






0、函数回顾
==函数: 提前组织好的,可以重复使用的,具有特定功能的代码段==
通用定义格式:
def 函数名(形式参数):
函数体
return 返回值
通用调用格式:
变量接收返回值 = 函数名(实际参数)
lambda匿名函数:
格式: lambada 形式参数 : 函数体
注意: 函数体有且只有一行代码
1、读写HDFS
环境准备: 1- 启动Hadoop集群 start-all.sh 2- 验证Hadoop集群是否运行正常 jps 访问 http://node1:9870 http://node1:8088 3- 上传文件到HDFS 准备一个content.txt文件,内容如下 hello hello spark hello heima spark 接着将content.txt文件上传到hdfs hdfs dfs -mkdir /input hdfs dfs -put content.txt /input/ 4- 基于原生入门案例,修改文件路径为 hdfs://node1:8020/...
代码:
# 导包
import os
import time
from pyspark import SparkConf, SparkContext
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
print("Spark加强案例: 从hdfs中读取文件进行WordCount词频统计开始~")
# - 1.创建SparkContext对象
conf = SparkConf().setAppName('my_pyspark_demo').setMaster('local[*]')
sc = SparkContext(conf=conf)
print(sc) # 默认<SparkContext master=local[*] appName=pyspark-shell>
# - 2.数据输入
# 注意: 默认是linux本地路径省略了file:/// 如果是hdfs路径必须加hdfs://node1:8020/
# 注意: 需要修改为hdfs路径
init_rdd = sc.textFile('hdfs://node1:8020/input/content.txt')
# - 3.数据处理
# - 3.1文本内容切分
flatmap_rdd = init_rdd.flatMap(lambda line: line.split(' '))
# - 3.2数据格式转换
map_rdd = flatmap_rdd.map(lambda word: (word, 1))
# - 3.3分组和聚合
reduce_rdd = map_rdd.reduceByKey(lambda agg, curr: agg + curr)
# - 4.数据输出
# 注意: 此时结果也需要利用算子存储到hdfs中
reduce_rdd.saveAsTextFile('hdfs://node1:8020/day02_output')
# - 5.释放资源
time.sleep(100)
sc.stop()
print("Spark加强案例: WordCount词频统计结果已经保存到hdfs,程序结束~")
可能报的错误:

原因: 输出路径已经存在
解决: 直接删除已经存在的路径即可
该错误需要查看Hadoop的源代码(131行):https://gitee.com/highmoutain/hadoop/blob/trunk/hadoop-mapreduce-project/hadoop-mapreduce-client/hadoop-mapreduce-client-core/src/main/java/org/apache/hadoop/mapred/FileOutputFormat.java
2、链式编程
链式编程: 就是一种代码简洁的写法。省略中间变量的声明,调用完一个算子后,继续调用其他算子 使用场景:当功能需求比较简单(代码比较少)的时候,推荐使用链式编程,可以让你的代码看起来更加简洁。另外,算子返回值类型都是相同的时候才能够使用
# 导包
import os
from pyspark import SparkConf, SparkContext
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
# 创建main函数
if __name__ == '__main__':
print("Spark加强案例: 从hdfs中读取文件进行WordCount词频统计开始~")
# - 1.创建SparkContext对象
conf = SparkConf().setAppName('my_pyspark_demo').setMaster('local[*]')
sc = SparkContext(conf=conf)
print(sc) # 默认<SparkContext master=local[*] appName=pyspark-shell>
# - 2.数据输入_处理_输出
result = sc.textFile('hdfs://node1:8020/input/content.txt') \
.flatMap(lambda line: line.split(' ')) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda agg, curr: agg + curr)
print(result.collect())
# - 3.释放资源
sc.stop()
print("Spark加强案例:程序结束~")
3、对结果排序
sortBy(参数1,参数2):
参数1: 自定义函数,通过函数指定按照谁来进行排序操作
参数2: (可选)boolean类型,表示是否为升序。默认为True,表示升序
sortByKey(参数1):
参数1: 可选的,boolean类型,表示是否为升序。默认为True 表示升序
top(N,函数):
参数N: 取RDD的前N个元素
参数函数:(可选)如果kv(键值对)类型,默认是根据key进行排序操作,如果想根据其他排序,可以定义函数指定
# 导包
from pyspark import SparkContext
import os
# 绑定指定的python解释器
os.environ['SPARK_HOME'] = '/export/server/spark'
os.environ['PYSPARK_PYTHON'] = '/root/anaconda3/bin/python3'
os.environ['PYSPARK_DRIVER_PYTHON'] = '/root/anaconda3/bin/python3'
if __name__ == '__main__':
# - 1.创建SparkContext对象
sc = SparkContext() # 默认master=local[*],默认appname=pyspark-shell
print(sc)
# - 2.数据输入
# - 3.数据处理
reduceRDD = sc.textFile('file:///export/data/spark_project/spark_base/content.txt') \
.flatMap(lambda line: line.split(" ")) \
.map(lambda word: (word, 1)) \
.reduceByKey(lambda agg, curr: agg + curr)
# - 4.数据输出
# 排序操作
# ①sortBy 默认升序
s1 = reduceRDD.sortBy(lambda tup: tup[1], False)
print(s1.collect())
# ②sortByKey 默认升序 (key,value)
s2 = reduceRDD.sortByKey(False)
print(s2.collect())
# 思考: sortByKey 能不能根据value值降序排序
s2 = reduceRDD.map(lambda tup:(tup[1],tup[0])).sortByKey(False).map(lambda tup:(tup[1],tup[0]))
print(s2.collect())
# ③top 默认降序
s3 = reduceRDD.top(4, lambda tup: tup[1])
print(s3)
# 思考: top能不能拿最小n个value值
# 排序规则可以利用负数概念,-1>-2>-3,注意:不能修改数据本身
s4 = reduceRDD.top(4, lambda tup: -tup[1])
print(s4)
# - 5.释放资源
sc.stop()
4、案例相关算子小结
读取文件:
textFile(path): 读取外部数据源,支持本地文件系统和HDFS文件系统
将结果数据输出文件上:
saveAsTextFile(path): 将数据输出到外部存储系统,支持本地文件系统和HDFS文件系统
文件路径协议:
本地: file:///路径
hdfs: hdfs://node1:8020/路径
排序相关的API:
sortBy(参数1,参数2):
参数1: 自定义函数,通过函数指定按照谁来进行排序操作
参数2: 可选的,boolean类型,表示是否为升序。默认为True,表示升序
sortByKey(参数1):
参数1: 可选的,boolean类型,表示是否为升序。默认为True 表示升序
top(N,函数):
参数N: 取RDD的前N个元素
参数函数: 可选的。如果kv(键值对)类型,默认是根据key进行排序操作,如果想根据其他排序,可以定义函数指定
相关其他API/算子:
flatMap(函数): 根据指定的函数对元素进行转换操作,支持将一个元素转换为多个元素
map(函数): 根据指定的函数对元素进行转换操作,支持一对一的转换操作,传入一个返回一个
reduceByKey(函数): 根据key进行分组操作,将同一分组内的value数据合并为一个列表,然后执行传入的函数。函数传入的参数有两个,参数1表示的是局部聚合结果,默认值是列表中的第一个元素;参数2表示遍历的每一个列表中value值,默认从第二开始
collect(): 收集,将程序中全部的结果数据收集回来,形成一个列表返回
百度统计中实际应用:
5、PySpark的异常排查流程

