






Hive官网介绍
文档
数据库操作
其他文档
官方文档
hive文档: https://cwiki.apache.org/confluence/display/Hive/Configuration+Properties
Hadoop官网使用说明文档: https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/MapReduceTutorial.html
hdfs文档: https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-hdfs/hdfs-default.xml
yarn文档: https://hadoop.apache.org/docs/stable/hadoop-yarn/hadoop-yarn-common/yarn-default.xml
mr文档: https://hadoop.apache.org/docs/stable/hadoop-mapreduce-client/hadoop-mapreduce-client-core/mapred-default.xml
Hive数据库操作
1、基本操作
知识点:
创建数据库: create database [if not exists] 库名 [location '路径']; 使用数据库: use 库名; 注意: location路径默认是: 删除数据库: drop database 数据库名 [cascade];
示例:
-- Hive的数据库核心操作 -- 创建Hive数据库 -- if not exists:如果不存在,就创建;如果存在,不会有任何的变化 -- 数据库默认放在/user/hive/warehouse HDFS目录中 create database if not exists hive1; create database test; -- 创建数据库的时候可以手动指定数据库存放的路径 -- location指定的是HDFS路径 create database test1 location '/test1'; -- 在数据库中创建表 -- 需要先指定数据库 use hive1; -- 建表 -- 建表实际上就是在HDFS的数据库目录下创建一个与表名同名的文件夹 create table stu(id int,name varchar(100)); -- 通过 数据库名称.表名称 也可以创建表 create table test1.stu(id int,name varchar(100)); -- 删除数据库 drop database test1; -- 强制删除非空的数据库 -- 删除数据库的时候,同时会将HDFS上面的数据库目录删除 drop database test1 cascade; -- 查看建库的语句 show create database hive1; -- 查看所有数据库 show databases; -- 查看目前正在使用的数据库 select current_database(); -- 查看指定数据库的基本信息。desc是describe单词缩写 desc database hive1;
删除数据库可能遇到的错误:
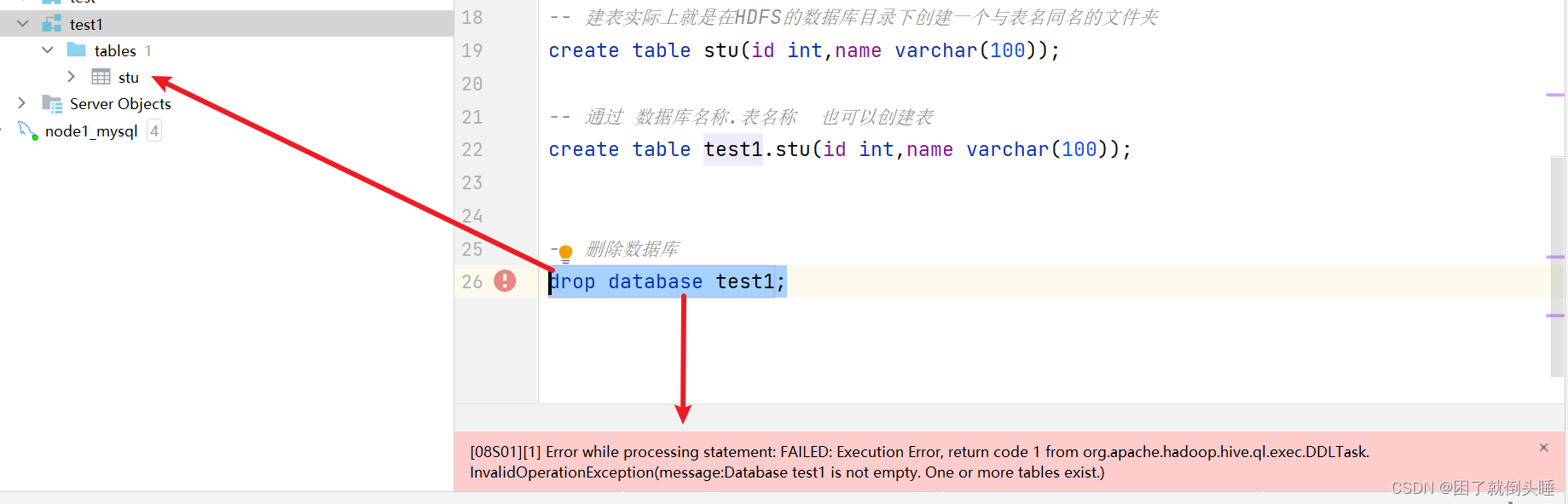
原因: 在Hive中删除数据库的时候,需要确保数据库下面没有其他的内容,否则会报错
解决办法:
1- (不推荐)先手动删除数据库中的内容,然后再删除
2- 使用cascade进行强制删除
2、其他操作
创建数据库: create database [if not exists] 库名 [comment '注释'] [location '路径'] [with dbproperties ('k'='v')];
