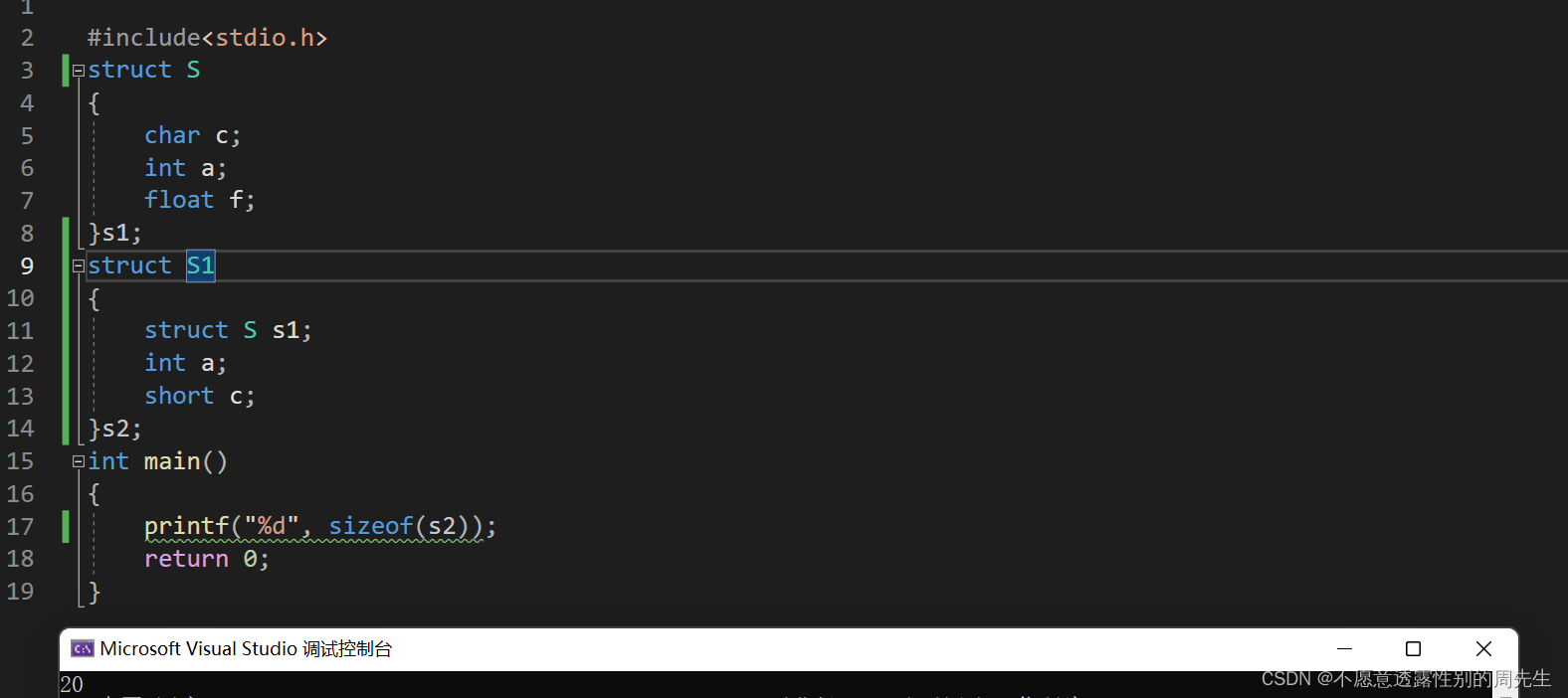
实例分析结构体嵌套

当不进行内存对齐时对变量进行访问
我们知道计算机中内存是以字节为单位划分的,CPU通过地址总线来访问内存,CPU一个时钟周期内能处理多少字节的数据,就命令地址总线读取几个字节的数据
举个例子:32位的CPU,一次能处理32bit的数据,也就是4字节的数据,那么CPU就命令地址总线一次性读取4字节的数据,即每次的步长都为4字节,只对地址是4的整倍数的地址进行寻址,比如:0,4,8,100等进行寻址。
对于程序来说,一个变量的地址最好刚在一个寻址步长内,这样一次寻址就可以读取到该变量的值,如果变量跨步长存储,就需要寻址两次甚至多次然后再进行拼接才能获取到变量的值,效率明显就低了,所以编译器会进行内存对齐,以保证寻址效率
如果不采用内存对齐
struct S
{
char c;
int a;
}s1;
上述代码中成员在内存中的分布
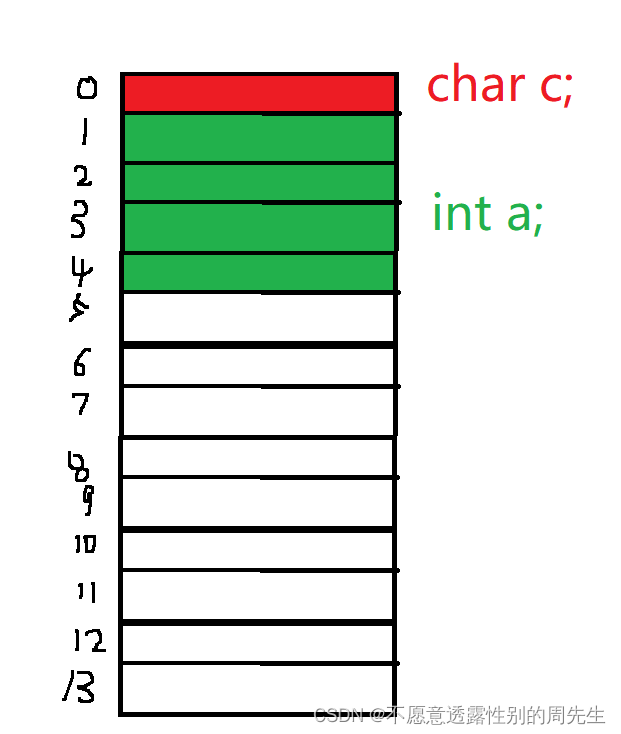
