







系统结构图
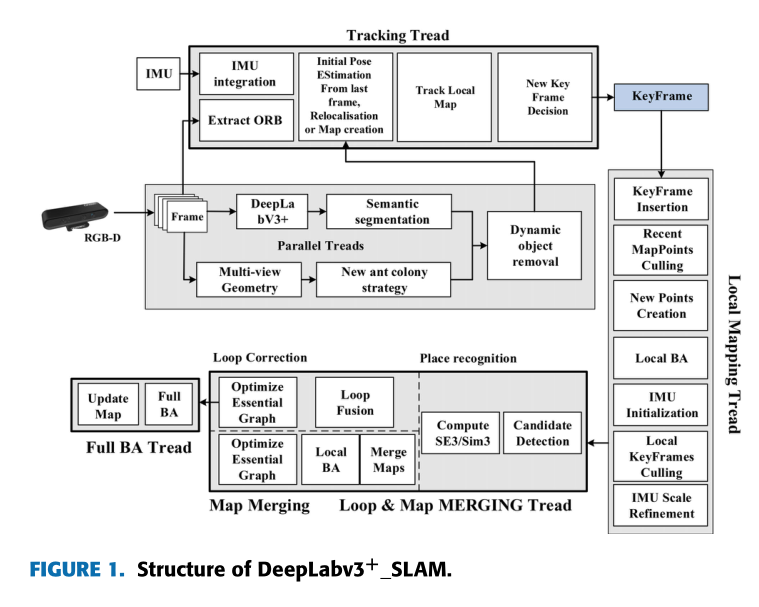
首先,RGB-D 相机收集图像数据。然后将数据传入跟踪线程进行预处理,DeepLabv3+模型将所有先验动态内容按像素进行细分,同时使用几何线程模块区分图像中的动态和静态特征点。
其次,结合DeepLabv3+模型的分割结果和几何模块判断的运动状态信息,提取动态物体的轮廓区域。
最后,去除动态目标区域的特征点和空间点,仅具有静态特征的图像帧用于后续跟踪和地图构建,从而提高视觉SLAM系统在高度动态环境中的准确性和鲁棒性。
语义分割 DeepLabv3+
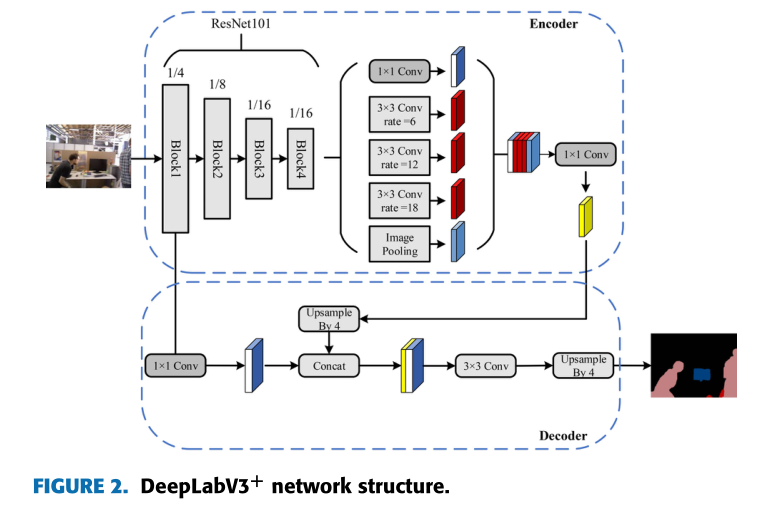
ResNet作为DeepLabv3+的骨干网,性能良好。ResNet主要采用基于瓶颈设计的残差结构,一般在网络层数大于30层时使用,这样可以显著降低网络参数,使网络被训练得更深入,但其接受野的大小是固定的、单一的,不能用于融合多尺度特征,也不能利用跨信道特征之间的相互作用。ResNest的提出弥补了ResNet的不足。
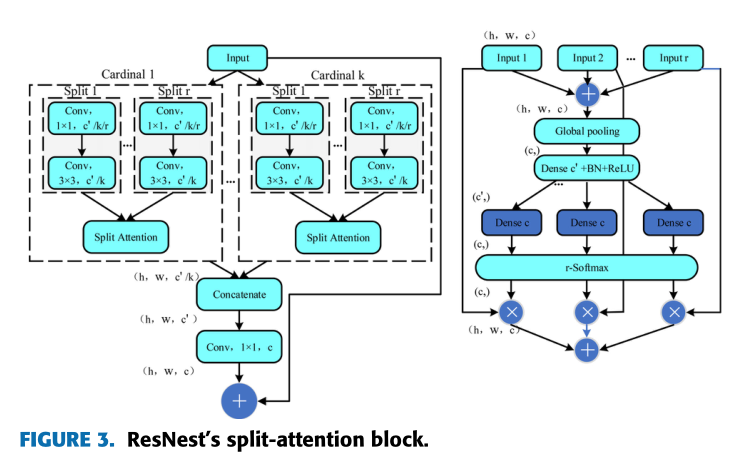
ResNest是对ResNet的一种修改,它将特征图的分裂注意结合在一个网络中,并将通道维度的注意机制扩展到特征图组的表示上,形成模块化。与ResNet及其变体相比,ResNest不需要额外的计算,结果与ResNet及其变体相比有显著的改进。因此,本文采用ResNest作为DeepLabv3+的骨干网,使SLAM系统中的语义线程具有更好的图像分割性能。
ASPP模块
在解码模块中,原始ASPP模块中的卷积层为1 × 1空洞卷积、3 × 3空洞卷积(空洞率为6、12、18)和全局平均池化层,随着骨干网络对图像特征的不断提取,特征图的分辨率会不断降低,膨胀率较大的膨胀卷积不利于提取分辨率较低的特征图信息。
为了解决这一问题,在原有的空洞卷积基础上增加了一层新的空洞卷积,并将空洞率调整为4、8、12、16,以提高低分辨率特征图信息的提取。
深度可分离式卷积
