







 本文介绍了如何在麻将机中实现高效、公平的洗牌,通过应用Knuth算法,简化了原本不可能的任务,让每个麻将牌等概率出现在序列的每个位置,减少内存消耗。
本文介绍了如何在麻将机中实现高效、公平的洗牌,通过应用Knuth算法,简化了原本不可能的任务,让每个麻将牌等概率出现在序列的每个位置,减少内存消耗。
PART1——引言
桌游有很多,有三国杀、UNO、斗地主、狼人杀、谁是卧底等等。这类游戏大多的玩法大多建立在纸质/塑料堆的基础上,因此我们需要至少一个人对这堆东西进行”洗牌“。卡牌很轻便,一个人可以很轻松且快速地洗牌,并且保证洗出来的牌公平。
但是如果我玩的是麻将呢?对麻将稍微熟悉的小伙伴都知道,麻将对比卡牌来说重太多了,加上麻将数量至少有136张之多,一般麻将都是四个人一起洗牌的。不过好在现在有麻将机可以代替人洗牌,一下子就省事了很多。
但是,我们如何保证让麻将机公平洗牌呢?最直接的一种办法就是列出麻将牌所有的排列可能性,然后随机抽出种可能。但对于麻将牌来说,排列的情况一共至少有136!(即3.6590429e+232)那么多!!!这样的数字简直是天文数字,可能一局玩下来,上一局的牌还没洗完。虽然排列的可能性为常量,但这对麻将机有136!-1个排列是浪费的(因为我们最后只取136!中的一个可能),对麻将机的内存也是极大的浪费。
因此”列出麻将牌所有的排列可能性,然后随机抽出种可能“的做法是不现实的,那么我们就需要寻找一个更优的方法提高时间效率和节省空间容量。
对于“列出麻将牌所有的排列可能性”,我们可以等价为“麻将牌序列的每一个位置都能等概率地放置每一张麻将牌”(这个PART 2的最后会证明)这样我们只需要设计一个算法生成一个随机的麻将序列即可,对空间的消耗大幅降低。
PART 2——Knuth算法过程介绍
那么如何在麻将序列的每一个位置放置等概率地放置每一张麻将牌呢?对于这个问题,为了方便描述,我们可以抽象成“让序列的每一个元素都等概率出现在每一个位置上”。
这个部分为了说明一般情况下Kunth算法确实可行,刚开始会比Kunth算法复杂一点,主要是体会Kunth算法的过程。如果不想完全看下来的话也有过程总结。
现在假定有一个序列 seq=[1,2,3,4,5,6,7] 和标记 i ,j(i >= 0 && i <= 6 && j>= 0 && j <= 6)。对于序列seq,它的索引也可以生成一个序列 ind=[0,1,2,3,4,5,6] 。现在让我们公平地生成一个随机序列。
第一步:让我们随机选中索引 ind[ i ](假定我们选中的是 ind[4] ) ,让seq[ ind[ i ] ]和随机一个序列元素seq[ j ](假定我们随机到的元素是 seq[ ind[3] ])进行交换,则我们得到一个新的序列seq=[1,2,3,5,4,6,7](对于被选中过的索引上的元素,我们使用橙色+加粗做标记,下面不再说明)。这样,元素seq[ ind[3] ]出现在索引ind[4]的可能性为1/7。