一次读取4字节,那么int类型的变量a需要读取两次,并且需要进行拼接后才可以取出变量a的数据
如果采用内存对齐
上述代码中成员在内存中的存储
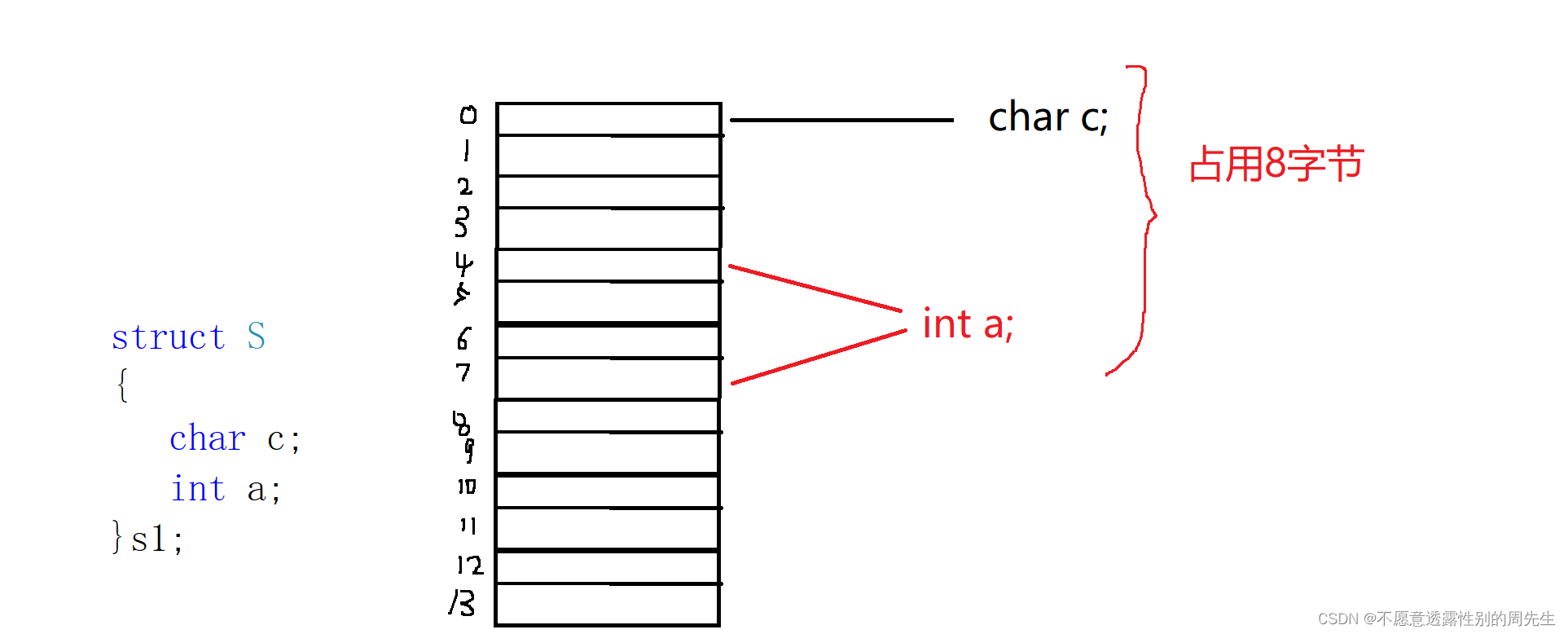
一次读取四个字节,int类型的变量a的地址刚好对齐数的整数倍处,所以读取数据的时候大大降低了消耗
内存对齐的原因
1.平台原因:
不是所有的硬件平台都能访问任意地址上的任意数据的;某些硬件平台只能在某些地址处取某些特定类型的数据,否则抛出硬件异常。
2. 性能原因 :
数据结构(尤其是栈)应该尽可能地在自然边界上对齐。原因在于,为了访问未对齐的内存,处理器需要作两次内存访问;而对齐的内存访问仅需要一次访问。这里归根结底的来说就是以空间换时间。














 766
766











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