本文在不改变膨胀率的情况下,通过二维分解将ASPP中的所有3 × 3卷积转化为3 × 1和1 × 3卷积。与原有结构相比,减少了约1/3的参数数量,有效减少了该模块的计算量,训练速度更快,能够提取重要特征信息。
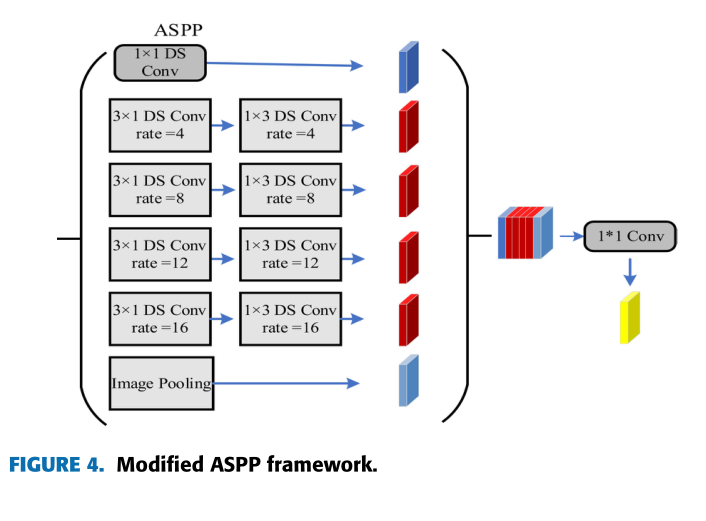
骨干网生成的特征图发送到ASPP处理时,首先对特征图进行1 × 1卷积,扩张率为4、8、12、16的卷积,并进行全局平均池化操作。然后,将得到的6个特征映射在信道维度上进行拼接和融合。最后,经过1 × 1卷积和降维操作,得到包含高级语义特征的特征图。
基于多视图几何的动态目标检测
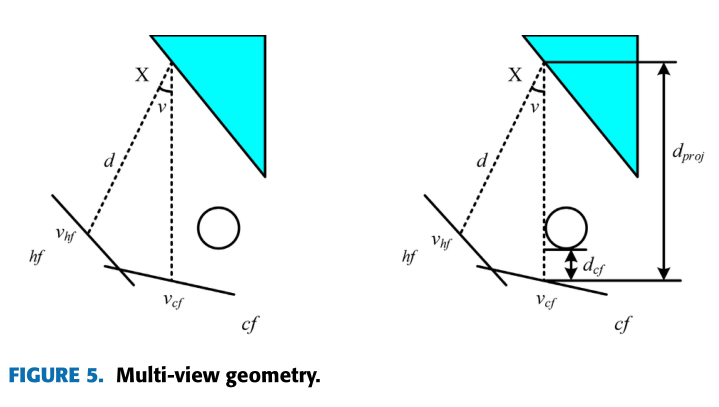
通过计算当前帧各关键点的视角值vcf (cf)和历史帧各关键点的视角值vhf (hf),如果视角值1v = |vcf−vhf |之差大于设置的阈值,则判定该关键点为动态点。同时,我们还需要计算当前帧中关键点的深度值dcf和历史帧在当前帧中的投影深度值dproj。如果深度值的差值为1d = |dproj−dcf | = 0,则确定关键点为静态点。如果1d大于设置的阈值dthresh,则认为关键点是动态的
蚁群算法
多视图几何方法将历史帧图像通过投影转换为当前帧图像时,会得到大量的投影特征点。
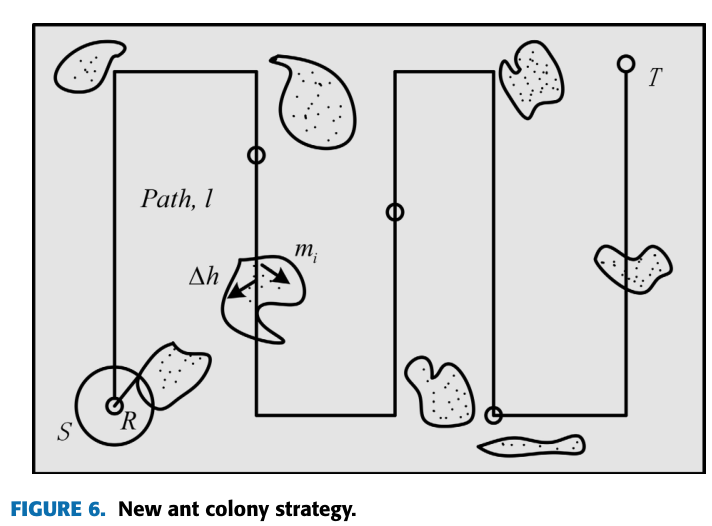
通过遍历所有投影特征点来确定一个点是静态点还是动态点。然而,在特征提取过程中有数千个特征点,如果必须确定每个特征是静态的还是动态的,SLAM的实时性会受到限制。本文在蚁群算法策略的基础上,提出了一种新的蚁群策略,通过最优路径找到所有动态特征点的组,从而避免遍历所有特征点,减少特征点所消耗的时间。
在移动路径上,每个特征点m以自身为原点,在半径r内搜索特征点,如果没有找到动态点,则在路径l上继续搜索。当找到动态点时,以带宽1h向外展开。如果找到下一个新的动态点,则继续向外展开1h,直到在展开区域内没有发现动态点,然后返回路径l,继续依次搜索下一个与动态特征相匹配的特征点mi,直到路径l完成


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









