







 本文介绍了KMP算法,一种用于在文本串中高效查找模式串的匹配方法,通过next数组利用已匹配信息避免回溯,提高匹配效率。重点讲解了next数组的计算和在字符串匹配中的应用。
本文介绍了KMP算法,一种用于在文本串中高效查找模式串的匹配方法,通过next数组利用已匹配信息避免回溯,提高匹配效率。重点讲解了next数组的计算和在字符串匹配中的应用。
在看过文章 从头到尾彻底理解KMP(2014年8月22日版)_kmp算法 csdn-CSDN博客 后,对文章尝试加入自己的理解,仅作我个人学习记录,详细可以看这位博主的文章。
引言
给出两个字符串,分别是文本串(主串)s和模式串(字串)p,查找模式串p在文本串s中出现的位置。
模式串:一段字符串,实际场景中远短于主串 。
对于这个问题,会很自然地想到用 朴素匹配法 来解决(我自己今天解题的时候也是第一时间用了这种方法),很多讲解KMP算法的文章都是从这个办法讲起:
假设现在文本串s匹配到 i 位置,模式串p匹配到 j 位置
·如果位置i和位置j的字符匹配成功(s[i] == p[j]),则 i++,j++,继续匹配
·如果位置i和位置j的字符匹配失败(s[i] != p[j]),则令 i = i - (j - 1),j = 0。即 i 回溯,j 置0
操作如下:
后面以此类推
图片来源:从头到尾彻底理解KMP(2014年8月22日版)_kmp算法 csdn-CSDN博客
详细代码看来源文章。






这个方法无法利用之前已经部分匹配的有效信息,花费时间会相对更多,因此Knuth,Morris和Pratt三位前辈发表了KMP算法来解决这类问题。
KMP算法
假设现在文本串s匹配到 i 位置,模式串p匹配到 j 位置
·如果j == -1,或位置i和位置j的字符匹配成功(s[i] == p[j]),则 i++,j++,继续匹配
·如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]。
当匹配失败时,模式串向右移动的位数为:失配字符所在位置 - 失配字符对应的next 值,即移动的实际位数为:j - next[j],且此值大于等于1。
next 数组各值的含义:代表当前字符之前的字符串中,有多大长度的相同前缀后缀。例如,如果next [j] = k,代表j 之前的字符串中有最大长度为k 的相同前缀后缀。(这个一定要记住,后面有一些地方的理解还要结合这个)
next的值告诉了下一步的匹配,模式串p应该跳到next[j]的位置。
如果next [j] 等于0或-1,则跳到模式串的开头字符,若next [j] = k 且 k > 0,代表下次匹配跳到j 之前的某个字符,而不是跳到开头,且具体跳过了k 个字符。
代码:
(来源:从头到尾彻底理解KMP(2014年8月22日版)_kmp算法 csdn-CSDN博客)
int KmpSearch(char* s, char* p)
{
int i = 0;
int j = 0;
int sLen = strlen(s);
int pLen = strlen(p);
while (i < sLen && j < pLen)
{
//①如果j = -1,或者当前字符匹配成功(即S[i] == P[j]),都令i++,j++
if (j == -1 || s[i] == p[j])
{
i++;
j++;
}
else
{
//②如果j != -1,且当前字符匹配失败(即S[i] != P[j]),则令 i 不变,j = next[j]
//next[j]即为j所对应的next值
j = next[j];
}
}
if (j == pLen)
return i - j;
else
return -1;
} next数组
字符串前缀:不包含最后一个字符的所有以第一个字符(索引为0)开头的连续子串
字符串后缀:不包含第一个字符的所有以最后一个字符结尾的连续子串
公共前后缀:一个字符串的 所有前缀连续子串 和 所有后缀连续子串 中相等的子串
最长公共前后缀:所有公共前后缀的长度最长的子串
字符串ABABA
字符串前缀:A,AB,ABA,ABAB
字符串后缀:BABA,ABA,BA,A
公共前后缀:A,ABA
最长公共前后缀:ABA
在求解next数组之前,要寻找前缀后缀最长公共元素长度。
假定p[k]为前缀字符,p[j]为后缀字符。
对于p=p[0]p[1]p[2]p[3]...p[j-1]p[j],如果存在p[0]p[1]...p[k-1]p[k]=p[j-k]p[j-k+1]...