排错步骤: 1- 查看【真正的错误原因】,理解报错的含义 2- 查看【Python的错误堆栈】,找到具体报错的地方。再结合错误原因,进行分析,得到解决办法
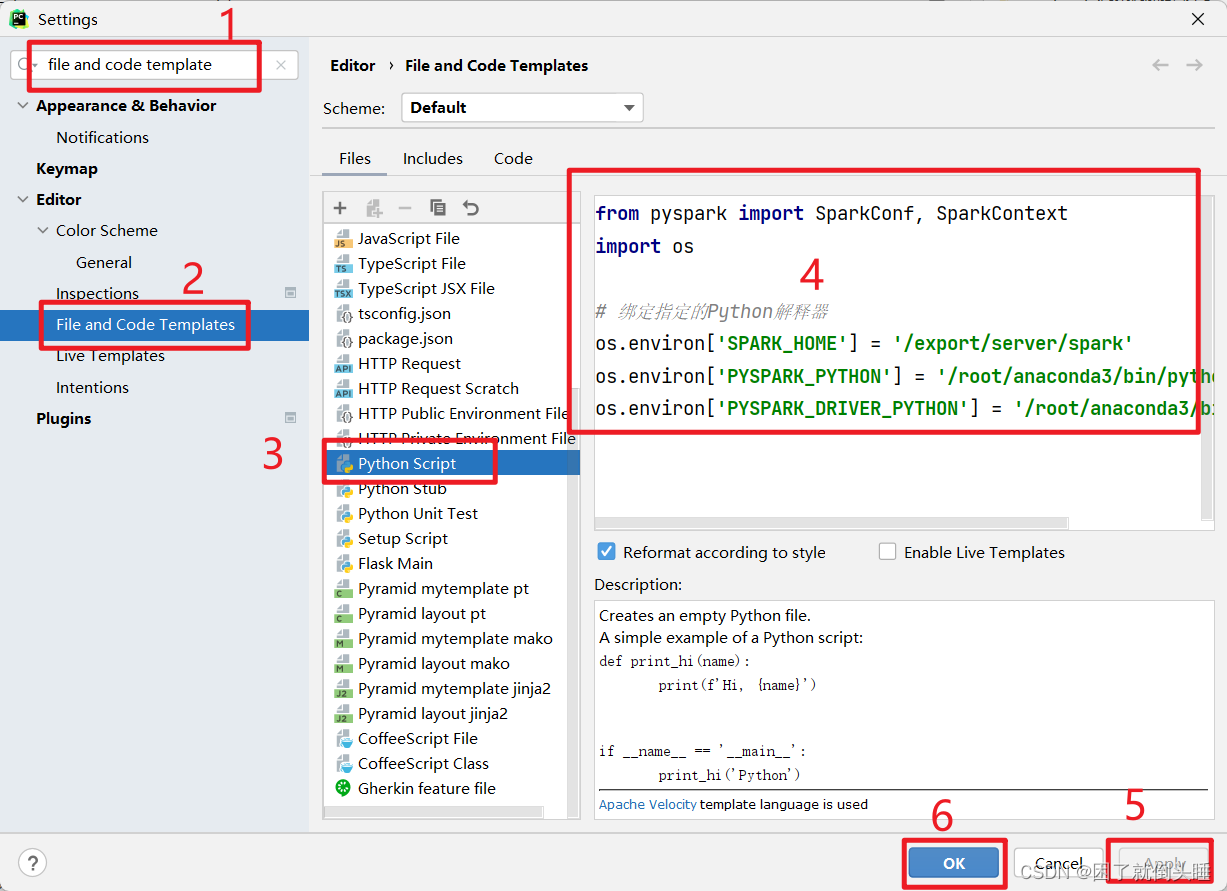
6、代码模板设置

















 3067
3067











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











