






 本文介绍了聚类问题的基本概念,重点分析了K-MEANS算法(包括确定k值、质心计算和距离度量)及其优缺点,以及DBSCAN算法(基于密度而非距离的聚类)和轮廓系数(评估聚类质量的指标)。讨论了如何处理无监督问题和参数调优问题。
本文介绍了聚类问题的基本概念,重点分析了K-MEANS算法(包括确定k值、质心计算和距离度量)及其优缺点,以及DBSCAN算法(基于密度而非距离的聚类)和轮廓系数(评估聚类质量的指标)。讨论了如何处理无监督问题和参数调优问题。
聚类概念:
无监督问题:我们手里没有标签了
聚类:相似的东西分到一组
难点:如何评估,如何调参
1、K-MEANS算法
基本概念:
要得到簇的个数,需要制定k值(几堆数据);
质心:均值,即向量各维取平均即可(后续迭代需要用);
距离的度量:常用欧几里得距离和余弦相似度(先标准化);
优化目标: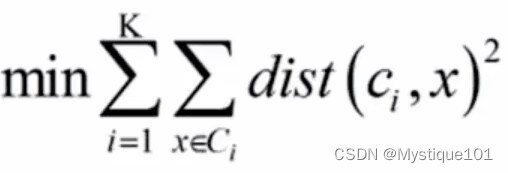

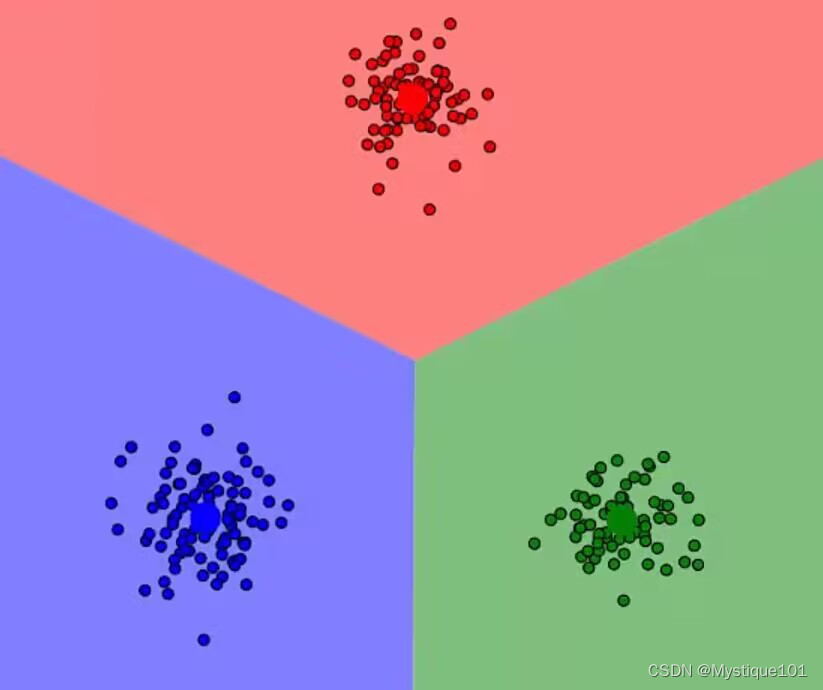
在图片中随机选择两个质心,判断所有的点到两个质心的距离,离哪个近就是什么颜色。随后更新依据,即重新计算两个质心的位置,然后重新遍历所有点到质心的距离,然后看谁小就把谁划分到哪个簇。重复以上过程,直至所有点都不再发生变化!