p[j-1]p[j](即前缀字符串等于后缀字符串),那么在包含 p[j] 的模式串中有最大长度为 k+1 的相同前缀后缀(前缀字符串pk的长度为k+1)。
假设给定字符串ABAB。
A:无前缀后缀,因此最大前后缀公共元素长度为0;
AB:前缀为A,后缀为B,无前后缀公共元素,因此最大前后缀公共元素长度为0;
ABA:前缀为A,AB,后缀为BA,A,前后缀最长公共元素为A,因此最大前后缀公共元素长度为1;
ABAB:前缀为A,AB,ABA,后缀为BAB,AB,B,前后缀最长公共元素为AB,因此最大前后缀公共元素长度为2。
各个子串的前缀后缀的公共元素的最大长度如下表格所示:
模式串p A B A B 最大前后缀公共元素长度 0 0 1 2
知道了如何寻找前缀后缀最长公共元素长度,只需要将求得的 前缀后缀最长公共元素长度 整体右移一位,然后初值赋为-1,即可求得next数组的值。
| 模式串p | A | B | A | B |
| next数组的值 | -1 | 0 | 0 | 1 |
比如对于aba来说,第3个字符a之前的字符串ab中有长度为0的相同前缀后缀,所以第3个字符a对应的next值为0;而对于abab来说,第4个字符b之前的字符串aba中有长度为1的相同前缀后缀a,所以第4个字符b对应的next值为1。
求得next数组的值后,可以用next数组对文本串s和模式串p进行匹配。
当模式串的后缀p[j-k] p[j-k+1] ...,p[j-1] 跟文本串s[i-k]s[i-k+1]...s[i-1] 匹配成功,但p[j] 跟s[i]匹配失败时,因为next[j] = k,相当于在不包含 p[j] 的模式串中有最大长度为k 的相同前缀后缀,即p[0]p[1]...p[k-1] = p[j-k]p[j-k+1]...p[j-1],故令j = next[j],从而让模式串右移j - next[j] 位,使得模式串的前缀p[0]p[1] ...p[k-1]对应着文本串 s[i-k]s[i-k+1] ...s[i-1],而后让 p[k] 跟s[i] 继续匹配。
来源:从头到尾彻底理解KMP(2014年8月22日版)_kmp算法 csdn-CSDN博客
理解:当p[j]和s[i]匹配失败时,因为字符p[j-k]到p[j-1]的长度为k,根据next数组各值的含义可以推出,next[j]=k(next[j] 表示 p[j] 字符代表的next值)。j = next[j] 就是让模式串 p 的标记 j 回溯到p[k]的位置。在我们的图画上就是模式串p向右移动了 j - next[j] 个长度,在代码执行上就是回到p[k],让p[k]和s[i]进行匹配,如果失败,继续上述操作,如果成功,进行下一个匹配。
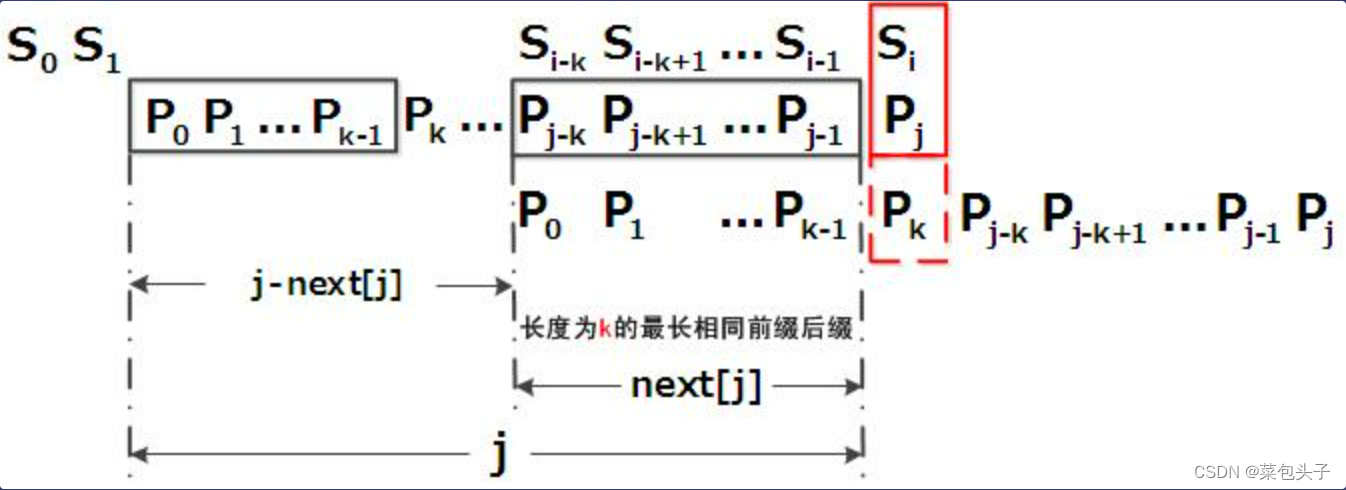
文章 从头到尾彻底理解KMP(2014年8月22日版)_kmp算法 csdn-CSDN博客 抛出结论:
根据《最大长度表》,失配时,模式串向右移动的位数 = 已经匹配的字符数 - 失配字符的上一位字符的最大长度值
根据《next 数组》,失配时,模式串向右移动的位数 = 失配字符的位置 - 失配字符对应的next 值