修改数据库路径: alter database 库名 set location 'hdfs://node1.itcast.cn:8020/路径'
修改数据库属性: alter database 库名 set dbproperties ('k'='v');
查看所有的数据库: show databases;
查看某库建库语句: show create database 库名;
查看指定数据库信息: desc database 库名;
查看指定数据库扩展信息: desc database extended 库名;
查看当前使用的数据库: select current_database();
示例:
-- Hive数据库的其他操作
-- 1- 创建数据库database,也可以使用schema进行创建数据库
create schema demo1;
-- 2- 创建数据库指定其他的信息。推荐将数据库默认就放在/user/hive/warehouse路径
create database demo2
comment "这是一个数据库"
location "/user/hive/warehouse/demo2.db"
with dbproperties ('name'='my name is demo2');
create database demo3
comment "it is database"
location "/user/hive/warehouse/demo3.db"
with dbproperties ('name'='my name is demo3');
-- 3- 查看建库的语句
show create database demo3;
-- 4- 查看所有数据库
show databases;
-- 5- 查看目前正在使用的数据库
select current_database();
-- 6- 查看指定数据库的基本信息。desc是describe单词缩写
desc database demo3;
-- describe database demo3;
-- 7- 查看指定数据库的扩展信息
desc database extended demo3;
-- 8- 修改数据库中数据存放的路径
-- 注意:location中的路径必须要写HDFS完整路径
-- 注意:如果修改了数据库的路径,那么只有在数据库下面创建表的时候,它才会给你创建数据库目录
-- 注释的快捷键:ctrl+/
-- 复制的快捷键:ctrl+D
-- alter database demo3 set location '/dir/demo3';
alter database demo3 set location 'hdfs://node1:8020/dir/demo3';
-- 注意:如果修改了数据库的路径,那么只有在数据库下面创建表的时候,它才会给你创建数据库目录
create table demo3.stu(id int,name varchar(100));
alter database demo3 set dbproperties ('name'='my name is demo33333');
desc database extended demo3;
修改数据库的location可能遇到的错误:
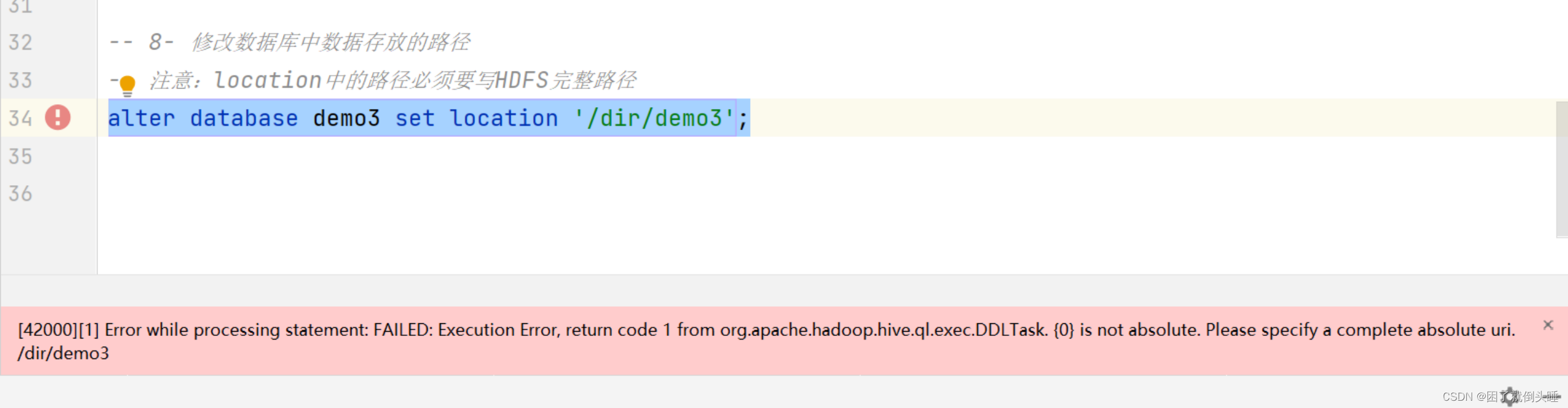
原因: location中的路径必须要写HDFS完整路径
















 1039
1039











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