优势:简单、快速、适合常规数据集
劣势:k值难确定、复杂度与样本呈线性关系、很难发现任意形状的簇。
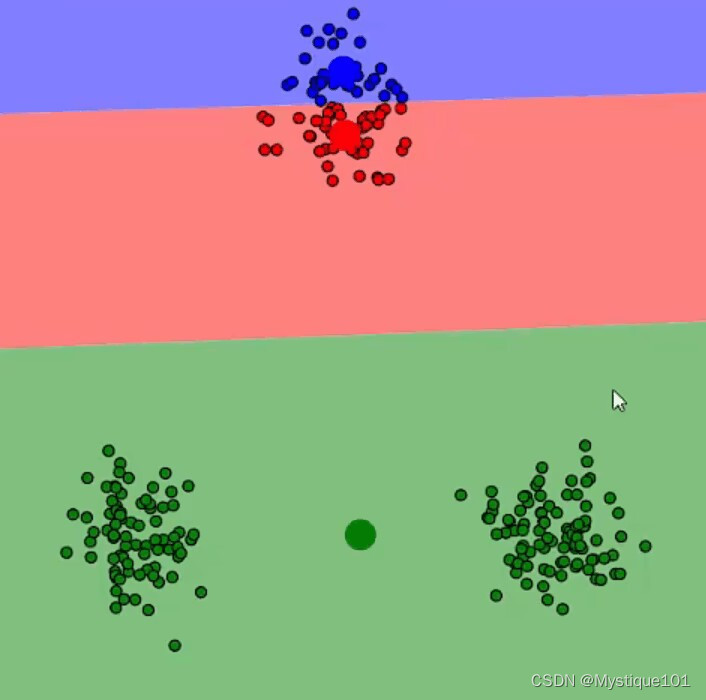
该算法对初始值的设定至关重要(不同的初始点会对结果产生很大的影响),如下图,再迭代无数次,也无法正确聚类。因此在设置时,多取几次初始值,做平均。
2、DBSCAN算法
基本概念:(Density-Based Spatial Clustering of Applications with Noise)是一种密度聚类算法,用于将数据集中的样本点划分为不同的簇。与传统的基于距离的聚类算法(如K-means)不同,DBSCAN利用样本点的密度来确定簇的边界。
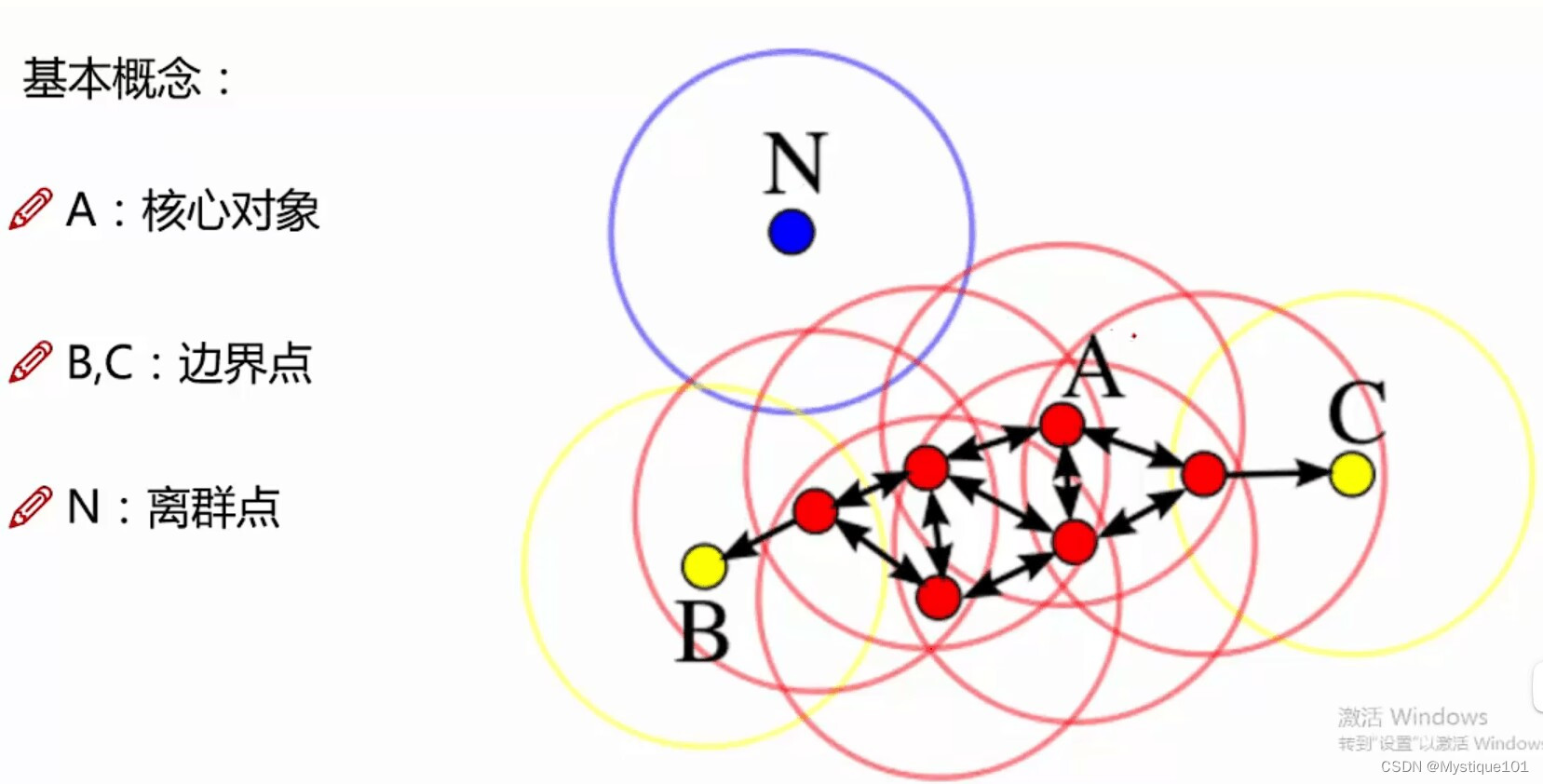
核心对象:若某个点的密度达到算法设定的阈值则其为核心点。(即r邻域内点的数量不小于minPts)。
-邻域的距离阈值:设定的半径r。
直接密度可达:若某点p在点q的r邻域内,且q是核心点则p-q直接密度可达。
密度可达:若有一个点的序列q0、q1、...qk,对任意qi到qi-1是直接密度可达的,则称从q0到qk密度可达,这实际上是直接密度可阿达的“传播”。
密度相连:若从某核心点p出发,点q和点k都是密度可达的,称点q和点k是密度相连的。
边界点:属于某一个类的非核心点,不能发展下线了。
噪声点:不属于任何一个类簇的点,从任何一个核心点出发都是密度不可达的。
算法的步骤如下:
- 初始化参数:设定半径ε和最小样本点数MinPts(密度阈值)。
- 随机选择一个未访问的样本点p。