无论是基于《最大长度表》的匹配,还是基于next 数组的匹配,两者得出来的向右移动的位数是一样的。
原因:已经匹配的字符数不计入0,且记入失配字符位置;失配字符的位置计入0,且不计入失配字符的位置;根据next数组的值得出的方法,显然失配字符的上一位字符的最大长度值=失配字符对应的next 值。
如果已经知道了 next[j] 的值,如何求出 next[j+1]?
如果p[k] == p[j],显然 next[j+1] = next[j]+1 = k+1;
解释:因为p[k]和p[j]字符相同,则模式串p的公共前后缀长度会加1,则next[j+1]会在next[j]的基础上加1。
若p[k ] != p[j]
如果此时p[ next[k] ] == p[j],则next[ j + 1 ] = next[k] + 1,否则继续递归前缀索引k = next[k],而后重复此过程。
解释:在看过 p[next[k]]的含义 后,不难看出,因为p[ next[k] ] == p[j],而next[k]表示p[k]前有next[k]个长度的公共前后缀元素,算上p[ next[k] ] == p[j]这个前后缀元素,则next[ j + 1 ] = next[k] + 1。结果是next[k]+1的原因很简单,next[k]是p[k]在,模式串p的位置,也表示了p[k]前有多少个字符长度,因此可以表示公共前后缀长度。
从头到尾彻底理解KMP(2014年8月22日版)_kmp算法 csdn-CSDN博客 中也有相应的解释,不懂的话看这篇文章。
p[next[k]]的含义:next[k]是p[k]对应的next值,表示p[k]前面的字符串有next[k]个长度的公共前后缀元素,因此p[next[k]]是公共前后缀在p的前缀的最后一个位置。以字符串ABABA为例,如果k=3,j=4,则next[k]=1,next[j]=2,由于p[k] != p[j],需要查看p[k]的next[k]值并让k回溯到p[next[k]],这个p[next[k]]就是字符串ABABA的第二个元素'B'。
如果要理解为什么递归前缀索引k = next[k],就找到长度更短的相同前缀后缀,必须理解公共前后缀是如何的出来的,还有理解next数组各值的含义。由于我个人的理解比较难用语言描述出来(主要是懒了),如果还无法理解可以尝试看看(算法)通俗易懂的字符串匹配KMP算法及求next值算法_kmp算法next计算方法-CSDN博客 。其实还有一篇的,但当时用的是手机浏览器,不知道为什么PC浏览器没找到。
总结
昨天写题的时候偶尔看见一种解法使用KMP算法,从昨天开始啃到现在写完这篇文章花了六个多小时,我已经把我现阶段能理解的且最主要的内容记在上面了。难点还是字符串的匹配机制,理解了如何匹配就很流畅了,重点还是要看懂next值的含义。
到这里KMP算法大致就结束了,如果要对字符串查找算法更深入了解,照样推荐去看文章 从头到尾彻底理解KMP(2014年8月22日版)_kmp算法 csdn-CSDN博客 。















 1465
1465

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