第二步:再让我们随机选中未选中过的索引ind[ i ](假定我们选中的是 ind[6] ),让seq[ ind[ i ] ]和随机一个序列元素seq[ j ](被标记为橙色的元素除外,假定我们随机到的元素是 seq[ ind[2] ])进行交换,则我们得到一个新的序列seq=[1,2,7,5,4,6,3]。这样,元素seq[ ind[2] ]出现在索引ind[6]的可能性为6/7*1/6==1/7(P1(未被选中事件)*P2(选中事件))。
后面的步骤再按照此段落进行即可,有兴趣的宝子们可以自行继续推下去。
直到最后,我们会得到一个新序列,并且序列seq每一个seq[ j ]出现在ind[ i ]的概率都为1/7,由于sqe[ j ] 和 ind[ i ] 都是随机选中的,实现了“让序列的每一个元素都等概率出现在每一个位置上”。
虽然我们只做了两步的描述很长,当时如果看懂的话会发现我们做的事非常简单,即随机选中一个从未选中过的一个位置(为了最后描述简洁,我们将这个位置用index代替),然后再随机选择从未选中过的位置上的元素(为了最后描述简洁,我们将这个元素用element代替),将element放置到和index上的元素互换。
知道了怎么做,但Knuth算法并不是这么写,因为现在算法还不够简单。
原因在于选中的位置是随机的且被选中过的位置不能再选,这意味着我们需要一个序列L来存被选中过的位置,在选中index之后遍历序列L看index是否被选中过,否的话还要判断随机选中的元素是否属于seq[ L ]。
既然知道了Kunth算法的过程,那么就来证明我们在PART 1中遗漏的证明。
根据我们上面对于Kunth算法的过程的描述,当算法执行了一步,我们选中元素4的概率是1/7,则得到序列[x,x,x,x,4,x,x]的概率是1/7,如果我们列出seq序列是所有可能,会发现序列 [x,x,x,x,4,x,x]的概率也是1/7( (seq.length-已选中的index数量)! / seq.length! );
当算法执行了两步,我们选中元素3的概率是1/6,则得到序列[x,x,x,x,4,x,3]的概率是1/7*1/6,如果我们列出seq序列是所有可能,会发现序列 [x,x,x,x,4,x,3]的概率也是1/7*1/6
以此类推,证毕!(主要还是本人懒(~ˉ▽ ̄~) )
PART 3——Kunth算法
再重新看一下我们算法的执行过程,会发现index的随机其实是可以不必要的。无论选中的ind[ i ]是多少,seq[ j ]被选中的概率都是1/seq.length。因此,为了我们可以选择索引是从头到尾或者从尾到头的。
从头到尾:
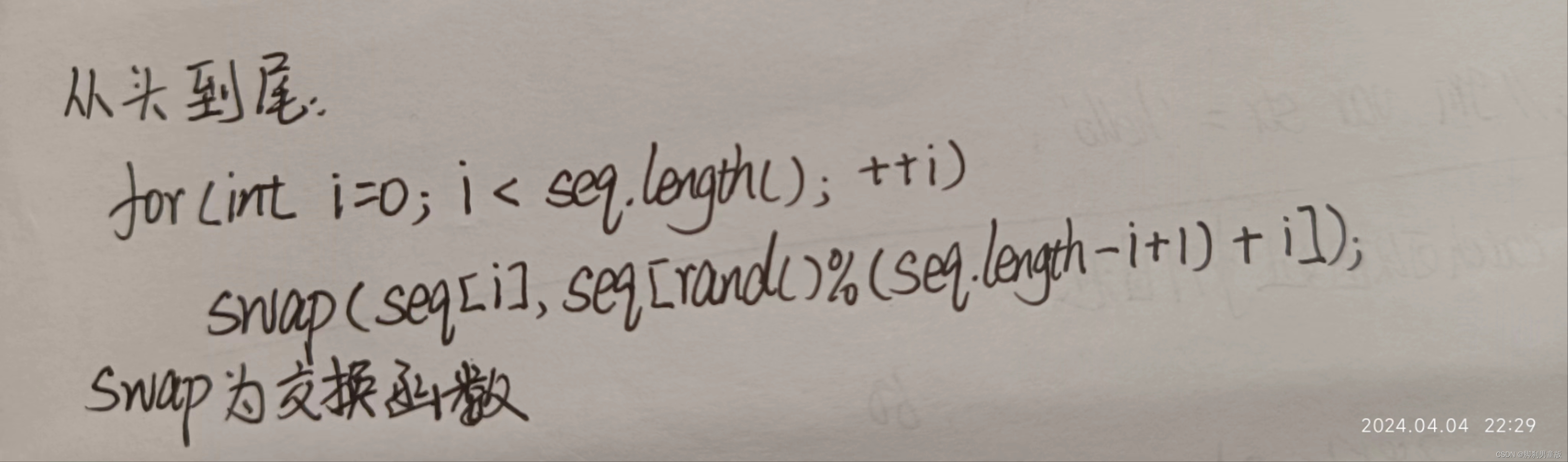
从尾到头:
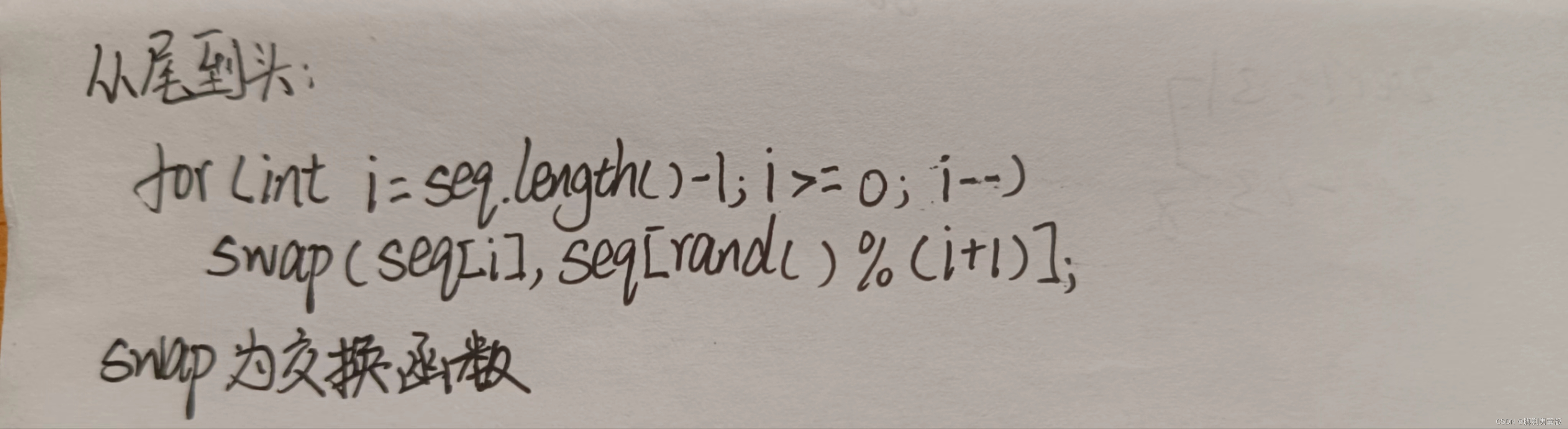
至此Kunth算法的核心就结束了,就是这么简单。

















 3878
3878

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