- 如果p是一个核心点,则找到所有由p密度直接可达的样本点,以及它们的密度可达样本点,将它们划入同一簇。
- 重复步骤3,直到不能再找到新样本点被划入簇为止。
- 如果p不是核心点,则标记p为噪声点。
- 选择下一个未被访问的样本点,重复步骤3和步骤4。
- 直到所有样本点都被访问过为止,结束算法。
优势:不需要指定簇个数、可以发现任意形状的簇、擅长找到离群点(检测任务)、两个参数就够了。劣势:高维数据有些困难(可以做降维)、参数难以选择(参数对结果的影响非常大)、Sklearn中效率很慢(数据消减策略)。
3、轮廓系数
轮廓系数(Silhouette Coefficient)是一种用于评估聚类质量的指标,它将同一簇内的样本点距离尽量小、不同簇之间的距离尽量大作为优化目标。对于一个样本点i,其轮廓系数的计算方法如下:
- a(i):样本点i与同一簇内所有其他样本点之间的平均距离。
- b(i):样本点i与距离它最近的其他簇中所有样本点的平均距离。
- s(i):样本点i的轮廓系数,即(s(i) = b(i) - a(i)) / max(a(i), b(i))。
其中,轮廓系数s(i)取值范围在[-1, 1]之间,当s(i)越接近于1时,表示样本点i聚类效果越好;当s(i)越接近于-1时,表示样本点i被错误的聚类到了错误的簇中;当s(i)接近于0时,则表明样本点i在两个簇的边界上。
对于整个聚类结果,可以计算所有样本点的轮廓系数的平均值来衡量聚类的整体质量,该平均值越趋近于1则表示聚类效果越好。

















 1188
1188

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









